 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStyleMe3D: Stylization with Disentangled Priors by Multiple Encoders on 3D Gaussians
Apr 21, 20253D Gaussian Splatting (3DGS) excels in photorealistic scene reconstruction but struggles with stylized scenarios (e.g., cartoons, games) due to fragmented textures, semantic misalignment, and limited adaptability to abstract aesthetics. We propose StyleMe3D, a holistic framework for 3D GS style transfer that integrates multi-modal style conditioning, multi-level semantic alignment, and perceptual quality enhancement. Our key insights include: (1) optimizing only RGB attributes preserves geometric integrity during stylization; (2) disentangling low-, medium-, and high-level semantics is critical for coherent style transfer; (3) scalability across isolated objects and complex scenes is essential for practical deployment. StyleMe3D introduces four novel components: Dynamic Style Score Distillation (DSSD), leveraging Stable Diffusion's latent space for semantic alignment; Contrastive Style Descriptor (CSD) for localized, content-aware texture transfer; Simultaneously Optimized Scale (SOS) to decouple style details and structural coherence; and 3D Gaussian Quality Assessment (3DG-QA), a differentiable aesthetic prior trained on human-rated data to suppress artifacts and enhance visual harmony. Evaluated on NeRF synthetic dataset (objects) and tandt db (scenes) datasets, StyleMe3D outperforms state-of-the-art methods in preserving geometric details (e.g., carvings on sculptures) and ensuring stylistic consistency across scenes (e.g., coherent lighting in landscapes), while maintaining real-time rendering. This work bridges photorealistic 3D GS and artistic stylization, unlocking applications in gaming, virtual worlds, and digital art.
Leveraging Large Self-Supervised Time-Series Models for Transferable Diagnosis in Cross-Aircraft Type Bleed Air System
Apr 12, 2025



Bleed Air System (BAS) is critical for maintaining flight safety and operational efficiency, supporting functions such as cabin pressurization, air conditioning, and engine anti-icing. However, BAS malfunctions, including overpressure, low pressure, and overheating, pose significant risks such as cabin depressurization, equipment failure, or engine damage. Current diagnostic approaches face notable limitations when applied across different aircraft types, particularly for newer models that lack sufficient operational data. To address these challenges, this paper presents a self-supervised learning-based foundation model that enables the transfer of diagnostic knowledge from mature aircraft (e.g., A320, A330) to newer ones (e.g., C919). Leveraging self-supervised pretraining, the model learns universal feature representations from flight signals without requiring labeled data, making it effective in data-scarce scenarios. This model enhances both anomaly detection and baseline signal prediction, thereby improving system reliability. The paper introduces a cross-model dataset, a self-supervised learning framework for BAS diagnostics, and a novel Joint Baseline and Anomaly Detection Loss Function tailored to real-world flight data. These innovations facilitate efficient transfer of diagnostic knowledge across aircraft types, ensuring robust support for early operational stages of new models. Additionally, the paper explores the relationship between model capacity and transferability, providing a foundation for future research on large-scale flight signal models.
OmniSVG: A Unified Scalable Vector Graphics Generation Model
Apr 08, 2025
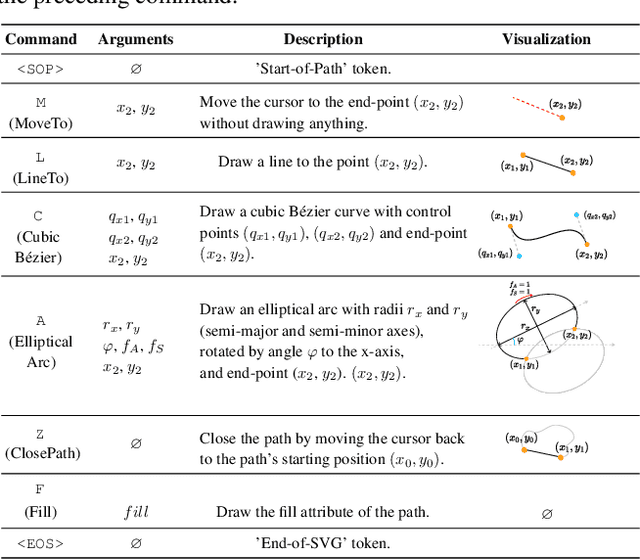


Scalable Vector Graphics (SVG) is an important image format widely adopted in graphic design because of their resolution independence and editability. The study of generating high-quality SVG has continuously drawn attention from both designers and researchers in the AIGC community. However, existing methods either produces unstructured outputs with huge computational cost or is limited to generating monochrome icons of over-simplified structures. To produce high-quality and complex SVG, we propose OmniSVG, a unified framework that leverages pre-trained Vision-Language Models (VLMs) for end-to-end multimodal SVG generation. By parameterizing SVG commands and coordinates into discrete tokens, OmniSVG decouples structural logic from low-level geometry for efficient training while maintaining the expressiveness of complex SVG structure. To further advance the development of SVG synthesis, we introduce MMSVG-2M, a multimodal dataset with two million richly annotated SVG assets, along with a standardized evaluation protocol for conditional SVG generation tasks. Extensive experiments show that OmniSVG outperforms existing methods and demonstrates its potential for integration into professional SVG design workflows.
FAVOR-Bench: A Comprehensive Benchmark for Fine-Grained Video Motion Understanding
Mar 19, 2025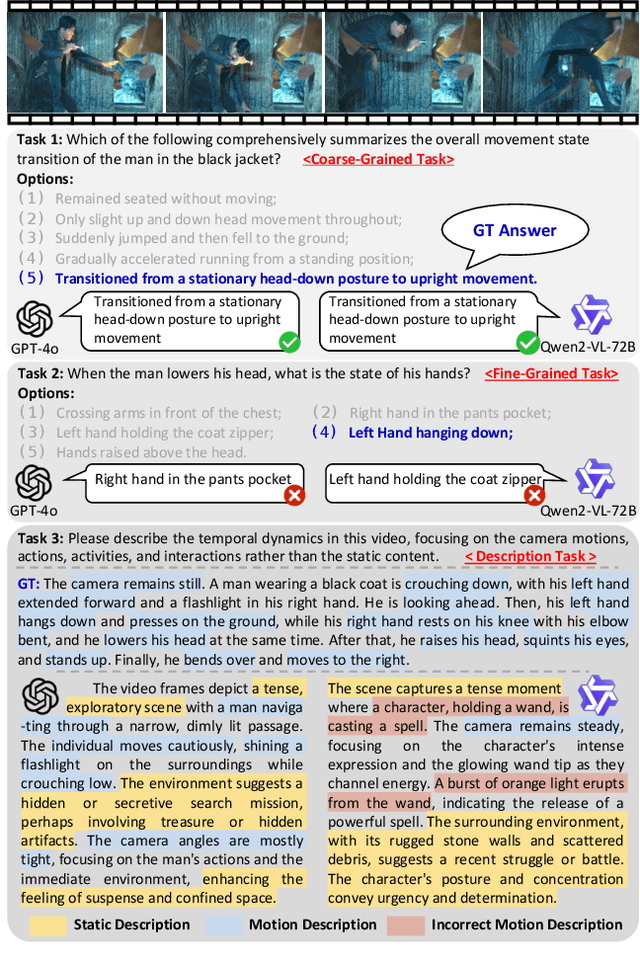

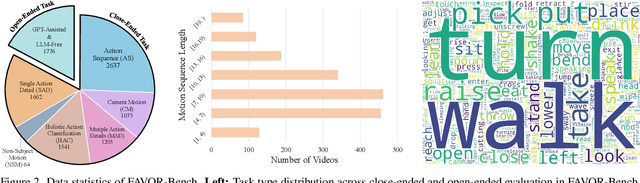
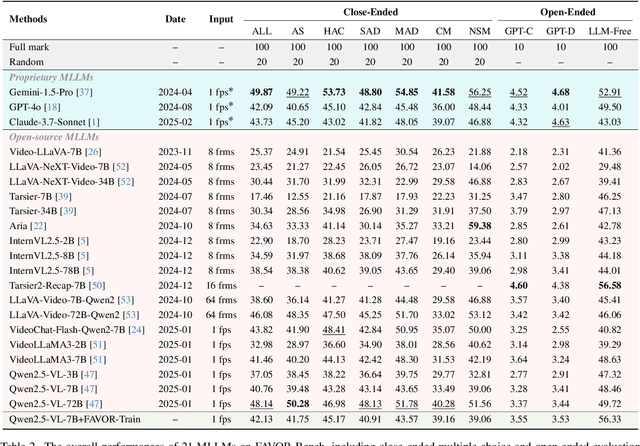
Multimodal Large Language Models (MLLMs) have shown remarkable capabilities in video content understanding but still struggle with fine-grained motion comprehension. To comprehensively assess the motion understanding ability of existing MLLMs, we introduce FAVOR-Bench, comprising 1,776 videos with structured manual annotations of various motions. Our benchmark includes both close-ended and open-ended tasks. For close-ended evaluation, we carefully design 8,184 multiple-choice question-answer pairs spanning six distinct sub-tasks. For open-ended evaluation, we develop both a novel cost-efficient LLM-free and a GPT-assisted caption assessment method, where the former can enhance benchmarking interpretability and reproducibility. Comprehensive experiments with 21 state-of-the-art MLLMs reveal significant limitations in their ability to comprehend and describe detailed temporal dynamics in video motions. To alleviate this limitation, we further build FAVOR-Train, a dataset consisting of 17,152 videos with fine-grained motion annotations. The results of finetuning Qwen2.5-VL on FAVOR-Train yield consistent improvements on motion-related tasks of TVBench, MotionBench and our FAVOR-Bench. Comprehensive assessment results demonstrate that the proposed FAVOR-Bench and FAVOR-Train provide valuable tools to the community for developing more powerful video understanding models. Project page: \href{https://favor-bench.github.io/}{https://favor-bench.github.io/}.
Explainable Multi-modal Time Series Prediction with LLM-in-the-Loop
Mar 02, 2025



Time series analysis provides essential insights for real-world system dynamics and informs downstream decision-making, yet most existing methods often overlook the rich contextual signals present in auxiliary modalities. To bridge this gap, we introduce TimeXL, a multi-modal prediction framework that integrates a prototype-based time series encoder with three collaborating Large Language Models (LLMs) to deliver more accurate predictions and interpretable explanations. First, a multi-modal prototype-based encoder processes both time series and textual inputs to generate preliminary forecasts alongside case-based rationales. These outputs then feed into a prediction LLM, which refines the forecasts by reasoning over the encoder's predictions and explanations. Next, a reflection LLM compares the predicted values against the ground truth, identifying textual inconsistencies or noise. Guided by this feedback, a refinement LLM iteratively enhances text quality and triggers encoder retraining. This closed-loop workflow -- prediction, critique (reflect), and refinement -- continuously boosts the framework's performance and interpretability. Empirical evaluations on four real-world datasets demonstrate that TimeXL achieves up to 8.9\% improvement in AUC and produces human-centric, multi-modal explanations, highlighting the power of LLM-driven reasoning for time series prediction.
DISC: Dynamic Decomposition Improves LLM Inference Scaling
Feb 23, 2025Many inference scaling methods work by breaking a problem into smaller steps (or groups of tokens), then sampling and choosing the best next step. However, these steps and their sizes are usually predetermined based on human intuition or domain knowledge. This paper introduces dynamic decomposition, a method that automatically and adaptively splits solution and reasoning traces into steps during inference. This approach improves computational efficiency by focusing more resources on difficult steps, breaking them down further and prioritizing their sampling. Experiments on coding and math benchmarks (APPS, MATH, and LiveCodeBench) show that dynamic decomposition performs better than static methods, which rely on fixed steps like token-level, sentence-level, or single-step decompositions. These results suggest that dynamic decomposition can enhance many inference scaling techniques.
Baichuan-M1: Pushing the Medical Capability of Large Language Models
Feb 18, 2025



The current generation of large language models (LLMs) is typically designed for broad, general-purpose applications, while domain-specific LLMs, especially in vertical fields like medicine, remain relatively scarce. In particular, the development of highly efficient and practical LLMs for the medical domain is challenging due to the complexity of medical knowledge and the limited availability of high-quality data. To bridge this gap, we introduce Baichuan-M1, a series of large language models specifically optimized for medical applications. Unlike traditional approaches that simply continue pretraining on existing models or apply post-training to a general base model, Baichuan-M1 is trained from scratch with a dedicated focus on enhancing medical capabilities. Our model is trained on 20 trillion tokens and incorporates a range of effective training methods that strike a balance between general capabilities and medical expertise. As a result, Baichuan-M1 not only performs strongly across general domains such as mathematics and coding but also excels in specialized medical fields. We have open-sourced Baichuan-M1-14B, a mini version of our model, which can be accessed through the following links.
TimeCAP: Learning to Contextualize, Augment, and Predict Time Series Events with Large Language Model Agents
Feb 17, 2025Time series data is essential in various applications, including climate modeling, healthcare monitoring, and financial analytics. Understanding the contextual information associated with real-world time series data is often essential for accurate and reliable event predictions. In this paper, we introduce TimeCAP, a time-series processing framework that creatively employs Large Language Models (LLMs) as contextualizers of time series data, extending their typical usage as predictors. TimeCAP incorporates two independent LLM agents: one generates a textual summary capturing the context of the time series, while the other uses this enriched summary to make more informed predictions. In addition, TimeCAP employs a multi-modal encoder that synergizes with the LLM agents, enhancing predictive performance through mutual augmentation of inputs with in-context examples. Experimental results on real-world datasets demonstrate that TimeCAP outperforms state-of-the-art methods for time series event prediction, including those utilizing LLMs as predictors, achieving an average improvement of 28.75% in F1 score.
Harnessing Vision Models for Time Series Analysis: A Survey
Feb 13, 2025



Time series analysis has witnessed the inspiring development from traditional autoregressive models, deep learning models, to recent Transformers and Large Language Models (LLMs). Efforts in leveraging vision models for time series analysis have also been made along the way but are less visible to the community due to the predominant research on sequence modeling in this domain. However, the discrepancy between continuous time series and the discrete token space of LLMs, and the challenges in explicitly modeling the correlations of variates in multivariate time series have shifted some research attentions to the equally successful Large Vision Models (LVMs) and Vision Language Models (VLMs). To fill the blank in the existing literature, this survey discusses the advantages of vision models over LLMs in time series analysis. It provides a comprehensive and in-depth overview of the existing methods, with dual views of detailed taxonomy that answer the key research questions including how to encode time series as images and how to model the imaged time series for various tasks. Additionally, we address the challenges in the pre- and post-processing steps involved in this framework and outline future directions to further advance time series analysis with vision models.
ChorusCVR: Chorus Supervision for Entire Space Post-Click Conversion Rate Modeling
Feb 12, 2025



Post-click conversion rate (CVR) estimation is a vital task in many recommender systems of revenue businesses, e.g., e-commerce and advertising. In a perspective of sample, a typical CVR positive sample usually goes through a funnel of exposure to click to conversion. For lack of post-event labels for un-clicked samples, CVR learning task commonly only utilizes clicked samples, rather than all exposed samples as for click-through rate (CTR) learning task. However, during online inference, CVR and CTR are estimated on the same assumed exposure space, which leads to a inconsistency of sample space between training and inference, i.e., sample selection bias (SSB). To alleviate SSB, previous wisdom proposes to design novel auxiliary tasks to enable the CVR learning on un-click training samples, such as CTCVR and counterfactual CVR, etc. Although alleviating SSB to some extent, none of them pay attention to the discrimination between ambiguous negative samples (un-clicked) and factual negative samples (clicked but un-converted) during modelling, which makes CVR model lacks robustness. To full this gap, we propose a novel ChorusCVR model to realize debiased CVR learning in entire-space.