 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniHM: Universal Human Motion Generation with Object Interactions in Indoor Scenes
May 19, 2025Human motion synthesis in complex scenes presents a fundamental challenge, extending beyond conventional Text-to-Motion tasks by requiring the integration of diverse modalities such as static environments, movable objects, natural language prompts, and spatial waypoints. Existing language-conditioned motion models often struggle with scene-aware motion generation due to limitations in motion tokenization, which leads to information loss and fails to capture the continuous, context-dependent nature of 3D human movement. To address these issues, we propose UniHM, a unified motion language model that leverages diffusion-based generation for synthesizing scene-aware human motion. UniHM is the first framework to support both Text-to-Motion and Text-to-Human-Object Interaction (HOI) in complex 3D scenes. Our approach introduces three key contributions: (1) a mixed-motion representation that fuses continuous 6DoF motion with discrete local motion tokens to improve motion realism; (2) a novel Look-Up-Free Quantization VAE (LFQ-VAE) that surpasses traditional VQ-VAEs in both reconstruction accuracy and generative performance; and (3) an enriched version of the Lingo dataset augmented with HumanML3D annotations, providing stronger supervision for scene-specific motion learning. Experimental results demonstrate that UniHM achieves comparative performance on the OMOMO benchmark for text-to-HOI synthesis and yields competitive results on HumanML3D for general text-conditioned motion generation.
Enhance Mobile Agents Thinking Process Via Iterative Preference Learning
May 18, 2025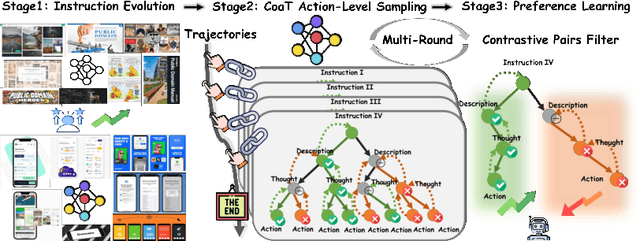
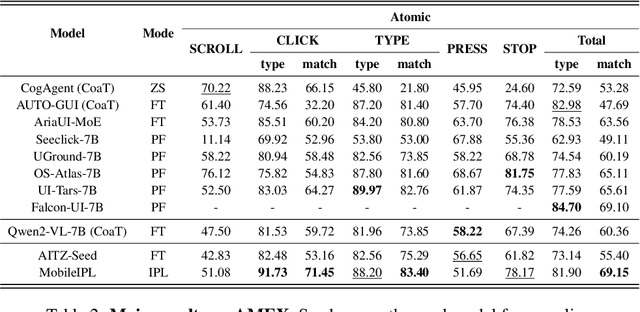
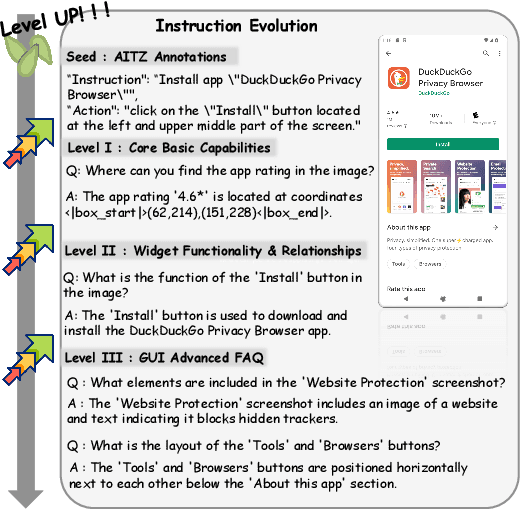
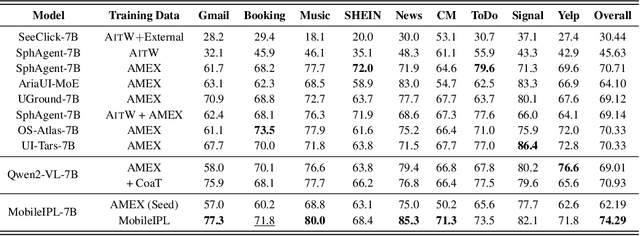
The Chain of Action-Planning Thoughts (CoaT) paradigm has been shown to improve the reasoning performance of VLM-based mobile agents in GUI tasks. However, the scarcity of diverse CoaT trajectories limits the expressiveness and generalization ability of such agents. While self-training is commonly employed to address data scarcity, existing approaches either overlook the correctness of intermediate reasoning steps or depend on expensive process-level annotations to construct process reward models (PRM). To address the above problems, we propose an Iterative Preference Learning (IPL) that constructs a CoaT-tree through interative sampling, scores leaf nodes using rule-based reward, and backpropagates feedback to derive Thinking-level Direct Preference Optimization (T-DPO) pairs. To prevent overfitting during warm-up supervised fine-tuning, we further introduce a three-stage instruction evolution, which leverages GPT-4o to generate diverse Q\&A pairs based on real mobile UI screenshots, enhancing both generality and layout understanding. Experiments on three standard Mobile GUI-agent benchmarks demonstrate that our agent MobileIPL outperforms strong baselines, including continual pretraining models such as OS-ATLAS and UI-TARS. It achieves state-of-the-art performance across three standard Mobile GUI-Agents benchmarks and shows strong generalization to out-of-domain scenarios.
How Reliable is Multilingual LLM-as-a-Judge?
May 18, 2025LLM-as-a-Judge has emerged as a popular evaluation strategy, where advanced large language models assess generation results in alignment with human instructions. While these models serve as a promising alternative to human annotators, their reliability in multilingual evaluation remains uncertain. To bridge this gap, we conduct a comprehensive analysis of multilingual LLM-as-a-Judge. Specifically, we evaluate five models from different model families across five diverse tasks involving 25 languages. Our findings reveal that LLMs struggle to achieve consistent judgment results across languages, with an average Fleiss' Kappa of approximately 0.3, and some models performing even worse. To investigate the cause of inconsistency, we analyze various influencing factors. We observe that consistency varies significantly across languages, with particularly poor performance in low-resource languages. Additionally, we find that neither training on multilingual data nor increasing model scale directly improves judgment consistency. These findings suggest that LLMs are not yet reliable for evaluating multilingual predictions. We finally propose an ensemble strategy which improves the consistency of the multilingual judge in real-world applications.
Mobile-Bench-v2: A More Realistic and Comprehensive Benchmark for VLM-based Mobile Agents
May 17, 2025



VLM-based mobile agents are increasingly popular due to their capabilities to interact with smartphone GUIs and XML-structured texts and to complete daily tasks. However, existing online benchmarks struggle with obtaining stable reward signals due to dynamic environmental changes. Offline benchmarks evaluate the agents through single-path trajectories, which stands in contrast to the inherently multi-solution characteristics of GUI tasks. Additionally, both types of benchmarks fail to assess whether mobile agents can handle noise or engage in proactive interactions due to a lack of noisy apps or overly full instructions during the evaluation process. To address these limitations, we use a slot-based instruction generation method to construct a more realistic and comprehensive benchmark named Mobile-Bench-v2. Mobile-Bench-v2 includes a common task split, with offline multi-path evaluation to assess the agent's ability to obtain step rewards during task execution. It contains a noisy split based on pop-ups and ads apps, and a contaminated split named AITZ-Noise to formulate a real noisy environment. Furthermore, an ambiguous instruction split with preset Q\&A interactions is released to evaluate the agent's proactive interaction capabilities. We conduct evaluations on these splits using the single-agent framework AppAgent-v1, the multi-agent framework Mobile-Agent-v2, as well as other mobile agents such as UI-Tars and OS-Atlas. Code and data are available at https://huggingface.co/datasets/xwk123/MobileBench-v2.
XRAG: Cross-lingual Retrieval-Augmented Generation
May 15, 2025We propose XRAG, a novel benchmark designed to evaluate the generation abilities of LLMs in cross-lingual Retrieval-Augmented Generation (RAG) settings where the user language does not match the retrieval results. XRAG is constructed from recent news articles to ensure that its questions require external knowledge to be answered. It covers the real-world scenarios of monolingual and multilingual retrieval, and provides relevancy annotations for each retrieved document. Our novel dataset construction pipeline results in questions that require complex reasoning, as evidenced by the significant gap between human and LLM performance. Consequently, XRAG serves as a valuable benchmark for studying LLM reasoning abilities, even before considering the additional cross-lingual complexity. Experimental results on five LLMs uncover two previously unreported challenges in cross-lingual RAG: 1) in the monolingual retrieval setting, all evaluated models struggle with response language correctness; 2) in the multilingual retrieval setting, the main challenge lies in reasoning over retrieved information across languages rather than generation of non-English text.
DanceGRPO: Unleashing GRPO on Visual Generation
May 12, 2025



Recent breakthroughs in generative models-particularly diffusion models and rectified flows-have revolutionized visual content creation, yet aligning model outputs with human preferences remains a critical challenge. Existing reinforcement learning (RL)-based methods for visual generation face critical limitations: incompatibility with modern Ordinary Differential Equations (ODEs)-based sampling paradigms, instability in large-scale training, and lack of validation for video generation. This paper introduces DanceGRPO, the first unified framework to adapt Group Relative Policy Optimization (GRPO) to visual generation paradigms, unleashing one unified RL algorithm across two generative paradigms (diffusion models and rectified flows), three tasks (text-to-image, text-to-video, image-to-video), four foundation models (Stable Diffusion, HunyuanVideo, FLUX, SkyReel-I2V), and five reward models (image/video aesthetics, text-image alignment, video motion quality, and binary reward). To our knowledge, DanceGRPO is the first RL-based unified framework capable of seamless adaptation across diverse generative paradigms, tasks, foundational models, and reward models. DanceGRPO demonstrates consistent and substantial improvements, which outperform baselines by up to 181% on benchmarks such as HPS-v2.1, CLIP Score, VideoAlign, and GenEval. Notably, DanceGRPO not only can stabilize policy optimization for complex video generation, but also enables generative policy to better capture denoising trajectories for Best-of-N inference scaling and learn from sparse binary feedback. Our results establish DanceGRPO as a robust and versatile solution for scaling Reinforcement Learning from Human Feedback (RLHF) tasks in visual generation, offering new insights into harmonizing reinforcement learning and visual synthesis. The code will be released.
EcoLANG: Efficient and Effective Agent Communication Language Induction for Social Simulation
May 11, 2025Large language models (LLMs) have demonstrated an impressive ability to role-play humans and replicate complex social dynamics. While large-scale social simulations are gaining increasing attention, they still face significant challenges, particularly regarding high time and computation costs. Existing solutions, such as distributed mechanisms or hybrid agent-based model (ABM) integrations, either fail to address inference costs or compromise accuracy and generalizability. To this end, we propose EcoLANG: Efficient and Effective Agent Communication Language Induction for Social Simulation. EcoLANG operates in two stages: (1) language evolution, where we filter synonymous words and optimize sentence-level rules through natural selection, and (2) language utilization, where agents in social simulations communicate using the evolved language. Experimental results demonstrate that EcoLANG reduces token consumption by over 20%, enhancing efficiency without sacrificing simulation accuracy.
Bring Reason to Vision: Understanding Perception and Reasoning through Model Merging
May 08, 2025Vision-Language Models (VLMs) combine visual perception with the general capabilities, such as reasoning, of Large Language Models (LLMs). However, the mechanisms by which these two abilities can be combined and contribute remain poorly understood. In this work, we explore to compose perception and reasoning through model merging that connects parameters of different models. Unlike previous works that often focus on merging models of the same kind, we propose merging models across modalities, enabling the incorporation of the reasoning capabilities of LLMs into VLMs. Through extensive experiments, we demonstrate that model merging offers a successful pathway to transfer reasoning abilities from LLMs to VLMs in a training-free manner. Moreover, we utilize the merged models to understand the internal mechanism of perception and reasoning and how merging affects it. We find that perception capabilities are predominantly encoded in the early layers of the model, whereas reasoning is largely facilitated by the middle-to-late layers. After merging, we observe that all layers begin to contribute to reasoning, whereas the distribution of perception abilities across layers remains largely unchanged. These observations shed light on the potential of model merging as a tool for multimodal integration and interpretation.
X-Driver: Explainable Autonomous Driving with Vision-Language Models
May 08, 2025



End-to-end autonomous driving has advanced significantly, offering benefits such as system simplicity and stronger driving performance in both open-loop and closed-loop settings than conventional pipelines. However, existing frameworks still suffer from low success rates in closed-loop evaluations, highlighting their limitations in real-world deployment. In this paper, we introduce X-Driver, a unified multi-modal large language models(MLLMs) framework designed for closed-loop autonomous driving, leveraging Chain-of-Thought(CoT) and autoregressive modeling to enhance perception and decision-making. We validate X-Driver across multiple autonomous driving tasks using public benchmarks in CARLA simulation environment, including Bench2Drive[6]. Our experimental results demonstrate superior closed-loop performance, surpassing the current state-of-the-art(SOTA) while improving the interpretability of driving decisions. These findings underscore the importance of structured reasoning in end-to-end driving and establish X-Driver as a strong baseline for future research in closed-loop autonomous driving.
DocSpiral: A Platform for Integrated Assistive Document Annotation through Human-in-the-Spiral
May 06, 2025Acquiring structured data from domain-specific, image-based documents such as scanned reports is crucial for many downstream tasks but remains challenging due to document variability. Many of these documents exist as images rather than as machine-readable text, which requires human annotation to train automated extraction systems. We present DocSpiral, the first Human-in-the-Spiral assistive document annotation platform, designed to address the challenge of extracting structured information from domain-specific, image-based document collections. Our spiral design establishes an iterative cycle in which human annotations train models that progressively require less manual intervention. DocSpiral integrates document format normalization, comprehensive annotation interfaces, evaluation metrics dashboard, and API endpoints for the development of AI / ML models into a unified workflow. Experiments demonstrate that our framework reduces annotation time by at least 41\% while showing consistent performance gains across three iterations during model training. By making this annotation platform freely accessible, we aim to lower barriers to AI/ML models development in document processing, facilitating the adoption of large language models in image-based, document-intensive fields such as geoscience and healthcare. The system is freely available at: https://app.ai4wa.com. The demonstration video is available: https://app.ai4wa.com/docs/docspiral/demo.