 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving 3D Object Detection through Progressive Population Based Augmentation
Apr 02, 2020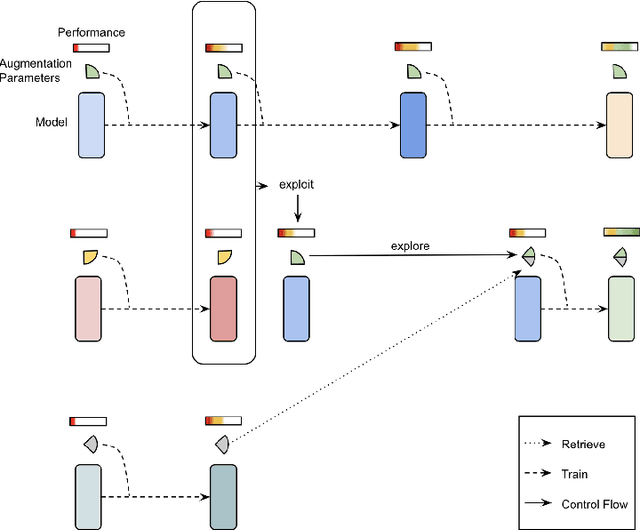
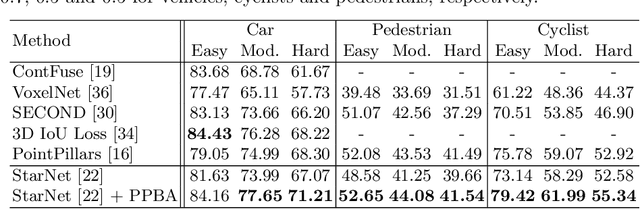

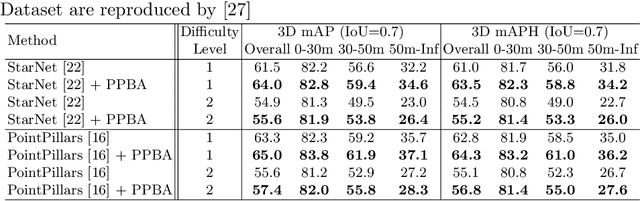
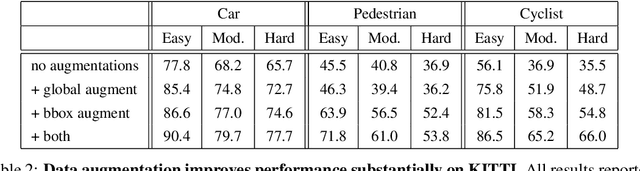
Data augmentation has been widely adopted for object detection in 3D point clouds. All previous efforts have focused on manually designing specific data augmentation methods for individual architectures, however no work has attempted to automate the design of data augmentation in 3D detection problems -- as is common in 2D image-based computer vision. In this work, we present the first attempt to automate the design of data augmentation policies for 3D object detection. We present an algorithm, termed Progressive Population Based Augmentation (PPBA). PPBA learns to optimize augmentation strategies by narrowing down the search space and adopting the best parameters discovered in previous iterations. On the KITTI test set, PPBA improves the StarNet detector by substantial margins on the moderate difficulty category of cars, pedestrians, and cyclists, outperforming all current state-of-the-art single-stage detection models. Additional experiments on the Waymo Open Dataset indicate that PPBA continues to effectively improve 3D object detection on a 20x larger dataset compared to KITTI. The magnitude of the improvements may be comparable to advances in 3D perception architectures and the gains come without an incurred cost at inference time. In subsequent experiments, we find that PPBA may be up to 10x more data efficient than baseline 3D detection models without augmentation, highlighting that 3D detection models may achieve competitive accuracy with far fewer labeled examples.
Scalability in Perception for Autonomous Driving: Waymo Open Dataset
Dec 18, 2019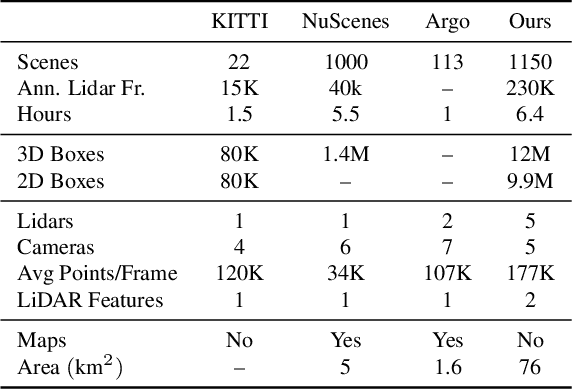
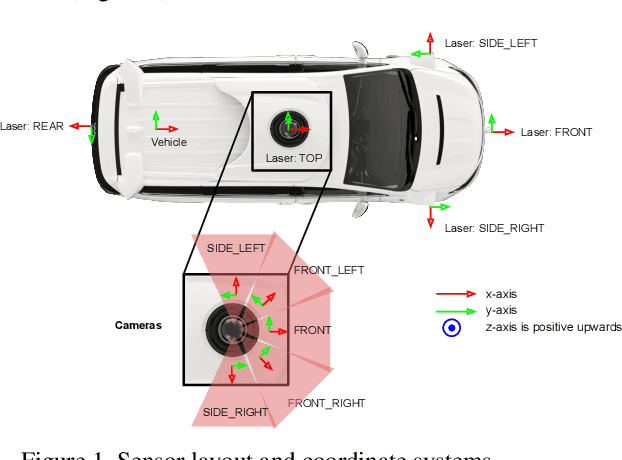

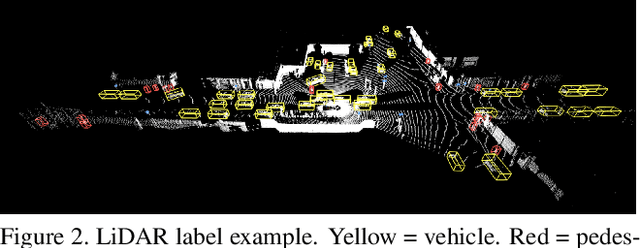
The research community has increasing interest in autonomous driving research, despite the resource intensity of obtaining representative real world data. Existing self-driving datasets are limited in the scale and variation of the environments they capture, even though generalization within and between operating regions is crucial to the overall viability of the technology. In an effort to help align the research community's contributions with real-world self-driving problems, we introduce a new large scale, high quality, diverse dataset. Our new dataset consists of 1150 scenes that each span 20 seconds, consisting of well synchronized and calibrated high quality LiDAR and camera data captured across a range of urban and suburban geographies. It is 15x more diverse than the largest camera+LiDAR dataset available based on our proposed diversity metric. We exhaustively annotated this data with 2D (camera image) and 3D (LiDAR) bounding boxes, with consistent identifiers across frames. Finally, we provide strong baselines for 2D as well as 3D detection and tracking tasks. We further study the effects of dataset size and generalization across geographies on 3D detection methods. Find data, code and more up-to-date information at http://www.waymo.com/open.
End-to-End Multi-View Fusion for 3D Object Detection in LiDAR Point Clouds
Oct 23, 2019
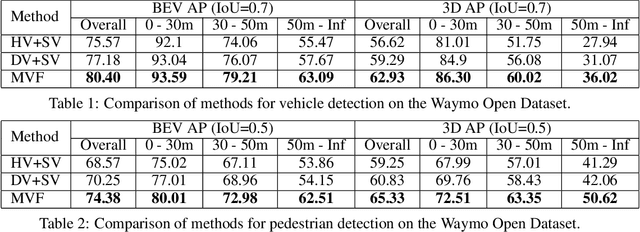
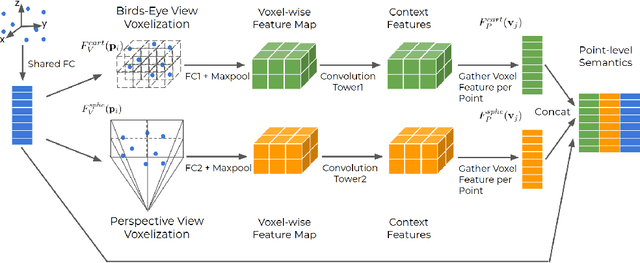
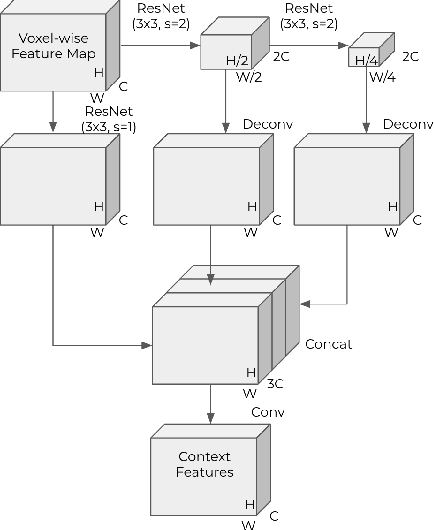
Recent work on 3D object detection advocates point cloud voxelization in birds-eye view, where objects preserve their physical dimensions and are naturally separable. When represented in this view, however, point clouds are sparse and have highly variable point density, which may cause detectors difficulties in detecting distant or small objects (pedestrians, traffic signs, etc.). On the other hand, perspective view provides dense observations, which could allow more favorable feature encoding for such cases. In this paper, we aim to synergize the birds-eye view and the perspective view and propose a novel end-to-end multi-view fusion (MVF) algorithm, which can effectively learn to utilize the complementary information from both. Specifically, we introduce dynamic voxelization, which has four merits compared to existing voxelization methods, i) removing the need of pre-allocating a tensor with fixed size; ii) overcoming the information loss due to stochastic point/voxel dropout; iii) yielding deterministic voxel embeddings and more stable detection outcomes; iv) establishing the bi-directional relationship between points and voxels, which potentially lays a natural foundation for cross-view feature fusion. By employing dynamic voxelization, the proposed feature fusion architecture enables each point to learn to fuse context information from different views. MVF operates on points and can be naturally extended to other approaches using LiDAR point clouds. We evaluate our MVF model extensively on the newly released Waymo Open Dataset and on the KITTI dataset and demonstrate that it significantly improves detection accuracy over the comparable single-view PointPillars baseline.
StarNet: Targeted Computation for Object Detection in Point Clouds
Aug 29, 2019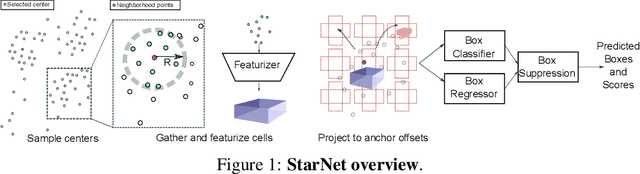
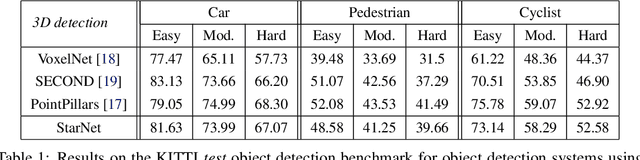
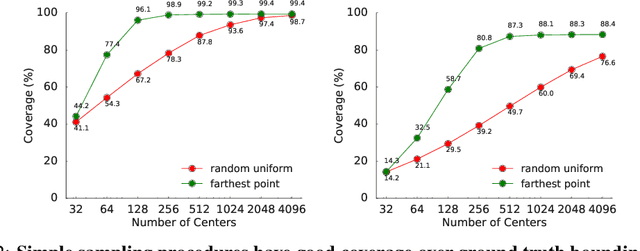
LiDAR sensor systems provide high resolution spatial information about the environment for self-driving cars. Therefore, detecting objects from point clouds derived from LiDAR represents a critical problem. Previous work on object detection from LiDAR has emphasized re-purposing convolutional approaches from traditional camera imagery. In this work, we present an object detection system designed specifically for point cloud data blending aspects of one-stage and two-stage systems. We observe that objects in point clouds are quite distinct from traditional camera images: objects are sparse and vary widely in location, but do not exhibit scale distortions observed in single camera perspective. These two observations suggest that simple and cheap data-driven object proposals to maximize spatial coverage or match the observed densities of point cloud data may suffice. This recognition paired with a local, non-convolutional, point-based network permits building an object detector for point clouds that may be trained only once, but adapted to different computational settings -- targeted to different predictive priorities or spatial regions. We demonstrate this flexibility and the targeted detection strategies on both the KITTI detection dataset as well as on the large-scale Waymo Open Dataset. Furthermore, we find that a single network is competitive with other point cloud detectors across a range of computational budgets, while being more flexible to adapt to contextual priorities.
Searching for MobileNetV3
May 14, 2019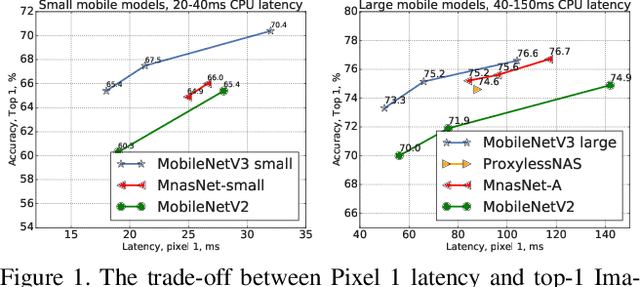
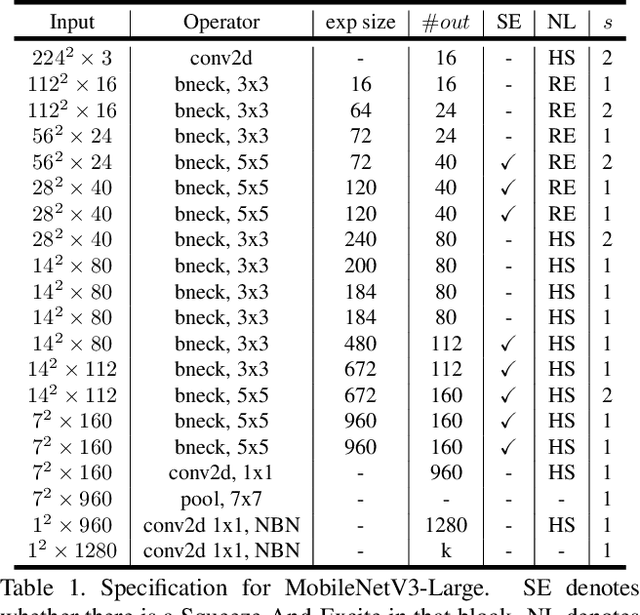
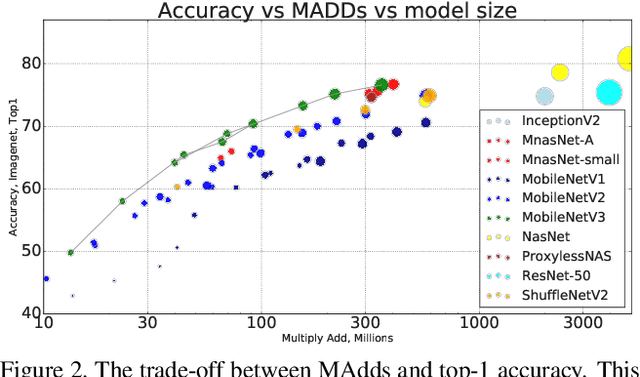
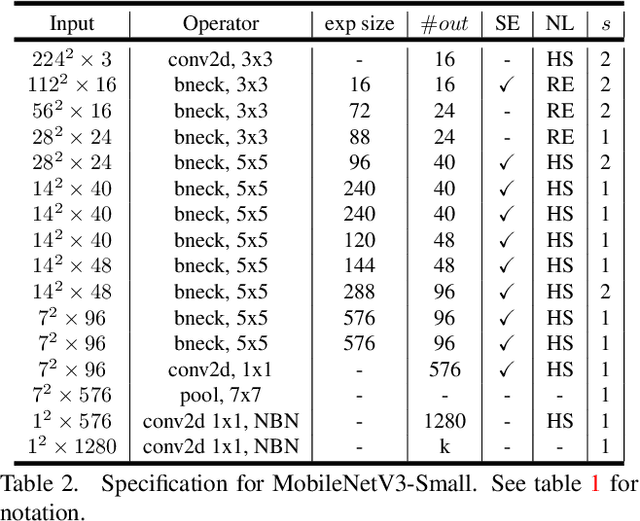
We present the next generation of MobileNets based on a combination of complementary search techniques as well as a novel architecture design. MobileNetV3 is tuned to mobile phone CPUs through a combination of hardware aware network architecture search (NAS) complemented by the NetAdapt algorithm and then subsequently improved through novel architecture advances. This paper starts the exploration of how automated search algorithms and network design can work together to harness complementary approaches improving the overall state of the art. Through this process we create two new MobileNet models for release: MobileNetV3-Large and MobileNetV3-Small which are targeted for high and low resource use cases. These models are then adapted and applied to the tasks of object detection and semantic segmentation. For the task of semantic segmentation (or any dense pixel prediction), we propose a new efficient segmentation decoder Lite Reduced Atrous Spatial Pyramid Pooling (LR-ASPP). We achieve new state of the art results for mobile classification, detection and segmentation. MobileNetV3-Large is 3.2% more accurate on ImageNet classification while reducing latency by 15% compared to MobileNetV2. MobileNetV2-Small is 4.6% more accurate while reducing latency by 5% compared to MobileNetV2. MobileNetV3-Large detection is 25% faster at roughly the same accuracy as MobileNetV2 on COCO detection. MobileNetV3-Large LR-ASPP is 30% faster than MobileNetV2 R-ASPP at similar accuracy for Cityscapes segmentation.
Domain Adaptive Transfer Learning with Specialist Models
Dec 11, 2018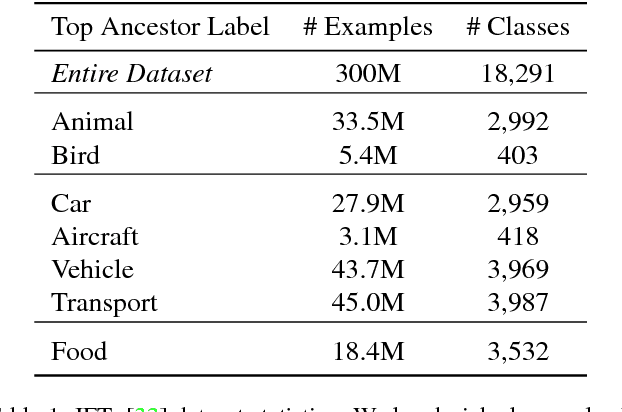
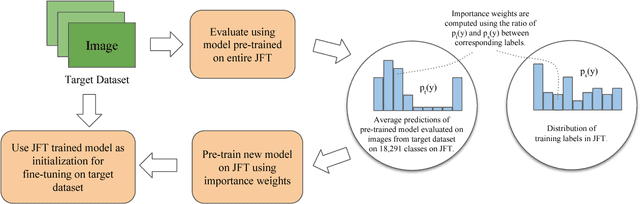
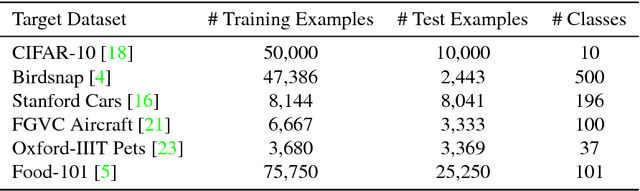
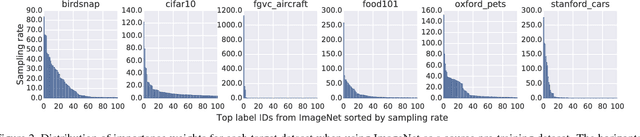
Transfer learning is a widely used method to build high performing computer vision models. In this paper, we study the efficacy of transfer learning by examining how the choice of data impacts performance. We find that more pre-training data does not always help, and transfer performance depends on a judicious choice of pre-training data. These findings are important given the continued increase in dataset sizes. We further propose domain adaptive transfer learning, a simple and effective pre-training method using importance weights computed based on the target dataset. Our method to compute importance weights follow from ideas in domain adaptation, and we show a novel application to transfer learning. Our methods achieve state-of-the-art results on multiple fine-grained classification datasets and are well-suited for use in practice.
AutoAugment: Learning Augmentation Policies from Data
Oct 09, 2018
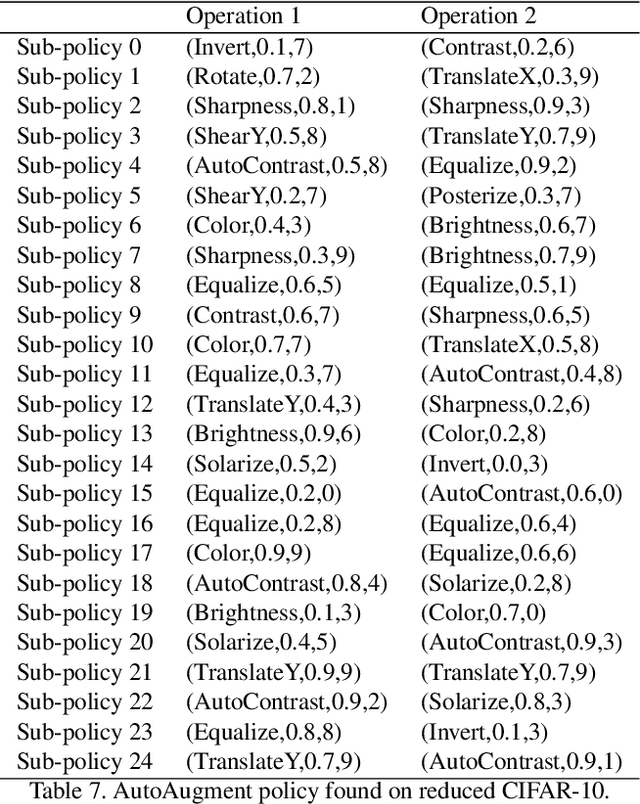


In this paper, we take a closer look at data augmentation for images, and describe a simple procedure called AutoAugment to search for improved data augmentation policies. Our key insight is to create a search space of data augmentation policies, evaluating the quality of a particular policy directly on the dataset of interest. In our implementation, we have designed a search space where a policy consists of many sub-policies, one of which is randomly chosen for each image in each mini-batch. A sub-policy consists of two operations, each operation being an image processing function such as translation, rotation, or shearing, and the probabilities and magnitudes with which the functions are applied. We use a search algorithm to find the best policy such that the neural network yields the highest validation accuracy on a target dataset. Our method achieves state-of-the-art accuracy on CIFAR-10, CIFAR-100, SVHN, and ImageNet (without additional data). On ImageNet, we attain a Top-1 accuracy of 83.54%. On CIFAR-10, we achieve an error rate of 1.48%, which is 0.65% better than the previous state-of-the-art. Finally, policies learned from one dataset can be transferred to work well on other similar datasets. For example, the policy learned on ImageNet allows us to achieve state-of-the-art accuracy on the fine grained visual classification dataset Stanford Cars, without fine-tuning weights pre-trained on additional data. Code to train Wide-ResNet, Shake-Shake and ShakeDrop models with AutoAugment policies can be found at https://github.com/tensorflow/models/tree/master/research/autoaugment
MnasNet: Platform-Aware Neural Architecture Search for Mobile
Jul 31, 2018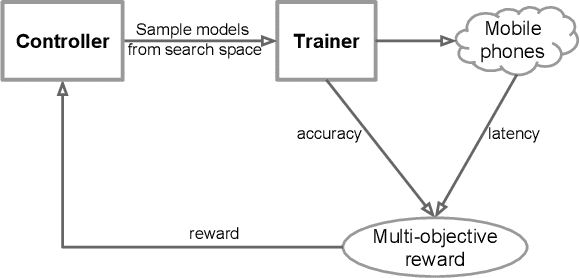
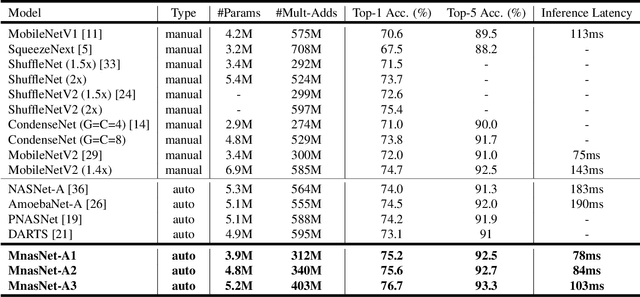
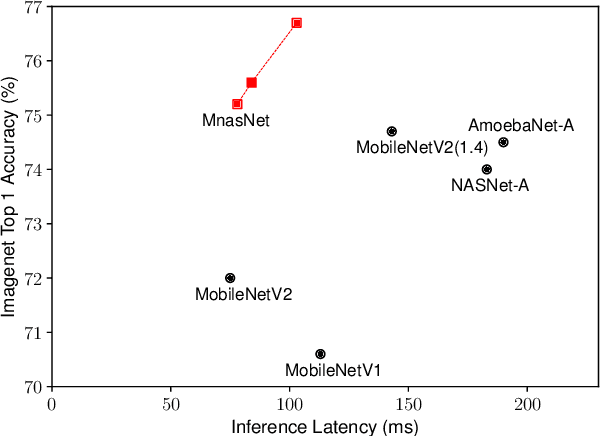
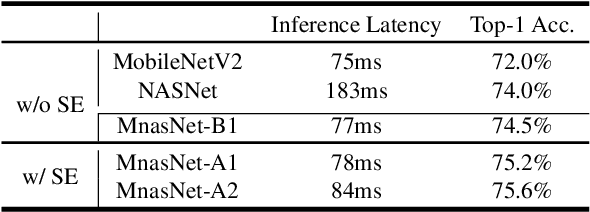
Designing convolutional neural networks (CNN) models for mobile devices is challenging because mobile models need to be small and fast, yet still accurate. Although significant effort has been dedicated to design and improve mobile models on all three dimensions, it is challenging to manually balance these trade-offs when there are so many architectural possibilities to consider. In this paper, we propose an automated neural architecture search approach for designing resource-constrained mobile CNN models. We propose to explicitly incorporate latency information into the main objective so that the search can identify a model that achieves a good trade-off between accuracy and latency. Unlike in previous work, where mobile latency is considered via another, often inaccurate proxy (e.g., FLOPS), in our experiments, we directly measure real-world inference latency by executing the model on a particular platform, e.g., Pixel phones. To further strike the right balance between flexibility and search space size, we propose a novel factorized hierarchical search space that permits layer diversity throughout the network. Experimental results show that our approach consistently outperforms state-of-the-art mobile CNN models across multiple vision tasks. On the ImageNet classification task, our model achieves 74.0% top-1 accuracy with 76ms latency on a Pixel phone, which is 1.5x faster than MobileNetV2 (Sandler et al. 2018) and 2.4x faster than NASNet (Zoph et al. 2018) with the same top-1 accuracy. On the COCO object detection task, our model family achieves both higher mAP quality and lower latency than MobileNets.
Parallel Architecture and Hyperparameter Search via Successive Halving and Classification
May 25, 2018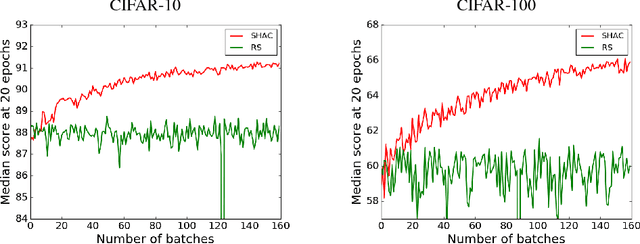
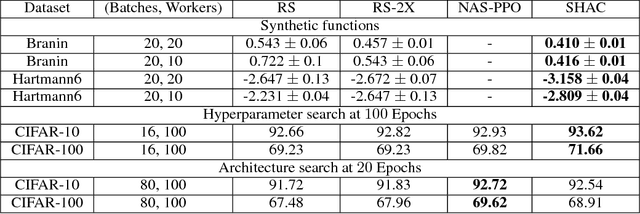
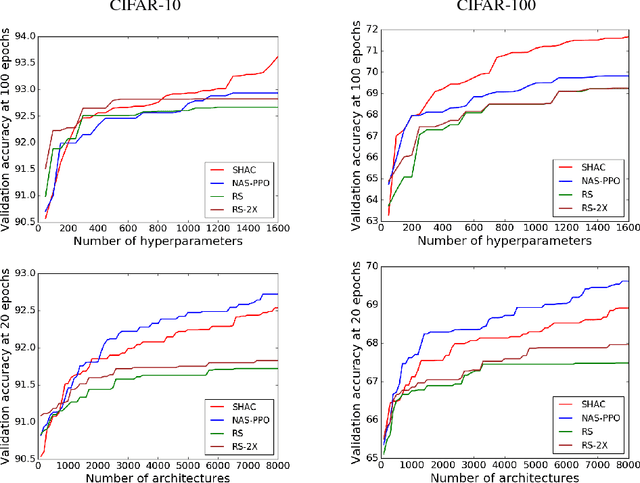

We present a simple and powerful algorithm for parallel black box optimization called Successive Halving and Classification (SHAC). The algorithm operates in $K$ stages of parallel function evaluations and trains a cascade of binary classifiers to iteratively cull the undesirable regions of the search space. SHAC is easy to implement, requires no tuning of its own configuration parameters, is invariant to the scale of the objective function and can be built using any choice of binary classifier. We adopt tree-based classifiers within SHAC and achieve competitive performance against several strong baselines for optimizing synthetic functions, hyperparameters and architectures.
Learning Transferable Architectures for Scalable Image Recognition
Apr 11, 2018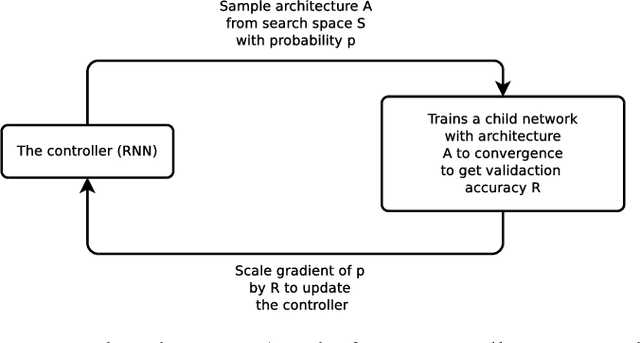
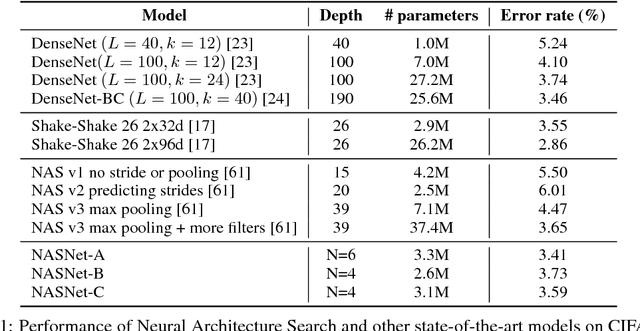
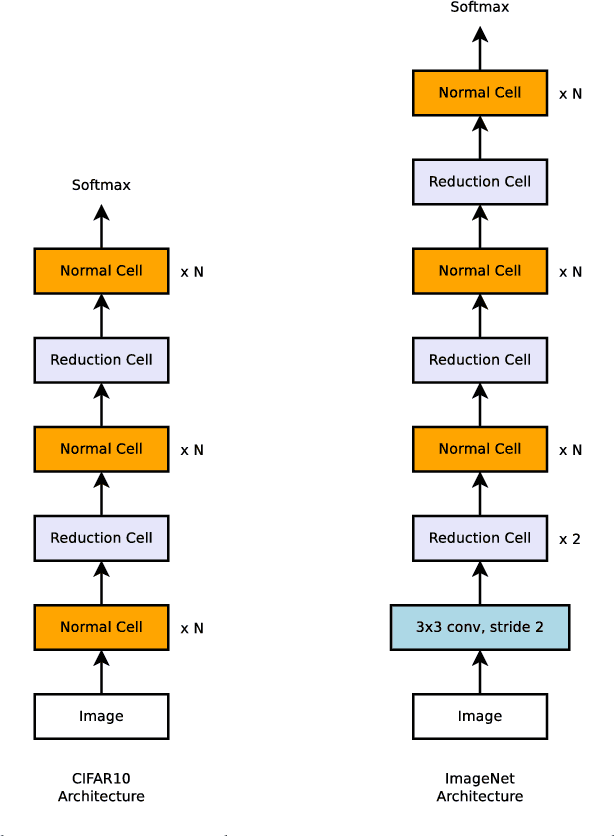
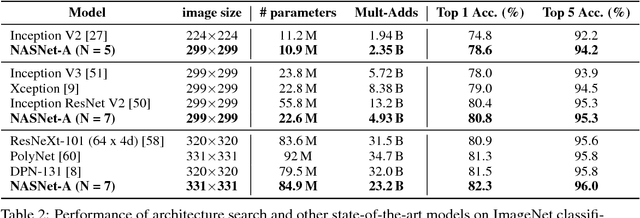
Developing neural network image classification models often requires significant architecture engineering. In this paper, we study a method to learn the model architectures directly on the dataset of interest. As this approach is expensive when the dataset is large, we propose to search for an architectural building block on a small dataset and then transfer the block to a larger dataset. The key contribution of this work is the design of a new search space (the "NASNet search space") which enables transferability. In our experiments, we search for the best convolutional layer (or "cell") on the CIFAR-10 dataset and then apply this cell to the ImageNet dataset by stacking together more copies of this cell, each with their own parameters to design a convolutional architecture, named "NASNet architecture". We also introduce a new regularization technique called ScheduledDropPath that significantly improves generalization in the NASNet models. On CIFAR-10 itself, NASNet achieves 2.4% error rate, which is state-of-the-art. On ImageNet, NASNet achieves, among the published works, state-of-the-art accuracy of 82.7% top-1 and 96.2% top-5 on ImageNet. Our model is 1.2% better in top-1 accuracy than the best human-invented architectures while having 9 billion fewer FLOPS - a reduction of 28% in computational demand from the previous state-of-the-art model. When evaluated at different levels of computational cost, accuracies of NASNets exceed those of the state-of-the-art human-designed models. For instance, a small version of NASNet also achieves 74% top-1 accuracy, which is 3.1% better than equivalently-sized, state-of-the-art models for mobile platforms. Finally, the learned features by NASNet used with the Faster-RCNN framework surpass state-of-the-art by 4.0% achieving 43.1% mAP on the COCO dataset.