 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWisdom of the Crowd: Reinforcement Learning from Coevolutionary Collective Feedback
Paper and Code
Aug 17, 2025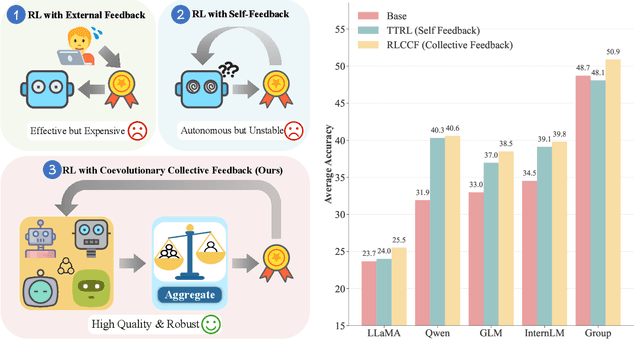
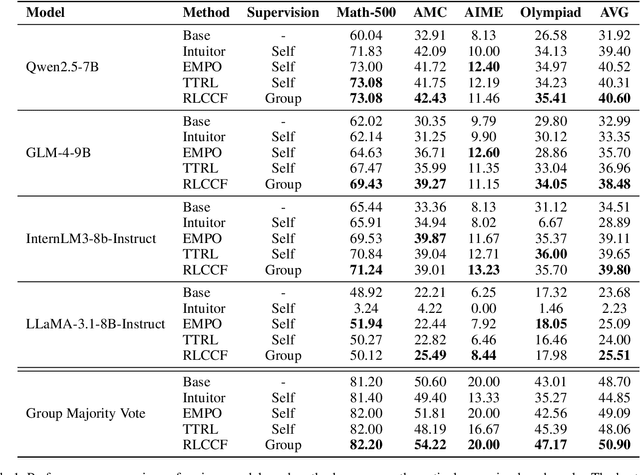
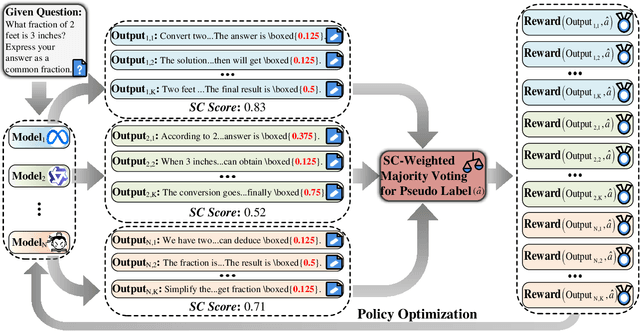
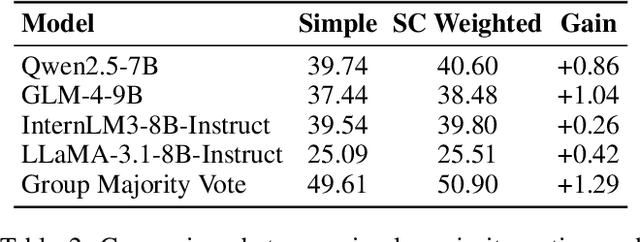
Reinforcement learning (RL) has significantly enhanced the reasoning capabilities of large language models (LLMs), but its reliance on expensive human-labeled data or complex reward models severely limits scalability. While existing self-feedback methods aim to address this problem, they are constrained by the capabilities of a single model, which can lead to overconfidence in incorrect answers, reward hacking, and even training collapse. To this end, we propose Reinforcement Learning from Coevolutionary Collective Feedback (RLCCF), a novel RL framework that enables multi-model collaborative evolution without external supervision. Specifically, RLCCF optimizes the ability of a model collective by maximizing its Collective Consistency (CC), which jointly trains a diverse ensemble of LLMs and provides reward signals by voting on collective outputs. Moreover, each model's vote is weighted by its Self-Consistency (SC) score, ensuring that more confident models contribute more to the collective decision. Benefiting from the diverse output distributions and complementary abilities of multiple LLMs, RLCCF enables the model collective to continuously enhance its reasoning ability through coevolution. Experiments on four mainstream open-source LLMs across four mathematical reasoning benchmarks demonstrate that our framework yields significant performance gains, achieving an average relative improvement of 16.72\% in accuracy. Notably, RLCCF not only improves the performance of individual models but also enhances the group's majority-voting accuracy by 4.51\%, demonstrating its ability to extend the collective capability boundary of the model collective.