 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeveraging Large Self-Supervised Time-Series Models for Transferable Diagnosis in Cross-Aircraft Type Bleed Air System
Apr 12, 2025



Bleed Air System (BAS) is critical for maintaining flight safety and operational efficiency, supporting functions such as cabin pressurization, air conditioning, and engine anti-icing. However, BAS malfunctions, including overpressure, low pressure, and overheating, pose significant risks such as cabin depressurization, equipment failure, or engine damage. Current diagnostic approaches face notable limitations when applied across different aircraft types, particularly for newer models that lack sufficient operational data. To address these challenges, this paper presents a self-supervised learning-based foundation model that enables the transfer of diagnostic knowledge from mature aircraft (e.g., A320, A330) to newer ones (e.g., C919). Leveraging self-supervised pretraining, the model learns universal feature representations from flight signals without requiring labeled data, making it effective in data-scarce scenarios. This model enhances both anomaly detection and baseline signal prediction, thereby improving system reliability. The paper introduces a cross-model dataset, a self-supervised learning framework for BAS diagnostics, and a novel Joint Baseline and Anomaly Detection Loss Function tailored to real-world flight data. These innovations facilitate efficient transfer of diagnostic knowledge across aircraft types, ensuring robust support for early operational stages of new models. Additionally, the paper explores the relationship between model capacity and transferability, providing a foundation for future research on large-scale flight signal models.
A Nerf-Based Color Consistency Method for Remote Sensing Images
Nov 08, 2024



Due to different seasons, illumination, and atmospheric conditions, the photometric of the acquired image varies greatly, which leads to obvious stitching seams at the edges of the mosaic image. Traditional methods can be divided into two categories, one is absolute radiation correction and the other is relative radiation normalization. We propose a NeRF-based method of color consistency correction for multi-view images, which weaves image features together using implicit expressions, and then re-illuminates feature space to generate a fusion image with a new perspective. We chose Superview-1 satellite images and UAV images with large range and time difference for the experiment. Experimental results show that the synthesize image generated by our method has excellent visual effect and smooth color transition at the edges.
RmGPT: Rotating Machinery Generative Pretrained Model
Sep 26, 2024



In industry, the reliability of rotating machinery is critical for production efficiency and safety. Current methods of Prognostics and Health Management (PHM) often rely on task-specific models, which face significant challenges in handling diverse datasets with varying signal characteristics, fault modes and operating conditions. Inspired by advancements in generative pretrained models, we propose RmGPT, a unified model for diagnosis and prognosis tasks. RmGPT introduces a novel token-based framework, incorporating Signal Tokens, Prompt Tokens, Time-Frequency Task Tokens and Fault Tokens to handle heterogeneous data within a unified model architecture. We leverage self-supervised learning for robust feature extraction and introduce a next signal token prediction pretraining strategy, alongside efficient prompt learning for task-specific adaptation. Extensive experiments demonstrate that RmGPT significantly outperforms state-of-the-art algorithms, achieving near-perfect accuracy in diagnosis tasks and exceptionally low errors in prognosis tasks. Notably, RmGPT excels in few-shot learning scenarios, achieving 92% accuracy in 16-class one-shot experiments, highlighting its adaptability and robustness. This work establishes RmGPT as a powerful PHM foundation model for rotating machinery, advancing the scalability and generalizability of PHM solutions.
Efficient Stochastic Differential Equation for DEM Super Resolution with Void Filling
Jul 02, 2024Digital Elevation Model (DEM) plays a fundamental role in remote sensing and photogrammetry. Enhancing the quality of DEM is crucial for various applications. Although multiple types of defects may appear simultaneously in the same DEM, they are commonly addressed separately. Most existing approaches only aim to fill the DEM voids, or apply super-resolution to the intact DEM. This paper introduces a unified generative model that simultaneously addresses voids and low-resolution problems, rather than taking two separate measures. The proposed approach presents the DEM Stochastic Differential Equation (DEM-SDE) for unified DEM quality enhancement. The DEM degradation of downsampling and random voids adding is modeled as the SDE forwarding, and the restoration is achieved by simulating the corresponding revert process. Conditioned on the terrain feature, and adopting efficient submodules with lightweight channel attention, DEM-SDE simultaneously enhances the DEM quality with an efficient process for training. The experiments show that DEM-SDE method achieves highly competitive performance in simultaneous super-resolution and void filling compared to the state-of-the-art work. DEM-SDE also manifests robustness for larger DEM patches.
psPRF:Pansharpening Planar Neural Radiance Field for Generalized 3D Reconstruction Satellite Imagery
Jun 22, 2024Most current NeRF variants for satellites are designed for one specific scene and fall short of generalization to new geometry. Additionally, the RGB images require pan-sharpening as an independent preprocessing step. This paper introduces psPRF, a Planar Neural Radiance Field designed for paired low-resolution RGB (LR-RGB) and high-resolution panchromatic (HR-PAN) images from satellite sensors with Rational Polynomial Cameras (RPC). To capture the cross-modal prior from both of the LR-RGB and HR-PAN images, for the Unet-shaped architecture, we adapt the encoder with explicit spectral-to-spatial convolution (SSConv) to enhance the multimodal representation ability. To support the generalization ability of psRPF across scenes, we adopt projection loss to ensure strong geometry self-supervision. The proposed method is evaluated with the multi-scene WorldView-3 LR-RGB and HR-PAN pairs, and achieves state-of-the-art performance.
Deep Extrinsic Manifold Representation for Vision Tasks
Mar 31, 2024



Non-Euclidean data is frequently encountered across different fields, yet there is limited literature that addresses the fundamental challenge of training neural networks with manifold representations as outputs. We introduce the trick named Deep Extrinsic Manifold Representation (DEMR) for visual tasks in this context. DEMR incorporates extrinsic manifold embedding into deep neural networks, which helps generate manifold representations. The DEMR approach does not directly optimize the complex geodesic loss. Instead, it focuses on optimizing the computation graph within the embedded Euclidean space, allowing for adaptability to various architectural requirements. We provide empirical evidence supporting the proposed concept on two types of manifolds, $SE(3)$ and its associated quotient manifolds. This evidence offers theoretical assurances regarding feasibility, asymptotic properties, and generalization capability. The experimental results show that DEMR effectively adapts to point cloud alignment, producing outputs in $ SE(3) $, as well as in illumination subspace learning with outputs on the Grassmann manifold.
rpcPRF: Generalizable MPI Neural Radiance Field for Satellite Camera
Oct 11, 2023



Novel view synthesis of satellite images holds a wide range of practical applications. While recent advances in the Neural Radiance Field have predominantly targeted pin-hole cameras, and models for satellite cameras often demand sufficient input views. This paper presents rpcPRF, a Multiplane Images (MPI) based Planar neural Radiance Field for Rational Polynomial Camera (RPC). Unlike coordinate-based neural radiance fields in need of sufficient views of one scene, our model is applicable to single or few inputs and performs well on images from unseen scenes. To enable generalization across scenes, we propose to use reprojection supervision to induce the predicted MPI to learn the correct geometry between the 3D coordinates and the images. Moreover, we remove the stringent requirement of dense depth supervision from deep multiview-stereo-based methods by introducing rendering techniques of radiance fields. rpcPRF combines the superiority of implicit representations and the advantages of the RPC model, to capture the continuous altitude space while learning the 3D structure. Given an RGB image and its corresponding RPC, the end-to-end model learns to synthesize the novel view with a new RPC and reconstruct the altitude of the scene. When multiple views are provided as inputs, rpcPRF exerts extra supervision provided by the extra views. On the TLC dataset from ZY-3, and the SatMVS3D dataset with urban scenes from WV-3, rpcPRF outperforms state-of-the-art nerf-based methods by a significant margin in terms of image fidelity, reconstruction accuracy, and efficiency, for both single-view and multiview task.
Fast Satellite Tensorial Radiance Field for Multi-date Satellite Imagery of Large Size
Sep 21, 2023



Existing NeRF models for satellite images suffer from slow speeds, mandatory solar information as input, and limitations in handling large satellite images. In response, we present SatensoRF, which significantly accelerates the entire process while employing fewer parameters for satellite imagery of large size. Besides, we observed that the prevalent assumption of Lambertian surfaces in neural radiance fields falls short for vegetative and aquatic elements. In contrast to the traditional hierarchical MLP-based scene representation, we have chosen a multiscale tensor decomposition approach for color, volume density, and auxiliary variables to model the lightfield with specular color. Additionally, to rectify inconsistencies in multi-date imagery, we incorporate total variation loss to restore the density tensor field and treat the problem as a denosing task.To validate our approach, we conducted assessments of SatensoRF using subsets from the spacenet multi-view dataset, which includes both multi-date and single-date multi-view RGB images. Our results clearly demonstrate that SatensoRF surpasses the state-of-the-art Sat-NeRF series in terms of novel view synthesis performance. Significantly, SatensoRF requires fewer parameters for training, resulting in faster training and inference speeds and reduced computational demands.
Learning Robust and Lightweight Model through Separable Structured Transformations
Dec 29, 2021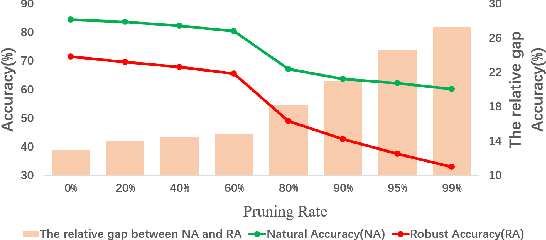

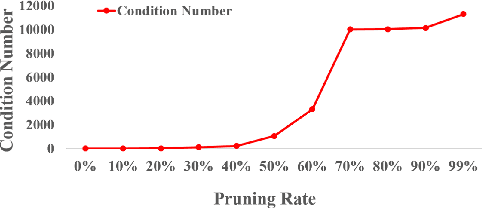
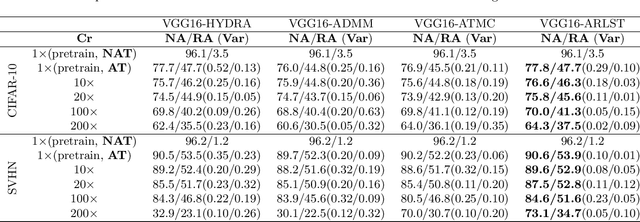
With the proliferation of mobile devices and the Internet of Things, deep learning models are increasingly deployed on devices with limited computing resources and memory, and are exposed to the threat of adversarial noise. Learning deep models with both lightweight and robustness is necessary for these equipments. However, current deep learning solutions are difficult to learn a model that possesses these two properties without degrading one or the other. As is well known, the fully-connected layers contribute most of the parameters of convolutional neural networks. We perform a separable structural transformation of the fully-connected layer to reduce the parameters, where the large-scale weight matrix of the fully-connected layer is decoupled by the tensor product of several separable small-sized matrices. Note that data, such as images, no longer need to be flattened before being fed to the fully-connected layer, retaining the valuable spatial geometric information of the data. Moreover, in order to further enhance both lightweight and robustness, we propose a joint constraint of sparsity and differentiable condition number, which is imposed on these separable matrices. We evaluate the proposed approach on MLP, VGG-16 and Vision Transformer. The experimental results on datasets such as ImageNet, SVHN, CIFAR-100 and CIFAR10 show that we successfully reduce the amount of network parameters by 90%, while the robust accuracy loss is less than 1.5%, which is better than the SOTA methods based on the original fully-connected layer. Interestingly, it can achieve an overwhelming advantage even at a high compression rate, e.g., 200 times.
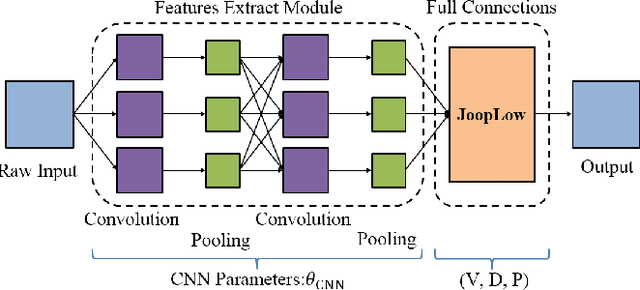
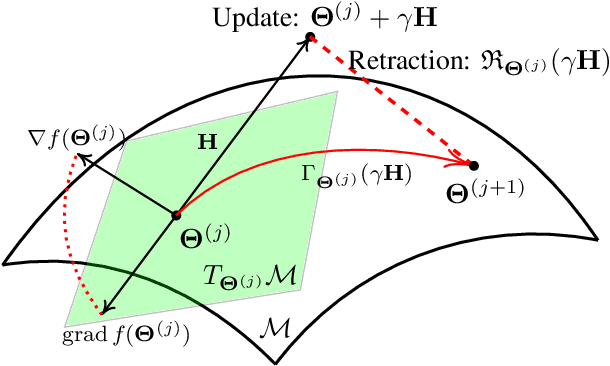
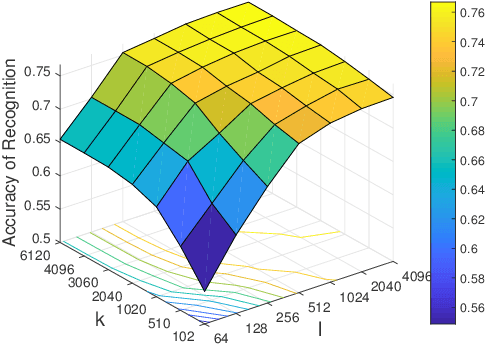
Joint Learning of Discriminative Low-dimensional Image Representations Based on Dictionary Learning and Two-layer Orthogonal Projections
Mar 27, 2019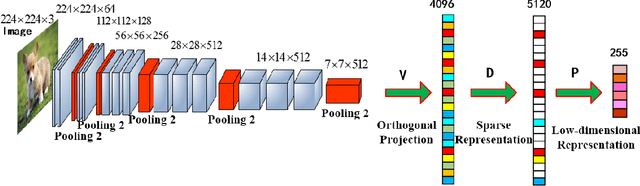
There are some inadequacies in the language description of this paper that require further improvement. This paper is based on a revision of a conference paper. It is now necessary to further explain the difference between the contributions of the two papers.