 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSimple multi-dataset detection
Feb 25, 2021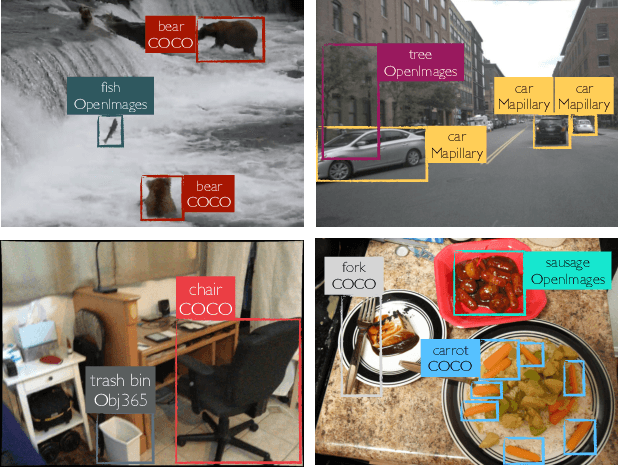
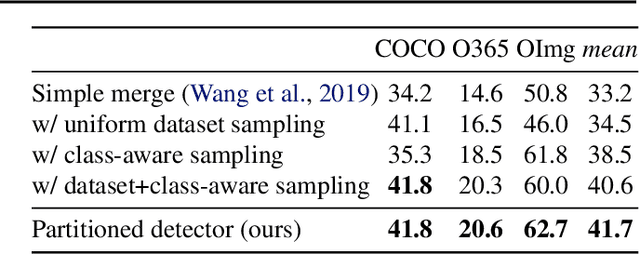
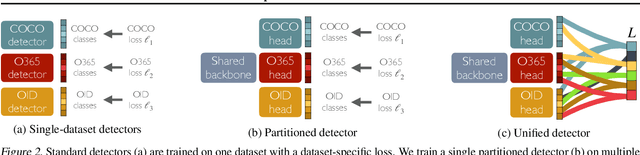
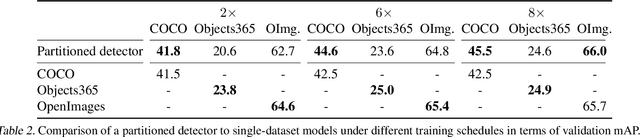
How do we build a general and broad object detection system? We use all labels of all concepts ever annotated. These labels span diverse datasets with potentially inconsistent taxonomies. In this paper, we present a simple method for training a unified detector on multiple large-scale datasets. We use dataset-specific training protocols and losses, but share a common detection architecture with dataset-specific outputs. We show how to automatically integrate these dataset-specific outputs into a common semantic taxonomy. In contrast to prior work, our approach does not require manual taxonomy reconciliation. Our multi-dataset detector performs as well as dataset-specific models on each training domain, but generalizes much better to new unseen domains. Entries based on the presented methodology ranked first in the object detection and instance segmentation tracks of the ECCV 2020 Robust Vision Challenge.
Point Transformer
Dec 16, 2020
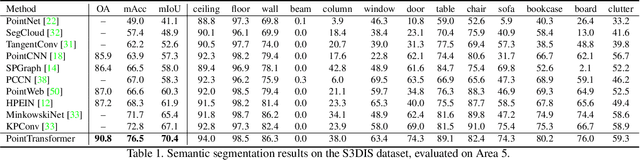
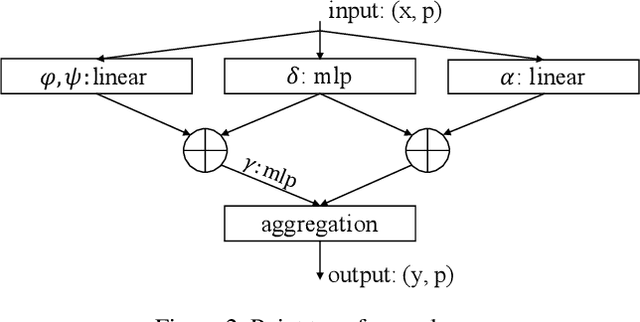
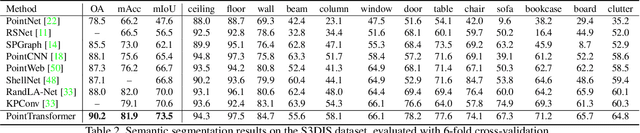
Self-attention networks have revolutionized natural language processing and are making impressive strides in image analysis tasks such as image classification and object detection. Inspired by this success, we investigate the application of self-attention networks to 3D point cloud processing. We design self-attention layers for point clouds and use these to construct self-attention networks for tasks such as semantic scene segmentation, object part segmentation, and object classification. Our Point Transformer design improves upon prior work across domains and tasks. For example, on the challenging S3DIS dataset for large-scale semantic scene segmentation, the Point Transformer attains an mIoU of 70.4% on Area 5, outperforming the strongest prior model by 3.3 absolute percentage points and crossing the 70% mIoU threshold for the first time.
Stable View Synthesis
Nov 14, 2020

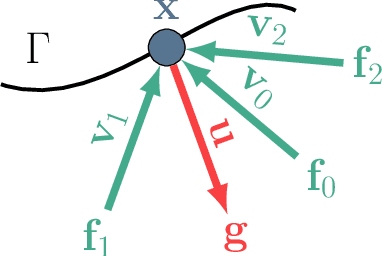
We present Stable View Synthesis (SVS). Given a set of source images depicting a scene from freely distributed viewpoints, SVS synthesizes new views of the scene. The method operates on a geometric scaffold computed via structure-from-motion and multi-view stereo. Each point on this 3D scaffold is associated with view rays and corresponding feature vectors that encode the appearance of this point in the input images. The core of SVS is view-dependent on-surface feature aggregation, in which directional feature vectors at each 3D point are processed to produce a new feature vector for a ray that maps this point into the new target view. The target view is then rendered by a convolutional network from a tensor of features synthesized in this way for all pixels. The method is composed of differentiable modules and is trained end-to-end. It supports spatially-varying view-dependent importance weighting and feature transformation of source images at each point; spatial and temporal stability due to the smooth dependence of on-surface feature aggregation on the target view; and synthesis of view-dependent effects such as specular reflection. Experimental results demonstrate that SVS outperforms state-of-the-art view synthesis methods both quantitatively and qualitatively on three diverse real-world datasets, achieving unprecedented levels of realism in free-viewpoint video of challenging large-scale scenes.
Rearrangement: A Challenge for Embodied AI
Nov 03, 2020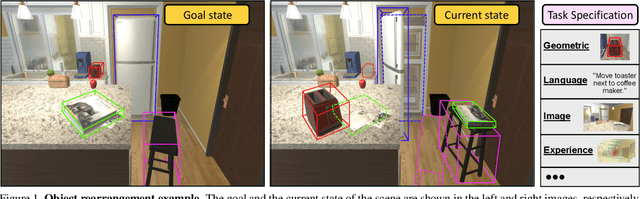
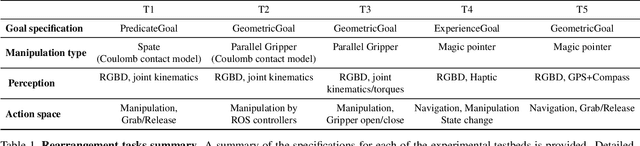


We describe a framework for research and evaluation in Embodied AI. Our proposal is based on a canonical task: Rearrangement. A standard task can focus the development of new techniques and serve as a source of trained models that can be transferred to other settings. In the rearrangement task, the goal is to bring a given physical environment into a specified state. The goal state can be specified by object poses, by images, by a description in language, or by letting the agent experience the environment in the goal state. We characterize rearrangement scenarios along different axes and describe metrics for benchmarking rearrangement performance. To facilitate research and exploration, we present experimental testbeds of rearrangement scenarios in four different simulation environments. We anticipate that other datasets will be released and new simulation platforms will be built to support training of rearrangement agents and their deployment on physical systems.
Learning Quadrupedal Locomotion over Challenging Terrain
Oct 21, 2020Some of the most challenging environments on our planet are accessible to quadrupedal animals but remain out of reach for autonomous machines. Legged locomotion can dramatically expand the operational domains of robotics. However, conventional controllers for legged locomotion are based on elaborate state machines that explicitly trigger the execution of motion primitives and reflexes. These designs have escalated in complexity while falling short of the generality and robustness of animal locomotion. Here we present a radically robust controller for legged locomotion in challenging natural environments. We present a novel solution to incorporating proprioceptive feedback in locomotion control and demonstrate remarkable zero-shot generalization from simulation to natural environments. The controller is trained by reinforcement learning in simulation. It is based on a neural network that acts on a stream of proprioceptive signals. The trained controller has taken two generations of quadrupedal ANYmal robots to a variety of natural environments that are beyond the reach of prior published work in legged locomotion. The controller retains its robustness under conditions that have never been encountered during training: deformable terrain such as mud and snow, dynamic footholds such as rubble, and overground impediments such as thick vegetation and gushing water. The presented work opens new frontiers for robotics and indicates that radical robustness in natural environments can be achieved by training in much simpler domains.
NeRF++: Analyzing and Improving Neural Radiance Fields
Oct 21, 2020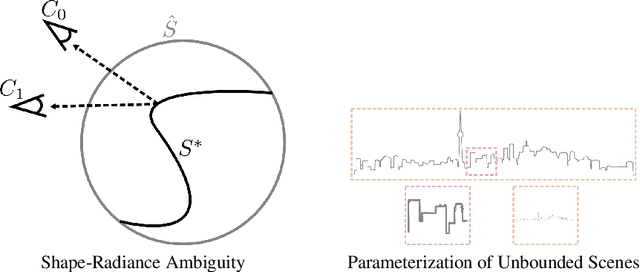


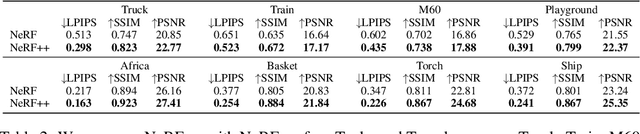
Neural Radiance Fields (NeRF) achieve impressive view synthesis results for a variety of capture settings, including 360 capture of bounded scenes and forward-facing capture of bounded and unbounded scenes. NeRF fits multi-layer perceptrons (MLPs) representing view-invariant opacity and view-dependent color volumes to a set of training images, and samples novel views based on volume rendering techniques. In this technical report, we first remark on radiance fields and their potential ambiguities, namely the shape-radiance ambiguity, and analyze NeRF's success in avoiding such ambiguities. Second, we address a parametrization issue involved in applying NeRF to 360 captures of objects within large-scale, unbounded 3D scenes. Our method improves view synthesis fidelity in this challenging scenario. Code is available at https://github.com/Kai-46/nerfplusplus.
OpenBot: Turning Smartphones into Robots
Aug 24, 2020
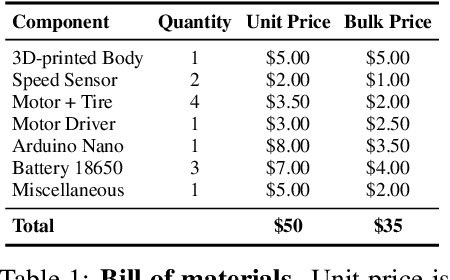
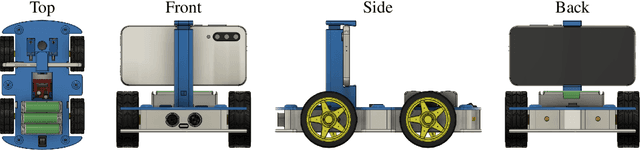
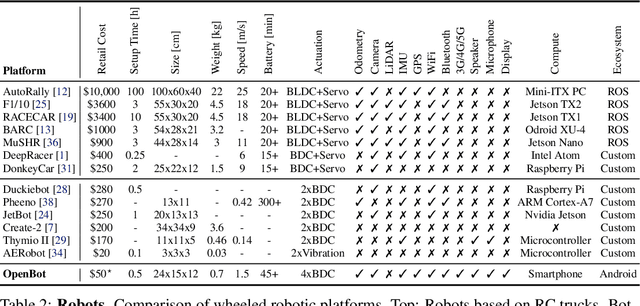
Current robots are either expensive or make significant compromises on sensory richness, computational power, and communication capabilities. We propose to leverage smartphones to equip robots with extensive sensor suites, powerful computational abilities, state-of-the-art communication channels, and access to a thriving software ecosystem. We design a small electric vehicle that costs $50 and serves as a robot body for standard Android smartphones. We develop a software stack that allows smartphones to use this body for mobile operation and demonstrate that the system is sufficiently powerful to support advanced robotics workloads such as person following and real-time autonomous navigation in unstructured environments. Controlled experiments demonstrate that the presented approach is robust across different smartphones and robot bodies. A video of our work is available at https://www.youtube.com/watch?v=qc8hFLyWDOM
Free View Synthesis
Aug 12, 2020
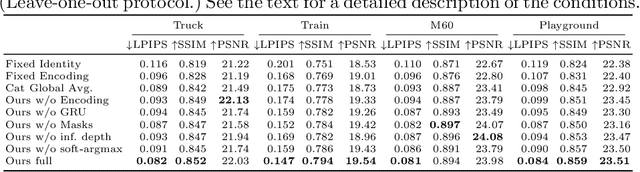

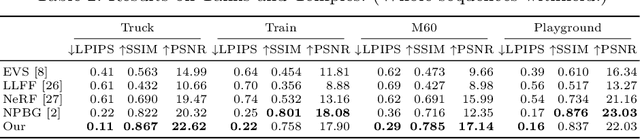
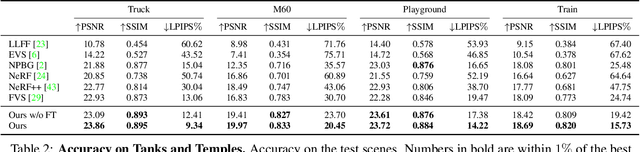
We present a method for novel view synthesis from input images that are freely distributed around a scene. Our method does not rely on a regular arrangement of input views, can synthesize images for free camera movement through the scene, and works for general scenes with unconstrained geometric layouts. We calibrate the input images via SfM and erect a coarse geometric scaffold via MVS. This scaffold is used to create a proxy depth map for a novel view of the scene. Based on this depth map, a recurrent encoder-decoder network processes reprojected features from nearby views and synthesizes the new view. Our network does not need to be optimized for a given scene. After training on a dataset, it works in previously unseen environments with no fine-tuning or per-scene optimization. We evaluate the presented approach on challenging real-world datasets, including Tanks and Temples, where we demonstrate successful view synthesis for the first time and substantially outperform prior and concurrent work.
Drinking from a Firehose: Continual Learning with Web-scale Natural Language
Jul 18, 2020

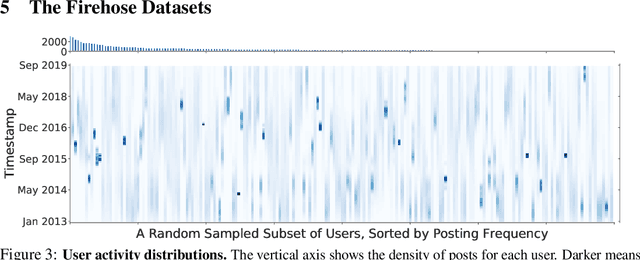

Continual learning systems will interact with humans, with each other, and with the physical world through time -- and continue to learn and adapt as they do. Such systems have typically been evaluated in artificial settings: for example, classifying randomly permuted images. A key limitation of these settings is the unnatural construct of discrete, sharply demarcated tasks that are solved in sequence. In this paper, we study a natural setting for continual learning on a massive scale. We introduce the problem of personalized online language learning (POLL), which involves fitting personalized language models to a population of users that evolves over time. To facilitate research on POLL, we collect massive datasets of Twitter posts. These datasets, Firehose10M and Firehose100M, comprise 100 million tweets, posted by one million users over six years. Enabled by the Firehose datasets, we present a rigorous evaluation of continual learning algorithms on an unprecedented scale. Based on this analysis, we develop a simple algorithm for continual gradient descent (ConGraD) that outperforms prior continual learning methods on the Firehose datasets as well as earlier benchmarks. Collectively, the POLL problem setting, the Firehose datasets, and the ConGraD algorithm enable reproducible research on web-scale continual learning.
Dynamic Low-light Imaging with Quanta Image Sensors
Jul 16, 2020
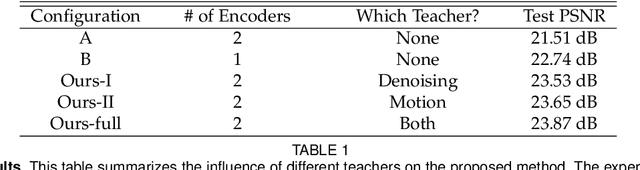


Imaging in low light is difficult because the number of photons arriving at the sensor is low. Imaging dynamic scenes in low-light environments is even more difficult because as the scene moves, pixels in adjacent frames need to be aligned before they can be denoised. Conventional CMOS image sensors (CIS) are at a particular disadvantage in dynamic low-light settings because the exposure cannot be too short lest the read noise overwhelms the signal. We propose a solution using Quanta Image Sensors (QIS) and present a new image reconstruction algorithm. QIS are single-photon image sensors with photon counting capabilities. Studies over the past decade have confirmed the effectiveness of QIS for low-light imaging but reconstruction algorithms for dynamic scenes in low light remain an open problem. We fill the gap by proposing a student-teacher training protocol that transfers knowledge from a motion teacher and a denoising teacher to a student network. We show that dynamic scenes can be reconstructed from a burst of frames at a photon level of 1 photon per pixel per frame. Experimental results confirm the advantages of the proposed method compared to existing methods.