 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBridging Scale Discrepancies in Robotic Control via Language-Based Action Representations
Dec 09, 2025Recent end-to-end robotic manipulation research increasingly adopts architectures inspired by large language models to enable robust manipulation. However, a critical challenge arises from severe distribution shifts between robotic action data, primarily due to substantial numerical variations in action commands across diverse robotic platforms and tasks, hindering the effective transfer of pretrained knowledge. To address this limitation, we propose a semantically grounded linguistic representation to normalize actions for efficient pretraining. Unlike conventional discretized action representations that are sensitive to numerical scales, the motion representation specifically disregards numeric scale effects, emphasizing directionality instead. This abstraction mitigates distribution shifts, yielding a more generalizable pretraining representation. Moreover, using the motion representation narrows the feature distance between action tokens and standard vocabulary tokens, mitigating modality gaps. Multi-task experiments on two benchmarks demonstrate that the proposed method significantly improves generalization performance and transferability in robotic manipulation tasks.
Visualizing attention zones in machine reading comprehension models
Oct 28, 2024



The attention mechanism plays an important role in the machine reading comprehension (MRC) model. Here, we describe a pipeline for building an MRC model with a pretrained language model and visualizing the effect of each attention zone in different layers, which can indicate the explainability of the model. With the presented protocol and accompanying code, researchers can easily visualize the relevance of each attention zone in the MRC model. This approach can be generalized to other pretrained language models.
A Static and Dynamic Attention Framework for Multi Turn Dialogue Generation
Oct 28, 2024



Recently, research on open domain dialogue systems have attracted extensive interests of academic and industrial researchers. The goal of an open domain dialogue system is to imitate humans in conversations. Previous works on single turn conversation generation have greatly promoted the research of open domain dialogue systems. However, understanding multiple single turn conversations is not equal to the understanding of multi turn dialogue due to the coherent and context dependent properties of human dialogue. Therefore, in open domain multi turn dialogue generation, it is essential to modeling the contextual semantics of the dialogue history, rather than only according to the last utterance. Previous research had verified the effectiveness of the hierarchical recurrent encoder-decoder framework on open domain multi turn dialogue generation. However, using RNN-based model to hierarchically encoding the utterances to obtain the representation of dialogue history still face the problem of a vanishing gradient. To address this issue, in this paper, we proposed a static and dynamic attention-based approach to model the dialogue history and then generate open domain multi turn dialogue responses. Experimental results on Ubuntu and Opensubtitles datasets verify the effectiveness of the proposed static and dynamic attention-based approach on automatic and human evaluation metrics in various experimental settings. Meanwhile, we also empirically verify the performance of combining the static and dynamic attentions on open domain multi turn dialogue generation.
* published as a journal paper at ACM Transactions on Information Systems 2023. 30 pages, 6 figures
A Stack-Propagation Framework for Low-Resource Personalized Dialogue Generation
Oct 26, 2024



With the resurgent interest in building open-domain dialogue systems, the dialogue generation task has attracted increasing attention over the past few years. This task is usually formulated as a conditional generation problem, which aims to generate a natural and meaningful response given dialogue contexts and specific constraints, such as persona. And maintaining a consistent persona is essential for the dialogue systems to gain trust from the users. Although tremendous advancements have been brought, traditional persona-based dialogue models are typically trained by leveraging a large number of persona-dense dialogue examples. Yet, such persona-dense training data are expensive to obtain, leading to a limited scale. This work presents a novel approach to learning from limited training examples by regarding consistency understanding as a regularization of response generation. To this end, we propose a novel stack-propagation framework for learning a generation and understanding pipeline.Specifically, the framework stacks a Transformer encoder and two Transformer decoders, where the first decoder models response generation and the second serves as a regularizer and jointly models response generation and consistency understanding. The proposed framework can benefit from the stacked encoder and decoders to learn from much smaller personalized dialogue data while maintaining competitive performance. Under different low-resource settings, subjective and objective evaluations prove that the stack-propagation framework outperforms strong baselines in response quality and persona consistency and largely overcomes the shortcomings of traditional models that rely heavily on the persona-dense dialogue data.
* published as a journal paper at ACM Transactions on Information Systems 2023. 35 pages, 5 figures
Policy-driven Knowledge Selection and Response Generation for Document-grounded Dialogue
Oct 21, 2024



Document-grounded dialogue (DGD) uses documents as external knowledge for dialogue generation. Correctly understanding the dialogue context is crucial for selecting knowledge from the document and generating proper responses. In this paper, we propose using a dialogue policy to help the dialogue understanding in DGD. Our dialogue policy consists of two kinds of guiding signals: utterance function and topic transfer intent. The utterance function reflects the purpose and style of an utterance, and the topic transfer intent reflects the topic and content of an utterance. We propose a novel framework exploiting our dialogue policy for two core tasks in DGD, namely knowledge selection (KS) and response generation (RG). The framework consists of two modules: the Policy planner leverages policy-aware dialogue representation to select knowledge and predict the policy of the response; the generator uses policy/knowledge-aware dialogue representation for response generation. Our policy-driven model gets state-of-the-art performance on three public benchmarks and we provide a detailed analysis of the experimental results. Our code/data will be released on GitHub.
* 29 pages, 9 figures, 14 tables, TOIS 2024
Conversational Recommender System and Large Language Model Are Made for Each Other in E-commerce Pre-sales Dialogue
Oct 23, 2023



E-commerce pre-sales dialogue aims to understand and elicit user needs and preferences for the items they are seeking so as to provide appropriate recommendations. Conversational recommender systems (CRSs) learn user representation and provide accurate recommendations based on dialogue context, but rely on external knowledge. Large language models (LLMs) generate responses that mimic pre-sales dialogues after fine-tuning, but lack domain-specific knowledge for accurate recommendations. Intuitively, the strengths of LLM and CRS in E-commerce pre-sales dialogues are complementary, yet no previous work has explored this. This paper investigates the effectiveness of combining LLM and CRS in E-commerce pre-sales dialogues, proposing two collaboration methods: CRS assisting LLM and LLM assisting CRS. We conduct extensive experiments on a real-world dataset of Ecommerce pre-sales dialogues. We analyze the impact of two collaborative approaches with two CRSs and two LLMs on four tasks of Ecommerce pre-sales dialogue. We find that collaborations between CRS and LLM can be very effective in some cases.
Harnessing the Power of Large Language Models for Empathetic Response Generation: Empirical Investigations and Improvements
Oct 08, 2023Empathetic dialogue is an indispensable part of building harmonious social relationships and contributes to the development of a helpful AI. Previous approaches are mainly based on fine small-scale language models. With the advent of ChatGPT, the application effect of large language models (LLMs) in this field has attracted great attention. This work empirically investigates the performance of LLMs in generating empathetic responses and proposes three improvement methods of semantically similar in-context learning, two-stage interactive generation, and combination with the knowledge base. Extensive experiments show that LLMs can significantly benefit from our proposed methods and is able to achieve state-of-the-art performance in both automatic and human evaluations. Additionally, we explore the possibility of GPT-4 simulating human evaluators.
CLIP Models are Few-shot Learners: Empirical Studies on VQA and Visual Entailment
Mar 14, 2022
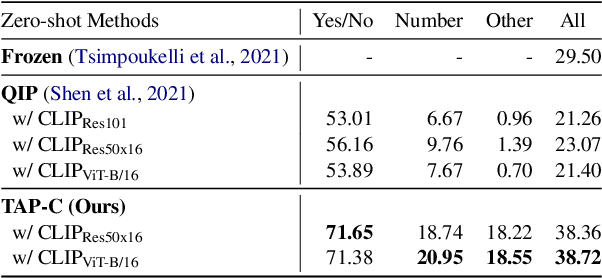
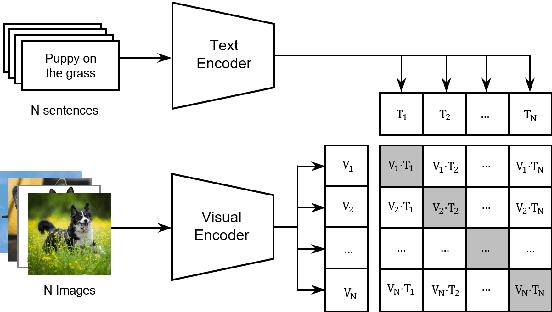
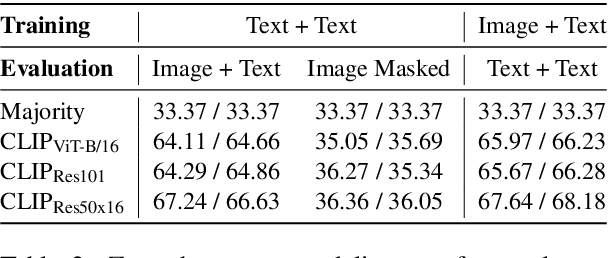
CLIP has shown a remarkable zero-shot capability on a wide range of vision tasks. Previously, CLIP is only regarded as a powerful visual encoder. However, after being pre-trained by language supervision from a large amount of image-caption pairs, CLIP itself should also have acquired some few-shot abilities for vision-language tasks. In this work, we empirically show that CLIP can be a strong vision-language few-shot learner by leveraging the power of language. We first evaluate CLIP's zero-shot performance on a typical visual question answering task and demonstrate a zero-shot cross-modality transfer capability of CLIP on the visual entailment task. Then we propose a parameter-efficient fine-tuning strategy to boost the few-shot performance on the vqa task. We achieve competitive zero/few-shot results on the visual question answering and visual entailment tasks without introducing any additional pre-training procedure.
Understanding Attention in Machine Reading Comprehension
Aug 26, 2021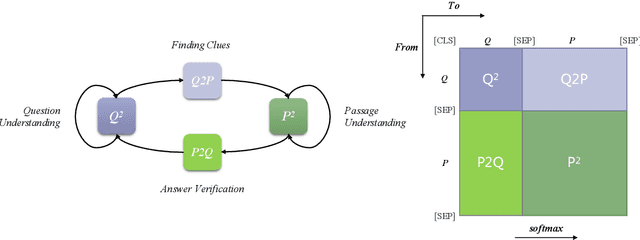
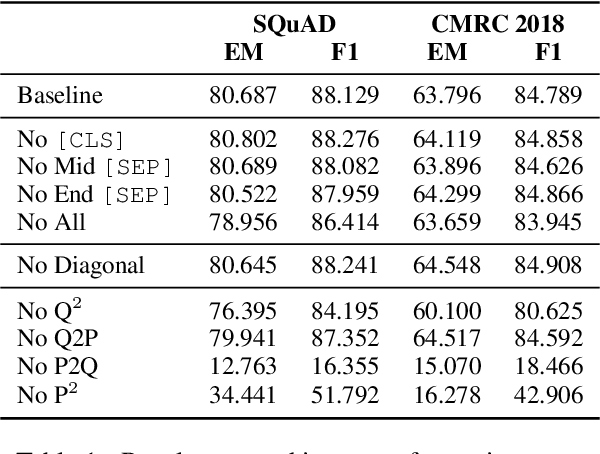
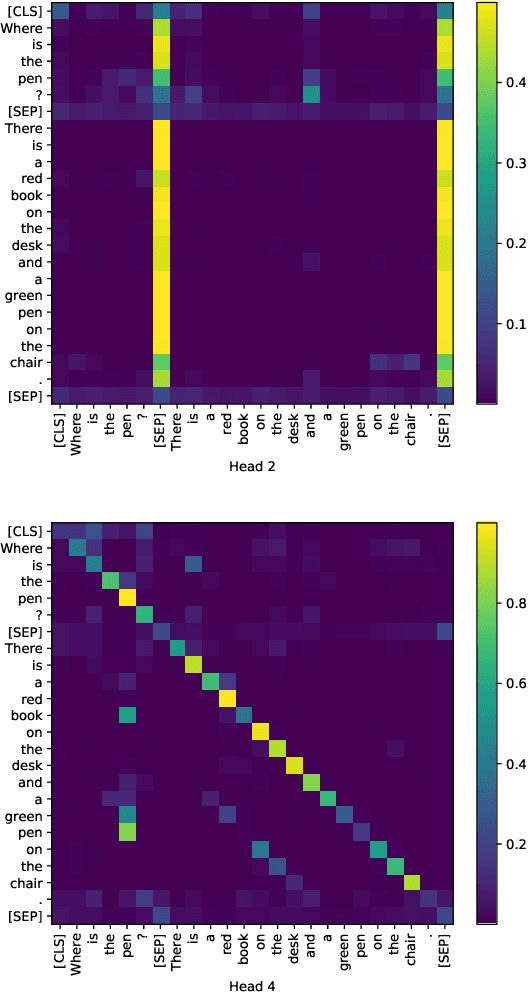
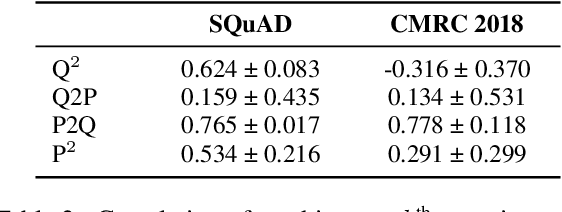
Achieving human-level performance on some of Machine Reading Comprehension (MRC) datasets is no longer challenging with the help of powerful Pre-trained Language Models (PLMs). However, the internal mechanism of these artifacts still remains unclear, placing an obstacle for further understanding these models. This paper focuses on conducting a series of analytical experiments to examine the relations between the multi-head self-attention and the final performance, trying to analyze the potential explainability in PLM-based MRC models. We perform quantitative analyses on SQuAD (English) and CMRC 2018 (Chinese), two span-extraction MRC datasets, on top of BERT, ALBERT, and ELECTRA in various aspects. We discover that {\em passage-to-question} and {\em passage understanding} attentions are the most important ones, showing strong correlations to the final performance than other parts. Through visualizations and case studies, we also observe several general findings on the attention maps, which could be helpful to understand how these models solve the questions.
BoB: BERT Over BERT for Training Persona-based Dialogue Models from Limited Personalized Data
Jun 14, 2021
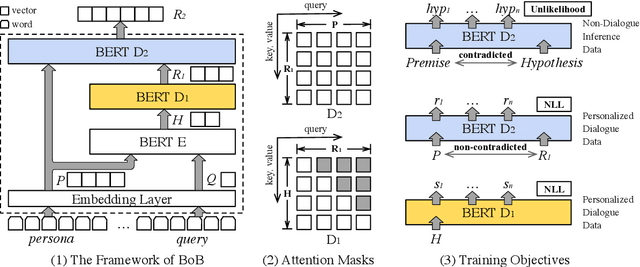
Maintaining consistent personas is essential for dialogue agents. Although tremendous advancements have been brought, the limited-scale of annotated persona-dense data are still barriers towards training robust and consistent persona-based dialogue models. In this work, we show how the challenges can be addressed by disentangling persona-based dialogue generation into two sub-tasks with a novel BERT-over-BERT (BoB) model. Specifically, the model consists of a BERT-based encoder and two BERT-based decoders, where one decoder is for response generation, and another is for consistency understanding. In particular, to learn the ability of consistency understanding from large-scale non-dialogue inference data, we train the second decoder in an unlikelihood manner. Under different limited data settings, both automatic and human evaluations demonstrate that the proposed model outperforms strong baselines in response quality and persona consistency.