 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLing and Ring 2.6 Technical Report: Efficient and Instant Agentic Intelligence at Trillion-Parameter Scale
Jun 13, 2026Efficient and scalable agentic intelligence requires models that can deliver both low-latency responses and strong reasoning capabilities while remaining practical to train, serve, and deploy. In this report, we present Ling-2.6 and Ring-2.6, a family of models designed to address this challenge at scale. Ling-2.6 is optimized for instant response generation and high capability per output token, whereas Ring-2.6 is tailored for deeper reasoning and more advanced agentic workflows. Instead of training from scratch, we upgrade the Ling-2.0 base model through architectural migration pre-training and large-scale post-training. This upgrade is guided by a unified co-design of model architecture, optimization objectives, serving systems, and agent training environments, enabling improvements in both model capability and deployment efficiency. At the architectural level, we introduce a hybrid linear attention design that integrates Lightning Attention with MLA, improving the efficiency of long-context training and decoding. To further enhance token efficiency, we optimize capability per output token through Evolutionary Chain-of-Thought, Linguistic Unit Policy Optimization, bidirectional preference alignment, and shortest-correct-response distillation. For agentic capabilities, we propose KPop, a reinforcement learning framework designed to support stable training of Ring-2.6-1T on large-scale environment-grounded data. KPop improves training efficiency through asynchronous scheduling across coding, search, tool use, and workflow execution, enabling scalable learning from complex agent-environment interactions. Together, Ling-2.6 and Ring-2.6 provide a practical pathway toward efficient, scalable, and open agentic systems. We open-source all checkpoints in the 2.6 family to support further research and development in practical agentic intelligence.
ExFusion: Efficient Transformer Training via Multi-Experts Fusion
Mar 30, 2026Mixture-of-Experts (MoE) models substantially improve performance by increasing the capacity of dense architectures. However, directly training MoE models requires considerable computational resources and introduces extra overhead in parameter storage and deployment. Therefore, it is critical to develop an approach that leverages the multi-expert capability of MoE to enhance performance while incurring minimal additional cost. To this end, we propose a novel pre-training approach, termed ExFusion, which improves the efficiency of Transformer training through multi-expert fusion. Specifically, during the initialization phase, ExFusion upcycles the feed-forward network (FFN) of the Transformer into a multi-expert configuration, where each expert is assigned a weight for later parameter fusion. During training, these weights allow multiple experts to be fused into a single unified expert equivalent to the original FFN, which is subsequently used for forward computation. As a result, ExFusion introduces multi-expert characteristics into the training process while incurring only marginal computational cost compared to standard dense training. After training, the learned weights are used to integrate multi-experts into a single unified expert, thereby eliminating additional overhead in storage and deployment. Extensive experiments on a variety of computer vision and natural language processing tasks demonstrate the effectiveness of the proposed method.
OnlineMate: An LLM-Based Multi-Agent Companion System for Cognitive Support in Online Learning
Sep 18, 2025In online learning environments, students often lack personalized peer interactions, which play a crucial role in supporting cognitive development and learning engagement. Although previous studies have utilized large language models (LLMs) to simulate interactive dynamic learning environments for students, these interactions remain limited to conversational exchanges, lacking insights and adaptations to the learners' individualized learning and cognitive states. As a result, students' interest in discussions with AI learning companions is low, and they struggle to gain inspiration from such interactions. To address this challenge, we propose OnlineMate, a multi-agent learning companion system driven by LLMs that integrates the Theory of Mind (ToM). OnlineMate is capable of simulating peer-like agent roles, adapting to learners' cognitive states during collaborative discussions, and inferring their psychological states, such as misunderstandings, confusion, or motivation. By incorporating Theory of Mind capabilities, the system can dynamically adjust its interaction strategies to support the development of higher-order thinking and cognition. Experimental results in simulated learning scenarios demonstrate that OnlineMate effectively fosters deep learning and discussions while enhancing cognitive engagement in online educational settings.
Wisdom of the Crowd: Reinforcement Learning from Coevolutionary Collective Feedback
Aug 17, 2025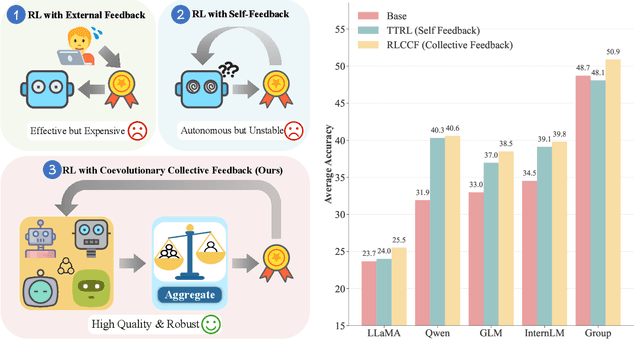
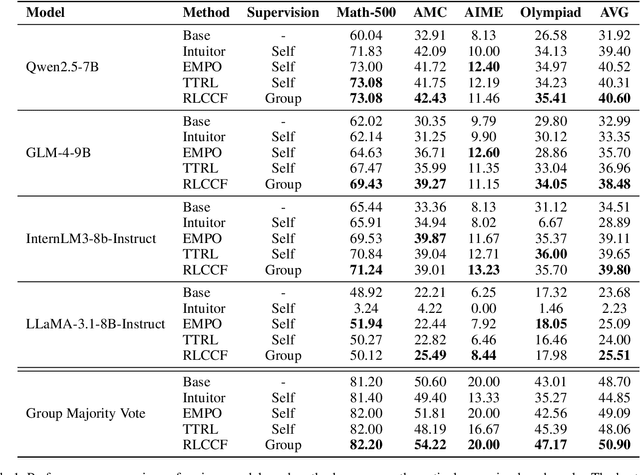
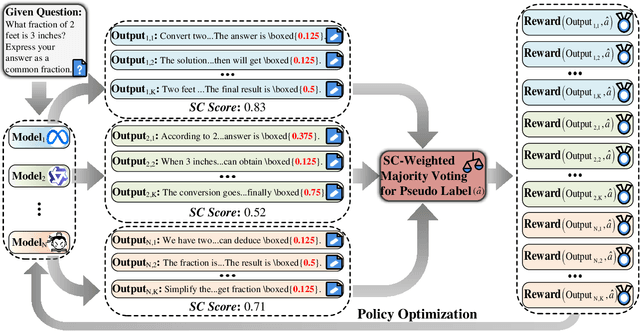
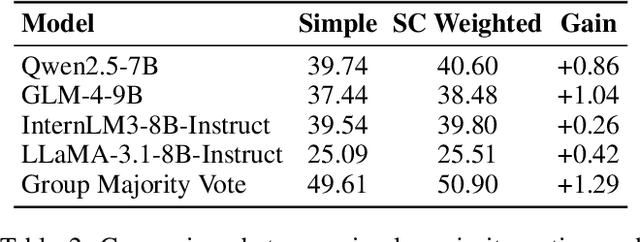
Reinforcement learning (RL) has significantly enhanced the reasoning capabilities of large language models (LLMs), but its reliance on expensive human-labeled data or complex reward models severely limits scalability. While existing self-feedback methods aim to address this problem, they are constrained by the capabilities of a single model, which can lead to overconfidence in incorrect answers, reward hacking, and even training collapse. To this end, we propose Reinforcement Learning from Coevolutionary Collective Feedback (RLCCF), a novel RL framework that enables multi-model collaborative evolution without external supervision. Specifically, RLCCF optimizes the ability of a model collective by maximizing its Collective Consistency (CC), which jointly trains a diverse ensemble of LLMs and provides reward signals by voting on collective outputs. Moreover, each model's vote is weighted by its Self-Consistency (SC) score, ensuring that more confident models contribute more to the collective decision. Benefiting from the diverse output distributions and complementary abilities of multiple LLMs, RLCCF enables the model collective to continuously enhance its reasoning ability through coevolution. Experiments on four mainstream open-source LLMs across four mathematical reasoning benchmarks demonstrate that our framework yields significant performance gains, achieving an average relative improvement of 16.72\% in accuracy. Notably, RLCCF not only improves the performance of individual models but also enhances the group's majority-voting accuracy by 4.51\%, demonstrating its ability to extend the collective capability boundary of the model collective.
EIAD: Explainable Industrial Anomaly Detection Via Multi-Modal Large Language Models
Mar 18, 2025Industrial Anomaly Detection (IAD) is critical to ensure product quality during manufacturing. Although existing zero-shot defect segmentation and detection methods have shown effectiveness, they cannot provide detailed descriptions of the defects. Furthermore, the application of large multi-modal models in IAD remains in its infancy, facing challenges in balancing question-answering (QA) performance and mask-based grounding capabilities, often owing to overfitting during the fine-tuning process. To address these challenges, we propose a novel approach that introduces a dedicated multi-modal defect localization module to decouple the dialog functionality from the core feature extraction. This decoupling is achieved through independent optimization objectives and tailored learning strategies. Additionally, we contribute to the first multi-modal industrial anomaly detection training dataset, named Defect Detection Question Answering (DDQA), encompassing a wide range of defect types and industrial scenarios. Unlike conventional datasets that rely on GPT-generated data, DDQA ensures authenticity and reliability and offers a robust foundation for model training. Experimental results demonstrate that our proposed method, Explainable Industrial Anomaly Detection Assistant (EIAD), achieves outstanding performance in defect detection and localization tasks. It not only significantly enhances accuracy but also improves interpretability. These advancements highlight the potential of EIAD for practical applications in industrial settings.
Graph of AI Ideas: Leveraging Knowledge Graphs and LLMs for AI Research Idea Generation
Mar 11, 2025Reading relevant scientific papers and analyzing research development trends is a critical step in generating new scientific ideas. However, the rapid increase in the volume of research literature and the complex citation relationships make it difficult for researchers to quickly analyze and derive meaningful research trends. The development of large language models (LLMs) has provided a novel approach for automatically summarizing papers and generating innovative research ideas. However, existing paper-based idea generation methods either simply input papers into LLMs via prompts or form logical chains of creative development based on citation relationships, without fully exploiting the semantic information embedded in these citations. Inspired by knowledge graphs and human cognitive processes, we propose a framework called the Graph of AI Ideas (GoAI) for the AI research field, which is dominated by open-access papers. This framework organizes relevant literature into entities within a knowledge graph and summarizes the semantic information contained in citations into relations within the graph. This organization effectively reflects the relationships between two academic papers and the advancement of the AI research field. Such organization aids LLMs in capturing the current progress of research, thereby enhancing their creativity. Experimental results demonstrate the effectiveness of our approach in generating novel, clear, and effective research ideas.
ReviewAgents: Bridging the Gap Between Human and AI-Generated Paper Reviews
Mar 11, 2025



Academic paper review is a critical yet time-consuming task within the research community. With the increasing volume of academic publications, automating the review process has become a significant challenge. The primary issue lies in generating comprehensive, accurate, and reasoning-consistent review comments that align with human reviewers' judgments. In this paper, we address this challenge by proposing ReviewAgents, a framework that leverages large language models (LLMs) to generate academic paper reviews. We first introduce a novel dataset, Review-CoT, consisting of 142k review comments, designed for training LLM agents. This dataset emulates the structured reasoning process of human reviewers-summarizing the paper, referencing relevant works, identifying strengths and weaknesses, and generating a review conclusion. Building upon this, we train LLM reviewer agents capable of structured reasoning using a relevant-paper-aware training method. Furthermore, we construct ReviewAgents, a multi-role, multi-LLM agent review framework, to enhance the review comment generation process. Additionally, we propose ReviewBench, a benchmark for evaluating the review comments generated by LLMs. Our experimental results on ReviewBench demonstrate that while existing LLMs exhibit a certain degree of potential for automating the review process, there remains a gap when compared to human-generated reviews. Moreover, our ReviewAgents framework further narrows this gap, outperforming advanced LLMs in generating review comments.
VLRMBench: A Comprehensive and Challenging Benchmark for Vision-Language Reward Models
Mar 10, 2025



Although large visual-language models (LVLMs) have demonstrated strong performance in multimodal tasks, errors may occasionally arise due to biases during the reasoning process. Recently, reward models (RMs) have become increasingly pivotal in the reasoning process. Specifically, process RMs evaluate each reasoning step, outcome RMs focus on the assessment of reasoning results, and critique RMs perform error analysis on the entire reasoning process, followed by corrections. However, existing benchmarks for vision-language RMs (VLRMs) typically assess only a single aspect of their capabilities (e.g., distinguishing between two answers), thus limiting the all-round evaluation and restricting the development of RMs in the visual-language domain. To address this gap, we propose a comprehensive and challenging benchmark, dubbed as VLRMBench, encompassing 12,634 questions. VLRMBench is constructed based on three distinct types of datasets, covering mathematical reasoning, hallucination understanding, and multi-image understanding. We design 12 tasks across three major categories, focusing on evaluating VLRMs in the aspects of process understanding, outcome judgment, and critique generation. Extensive experiments are conducted on 21 open-source models and 5 advanced closed-source models, highlighting the challenges posed by VLRMBench. For instance, in the `Forecasting Future', a binary classification task, the advanced GPT-4o achieves only a 76.0% accuracy. Additionally, we perform comprehensive analytical studies, offering valuable insights for the future development of VLRMs. We anticipate that VLRMBench will serve as a pivotal benchmark in advancing VLRMs. Code and datasets will be available at https://github.com/JCruan519/VLRMBench.
From Motion Signals to Insights: A Unified Framework for Student Behavior Analysis and Feedback in Physical Education Classes
Mar 09, 2025



Analyzing student behavior in educational scenarios is crucial for enhancing teaching quality and student engagement. Existing AI-based models often rely on classroom video footage to identify and analyze student behavior. While these video-based methods can partially capture and analyze student actions, they struggle to accurately track each student's actions in physical education classes, which take place in outdoor, open spaces with diverse activities, and are challenging to generalize to the specialized technical movements involved in these settings. Furthermore, current methods typically lack the ability to integrate specialized pedagogical knowledge, limiting their ability to provide in-depth insights into student behavior and offer feedback for optimizing instructional design. To address these limitations, we propose a unified end-to-end framework that leverages human activity recognition technologies based on motion signals, combined with advanced large language models, to conduct more detailed analyses and feedback of student behavior in physical education classes. Our framework begins with the teacher's instructional designs and the motion signals from students during physical education sessions, ultimately generating automated reports with teaching insights and suggestions for improving both learning and class instructions. This solution provides a motion signal-based approach for analyzing student behavior and optimizing instructional design tailored to physical education classes. Experimental results demonstrate that our framework can accurately identify student behaviors and produce meaningful pedagogical insights.
SmartRAG: Jointly Learn RAG-Related Tasks From the Environment Feedback
Oct 22, 2024



RAG systems consist of multiple modules to work together. However, these modules are usually separately trained. We argue that a system like RAG that incorporates multiple modules should be jointly optimized to achieve optimal performance. To demonstrate this, we design a specific pipeline called \textbf{SmartRAG} that includes a policy network and a retriever. The policy network can serve as 1) a decision maker that decides when to retrieve, 2) a query rewriter to generate a query most suited to the retriever, and 3) an answer generator that produces the final response with/without the observations. We then propose to jointly optimize the whole system using a reinforcement learning algorithm, with the reward designed to encourage the system to achieve the best performance with minimal retrieval cost. When jointly optimized, all the modules can be aware of how other modules are working and thus find the best way to work together as a complete system. Empirical results demonstrate that the jointly optimized SmartRAG can achieve better performance than separately optimized counterparts.