 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow Mobile World Model Guides GUI Agents?
May 11, 2026Recent advances in vision-language models have enabled mobile GUI agents to perceive visual interfaces and execute user instructions, but reliable prediction of action consequences remains critical for long-horizon and high-risk interactions. Existing mobile world models provide either text-based or image-based future states, yet it remains unclear which representation is useful, whether generated rollouts can replace real environments, and how test-time guidance helps agents of different strengths. To answer the above questions, we filter and annotate mobile world-model data, then train world models across four modalities: delta text, full text, diffusion-based images, and renderable code. These models achieve SoTA performance on both MobileWorldBench and Code2WorldBench. Furthermore, by evaluating their downstream utility on AITZ, AndroidControl, and AndroidWorld, we obtain three findings. First, renderable code reconstruction achieves high in-distribution fidelity and provides effective multimodal supervision for data construction, while text-based feedback is more robust for online out-of-distribution (OOD) execution. Second, world-model-generated trajectories can provide transferable interaction experience in the training process and improve agents' end-to-end task performance, although these data do not preserve the original distribution. Last, for overconfident mobile agents with low action entropy, posterior self-reflection provides limited gains, suggesting that world models are more effective as prior perception or training supervision than as universal post-hoc verifiers.
CoME: Empowering Channel-of-Mobile-Experts with Informative Hybrid-Capabilities Reasoning
Feb 27, 2026Mobile Agents can autonomously execute user instructions, which requires hybrid-capabilities reasoning, including screen summary, subtask planning, action decision and action function. However, existing agents struggle to achieve both decoupled enhancement and balanced integration of these capabilities. To address these challenges, we propose Channel-of-Mobile-Experts (CoME), a novel agent architecture consisting of four distinct experts, each aligned with a specific reasoning stage, CoME activates the corresponding expert to generate output tokens in each reasoning stage via output-oriented activation. To empower CoME with hybrid-capabilities reasoning, we introduce a progressive training strategy: Expert-FT enables decoupling and enhancement of different experts' capability; Router-FT aligns expert activation with the different reasoning stage; CoT-FT facilitates seamless collaboration and balanced optimization across multiple capabilities. To mitigate error propagation in hybrid-capabilities reasoning, we propose InfoGain-Driven DPO (Info-DPO), which uses information gain to evaluate the contribution of each intermediate step, thereby guiding CoME toward more informative reasoning. Comprehensive experiments show that CoME outperforms dense mobile agents and MoE methods on both AITZ and AMEX datasets.
Achieving Linear Speedup for Composite Federated Learning
Feb 03, 2026This paper proposes FedNMap, a normal map-based method for composite federated learning, where the objective consists of a smooth loss and a possibly nonsmooth regularizer. FedNMap leverages a normal map-based update scheme to handle the nonsmooth term and incorporates a local correction strategy to mitigate the impact of data heterogeneity across clients. Under standard assumptions, including smooth local losses, weak convexity of the regularizer, and bounded stochastic gradient variance, FedNMap achieves linear speedup with respect to both the number of clients $n$ and the number of local updates $Q$ for nonconvex losses, both with and without the Polyak-Łojasiewicz (PL) condition. To our knowledge, this is the first result establishing linear speedup for nonconvex composite federated learning.
Cross360: 360° Monocular Depth Estimation via Cross Projections Across Scales
Jan 24, 2026360° depth estimation is a challenging research problem due to the difficulty of finding a representation that both preserves global continuity and avoids distortion in spherical images. Existing methods attempt to leverage complementary information from multiple projections, but struggle with balancing global and local consistency. Their local patch features have limited global perception, and the combined global representation does not address discrepancies in feature extraction at the boundaries between patches. To address these issues, we propose Cross360, a novel cross-attention-based architecture integrating local and global information using less-distorted tangent patches along with equirectangular features. Our Cross Projection Feature Alignment module employs cross-attention to align local tangent projection features with the equirectangular projection's 360° field of view, ensuring each tangent projection patch is aware of the global context. Additionally, our Progressive Feature Aggregation with Attention module refines multi-scaled features progressively, enhancing depth estimation accuracy. Cross360 significantly outperforms existing methods across most benchmark datasets, especially those in which the entire 360° image is available, demonstrating its effectiveness in accurate and globally consistent depth estimation. The code and model are available at https://github.com/huangkun101230/Cross360.
The Llama 4 Herd: Architecture, Training, Evaluation, and Deployment Notes
Jan 15, 2026This document consolidates publicly reported technical details about Metas Llama 4 model family. It summarizes (i) released variants (Scout and Maverick) and the broader herd context including the previewed Behemoth teacher model, (ii) architectural characteristics beyond a high-level MoE description covering routed/shared-expert structure, early-fusion multimodality, and long-context design elements reported for Scout (iRoPE and length generalization strategies), (iii) training disclosures spanning pre-training, mid-training for long-context extension, and post-training methodology (lightweight SFT, online RL, and lightweight DPO) as described in release materials, (iv) developer-reported benchmark results for both base and instruction-tuned checkpoints, and (v) practical deployment constraints observed across major serving environments, including provider-specific context limits and quantization packaging. The manuscript also summarizes licensing obligations relevant to redistribution and derivative naming, and reviews publicly described safeguards and evaluation practices. The goal is to provide a compact technical reference for researchers and practitioners who need precise, source-backed facts about Llama 4.
DCMIL: A Progressive Representation Learning Model of Whole Slide Images for Cancer Prognosis Analysis
Oct 16, 2025The burgeoning discipline of computational pathology shows promise in harnessing whole slide images (WSIs) to quantify morphological heterogeneity and develop objective prognostic modes for human cancers. However, progress is impeded by the computational bottleneck of gigapixel-size inputs and the scarcity of dense manual annotations. Current methods often overlook fine-grained information across multi-magnification WSIs and variations in tumor microenvironments. Here, we propose an easy-to-hard progressive representation learning model, termed dual-curriculum contrastive multi-instance learning (DCMIL), to efficiently process WSIs for cancer prognosis. The model does not rely on dense annotations and enables the direct transformation of gigapixel-size WSIs into outcome predictions. Extensive experiments on twelve cancer types (5,954 patients, 12.54 million tiles) demonstrate that DCMIL outperforms standard WSI-based prognostic models. Additionally, DCMIL identifies fine-grained prognosis-salient regions, provides robust instance uncertainty estimation, and captures morphological differences between normal and tumor tissues, with the potential to generate new biological insights. All codes have been made publicly accessible at https://github.com/tuuuc/DCMIL.
APTOS-2024 challenge report: Generation of synthetic 3D OCT images from fundus photographs
Jun 09, 2025Optical Coherence Tomography (OCT) provides high-resolution, 3D, and non-invasive visualization of retinal layers in vivo, serving as a critical tool for lesion localization and disease diagnosis. However, its widespread adoption is limited by equipment costs and the need for specialized operators. In comparison, 2D color fundus photography offers faster acquisition and greater accessibility with less dependence on expensive devices. Although generative artificial intelligence has demonstrated promising results in medical image synthesis, translating 2D fundus images into 3D OCT images presents unique challenges due to inherent differences in data dimensionality and biological information between modalities. To advance generative models in the fundus-to-3D-OCT setting, the Asia Pacific Tele-Ophthalmology Society (APTOS-2024) organized a challenge titled Artificial Intelligence-based OCT Generation from Fundus Images. This paper details the challenge framework (referred to as APTOS-2024 Challenge), including: the benchmark dataset, evaluation methodology featuring two fidelity metrics-image-based distance (pixel-level OCT B-scan similarity) and video-based distance (semantic-level volumetric consistency), and analysis of top-performing solutions. The challenge attracted 342 participating teams, with 42 preliminary submissions and 9 finalists. Leading methodologies incorporated innovations in hybrid data preprocessing or augmentation (cross-modality collaborative paradigms), pre-training on external ophthalmic imaging datasets, integration of vision foundation models, and model architecture improvement. The APTOS-2024 Challenge is the first benchmark demonstrating the feasibility of fundus-to-3D-OCT synthesis as a potential solution for improving ophthalmic care accessibility in under-resourced healthcare settings, while helping to expedite medical research and clinical applications.
Enhance Mobile Agents Thinking Process Via Iterative Preference Learning
May 18, 2025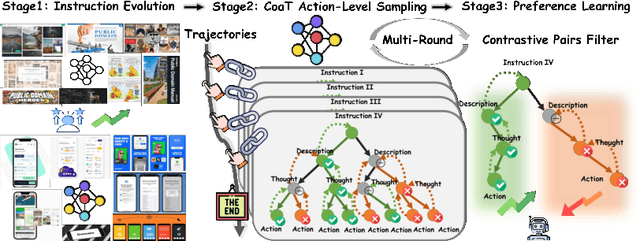
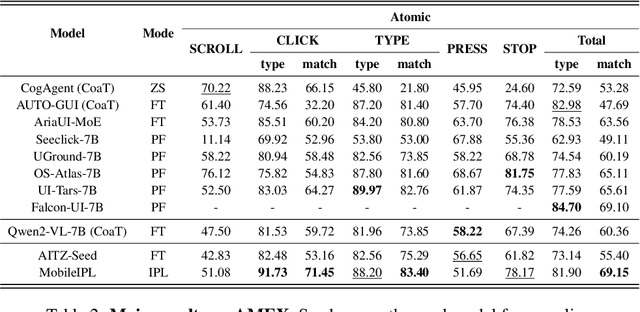
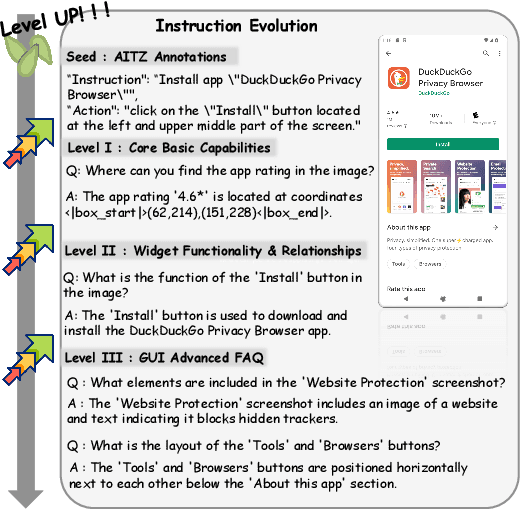
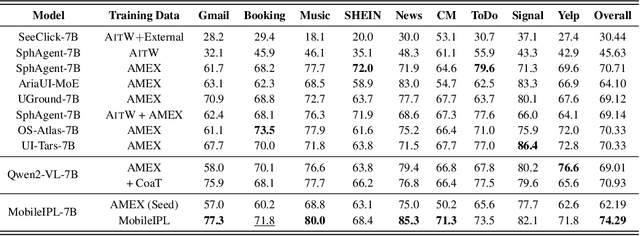
The Chain of Action-Planning Thoughts (CoaT) paradigm has been shown to improve the reasoning performance of VLM-based mobile agents in GUI tasks. However, the scarcity of diverse CoaT trajectories limits the expressiveness and generalization ability of such agents. While self-training is commonly employed to address data scarcity, existing approaches either overlook the correctness of intermediate reasoning steps or depend on expensive process-level annotations to construct process reward models (PRM). To address the above problems, we propose an Iterative Preference Learning (IPL) that constructs a CoaT-tree through interative sampling, scores leaf nodes using rule-based reward, and backpropagates feedback to derive Thinking-level Direct Preference Optimization (T-DPO) pairs. To prevent overfitting during warm-up supervised fine-tuning, we further introduce a three-stage instruction evolution, which leverages GPT-4o to generate diverse Q\&A pairs based on real mobile UI screenshots, enhancing both generality and layout understanding. Experiments on three standard Mobile GUI-agent benchmarks demonstrate that our agent MobileIPL outperforms strong baselines, including continual pretraining models such as OS-ATLAS and UI-TARS. It achieves state-of-the-art performance across three standard Mobile GUI-Agents benchmarks and shows strong generalization to out-of-domain scenarios.
OpenGV 2.0: Motion prior-assisted calibration and SLAM with vehicle-mounted surround-view systems
Mar 05, 2025

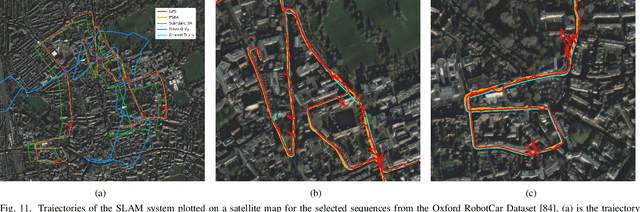
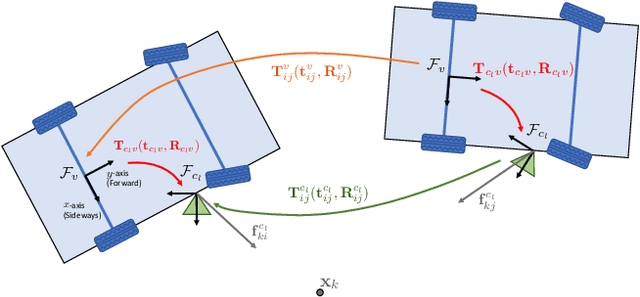
The present paper proposes optimization-based solutions to visual SLAM with a vehicle-mounted surround-view camera system. Owing to their original use-case, such systems often only contain a single camera facing into either direction and very limited overlap between fields of view. Our novelty consist of three optimization modules targeting at practical online calibration of exterior orientations from simple two-view geometry, reliable front-end initialization of relative displacements, and accurate back-end optimization using a continuous-time trajectory model. The commonality between the proposed modules is given by the fact that all three of them exploit motion priors that are related to the inherent non-holonomic characteristics of passenger vehicle motion. In contrast to prior related art, the proposed modules furthermore excel in terms of bypassing partial unobservabilities in the transformation variables that commonly occur for Ackermann-motion. As a further contribution, the modules are built into a novel surround-view camera SLAM system that specifically targets deployment on Ackermann vehicles operating in urban environments. All modules are studied in the context of in-depth ablation studies, and the practical validity of the entire framework is supported by a successful application to challenging, large-scale publicly available online datasets. Note that upon acceptance, the entire framework is scheduled for open-source release as part of an extension of the OpenGV library.
Multi-task Geometric Estimation of Depth and Surface Normal from Monocular 360° Images
Nov 04, 2024



Geometric estimation is required for scene understanding and analysis in panoramic 360{\deg} images. Current methods usually predict a single feature, such as depth or surface normal. These methods can lack robustness, especially when dealing with intricate textures or complex object surfaces. We introduce a novel multi-task learning (MTL) network that simultaneously estimates depth and surface normals from 360{\deg} images. Our first innovation is our MTL architecture, which enhances predictions for both tasks by integrating geometric information from depth and surface normal estimation, enabling a deeper understanding of 3D scene structure. Another innovation is our fusion module, which bridges the two tasks, allowing the network to learn shared representations that improve accuracy and robustness. Experimental results demonstrate that our MTL architecture significantly outperforms state-of-the-art methods in both depth and surface normal estimation, showing superior performance in complex and diverse scenes. Our model's effectiveness and generalizability, particularly in handling intricate surface textures, establish it as a new benchmark in 360{\deg} image geometric estimation. The code and model are available at \url{https://github.com/huangkun101230/360MTLGeometricEstimation}.