 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBridging Scale Discrepancies in Robotic Control via Language-Based Action Representations
Dec 09, 2025Recent end-to-end robotic manipulation research increasingly adopts architectures inspired by large language models to enable robust manipulation. However, a critical challenge arises from severe distribution shifts between robotic action data, primarily due to substantial numerical variations in action commands across diverse robotic platforms and tasks, hindering the effective transfer of pretrained knowledge. To address this limitation, we propose a semantically grounded linguistic representation to normalize actions for efficient pretraining. Unlike conventional discretized action representations that are sensitive to numerical scales, the motion representation specifically disregards numeric scale effects, emphasizing directionality instead. This abstraction mitigates distribution shifts, yielding a more generalizable pretraining representation. Moreover, using the motion representation narrows the feature distance between action tokens and standard vocabulary tokens, mitigating modality gaps. Multi-task experiments on two benchmarks demonstrate that the proposed method significantly improves generalization performance and transferability in robotic manipulation tasks.
GeoSketch: A Neural-Symbolic Approach to Geometric Multimodal Reasoning with Auxiliary Line Construction and Affine Transformation
Sep 26, 2025Geometric Problem Solving (GPS) poses a unique challenge for Multimodal Large Language Models (MLLMs), requiring not only the joint interpretation of text and diagrams but also iterative visuospatial reasoning. While existing approaches process diagrams as static images, they lack the capacity for dynamic manipulation - a core aspect of human geometric reasoning involving auxiliary line construction and affine transformations. We present GeoSketch, a neural-symbolic framework that recasts geometric reasoning as an interactive perception-reasoning-action loop. GeoSketch integrates: (1) a Perception module that abstracts diagrams into structured logic forms, (2) a Symbolic Reasoning module that applies geometric theorems to decide the next deductive step, and (3) a Sketch Action module that executes operations such as drawing auxiliary lines or applying transformations, thereby updating the diagram in a closed loop. To train this agent, we develop a two-stage pipeline: supervised fine-tuning on 2,000 symbolic-curated trajectories followed by reinforcement learning with dense, symbolic rewards to enhance robustness and strategic exploration. To evaluate this paradigm, we introduce the GeoSketch Benchmark, a high-quality set of 390 geometry problems requiring auxiliary construction or affine transformations. Experiments on strong MLLM baselines demonstrate that GeoSketch significantly improves stepwise reasoning accuracy and problem-solving success over static perception methods. By unifying hierarchical decision-making, executable visual actions, and symbolic verification, GeoSketch advances multimodal reasoning from static interpretation to dynamic, verifiable interaction, establishing a new foundation for solving complex visuospatial problems.
OnlineMate: An LLM-Based Multi-Agent Companion System for Cognitive Support in Online Learning
Sep 18, 2025In online learning environments, students often lack personalized peer interactions, which play a crucial role in supporting cognitive development and learning engagement. Although previous studies have utilized large language models (LLMs) to simulate interactive dynamic learning environments for students, these interactions remain limited to conversational exchanges, lacking insights and adaptations to the learners' individualized learning and cognitive states. As a result, students' interest in discussions with AI learning companions is low, and they struggle to gain inspiration from such interactions. To address this challenge, we propose OnlineMate, a multi-agent learning companion system driven by LLMs that integrates the Theory of Mind (ToM). OnlineMate is capable of simulating peer-like agent roles, adapting to learners' cognitive states during collaborative discussions, and inferring their psychological states, such as misunderstandings, confusion, or motivation. By incorporating Theory of Mind capabilities, the system can dynamically adjust its interaction strategies to support the development of higher-order thinking and cognition. Experimental results in simulated learning scenarios demonstrate that OnlineMate effectively fosters deep learning and discussions while enhancing cognitive engagement in online educational settings.
Wisdom of the Crowd: Reinforcement Learning from Coevolutionary Collective Feedback
Aug 17, 2025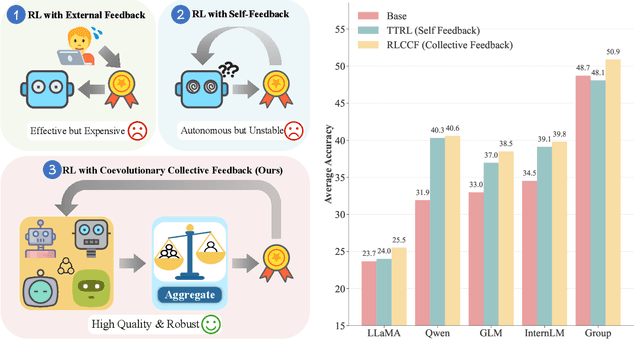
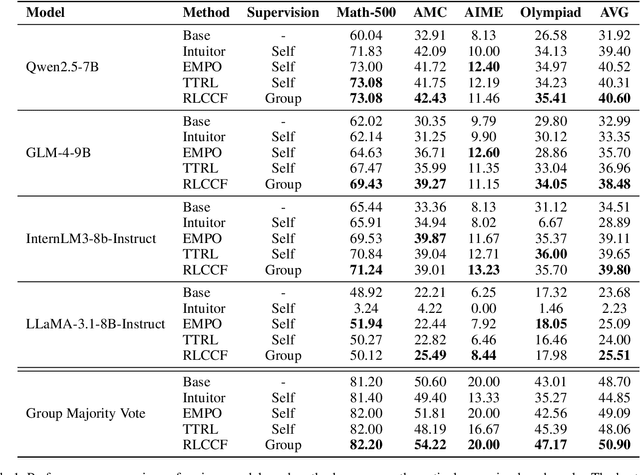
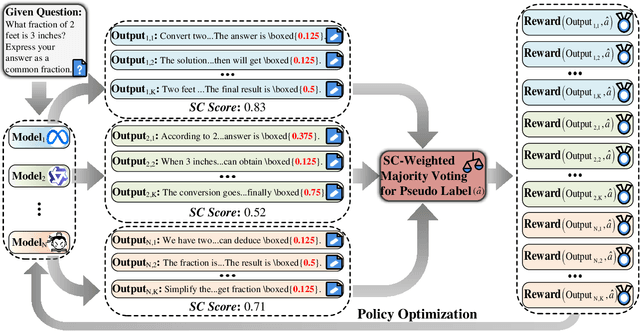
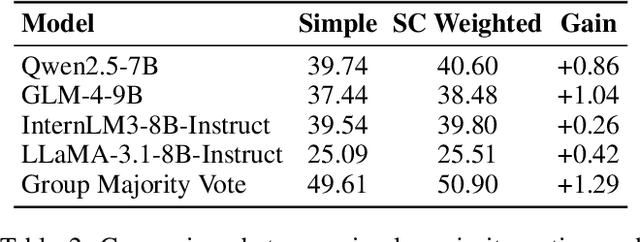
Reinforcement learning (RL) has significantly enhanced the reasoning capabilities of large language models (LLMs), but its reliance on expensive human-labeled data or complex reward models severely limits scalability. While existing self-feedback methods aim to address this problem, they are constrained by the capabilities of a single model, which can lead to overconfidence in incorrect answers, reward hacking, and even training collapse. To this end, we propose Reinforcement Learning from Coevolutionary Collective Feedback (RLCCF), a novel RL framework that enables multi-model collaborative evolution without external supervision. Specifically, RLCCF optimizes the ability of a model collective by maximizing its Collective Consistency (CC), which jointly trains a diverse ensemble of LLMs and provides reward signals by voting on collective outputs. Moreover, each model's vote is weighted by its Self-Consistency (SC) score, ensuring that more confident models contribute more to the collective decision. Benefiting from the diverse output distributions and complementary abilities of multiple LLMs, RLCCF enables the model collective to continuously enhance its reasoning ability through coevolution. Experiments on four mainstream open-source LLMs across four mathematical reasoning benchmarks demonstrate that our framework yields significant performance gains, achieving an average relative improvement of 16.72\% in accuracy. Notably, RLCCF not only improves the performance of individual models but also enhances the group's majority-voting accuracy by 4.51\%, demonstrating its ability to extend the collective capability boundary of the model collective.
Exploring and Exploiting the Inherent Efficiency within Large Reasoning Models for Self-Guided Efficiency Enhancement
Jun 18, 2025Recent advancements in large reasoning models (LRMs) have significantly enhanced language models' capabilities in complex problem-solving by emulating human-like deliberative thinking. However, these models often exhibit overthinking (i.e., the generation of unnecessarily verbose and redundant content), which hinders efficiency and inflates inference cost. In this work, we explore the representational and behavioral origins of this inefficiency, revealing that LRMs inherently possess the capacity for more concise reasoning. Empirical analyses show that correct reasoning paths vary significantly in length, and the shortest correct responses often suffice, indicating untapped efficiency potential. Exploiting these findings, we propose two lightweight methods to enhance LRM efficiency. First, we introduce Efficiency Steering, a training-free activation steering technique that modulates reasoning behavior via a single direction in the model's representation space. Second, we develop Self-Rewarded Efficiency RL, a reinforcement learning framework that dynamically balances task accuracy and brevity by rewarding concise correct solutions. Extensive experiments on seven LRM backbones across multiple mathematical reasoning benchmarks demonstrate that our methods significantly reduce reasoning length while preserving or improving task performance. Our results highlight that reasoning efficiency can be improved by leveraging and guiding the intrinsic capabilities of existing models in a self-guided manner.
RAG+: Enhancing Retrieval-Augmented Generation with Application-Aware Reasoning
Jun 13, 2025The integration of external knowledge through Retrieval-Augmented Generation (RAG) has become foundational in enhancing large language models (LLMs) for knowledge-intensive tasks. However, existing RAG paradigms often overlook the cognitive step of applying knowledge, leaving a gap between retrieved facts and task-specific reasoning. In this work, we introduce RAG+, a principled and modular extension that explicitly incorporates application-aware reasoning into the RAG pipeline. RAG+ constructs a dual corpus consisting of knowledge and aligned application examples, created either manually or automatically, and retrieves both jointly during inference. This design enables LLMs not only to access relevant information but also to apply it within structured, goal-oriented reasoning processes. Experiments across mathematical, legal, and medical domains, conducted on multiple models, demonstrate that RAG+ consistently outperforms standard RAG variants, achieving average improvements of 3-5%, and peak gains up to 7.5% in complex scenarios. By bridging retrieval with actionable application, RAG+ advances a more cognitively grounded framework for knowledge integration, representing a step toward more interpretable and capable LLMs.
Com$^2$: A Causal-Guided Benchmark for Exploring Complex Commonsense Reasoning in Large Language Models
Jun 08, 2025Large language models (LLMs) have mastered abundant simple and explicit commonsense knowledge through pre-training, enabling them to achieve human-like performance in simple commonsense reasoning. Nevertheless, LLMs struggle to reason with complex and implicit commonsense knowledge that is derived from simple ones (such as understanding the long-term effects of certain events), an aspect humans tend to focus on more. Existing works focus on complex tasks like math and code, while complex commonsense reasoning remains underexplored due to its uncertainty and lack of structure. To fill this gap and align with real-world concerns, we propose a benchmark Com$^2$ focusing on complex commonsense reasoning. We first incorporate causal event graphs to serve as structured complex commonsense. Then we adopt causal theory~(e.g., intervention) to modify the causal event graphs and obtain different scenarios that meet human concerns. Finally, an LLM is employed to synthesize examples with slow thinking, which is guided by the logical relationships in the modified causal graphs. Furthermore, we use detective stories to construct a more challenging subset. Experiments show that LLMs struggle in reasoning depth and breadth, while post-training and slow thinking can alleviate this. The code and data are available at https://github.com/Waste-Wood/Com2.
Predicting ICU In-Hospital Mortality Using Adaptive Transformer Layer Fusion
Jun 06, 2025



Early identification of high-risk ICU patients is crucial for directing limited medical resources. We introduce ALFIA (Adaptive Layer Fusion with Intelligent Attention), a modular, attention-based architecture that jointly trains LoRA (Low-Rank Adaptation) adapters and an adaptive layer-weighting mechanism to fuse multi-layer semantic features from a BERT backbone. Trained on our rigorous cw-24 (CriticalWindow-24) benchmark, ALFIA surpasses state-of-the-art tabular classifiers in AUPRC while preserving a balanced precision-recall profile. The embeddings produced by ALFIA's fusion module, capturing both fine-grained clinical cues and high-level concepts, enable seamless pairing with GBDTs (CatBoost/LightGBM) as ALFIA-boost, and deep neuro networks as ALFIA-nn, yielding additional performance gains. Our experiments confirm ALFIA's superior early-warning performance, by operating directly on routine clinical text, it furnishes clinicians with a convenient yet robust tool for risk stratification and timely intervention in critical-care settings.
CrossICL: Cross-Task In-Context Learning via Unsupervised Demonstration Transfer
May 30, 2025In-Context Learning (ICL) enhances the performance of large language models (LLMs) with demonstrations. However, obtaining these demonstrations primarily relies on manual effort. In most real-world scenarios, users are often unwilling or unable to provide such demonstrations. Inspired by the human analogy, we explore a new ICL paradigm CrossICL to study how to utilize existing source task demonstrations in the ICL for target tasks, thereby obtaining reliable guidance without any additional manual effort. To explore this, we first design a two-stage alignment strategy to mitigate the interference caused by gaps across tasks, as the foundation for our experimental exploration. Based on it, we conduct comprehensive exploration of CrossICL, with 875 NLP tasks from the Super-NI benchmark and six types of LLMs, including GPT-4o. Experimental results demonstrate the effectiveness of CrossICL and provide valuable insights on questions like the criteria for selecting cross-task demonstrations, as well as the types of task-gap-induced interference in CrossICL.
ExpeTrans: LLMs Are Experiential Transfer Learners
May 29, 2025Recent studies provide large language models (LLMs) with textual task-solving experiences via prompts to improve their performance. However, previous methods rely on substantial human labor or time to gather such experiences for each task, which is impractical given the growing variety of task types in user queries to LLMs. To address this issue, we design an autonomous experience transfer framework to explore whether LLMs can mimic human cognitive intelligence to autonomously transfer experience from existing source tasks to newly encountered target tasks. This not only allows the acquisition of experience without extensive costs of previous methods, but also offers a novel path for the generalization of LLMs. Experimental results on 13 datasets demonstrate that our framework effectively improves the performance of LLMs. Furthermore, we provide a detailed analysis of each module in the framework.