 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLow-Complexity Acoustic Echo Cancellation with Neural Kalman Filtering
Jul 23, 2022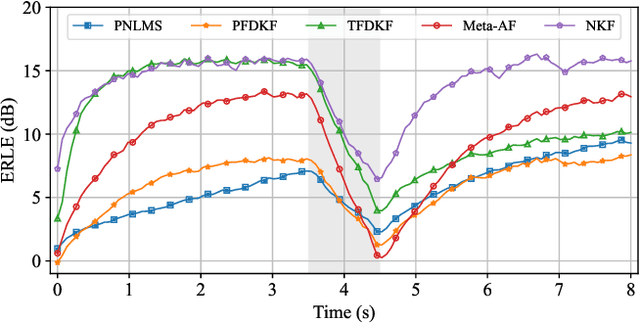

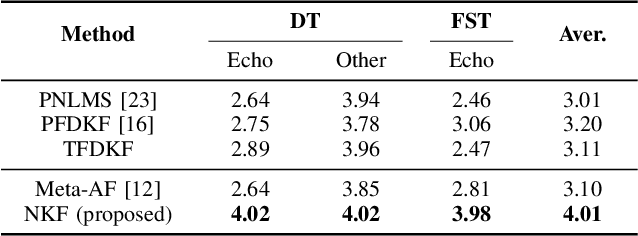
The Kalman filter has been adopted in acoustic echo cancellation due to its robustness to double-talk, fast convergence, and good steady-state performance. The performance of Kalman filter is closely related to the estimation accuracy of the state noise covariance and the observation noise covariance. The estimation error may lead to unacceptable results, especially when the echo path suffers abrupt changes, the tracking performance of the Kalman filter could be degraded significantly. In this paper, we propose the neural Kalman filtering (NKF), which uses neural networks to implicitly model the covariance of the state noise and observation noise and to output the Kalman gain in real-time. Experimental results on both synthetic test sets and real-recorded test sets show that, the proposed NKF has superior convergence and re-convergence performance while ensuring low near-end speech degradation comparing with the state-of-the-art model-based methods. Moreover, the model size of the proposed NKF is merely 5.3 K and the RTF is as low as 0.09, which indicates that it can be deployed in low-resource platforms.
HQANN: Efficient and Robust Similarity Search for Hybrid Queries with Structured and Unstructured Constraints
Jul 16, 2022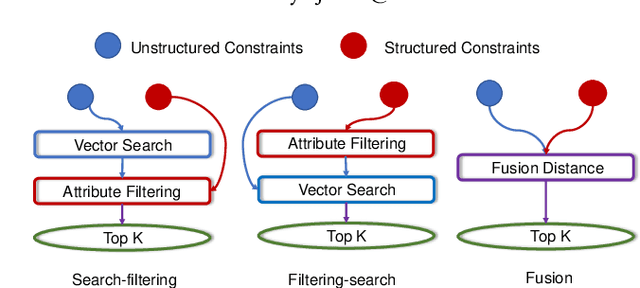
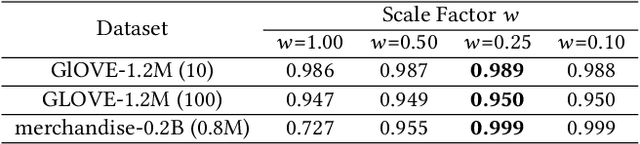
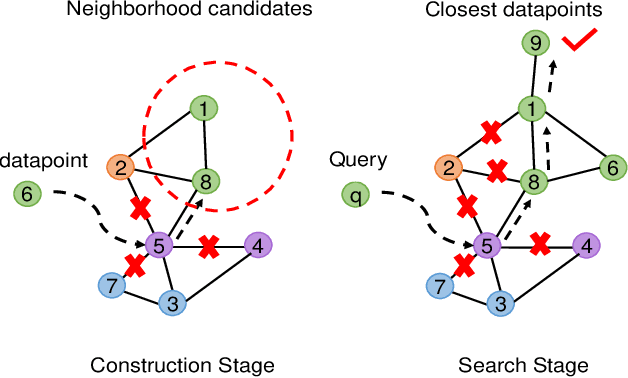

The in-memory approximate nearest neighbor search (ANNS) algorithms have achieved great success for fast high-recall query processing, but are extremely inefficient when handling hybrid queries with unstructured (i.e., feature vectors) and structured (i.e., related attributes) constraints. In this paper, we present HQANN, a simple yet highly efficient hybrid query processing framework which can be easily embedded into existing proximity graph-based ANNS algorithms. We guarantee both low latency and high recall by leveraging navigation sense among attributes and fusing vector similarity search with attribute filtering. Experimental results on both public and in-house datasets demonstrate that HQANN is 10x faster than the state-of-the-art hybrid ANNS solutions to reach the same recall quality and its performance is hardly affected by the complexity of attributes. It can reach 99\% recall@10 in just around 50 microseconds On GLOVE-1.2M with thousands of attribute constraints.
Perceptual Quality Assessment for Fine-Grained Compressed Images
Jun 08, 2022
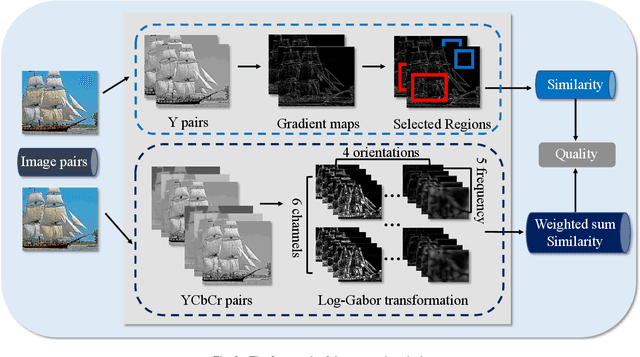

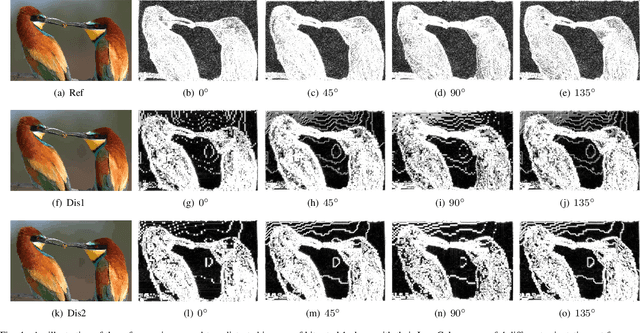
Recent years have witnessed the rapid development of image storage and transmission systems, in which image compression plays an important role. Generally speaking, image compression algorithms are developed to ensure good visual quality at limited bit rates. However, due to the different compression optimization methods, the compressed images may have different levels of quality, which needs to be evaluated quantificationally. Nowadays, the mainstream full-reference (FR) metrics are effective to predict the quality of compressed images at coarse-grained levels (the bit rates differences of compressed images are obvious), however, they may perform poorly for fine-grained compressed images whose bit rates differences are quite subtle. Therefore, to better improve the Quality of Experience (QoE) and provide useful guidance for compression algorithms, we propose a full-reference image quality assessment (FR-IQA) method for compressed images of fine-grained levels. Specifically, the reference images and compressed images are first converted to $YCbCr$ color space. The gradient features are extracted from regions that are sensitive to compression artifacts. Then we employ the Log-Gabor transformation to further analyze the texture difference. Finally, the obtained features are fused into a quality score. The proposed method is validated on the fine-grained compression image quality assessment (FGIQA) database, which is especially constructed for assessing the quality of compressed images with close bit rates. The experimental results show that our metric outperforms mainstream FR-IQA metrics on the FGIQA database. We also test our method on other commonly used compression IQA databases and the results show that our method obtains competitive performance on the coarse-grained compression IQA databases as well.
Searching for Optimal Subword Tokenization in Cross-domain NER
Jun 07, 2022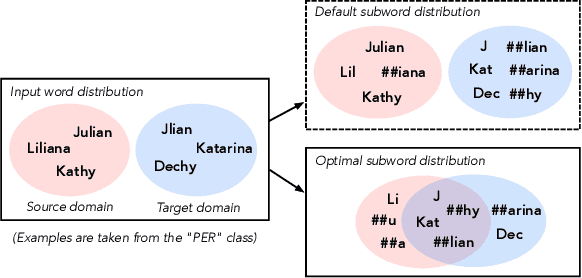

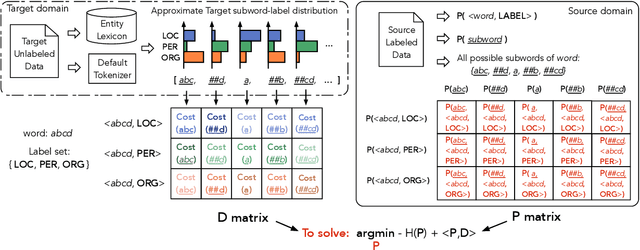
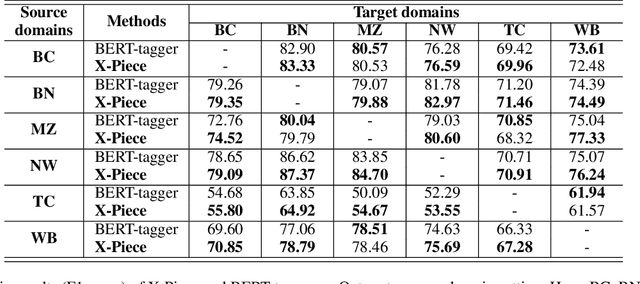
Input distribution shift is one of the vital problems in unsupervised domain adaptation (UDA). The most popular UDA approaches focus on domain-invariant representation learning, trying to align the features from different domains into similar feature distributions. However, these approaches ignore the direct alignment of input word distributions between domains, which is a vital factor in word-level classification tasks such as cross-domain NER. In this work, we shed new light on cross-domain NER by introducing a subword-level solution, X-Piece, for input word-level distribution shift in NER. Specifically, we re-tokenize the input words of the source domain to approach the target subword distribution, which is formulated and solved as an optimal transport problem. As this approach focuses on the input level, it can also be combined with previous DIRL methods for further improvement. Experimental results show the effectiveness of the proposed method based on BERT-tagger on four benchmark NER datasets. Also, the proposed method is proved to benefit DIRL methods such as DANN.
AutoDisc: Automatic Distillation Schedule for Large Language Model Compression
May 29, 2022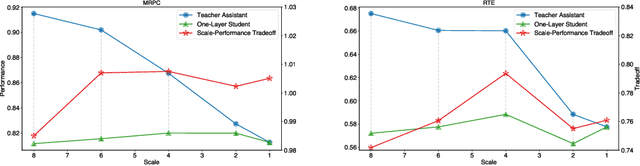
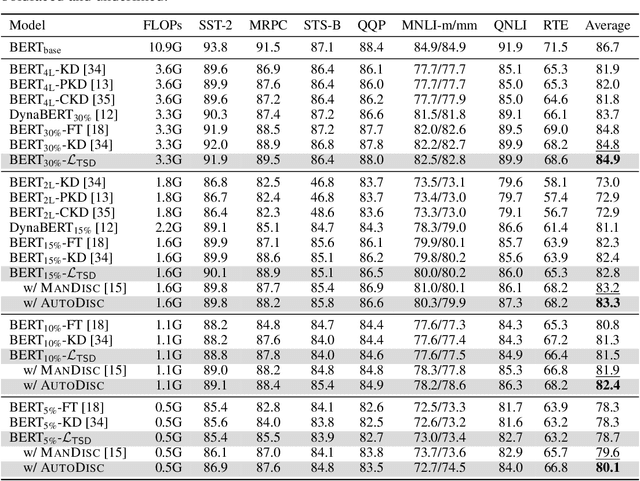

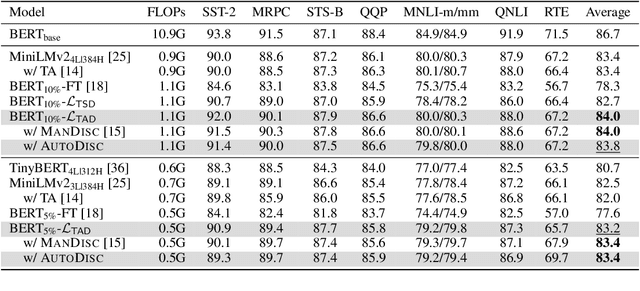
Driven by the teacher-student paradigm, knowledge distillation is one of the de facto ways for language model compression. Recent studies have uncovered that conventional distillation is less effective when facing a large capacity gap between the teacher and the student, and introduced teacher assistant-based distillation to bridge the gap. As a connection, the scale and the performance of the teacher assistant is crucial for transferring the knowledge from the teacher to the student. However, existing teacher assistant-based methods manually select the scale of the teacher assistant, which fails to identify the teacher assistant with the optimal scale-performance tradeoff. To this end, we propose an Automatic Distillation Schedule (AutoDisc) for large language model compression. In particular, AutoDisc first specifies a set of teacher assistant candidates at different scales with gridding and pruning, and then optimizes all candidates in an once-for-all optimization with two approximations. The best teacher assistant scale is automatically selected according to the scale-performance tradeoff. AutoDisc is evaluated with an extensive set of experiments on a language understanding benchmark GLUE. Experimental results demonstrate the improved performance and applicability of our AutoDisc. We further apply AutoDisc on a language model with over one billion parameters and show the scalability of AutoDisc.
Ensemble Multi-Relational Graph Neural Networks
May 24, 2022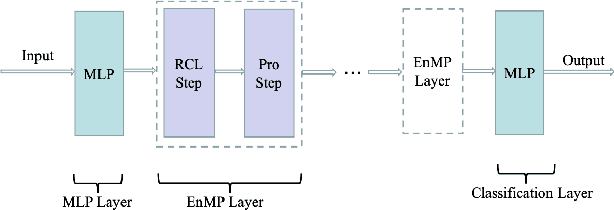
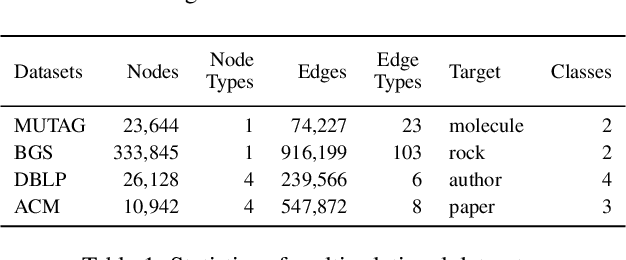
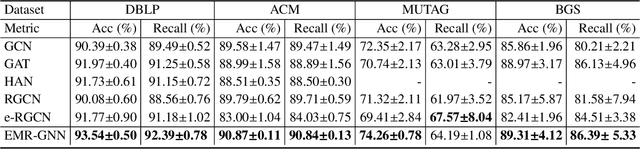

It is well established that graph neural networks (GNNs) can be interpreted and designed from the perspective of optimization objective. With this clear optimization objective, the deduced GNNs architecture has sound theoretical foundation, which is able to flexibly remedy the weakness of GNNs. However, this optimization objective is only proved for GNNs with single-relational graph. Can we infer a new type of GNNs for multi-relational graphs by extending this optimization objective, so as to simultaneously solve the issues in previous multi-relational GNNs, e.g., over-parameterization? In this paper, we propose a novel ensemble multi-relational GNNs by designing an ensemble multi-relational (EMR) optimization objective. This EMR optimization objective is able to derive an iterative updating rule, which can be formalized as an ensemble message passing (EnMP) layer with multi-relations. We further analyze the nice properties of EnMP layer, e.g., the relationship with multi-relational personalized PageRank. Finally, a new multi-relational GNNs which well alleviate the over-smoothing and over-parameterization issues are proposed. Extensive experiments conducted on four benchmark datasets well demonstrate the effectiveness of the proposed model.
Boosting Camouflaged Object Detection with Dual-Task Interactive Transformer
May 21, 2022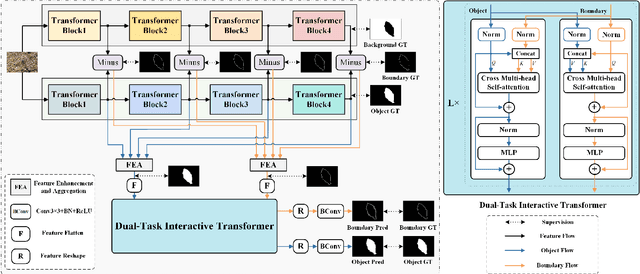
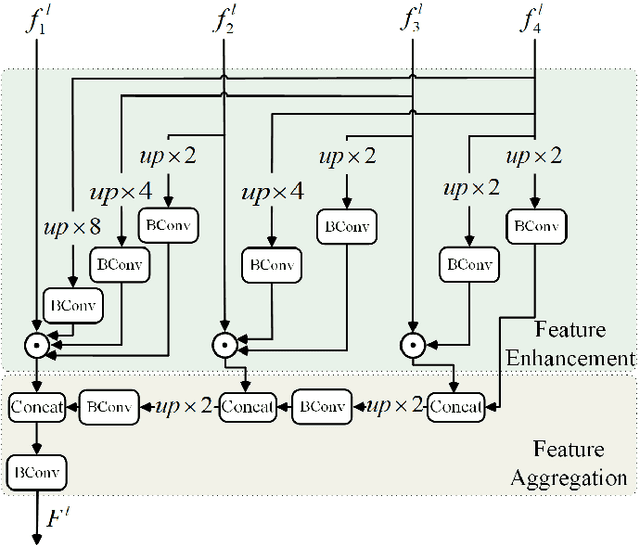
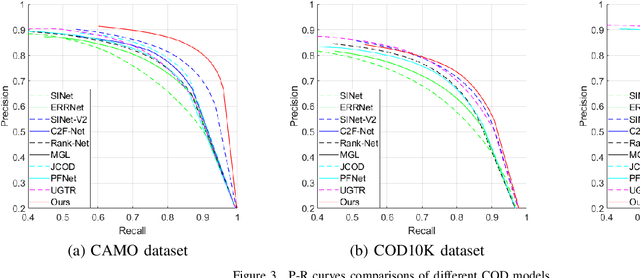

Camouflaged object detection intends to discover the concealed objects hidden in the surroundings. Existing methods follow the bio-inspired framework, which first locates the object and second refines the boundary. We argue that the discovery of camouflaged objects depends on the recurrent search for the object and the boundary. The recurrent processing makes the human tired and helpless, but it is just the advantage of the transformer with global search ability. Therefore, a dual-task interactive transformer is proposed to detect both accurate position of the camouflaged object and its detailed boundary. The boundary feature is considered as Query to improve the camouflaged object detection, and meanwhile the object feature is considered as Query to improve the boundary detection. The camouflaged object detection and the boundary detection are fully interacted by multi-head self-attention. Besides, to obtain the initial object feature and boundary feature, transformer-based backbones are adopted to extract the foreground and background. The foreground is just object, while foreground minus background is considered as boundary. Here, the boundary feature can be obtained from blurry boundary region of the foreground and background. Supervised by the object, the background and the boundary ground truth, the proposed model achieves state-of-the-art performance in public datasets. https://github.com/liuzywen/COD
* Accepted by ICPR2022
Graph Adaptive Semantic Transfer for Cross-domain Sentiment Classification
May 18, 2022
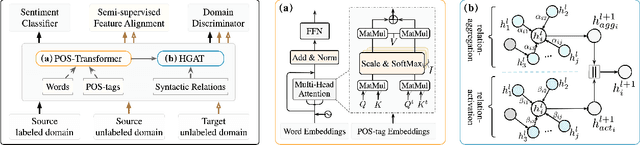
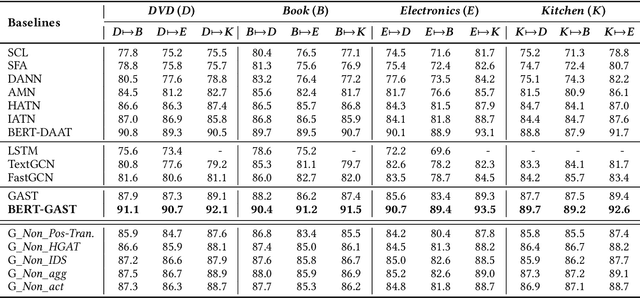
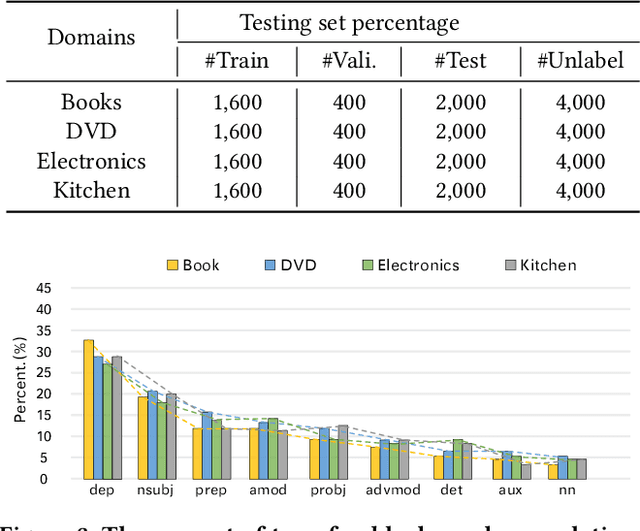
Cross-domain sentiment classification (CDSC) aims to use the transferable semantics learned from the source domain to predict the sentiment of reviews in the unlabeled target domain. Existing studies in this task attach more attention to the sequence modeling of sentences while largely ignoring the rich domain-invariant semantics embedded in graph structures (i.e., the part-of-speech tags and dependency relations). As an important aspect of exploring characteristics of language comprehension, adaptive graph representations have played an essential role in recent years. To this end, in the paper, we aim to explore the possibility of learning invariant semantic features from graph-like structures in CDSC. Specifically, we present Graph Adaptive Semantic Transfer (GAST) model, an adaptive syntactic graph embedding method that is able to learn domain-invariant semantics from both word sequences and syntactic graphs. More specifically, we first raise a POS-Transformer module to extract sequential semantic features from the word sequences as well as the part-of-speech tags. Then, we design a Hybrid Graph Attention (HGAT) module to generate syntax-based semantic features by considering the transferable dependency relations. Finally, we devise an Integrated aDaptive Strategy (IDS) to guide the joint learning process of both modules. Extensive experiments on four public datasets indicate that GAST achieves comparable effectiveness to a range of state-of-the-art models.
Making Pre-trained Language Models Good Long-tailed Learners
May 11, 2022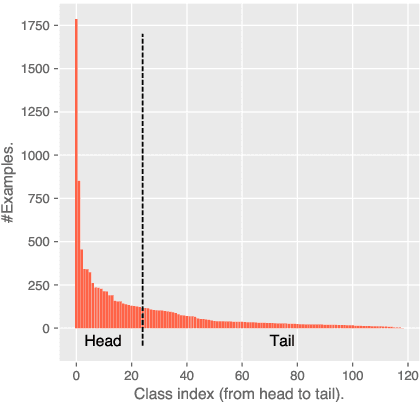
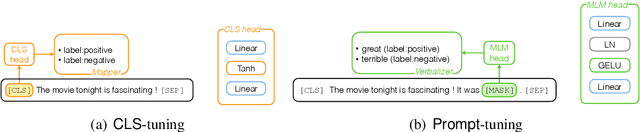
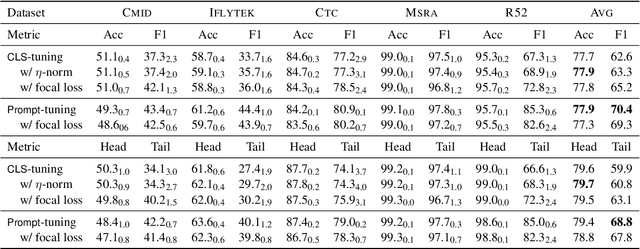
Prompt-tuning has shown appealing performance in few-shot classification by virtue of its capability in effectively exploiting pre-trained knowledge. This motivates us to check the hypothesis that prompt-tuning is also a promising choice for long-tailed classification, since the tail classes are intuitively few-shot ones. To achieve this aim, we conduct empirical studies to examine the hypothesis. The results demonstrate that prompt-tuning exactly makes pre-trained language models at least good long-tailed learners. For intuitions on why prompt-tuning can achieve good performance in long-tailed classification, we carry out an in-depth analysis by progressively bridging the gap between prompt-tuning and commonly used fine-tuning. The summary is that the classifier structure and parameterization form the key to making good long-tailed learners, in comparison with the less important input structure. Finally, we verify the applicability of our finding to few-shot classification.
Cross Domain Object Detection by Target-Perceived Dual Branch Distillation
May 03, 2022
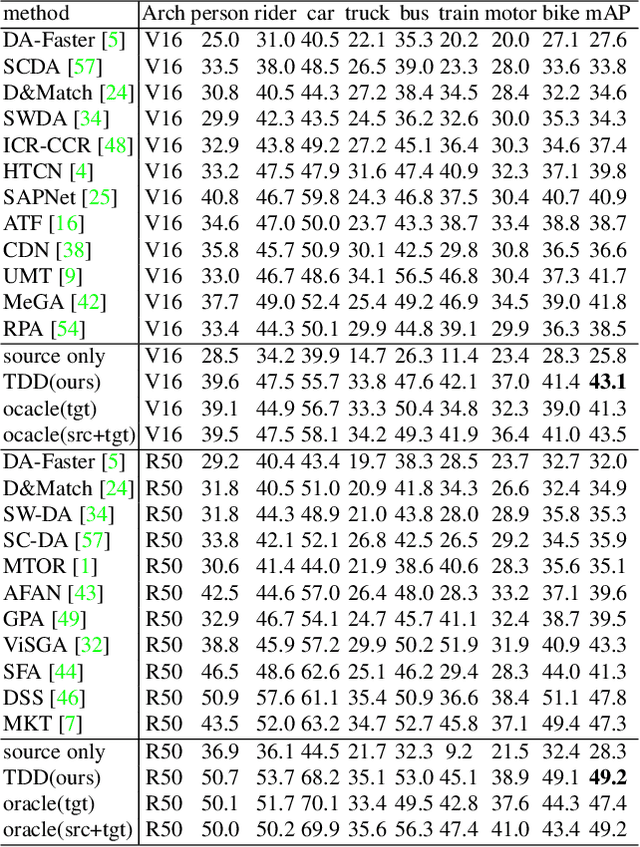
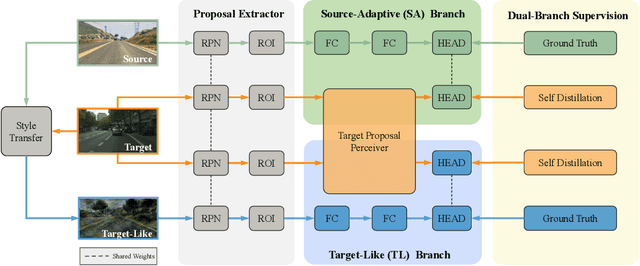
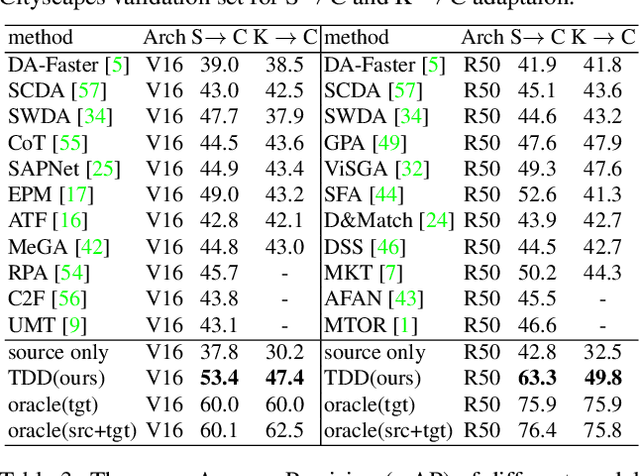
Cross domain object detection is a realistic and challenging task in the wild. It suffers from performance degradation due to large shift of data distributions and lack of instance-level annotations in the target domain. Existing approaches mainly focus on either of these two difficulties, even though they are closely coupled in cross domain object detection. To solve this problem, we propose a novel Target-perceived Dual-branch Distillation (TDD) framework. By integrating detection branches of both source and target domains in a unified teacher-student learning scheme, it can reduce domain shift and generate reliable supervision effectively. In particular, we first introduce a distinct Target Proposal Perceiver between two domains. It can adaptively enhance source detector to perceive objects in a target image, by leveraging target proposal contexts from iterative cross-attention. Afterwards, we design a concise Dual Branch Self Distillation strategy for model training, which can progressively integrate complementary object knowledge from different domains via self-distillation in two branches. Finally, we conduct extensive experiments on a number of widely-used scenarios in cross domain object detection. The results show that our TDD significantly outperforms the state-of-the-art methods on all the benchmarks. Our code and model will be available at https://github.com/Feobi1999/TDD.