 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHandling Compounding in Mobile Keyboard Input
Jan 17, 2022This paper proposes a framework to improve the typing experience of mobile users in morphologically rich languages. Smartphone keyboards typically support features such as input decoding, corrections and predictions that all rely on language models. For latency reasons, these operations happen on device, so the models are of limited size and cannot easily cover all the words needed by users for their daily tasks, especially in morphologically rich languages. In particular, the compounding nature of Germanic languages makes their vocabulary virtually infinite. Similarly, heavily inflecting and agglutinative languages (e.g. Slavic, Turkic or Finno-Ugric languages) tend to have much larger vocabularies than morphologically simpler languages, such as English or Mandarin. We propose to model such languages with automatically selected subword units annotated with what we call binding types, allowing the decoder to know when to bind subword units into words. We show that this method brings around 20% word error rate reduction in a variety of compounding languages. This is more than twice the improvement we previously obtained with a more basic approach, also described in the paper.
End-to-End Multi-View Fusion for 3D Object Detection in LiDAR Point Clouds
Oct 23, 2019
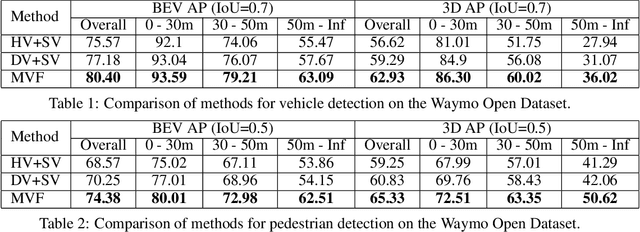
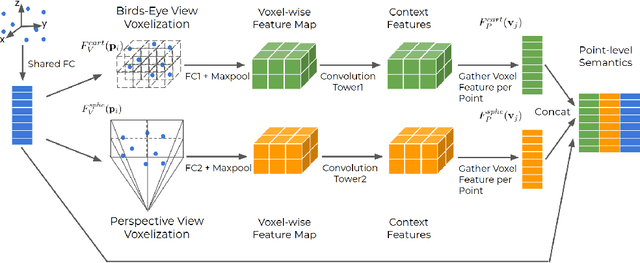
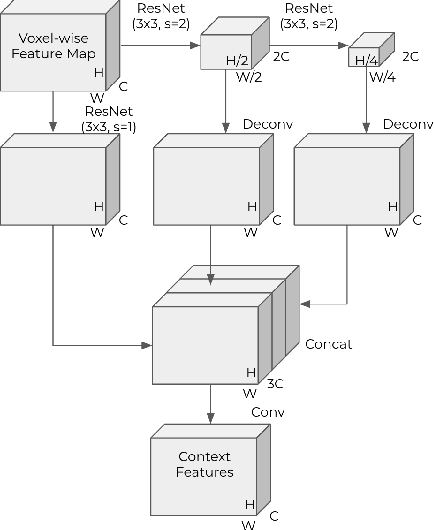
Recent work on 3D object detection advocates point cloud voxelization in birds-eye view, where objects preserve their physical dimensions and are naturally separable. When represented in this view, however, point clouds are sparse and have highly variable point density, which may cause detectors difficulties in detecting distant or small objects (pedestrians, traffic signs, etc.). On the other hand, perspective view provides dense observations, which could allow more favorable feature encoding for such cases. In this paper, we aim to synergize the birds-eye view and the perspective view and propose a novel end-to-end multi-view fusion (MVF) algorithm, which can effectively learn to utilize the complementary information from both. Specifically, we introduce dynamic voxelization, which has four merits compared to existing voxelization methods, i) removing the need of pre-allocating a tensor with fixed size; ii) overcoming the information loss due to stochastic point/voxel dropout; iii) yielding deterministic voxel embeddings and more stable detection outcomes; iv) establishing the bi-directional relationship between points and voxels, which potentially lays a natural foundation for cross-view feature fusion. By employing dynamic voxelization, the proposed feature fusion architecture enables each point to learn to fuse context information from different views. MVF operates on points and can be naturally extended to other approaches using LiDAR point clouds. We evaluate our MVF model extensively on the newly released Waymo Open Dataset and on the KITTI dataset and demonstrate that it significantly improves detection accuracy over the comparable single-view PointPillars baseline.
Federated Learning Of Out-Of-Vocabulary Words
Mar 26, 2019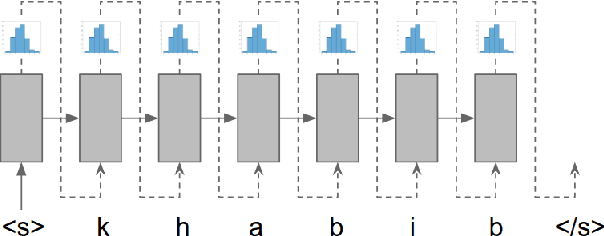
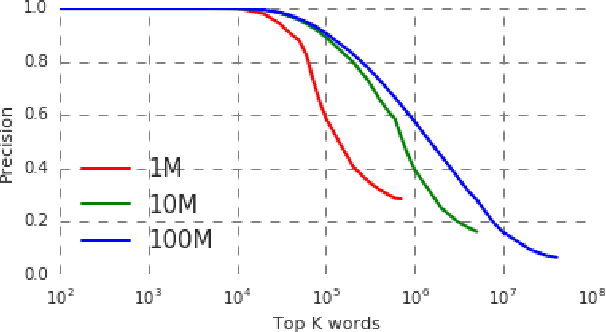

We demonstrate that a character-level recurrent neural network is able to learn out-of-vocabulary (OOV) words under federated learning settings, for the purpose of expanding the vocabulary of a virtual keyboard for smartphones without exporting sensitive text to servers. High-frequency words can be sampled from the trained generative model by drawing from the joint posterior directly. We study the feasibility of the approach in two settings: (1) using simulated federated learning on a publicly available non-IID per-user dataset from a popular social networking website, (2) using federated learning on data hosted on user mobile devices. The model achieves good recall and precision compared to ground-truth OOV words in setting (1). With (2) we demonstrate the practicality of this approach by showing that we can learn meaningful OOV words with good character-level prediction accuracy and cross entropy loss.
Mobile Keyboard Input Decoding with Finite-State Transducers
Apr 13, 2017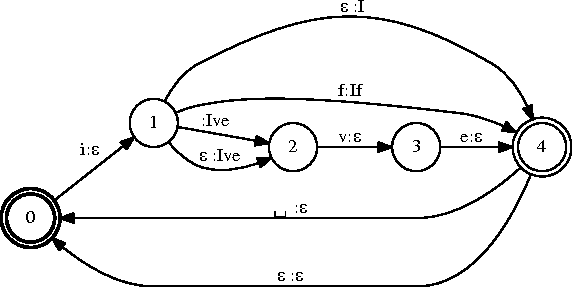
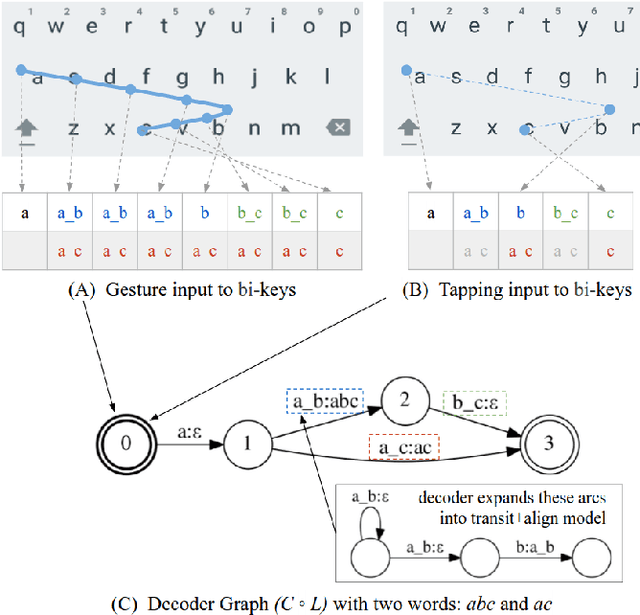
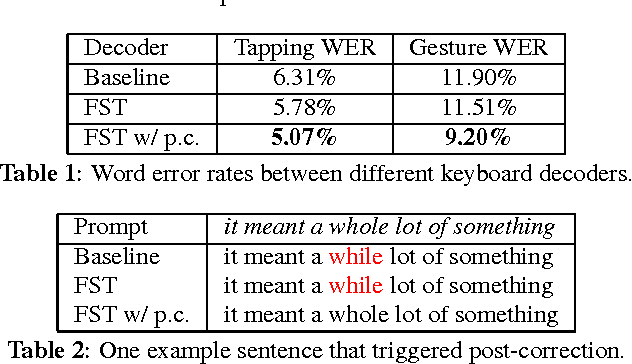
We propose a finite-state transducer (FST) representation for the models used to decode keyboard inputs on mobile devices. Drawing from learnings from the field of speech recognition, we describe a decoding framework that can satisfy the strict memory and latency constraints of keyboard input. We extend this framework to support functionalities typically not present in speech recognition, such as literal decoding, autocorrections, word completions, and next word predictions. We describe the general framework of what we call for short the keyboard "FST decoder" as well as the implementation details that are new compared to a speech FST decoder. We demonstrate that the FST decoder enables new UX features such as post-corrections. Finally, we sketch how this decoder can support advanced features such as personalization and contextualization.