 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptiWorld: Optimal Control for Video World Generation under Physical Constraints
May 30, 2026Video generation models are becoming a scalable form of world models, but they mainly generate plausible motion rather than proactively control or optimize the underlying dynamics. As a result, an object in the generated video may follow trajectories that are unsafe, not smooth, inefficient, or physically inconsistent. In this work, we propose \textbf{OptiWorld}, a framework that brings classical optimal control into video generation at inference time. OptiWorld first extracts a compact, task-relevant world state, then plans an optimal trajectory under physical constraints, and finally renders the video conditioned on this trajectory. We formulate planning as a geometric problem on a continuous manifold, which converts 3D geometry and task-dependent physical constraints into a unified planning geometry. By adding this optimal-control layer, OptiWorld generates videos with preferable dynamics, demonstrating strong potential in multiple tasks including goal-conditioned image-to-video generation, video dynamics editing, and counterfactual generation.
Pupil Design for Computational Wavefront Estimation
Mar 31, 2026Establishing a precise connection between imaged intensity and the incident wavefront is essential for emerging applications in adaptive optics, holography, computational microscopy, and non-line-of-sight imaging. While prior work has shown that breaking symmetries in pupil design enables wavefront recovery from a single intensity measurement, there is little guidance on how to design a pupil that improves wavefront estimation. In this work we introduce a quantitative asymmetry metric to bridge this gap and, through an extensive empirical study and supporting analysis, demonstrate that increasing asymmetry enhances wavefront recoverability. We analyze the trade-offs in pupil design, and the impact on light throughput along with performance in noise. Both large-scale simulations and optical bench experiments are carried out to support our findings.
Practical Geometric and Quantum Kernel Methods for Predicting Skeletal Muscle Outcomes in chronic obstructive pulmonary disease
Jan 01, 2026Skeletal muscle dysfunction is a clinically relevant extra-pulmonary manifestation of chronic obstructive pulmonary disease (COPD) and is closely linked to systemic and airway inflammation. This motivates predictive modelling of muscle outcomes from minimally invasive biomarkers that can be acquired longitudinally. We study a small-sample preclinical dataset comprising 213 animals across two conditions (Sham versus cigarette-smoke exposure), with blood and bronchoalveolar lavage fluid measurements and three continuous targets: tibialis anterior muscle weight (milligram: mg), specific force (millinewton: mN), and a derived muscle quality index (mN per mg). We benchmark tuned classical baselines, geometry-aware symmetric positive definite (SPD) descriptors with Stein divergence, and quantum kernel models designed for low-dimensional tabular data. In the muscle-weight setting, quantum kernel ridge regression using four interpretable inputs (blood C-reactive protein, neutrophil count, bronchoalveolar lavage cellularity, and condition) attains a test root mean squared error of 4.41 mg and coefficient of determination of 0.605, improving over a matched ridge baseline on the same feature set (4.70 mg and 0.553). Geometry-informed Stein-divergence prototype distances yield a smaller but consistent gain in the biomarker-only setting (4.55 mg versus 4.79 mg). Screening-style evaluation, obtained by thresholding the continuous outcome at 0.8 times the training Sham mean, achieves an area under the receiver operating characteristic curve (ROC-AUC) of up to 0.90 for detecting low muscle weight. These results indicate that geometric and quantum kernel lifts can provide measurable benefits in low-data, low-feature biomedical prediction problems, while preserving interpretability and transparent model selection.
FlowSteer: Conditioning Flow Field for Consistent Image Restoration
Dec 09, 2025Flow-based text-to-image (T2I) models excel at prompt-driven image generation, but falter on Image Restoration (IR), often "drifting away" from being faithful to the measurement. Prior work mitigate this drift with data-specific flows or task-specific adapters that are computationally heavy and not scalable across tasks. This raises the question "Can't we efficiently manipulate the existing generative capabilities of a flow model?" To this end, we introduce FlowSteer (FS), an operator-aware conditioning scheme that injects measurement priors along the sampling path,coupling a frozed flow's implicit guidance with explicit measurement constraints. Across super-resolution, deblurring, denoising, and colorization, FS improves measurement consistency and identity preservation in a strictly zero-shot setting-no retrained models, no adapters. We show how the nature of flow models and their sensitivities to noise inform the design of such a scheduler. FlowSteer, although simple, achieves a higher fidelity of reconstructed images, while leveraging the rich generative priors of flow models.
Diffusion Algorithm for Metalens Optical Aberration Correction
Nov 16, 2025
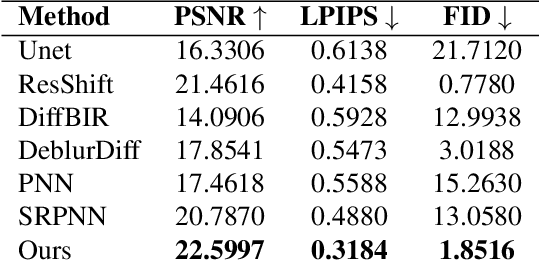


Metalenses offer a path toward creating ultra-thin optical systems, but they inherently suffer from severe, spatially varying optical aberrations, especially chromatic aberration, which makes image reconstruction a significant challenge. This paper presents a novel algorithmic solution to this problem, designed to reconstruct a sharp, full-color image from two inputs: a sharp, bandpass-filtered grayscale ``structure image'' and a heavily distorted ``color cue'' image, both captured by the metalens system. Our method utilizes a dual-branch diffusion model, built upon a pre-trained Stable Diffusion XL framework, to fuse information from the two inputs. We demonstrate through quantitative and qualitative comparisons that our approach significantly outperforms existing deblurring and pansharpening methods, effectively restoring high-frequency details while accurately colorizing the image.
Quanta Diffusion
Jun 07, 2025We present Quanta Diffusion (QuDi), a powerful generative video reconstruction method for single-photon imaging. QuDi is an algorithm supporting the latest Quanta Image Sensors (QIS) and Single Photon Avalanche Diodes (SPADs) for extremely low-light imaging conditions. Compared to existing methods, QuDi overcomes the difficulties of simultaneously managing the motion and the strong shot noise. The core innovation of QuDi is to inject a physics-based forward model into the diffusion algorithm, while keeping the motion estimation in the loop. QuDi demonstrates an average of 2.4 dB PSNR improvement over the best existing methods.
Joint Depth and Reflectivity Estimation using Single-Photon LiDAR
May 19, 2025Single-Photon Light Detection and Ranging (SP-LiDAR is emerging as a leading technology for long-range, high-precision 3D vision tasks. In SP-LiDAR, timestamps encode two complementary pieces of information: pulse travel time (depth) and the number of photons reflected by the object (reflectivity). Existing SP-LiDAR reconstruction methods typically recover depth and reflectivity separately or sequentially use one modality to estimate the other. Moreover, the conventional 3D histogram construction is effective mainly for slow-moving or stationary scenes. In dynamic scenes, however, it is more efficient and effective to directly process the timestamps. In this paper, we introduce an estimation method to simultaneously recover both depth and reflectivity in fast-moving scenes. We offer two contributions: (1) A theoretical analysis demonstrating the mutual correlation between depth and reflectivity and the conditions under which joint estimation becomes beneficial. (2) A novel reconstruction method, "SPLiDER", which exploits the shared information to enhance signal recovery. On both synthetic and real SP-LiDAR data, our method outperforms existing approaches, achieving superior joint reconstruction quality.
Person Recognition at Altitude and Range: Fusion of Face, Body Shape and Gait
May 07, 2025
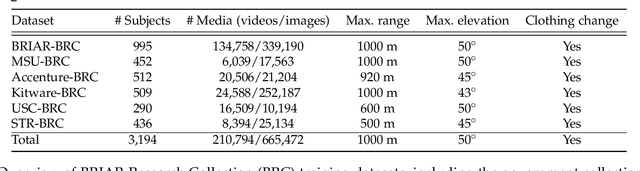

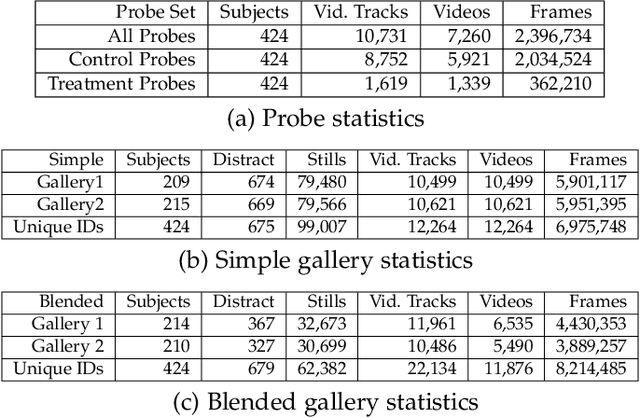
We address the problem of whole-body person recognition in unconstrained environments. This problem arises in surveillance scenarios such as those in the IARPA Biometric Recognition and Identification at Altitude and Range (BRIAR) program, where biometric data is captured at long standoff distances, elevated viewing angles, and under adverse atmospheric conditions (e.g., turbulence and high wind velocity). To this end, we propose FarSight, a unified end-to-end system for person recognition that integrates complementary biometric cues across face, gait, and body shape modalities. FarSight incorporates novel algorithms across four core modules: multi-subject detection and tracking, recognition-aware video restoration, modality-specific biometric feature encoding, and quality-guided multi-modal fusion. These components are designed to work cohesively under degraded image conditions, large pose and scale variations, and cross-domain gaps. Extensive experiments on the BRIAR dataset, one of the most comprehensive benchmarks for long-range, multi-modal biometric recognition, demonstrate the effectiveness of FarSight. Compared to our preliminary system, this system achieves a 34.1% absolute gain in 1:1 verification accuracy (TAR@0.1% FAR), a 17.8% increase in closed-set identification (Rank-20), and a 34.3% reduction in open-set identification errors (FNIR@1% FPIR). Furthermore, FarSight was evaluated in the 2025 NIST RTE Face in Video Evaluation (FIVE), which conducts standardized face recognition testing on the BRIAR dataset. These results establish FarSight as a state-of-the-art solution for operational biometric recognition in challenging real-world conditions.
Wavefront Estimation From a Single Measurement: Uniqueness and Algorithms
Apr 13, 2025Wavefront estimation is an essential component of adaptive optics where the goal is to recover the underlying phase from its Fourier magnitude. While this may sound identical to classical phase retrieval, wavefront estimation faces more strict requirements regarding uniqueness as adaptive optics systems need a unique phase to compensate for the distorted wavefront. Existing real-time wavefront estimation methodologies are dominated by sensing via specialized optical hardware due to their high speed, but they often have a low spatial resolution. A computational method that can perform both fast and accurate wavefront estimation with a single measurement can improve resolution and bring new applications such as real-time passive wavefront estimation, opening the door to a new generation of medical and defense applications. In this paper, we tackle the wavefront estimation problem by observing that the non-uniqueness is related to the geometry of the pupil shape. By analyzing the source of ambiguities and breaking the symmetry, we present a joint optics-algorithm approach by co-designing the shape of the pupil and the reconstruction neural network. Using our proposed lightweight neural network, we demonstrate wavefront estimation of a phase of size $128\times 128$ at $5,200$ frames per second on a CPU computer, achieving an average Strehl ratio up to $0.98$ in the noiseless case. We additionally test our method on real measurements using a spatial light modulator. Code is available at https://pages.github.itap.purdue.edu/StanleyChanGroup/wavefront-estimation/.
Learning Phase Distortion with Selective State Space Models for Video Turbulence Mitigation
Apr 03, 2025Atmospheric turbulence is a major source of image degradation in long-range imaging systems. Although numerous deep learning-based turbulence mitigation (TM) methods have been proposed, many are slow, memory-hungry, and do not generalize well. In the spatial domain, methods based on convolutional operators have a limited receptive field, so they cannot handle a large spatial dependency required by turbulence. In the temporal domain, methods relying on self-attention can, in theory, leverage the lucky effects of turbulence, but their quadratic complexity makes it difficult to scale to many frames. Traditional recurrent aggregation methods face parallelization challenges. In this paper, we present a new TM method based on two concepts: (1) A turbulence mitigation network based on the Selective State Space Model (MambaTM). MambaTM provides a global receptive field in each layer across spatial and temporal dimensions while maintaining linear computational complexity. (2) Learned Latent Phase Distortion (LPD). LPD guides the state space model. Unlike classical Zernike-based representations of phase distortion, the new LPD map uniquely captures the actual effects of turbulence, significantly improving the model's capability to estimate degradation by reducing the ill-posedness. Our proposed method exceeds current state-of-the-art networks on various synthetic and real-world TM benchmarks with significantly faster inference speed. The code is available at http://github.com/xg416/MambaTM.