 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan Foundation Models Perform Zero-Shot Task Specification For Robot Manipulation?
Apr 23, 2022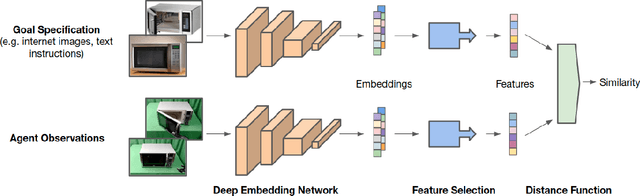
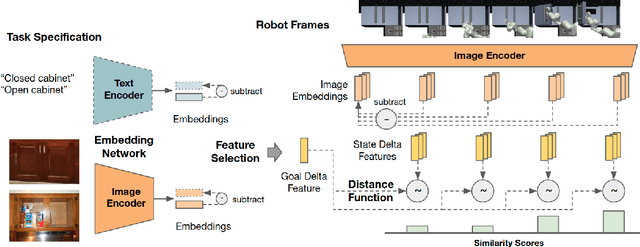
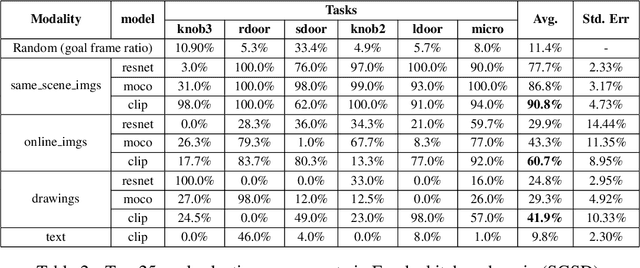

Task specification is at the core of programming autonomous robots. A low-effort modality for task specification is critical for engagement of non-expert end-users and ultimate adoption of personalized robot agents. A widely studied approach to task specification is through goals, using either compact state vectors or goal images from the same robot scene. The former is hard to interpret for non-experts and necessitates detailed state estimation and scene understanding. The latter requires the generation of desired goal image, which often requires a human to complete the task, defeating the purpose of having autonomous robots. In this work, we explore alternate and more general forms of goal specification that are expected to be easier for humans to specify and use such as images obtained from the internet, hand sketches that provide a visual description of the desired task, or simple language descriptions. As a preliminary step towards this, we investigate the capabilities of large scale pre-trained models (foundation models) for zero-shot goal specification, and find promising results in a collection of simulated robot manipulation tasks and real-world datasets.
Curiosity Driven Self-supervised Tactile Exploration of Unknown Objects
Mar 31, 2022
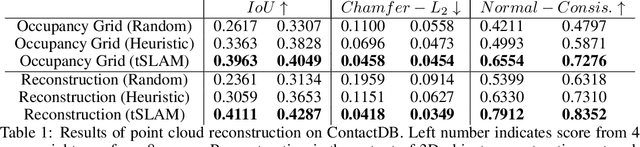

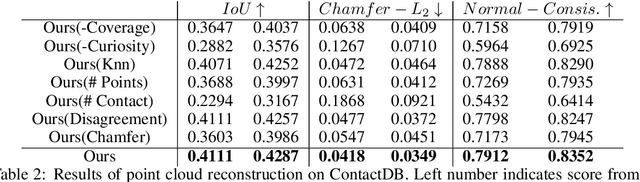
Intricate behaviors an organism can exhibit is predicated on its ability to sense and effectively interpret complexities of its surroundings. Relevant information is often distributed between multiple modalities, and requires the organism to exhibit information assimilation capabilities in addition to information seeking behaviors. While biological beings leverage multiple sensing modalities for decision making, current robots are overly reliant on visual inputs. In this work, we want to augment our robots with the ability to leverage the (relatively under-explored) modality of touch. To focus our investigation, we study the problem of scene reconstruction where touch is the only available sensing modality. We present Tactile Slam (tSLAM) -- which prepares an agent to acquire information seeking behavior and use implicit understanding of common household items to reconstruct the geometric details of the object under exploration. Using the anthropomorphic `ADROIT' hand, we demonstrate that tSLAM is highly effective in reconstructing objects of varying complexities within 6 seconds of interactions. We also established the generality of tSLAM by training only on 3D Warehouse objects and testing on ContactDB objects.
R3M: A Universal Visual Representation for Robot Manipulation
Mar 23, 2022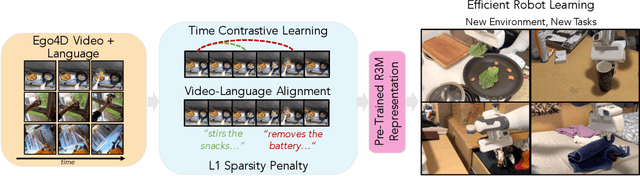
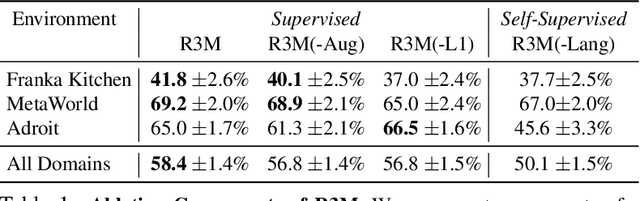
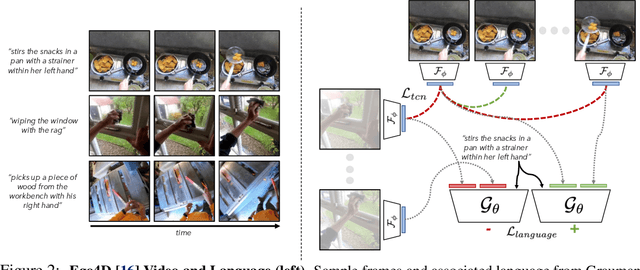
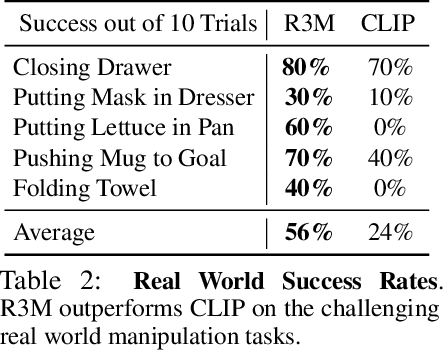
We study how visual representations pre-trained on diverse human video data can enable data-efficient learning of downstream robotic manipulation tasks. Concretely, we pre-train a visual representation using the Ego4D human video dataset using a combination of time-contrastive learning, video-language alignment, and an L1 penalty to encourage sparse and compact representations. The resulting representation, R3M, can be used as a frozen perception module for downstream policy learning. Across a suite of 12 simulated robot manipulation tasks, we find that R3M improves task success by over 20% compared to training from scratch and by over 10% compared to state-of-the-art visual representations like CLIP and MoCo. Furthermore, R3M enables a Franka Emika Panda arm to learn a range of manipulation tasks in a real, cluttered apartment given just 20 demonstrations. Code and pre-trained models are available at https://tinyurl.com/robotr3m.
RB2: Robotic Manipulation Benchmarking with a Twist
Mar 15, 2022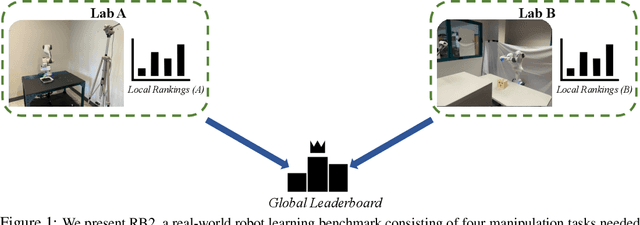
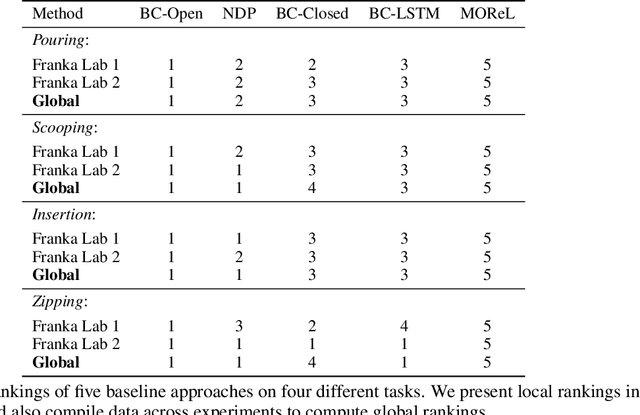


Benchmarks offer a scientific way to compare algorithms using objective performance metrics. Good benchmarks have two features: (a) they should be widely useful for many research groups; (b) and they should produce reproducible findings. In robotic manipulation research, there is a trade-off between reproducibility and broad accessibility. If the benchmark is kept restrictive (fixed hardware, objects), the numbers are reproducible but the setup becomes less general. On the other hand, a benchmark could be a loose set of protocols (e.g. object sets) but the underlying variation in setups make the results non-reproducible. In this paper, we re-imagine benchmarking for robotic manipulation as state-of-the-art algorithmic implementations, alongside the usual set of tasks and experimental protocols. The added baseline implementations will provide a way to easily recreate SOTA numbers in a new local robotic setup, thus providing credible relative rankings between existing approaches and new work. However, these local rankings could vary between different setups. To resolve this issue, we build a mechanism for pooling experimental data between labs, and thus we establish a single global ranking for existing (and proposed) SOTA algorithms. Our benchmark, called Ranking-Based Robotics Benchmark (RB2), is evaluated on tasks that are inspired from clinically validated Southampton Hand Assessment Procedures. Our benchmark was run across two different labs and reveals several surprising findings. For example, extremely simple baselines like open-loop behavior cloning, outperform more complicated models (e.g. closed loop, RNN, Offline-RL, etc.) that are preferred by the field. We hope our fellow researchers will use RB2 to improve their research's quality and rigor.
Policy Architectures for Compositional Generalization in Control
Mar 10, 2022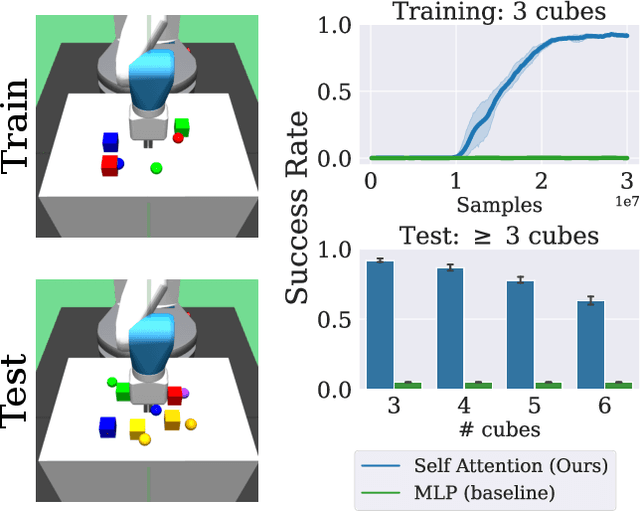
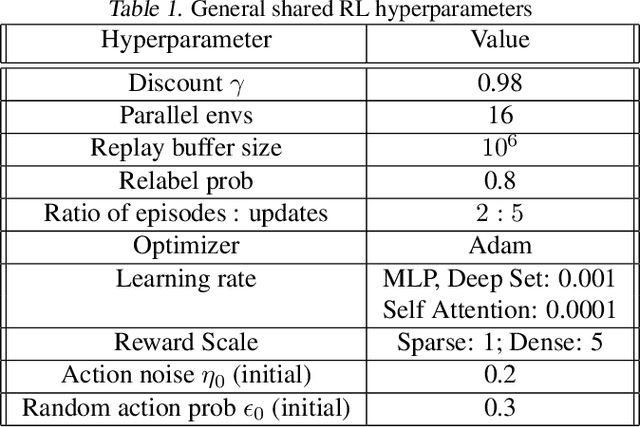
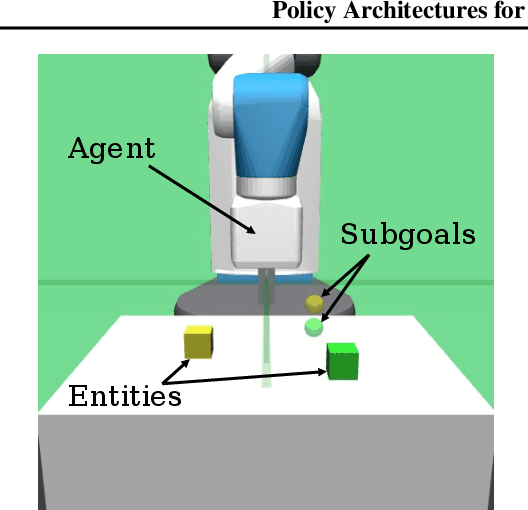
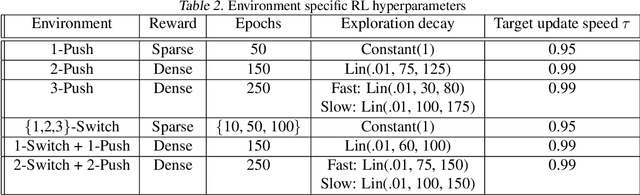
Many tasks in control, robotics, and planning can be specified using desired goal configurations for various entities in the environment. Learning goal-conditioned policies is a natural paradigm to solve such tasks. However, current approaches struggle to learn and generalize as task complexity increases, such as variations in number of environment entities or compositions of goals. In this work, we introduce a framework for modeling entity-based compositional structure in tasks, and create suitable policy designs that can leverage this structure. Our policies, which utilize architectures like Deep Sets and Self Attention, are flexible and can be trained end-to-end without requiring any action primitives. When trained using standard reinforcement and imitation learning methods on a suite of simulated robot manipulation tasks, we find that these architectures achieve significantly higher success rates with less data. We also find these architectures enable broader and compositional generalization, producing policies that extrapolate to different numbers of entities than seen in training, and stitch together (i.e. compose) learned skills in novel ways. Videos of the results can be found at https://sites.google.com/view/comp-gen-rl.
Deep Neural Network Approach to Estimate Early Worst-Case Execution Time
Jul 28, 2021
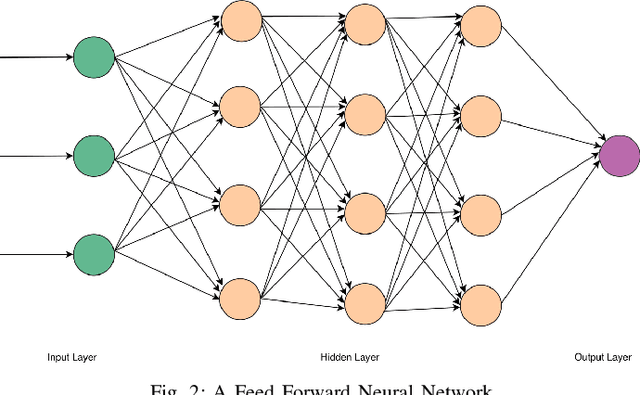
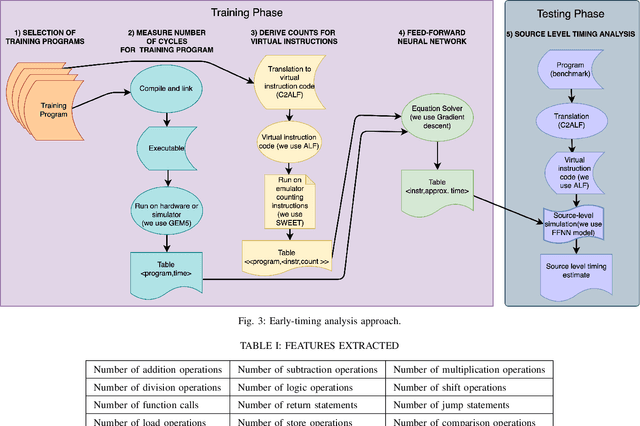
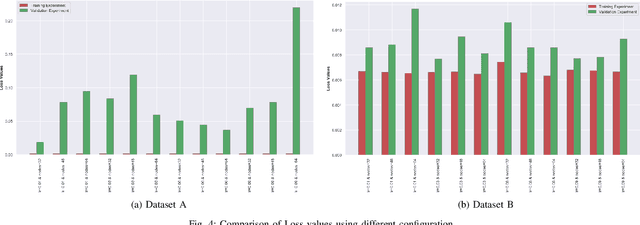
Estimating Worst-Case Execution Time (WCET) is of utmost importance for developing Cyber-Physical and Safety-Critical Systems. The system's scheduler uses the estimated WCET to schedule each task of these systems, and failure may lead to catastrophic events. It is thus imperative to build provably reliable systems. WCET is available to us in the last stage of systems development when the hardware is available and the application code is compiled on it. Different methodologies measure the WCET, but none of them give early insights on WCET, which is crucial for system development. If the system designers overestimate WCET in the early stage, then it would lead to the overqualified system, which will increase the cost of the final product, and if they underestimate WCET in the early stage, then it would lead to financial loss as the system would not perform as expected. This paper estimates early WCET using Deep Neural Networks as an approximate predictor model for hardware architecture and compiler. This model predicts the WCET based on the source code without compiling and running on the hardware architecture. Our WCET prediction model is created using the Pytorch framework. The resulting WCET is too erroneous to be used as an upper bound on the WCET. However, getting these results in the early stages of system development is an essential prerequisite for the system's dimensioning and configuration of the hardware setup.
RRL: Resnet as representation for Reinforcement Learning
Jul 09, 2021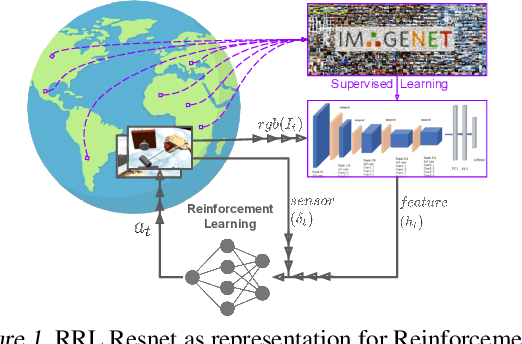
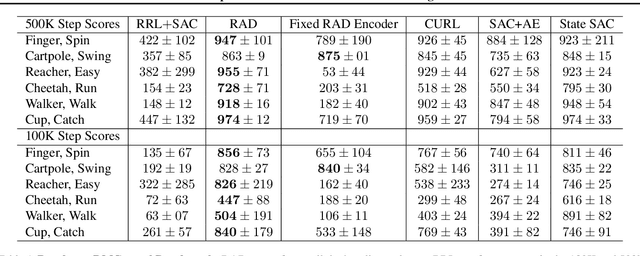
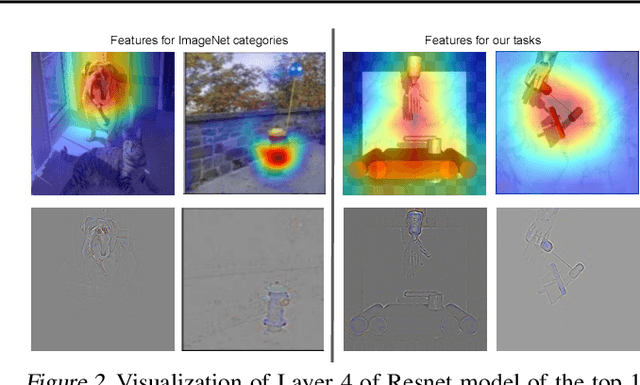
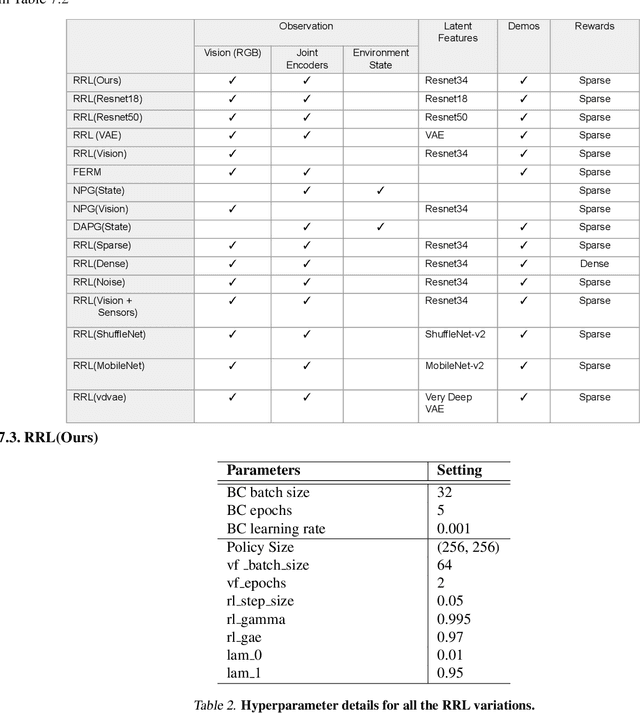
The ability to autonomously learn behaviors via direct interactions in uninstrumented environments can lead to generalist robots capable of enhancing productivity or providing care in unstructured settings like homes. Such uninstrumented settings warrant operations only using the robot's proprioceptive sensor such as onboard cameras, joint encoders, etc which can be challenging for policy learning owing to the high dimensionality and partial observability issues. We propose RRL: Resnet as representation for Reinforcement Learning -- a straightforward yet effective approach that can learn complex behaviors directly from proprioceptive inputs. RRL fuses features extracted from pre-trained Resnet into the standard reinforcement learning pipeline and delivers results comparable to learning directly from the state. In a simulated dexterous manipulation benchmark, where the state of the art methods fail to make significant progress, RRL delivers contact rich behaviors. The appeal of RRL lies in its simplicity in bringing together progress from the fields of Representation Learning, Imitation Learning, and Reinforcement Learning. Its effectiveness in learning behaviors directly from visual inputs with performance and sample efficiency matching learning directly from the state, even in complex high dimensional domains, is far from obvious.
Reset-Free Reinforcement Learning via Multi-Task Learning: Learning Dexterous Manipulation Behaviors without Human Intervention
Apr 22, 2021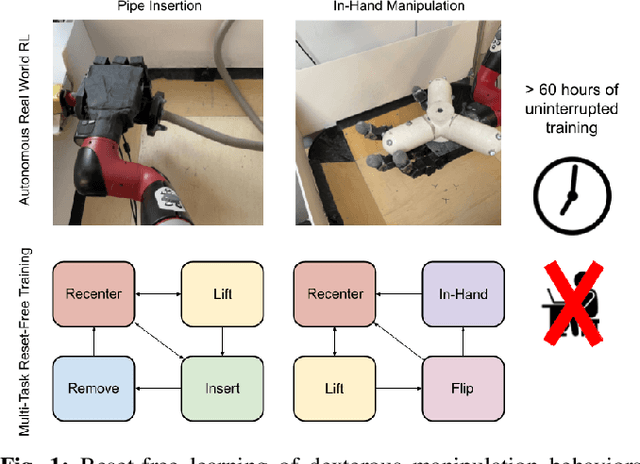



Reinforcement Learning (RL) algorithms can in principle acquire complex robotic skills by learning from large amounts of data in the real world, collected via trial and error. However, most RL algorithms use a carefully engineered setup in order to collect data, requiring human supervision and intervention to provide episodic resets. This is particularly evident in challenging robotics problems, such as dexterous manipulation. To make data collection scalable, such applications require reset-free algorithms that are able to learn autonomously, without explicit instrumentation or human intervention. Most prior work in this area handles single-task learning. However, we might also want robots that can perform large repertoires of skills. At first, this would appear to only make the problem harder. However, the key observation we make in this work is that an appropriately chosen multi-task RL setting actually alleviates the reset-free learning challenge, with minimal additional machinery required. In effect, solving a multi-task problem can directly solve the reset-free problem since different combinations of tasks can serve to perform resets for other tasks. By learning multiple tasks together and appropriately sequencing them, we can effectively learn all of the tasks together reset-free. This type of multi-task learning can effectively scale reset-free learning schemes to much more complex problems, as we demonstrate in our experiments. We propose a simple scheme for multi-task learning that tackles the reset-free learning problem, and show its effectiveness at learning to solve complex dexterous manipulation tasks in both hardware and simulation without any explicit resets. This work shows the ability to learn dexterous manipulation behaviors in the real world with RL without any human intervention.
Emergent Real-World Robotic Skills via Unsupervised Off-Policy Reinforcement Learning
Apr 27, 2020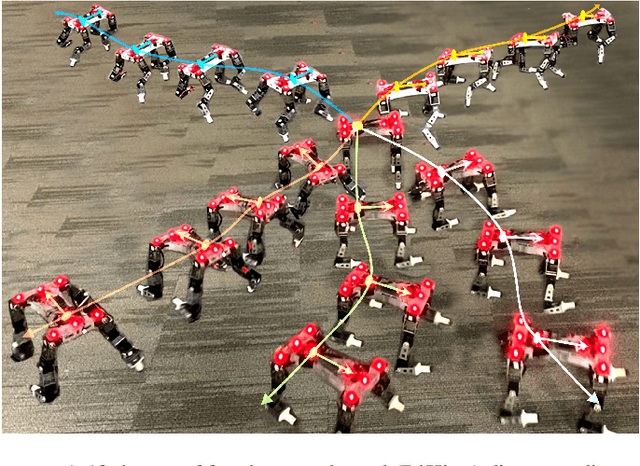
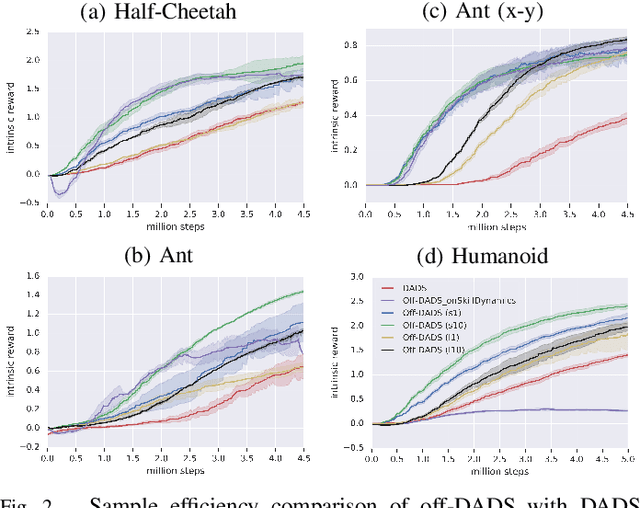


Reinforcement learning provides a general framework for learning robotic skills while minimizing engineering effort. However, most reinforcement learning algorithms assume that a well-designed reward function is provided, and learn a single behavior for that single reward function. Such reward functions can be difficult to design in practice. Can we instead develop efficient reinforcement learning methods that acquire diverse skills without any reward function, and then repurpose these skills for downstream tasks? In this paper, we demonstrate that a recently proposed unsupervised skill discovery algorithm can be extended into an efficient off-policy method, making it suitable for performing unsupervised reinforcement learning in the real world. Firstly, we show that our proposed algorithm provides substantial improvement in learning efficiency, making reward-free real-world training feasible. Secondly, we move beyond the simulation environments and evaluate the algorithm on real physical hardware. On quadrupeds, we observe that locomotion skills with diverse gaits and different orientations emerge without any rewards or demonstrations. We also demonstrate that the learned skills can be composed using model predictive control for goal-oriented navigation, without any additional training.
The Ingredients of Real-World Robotic Reinforcement Learning
Apr 27, 2020
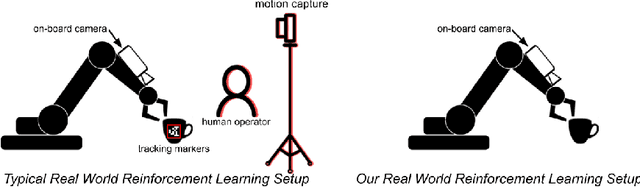
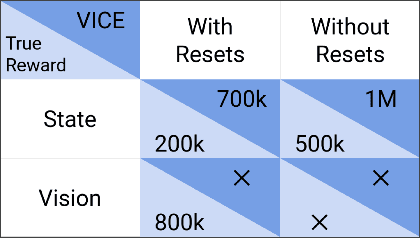
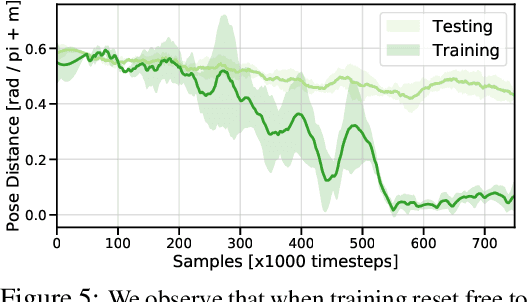
The success of reinforcement learning for real world robotics has been, in many cases limited to instrumented laboratory scenarios, often requiring arduous human effort and oversight to enable continuous learning. In this work, we discuss the elements that are needed for a robotic learning system that can continually and autonomously improve with data collected in the real world. We propose a particular instantiation of such a system, using dexterous manipulation as our case study. Subsequently, we investigate a number of challenges that come up when learning without instrumentation. In such settings, learning must be feasible without manually designed resets, using only on-board perception, and without hand-engineered reward functions. We propose simple and scalable solutions to these challenges, and then demonstrate the efficacy of our proposed system on a set of dexterous robotic manipulation tasks, providing an in-depth analysis of the challenges associated with this learning paradigm. We demonstrate that our complete system can learn without any human intervention, acquiring a variety of vision-based skills with a real-world three-fingered hand. Results and videos can be found at https://sites.google.com/view/realworld-rl/