 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLightHuBERT: Lightweight and Configurable Speech Representation Learning with Once-for-All Hidden-Unit BERT
Mar 29, 2022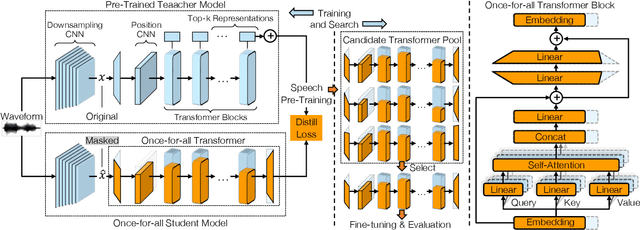
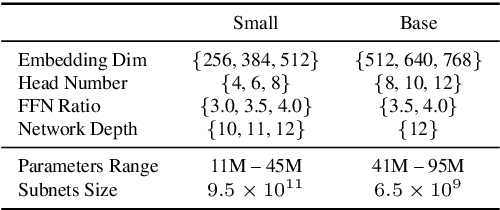

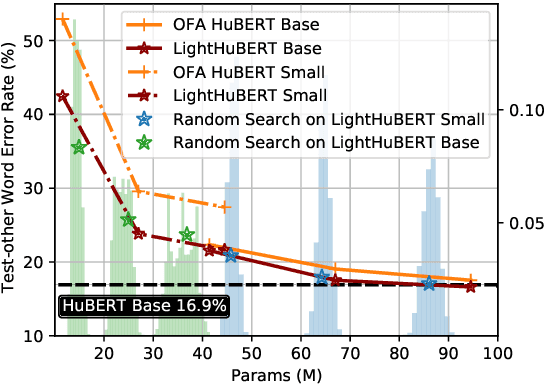
Self-supervised speech representation learning has shown promising results in various speech processing tasks. However, the pre-trained models, e.g., HuBERT, are storage-intensive Transformers, limiting their scope of applications under low-resource settings. To this end, we propose LightHuBERT, a once-for-all Transformer compression framework, to find the desired architectures automatically by pruning structured parameters. More precisely, we create a Transformer-based supernet that is nested with thousands of weight-sharing subnets and design a two-stage distillation strategy to leverage the contextualized latent representations from HuBERT. Experiments on automatic speech recognition (ASR) and the SUPERB benchmark show the proposed LightHuBERT enables over $10^9$ architectures concerning the embedding dimension, attention dimension, head number, feed-forward network ratio, and network depth. LightHuBERT outperforms the original HuBERT on ASR and five SUPERB tasks with the HuBERT size, achieves comparable performance to the teacher model in most tasks with a reduction of 29% parameters, and obtains a $3.5\times$ compression ratio in three SUPERB tasks, e.g., automatic speaker verification, keyword spotting, and intent classification, with a slight accuracy loss. The code and pre-trained models are available at https://github.com/mechanicalsea/lighthubert.
SpeechT5: Unified-Modal Encoder-Decoder Pre-training for Spoken Language Processing
Oct 14, 2021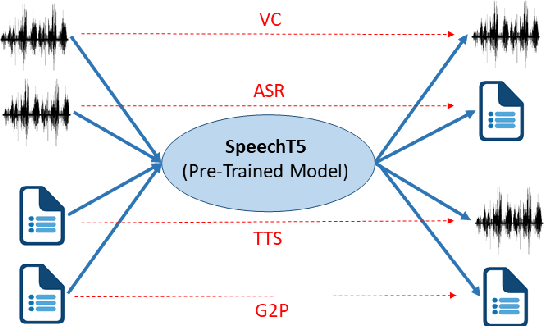
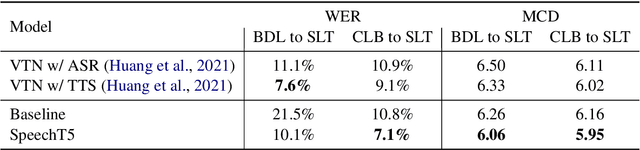
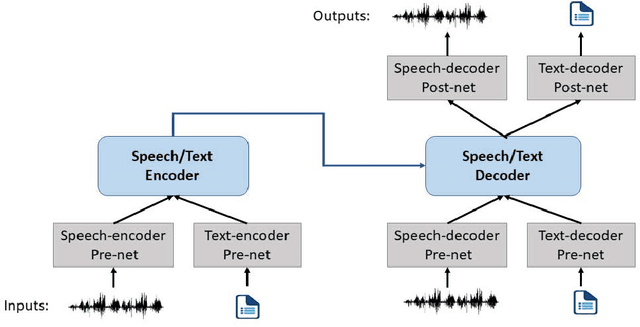
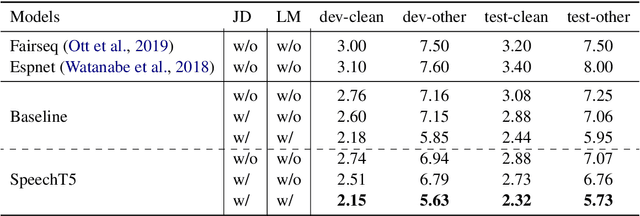
Motivated by the success of T5 (Text-To-Text Transfer Transformer) in pre-training natural language processing models, we propose a unified-modal SpeechT5 framework that explores the encoder-decoder pre-training for self-supervised speech/text representation learning. The SpeechT5 framework consists of a shared encoder-decoder network and six modal-specific (speech/text) pre/post-nets. After preprocessing the speech/text input through the pre-nets, the shared encoder-decoder network models the sequence to sequence transformation, and then the post-nets generate the output in the speech/text modality based on the decoder output. Particularly, SpeechT5 can pre-train on a large scale of unlabeled speech and text data to improve the capability of the speech and textual modeling. To align the textual and speech information into a unified semantic space, we propose a cross-modal vector quantization method with random mixing-up to bridge speech and text. Extensive evaluations on a wide variety of spoken language processing tasks, including voice conversion, automatic speech recognition, text to speech, and speaker identification, show the superiority of the proposed SpeechT5 framework.
Multi-View Self-Attention Based Transformer for Speaker Recognition
Oct 11, 2021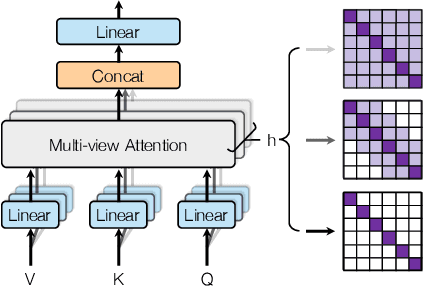
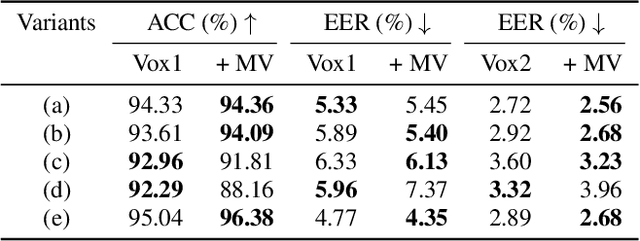
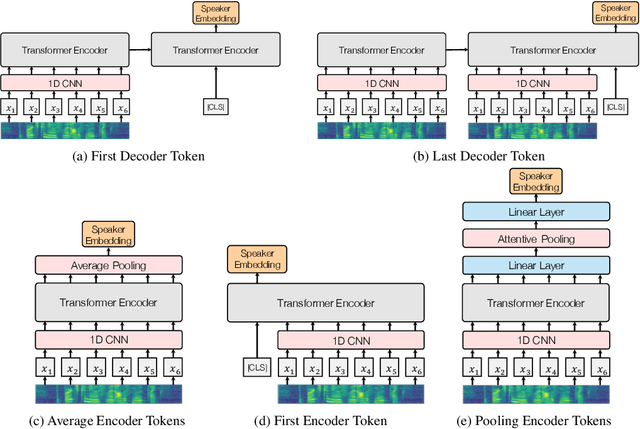
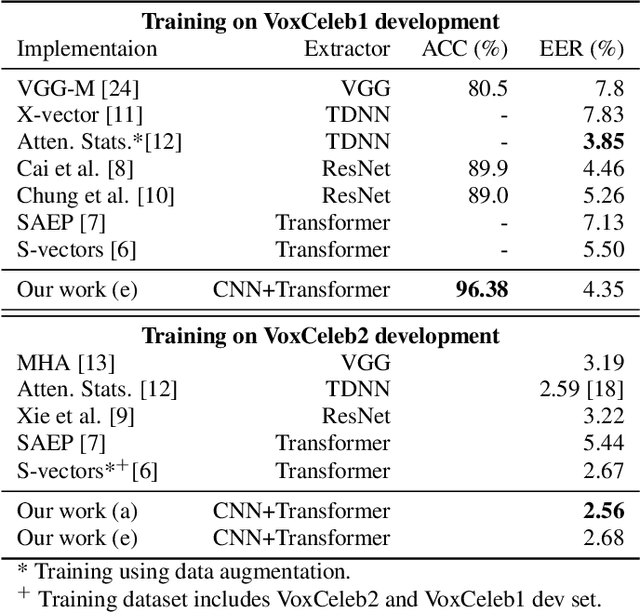
Initially developed for natural language processing (NLP), Transformer model is now widely used for speech processing tasks such as speaker recognition, due to its powerful sequence modeling capabilities. However, conventional self-attention mechanisms are originally designed for modeling textual sequence without considering the characteristics of speech and speaker modeling. Besides, different Transformer variants for speaker recognition have not been well studied. In this work, we propose a novel multi-view self-attention mechanism and present an empirical study of different Transformer variants with or without the proposed attention mechanism for speaker recognition. Specifically, to balance the capabilities of capturing global dependencies and modeling the locality, we propose a multi-view self-attention mechanism for speaker Transformer, in which different attention heads can attend to different ranges of the receptive field. Furthermore, we introduce and compare five Transformer variants with different network architectures, embedding locations, and pooling methods to learn speaker embeddings. Experimental results on the VoxCeleb1 and VoxCeleb2 datasets show that the proposed multi-view self-attention mechanism achieves improvement in the performance of speaker recognition, and the proposed speaker Transformer network attains excellent results compared with state-of-the-art models.
An Encoder-Decoder Based Audio Captioning System With Transfer and Reinforcement Learning
Aug 05, 2021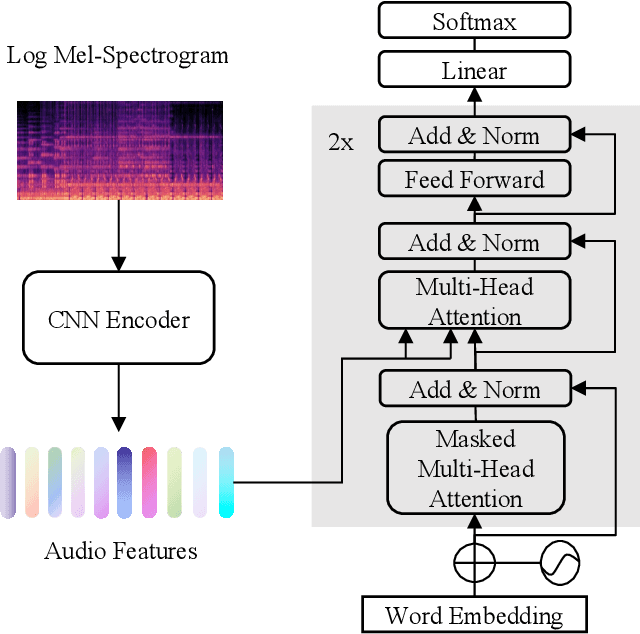
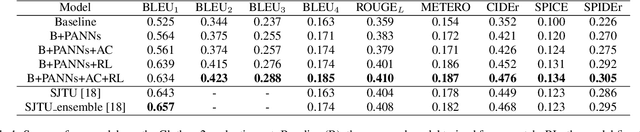


Automated audio captioning aims to use natural language to describe the content of audio data. This paper presents an audio captioning system with an encoder-decoder architecture, where the decoder predicts words based on audio features extracted by the encoder. To improve the proposed system, transfer learning from either an upstream audio-related task or a large in-domain dataset is introduced to mitigate the problem induced by data scarcity. Besides, evaluation metrics are incorporated into the optimization of the model with reinforcement learning, which helps address the problem of ``exposure bias'' induced by ``teacher forcing'' training strategy and the mismatch between the evaluation metrics and the loss function. The resulting system was ranked 3rd in DCASE 2021 Task 6. Ablation studies are carried out to investigate how much each element in the proposed system can contribute to final performance. The results show that the proposed techniques significantly improve the scores of the evaluation metrics, however, reinforcement learning may impact adversely on the quality of the generated captions.
CL4AC: A Contrastive Loss for Audio Captioning
Jul 21, 2021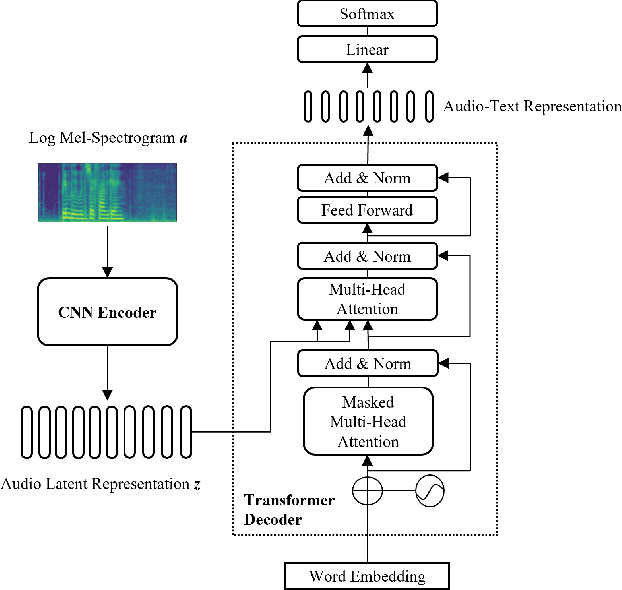

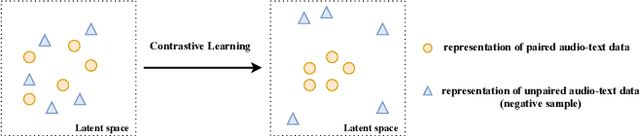

Automated Audio captioning (AAC) is a cross-modal translation task that aims to use natural language to describe the content of an audio clip. As shown in the submissions received for Task 6 of the DCASE 2021 Challenges, this problem has received increasing interest in the community. The existing AAC systems are usually based on an encoder-decoder architecture, where the audio signal is encoded into a latent representation, and aligned with its corresponding text descriptions, then a decoder is used to generate the captions. However, training of an AAC system often encounters the problem of data scarcity, which may lead to inaccurate representation and audio-text alignment. To address this problem, we propose a novel encoder-decoder framework called Contrastive Loss for Audio Captioning (CL4AC). In CL4AC, the self-supervision signals derived from the original audio-text paired data are used to exploit the correspondences between audio and texts by contrasting samples, which can improve the quality of latent representation and the alignment between audio and texts, while trained with limited data. Experiments are performed on the Clotho dataset to show the effectiveness of our proposed approach.
Token-Level Supervised Contrastive Learning for Punctuation Restoration
Jul 19, 2021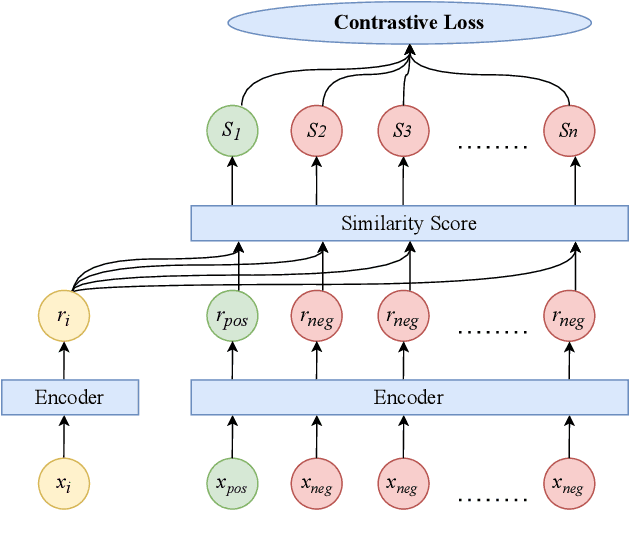
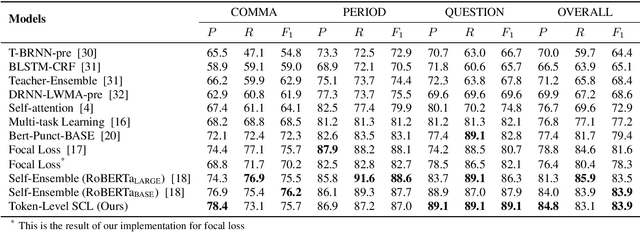
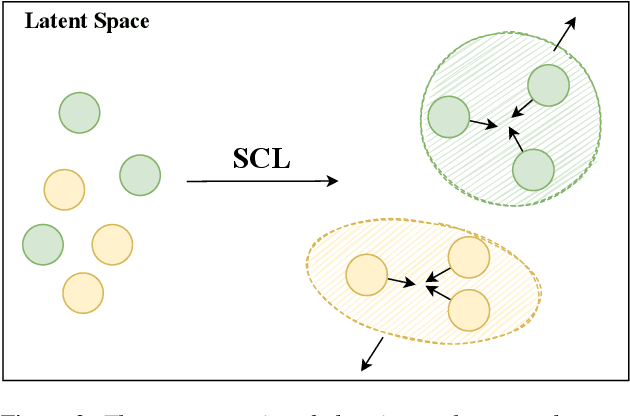

Punctuation is critical in understanding natural language text. Currently, most automatic speech recognition (ASR) systems do not generate punctuation, which affects the performance of downstream tasks, such as intent detection and slot filling. This gives rise to the need for punctuation restoration. Recent work in punctuation restoration heavily utilizes pre-trained language models without considering data imbalance when predicting punctuation classes. In this work, we address this problem by proposing a token-level supervised contrastive learning method that aims at maximizing the distance of representation of different punctuation marks in the embedding space. The result shows that training with token-level supervised contrastive learning obtains up to 3.2% absolute F1 improvement on the test set.
Exploring Machine Speech Chain for Domain Adaptation and Few-Shot Speaker Adaptation
Apr 08, 2021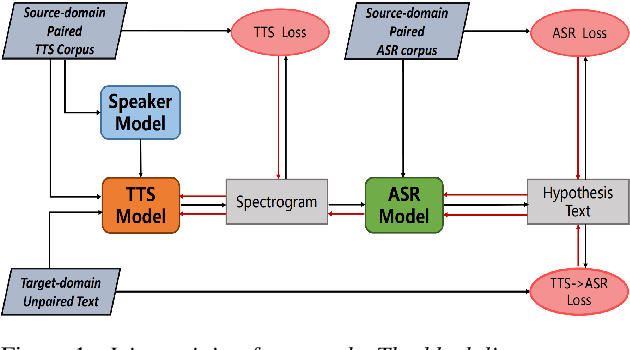
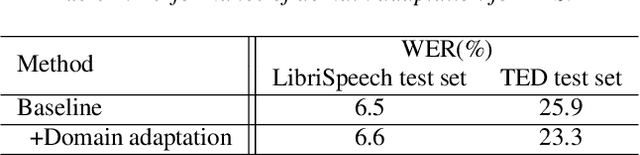
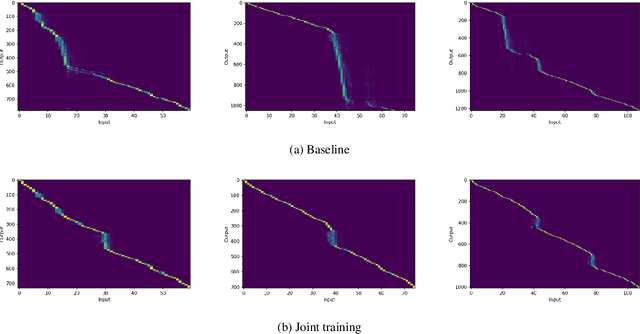
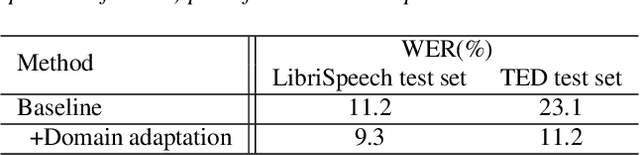
Machine Speech Chain, which integrates both end-to-end (E2E) automatic speech recognition (ASR) and text-to-speech (TTS) into one circle for joint training, has been proven to be effective in data augmentation by leveraging large amounts of unpaired data. In this paper, we explore the TTS->ASR pipeline in speech chain to do domain adaptation for both neural TTS and E2E ASR models, with only text data from target domain. We conduct experiments by adapting from audiobook domain (LibriSpeech) to presentation domain (TED-LIUM), there is a relative word error rate (WER) reduction of 10% for the E2E ASR model on the TED-LIUM test set, and a relative WER reduction of 51.5% in synthetic speech generated by neural TTS in the presentation domain. Further, we apply few-shot speaker adaptation for the E2E ASR by using a few utterances from target speakers in an unsupervised way, results in additional gains.
Auto-KWS 2021 Challenge: Task, Datasets, and Baselines
Mar 31, 2021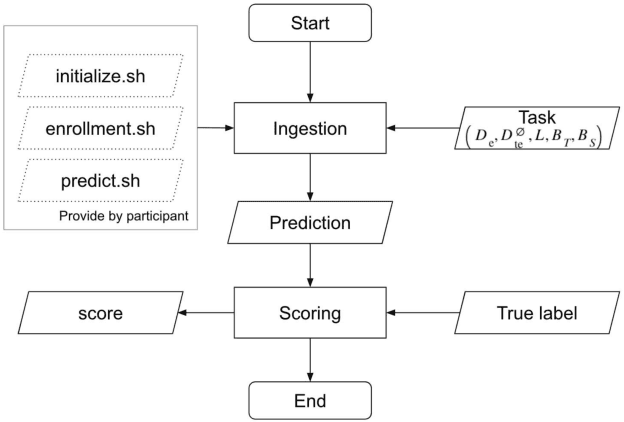

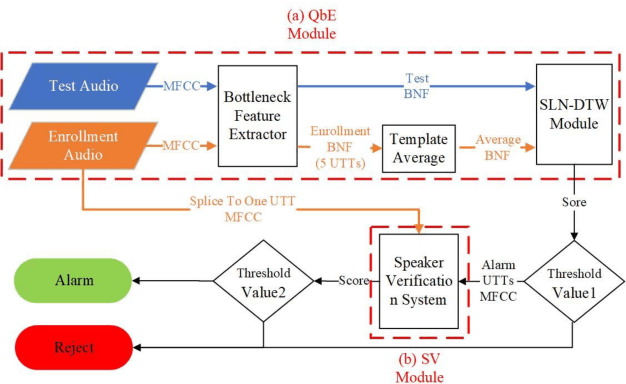
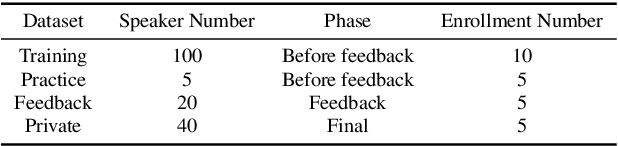
Auto-KWS 2021 challenge calls for automated machine learning (AutoML) solutions to automate the process of applying machine learning to a customized keyword spotting task. Compared with other keyword spotting tasks, Auto-KWS challenge has the following three characteristics: 1) The challenge focuses on the problem of customized keyword spotting, where the target device can only be awakened by an enrolled speaker with his specified keyword. The speaker can use any language and accent to define his keyword. 2) All dataset of the challenge is recorded in realistic environment. It is to simulate different user scenarios. 3) Auto-KWS is a "code competition", where participants need to submit AutoML solutions, then the platform automatically runs the enrollment and prediction steps with the submitted code.This challenge aims at promoting the development of a more personalized and flexible keyword spotting system. Two baseline systems are provided to all participants as references.
AutoSpeech 2020: The Second Automated Machine Learning Challenge for Speech Classification
Oct 25, 2020
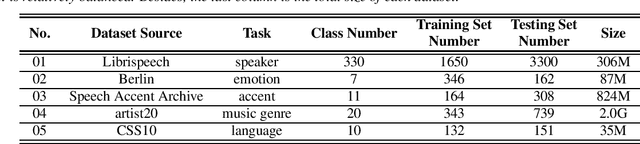
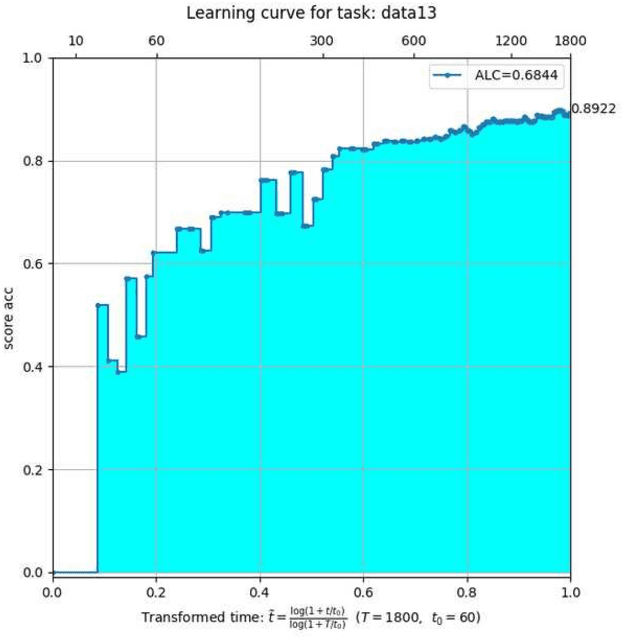
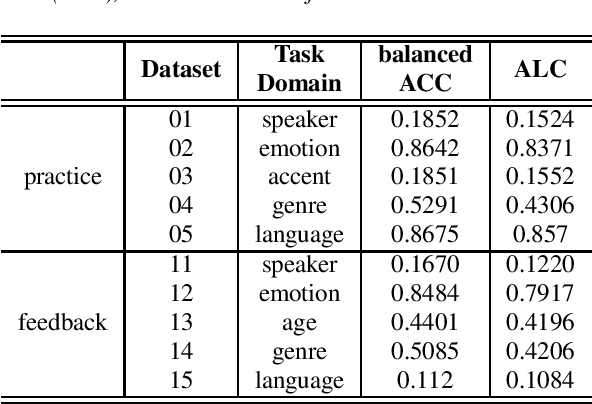
The AutoSpeech challenge calls for automated machine learning (AutoML) solutions to automate the process of applying machine learning to speech processing tasks. These tasks, which cover a large variety of domains, will be shown to the automated system in a random order. Each time when the tasks are switched, the information of the new task will be hinted with its corresponding training set. Thus, every submitted solution should contain an adaptation routine which adapts the system to the new task. Compared to the first edition, the 2020 edition includes advances of 1) more speech tasks, 2) noisier data in each task, 3) a modified evaluation metric. This paper outlines the challenge and describe the competition protocol, datasets, evaluation metric, starting kit, and baseline systems.
MetaMix: Improved Meta-Learning with Interpolation-based Consistency Regularization
Oct 10, 2020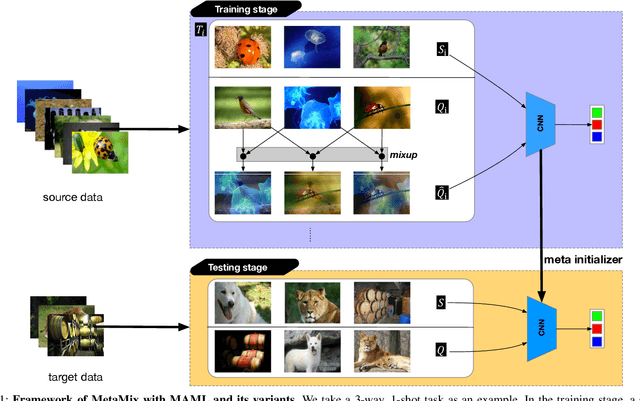
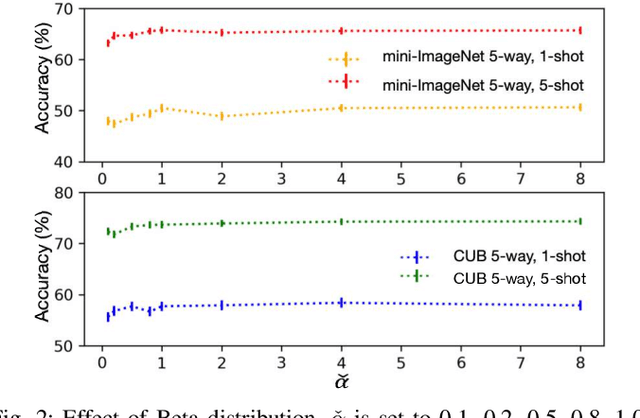
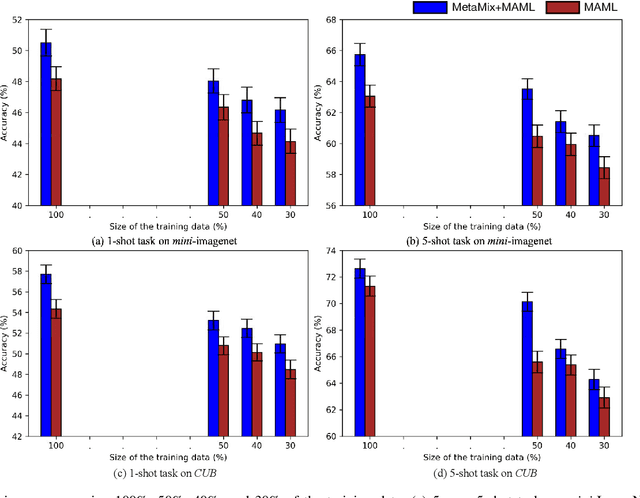
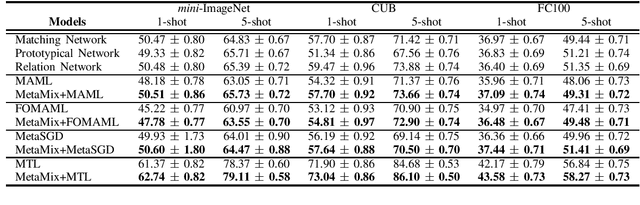
Model-Agnostic Meta-Learning (MAML) and its variants are popular few-shot classification methods. They train an initializer across a variety of sampled learning tasks (also known as episodes) such that the initialized model can adapt quickly to new tasks. However, current MAML-based algorithms have limitations in forming generalizable decision boundaries. In this paper, we propose an approach called MetaMix. It generates virtual feature-target pairs within each episode to regularize the backbone models. MetaMix can be integrated with any of the MAML-based algorithms and learn the decision boundaries generalizing better to new tasks. Experiments on the mini-ImageNet, CUB, and FC100 datasets show that MetaMix improves the performance of MAML-based algorithms and achieves state-of-the-art result when integrated with Meta-Transfer Learning.