 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamic Relation Discovery and Utilization in Multi-Entity Time Series Forecasting
Feb 18, 2022
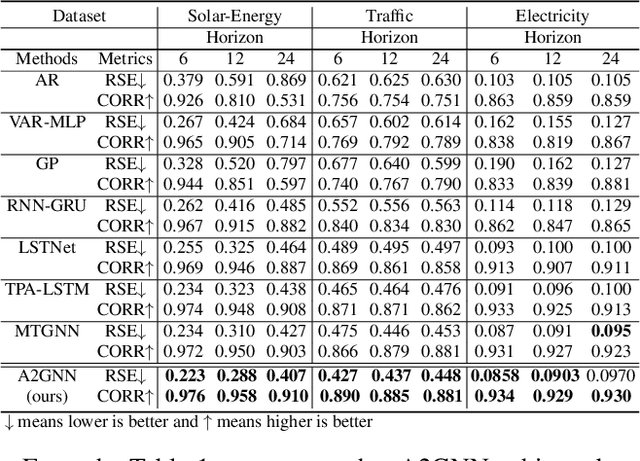
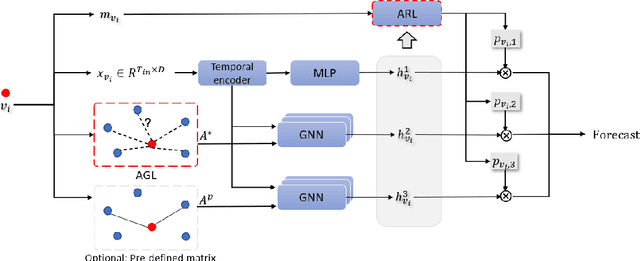
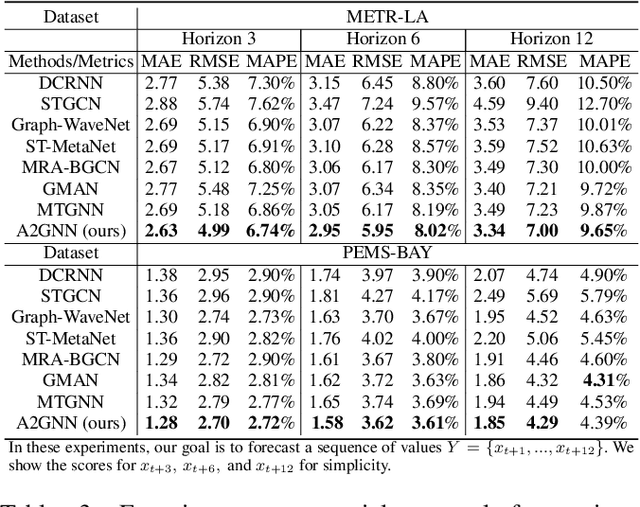
Time series forecasting plays a key role in a variety of domains. In a lot of real-world scenarios, there exist multiple forecasting entities (e.g. power station in the solar system, stations in the traffic system). A straightforward forecasting solution is to mine the temporal dependency for each individual entity through 1d-CNN, RNN, transformer, etc. This approach overlooks the relations between these entities and, in consequence, loses the opportunity to improve performance using spatial-temporal relation. However, in many real-world scenarios, beside explicit relation, there could exist crucial yet implicit relation between entities. How to discover the useful implicit relation between entities and effectively utilize the relations for each entity under various circumstances is crucial. In order to mine the implicit relation between entities as much as possible and dynamically utilize the relation to improve the forecasting performance, we propose an attentional multi-graph neural network with automatic graph learning (A2GNN) in this work. Particularly, a Gumbel-softmax based auto graph learner is designed to automatically capture the implicit relation among forecasting entities. We further propose an attentional relation learner that enables every entity to dynamically pay attention to its preferred relations. Extensive experiments are conducted on five real-world datasets from three different domains. The results demonstrate the effectiveness of A2GNN beyond several state-of-the-art methods.
AF$_2$: Adaptive Focus Framework for Aerial Imagery Segmentation
Feb 18, 2022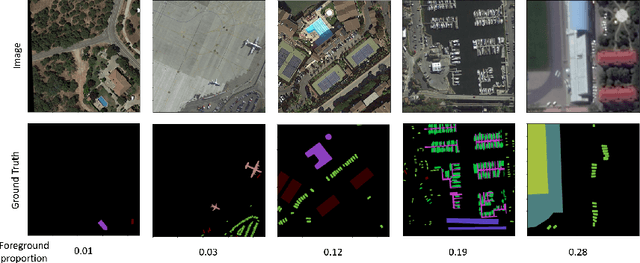
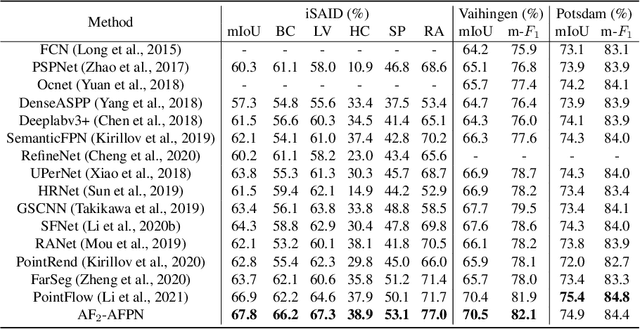
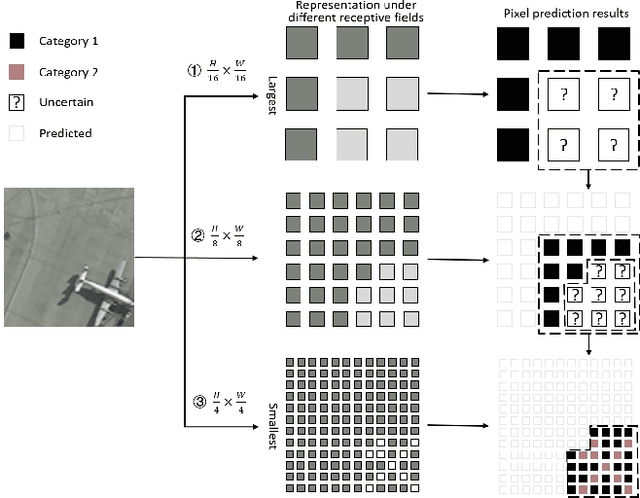
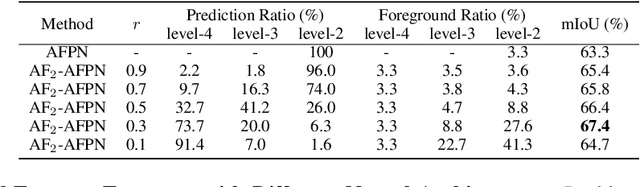
As a specific semantic segmentation task, aerial imagery segmentation has been widely employed in high spatial resolution (HSR) remote sensing images understanding. Besides common issues (e.g. large scale variation) faced by general semantic segmentation tasks, aerial imagery segmentation has some unique challenges, the most critical one among which lies in foreground-background imbalance. There have been some recent efforts that attempt to address this issue by proposing sophisticated neural network architectures, since they can be used to extract informative multi-scale feature representations and increase the discrimination of object boundaries. Nevertheless, many of them merely utilize those multi-scale representations in ad-hoc measures but disregard the fact that the semantic meaning of objects with various sizes could be better identified via receptive fields of diverse ranges. In this paper, we propose Adaptive Focus Framework (AF$_2$), which adopts a hierarchical segmentation procedure and focuses on adaptively utilizing multi-scale representations generated by widely adopted neural network architectures. Particularly, a learnable module, called Adaptive Confidence Mechanism (ACM), is proposed to determine which scale of representation should be used for the segmentation of different objects. Comprehensive experiments show that AF$_2$ has significantly improved the accuracy on three widely used aerial benchmarks, as fast as the mainstream method.
Towards Deployment-Efficient Reinforcement Learning: Lower Bound and Optimality
Feb 14, 2022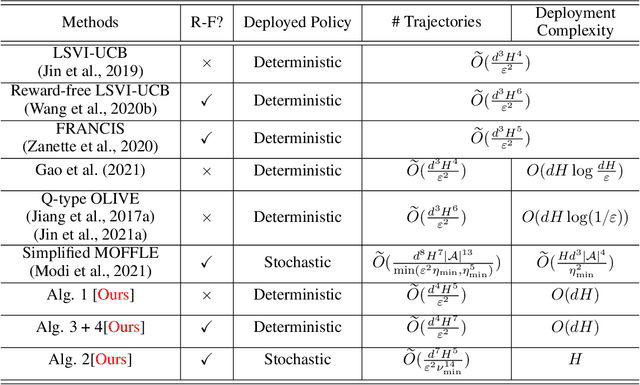
Deployment efficiency is an important criterion for many real-world applications of reinforcement learning (RL). Despite the community's increasing interest, there lacks a formal theoretical formulation for the problem. In this paper, we propose such a formulation for deployment-efficient RL (DE-RL) from an "optimization with constraints" perspective: we are interested in exploring an MDP and obtaining a near-optimal policy within minimal \emph{deployment complexity}, whereas in each deployment the policy can sample a large batch of data. Using finite-horizon linear MDPs as a concrete structural model, we reveal the fundamental limit in achieving deployment efficiency by establishing information-theoretic lower bounds, and provide algorithms that achieve the optimal deployment efficiency. Moreover, our formulation for DE-RL is flexible and can serve as a building block for other practically relevant settings; we give "Safe DE-RL" and "Sample-Efficient DE-RL" as two examples, which may be worth future investigation.
Direct Molecular Conformation Generation
Feb 03, 2022
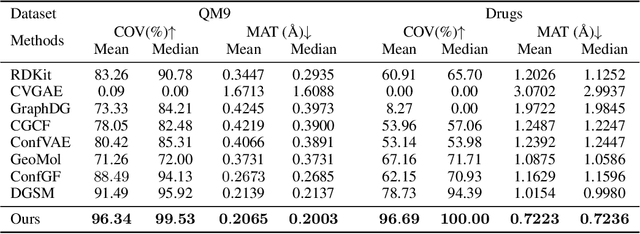
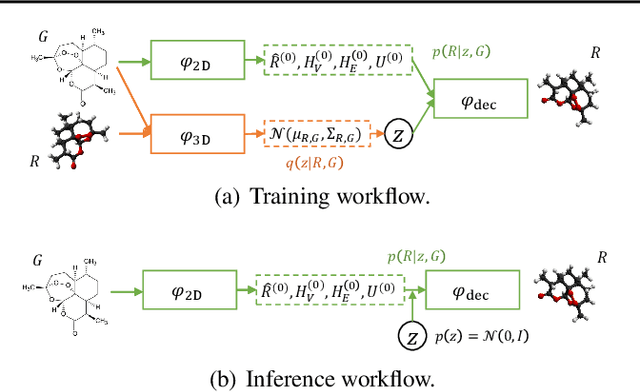
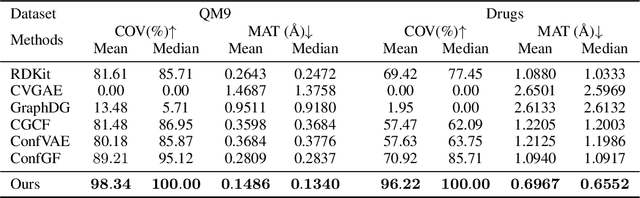
Molecular conformation generation aims to generate three-dimensional coordinates of all the atoms in a molecule and is an important task in bioinformatics and pharmacology. Previous distance-based methods first predict interatomic distances and then generate conformations based on them, which could result in conflicting distances. In this work, we propose a method that directly predicts the coordinates of atoms. We design a dedicated loss function for conformation generation, which is invariant to roto-translation of coordinates of conformations and permutation of symmetric atoms in molecules. We further design a backbone model that stacks multiple blocks, where each block refines the conformation generated by its preceding block. Our method achieves state-of-the-art results on four public benchmarks: on small-scale GEOM-QM9 and GEOM-Drugs which have $200$K training data, we can improve the previous best matching score by $3.5\%$ and $28.9\%$; on large-scale GEOM-QM9 and GEOM-Drugs which have millions of training data, those two improvements are $47.1\%$ and $36.3\%$. This shows the effectiveness of our method and the great potential of the direct approach. Our code is released at \url{https://github.com/DirectMolecularConfGen/DMCG}.
SHGNN: Structure-Aware Heterogeneous Graph Neural Network
Dec 14, 2021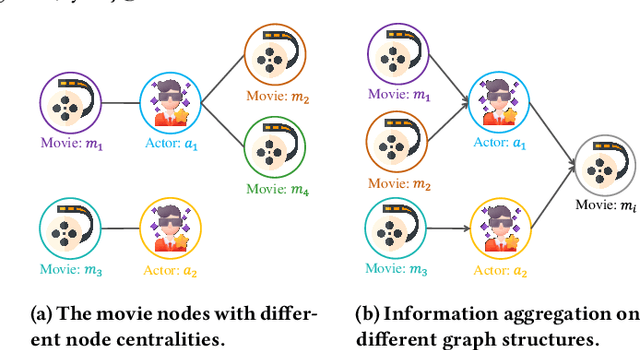
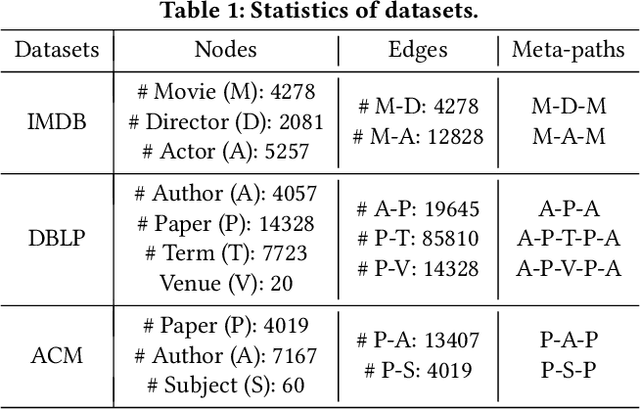
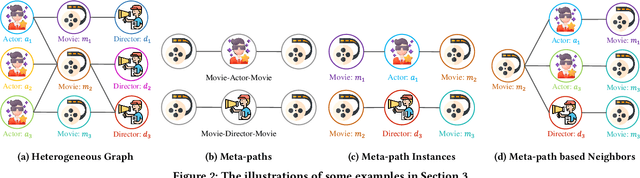
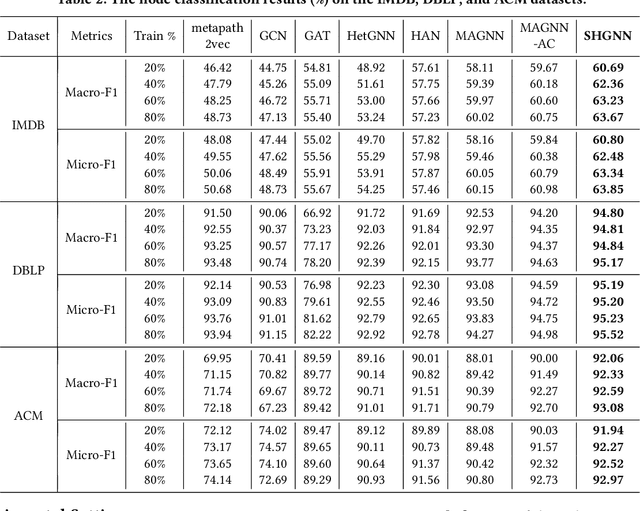
Many real-world graphs (networks) are heterogeneous with different types of nodes and edges. Heterogeneous graph embedding, aiming at learning the low-dimensional node representations of a heterogeneous graph, is vital for various downstream applications. Many meta-path based embedding methods have been proposed to learn the semantic information of heterogeneous graphs in recent years. However, most of the existing techniques overlook the graph structure information when learning the heterogeneous graph embeddings. This paper proposes a novel Structure-Aware Heterogeneous Graph Neural Network (SHGNN) to address the above limitations. In detail, we first utilize a feature propagation module to capture the local structure information of intermediate nodes in the meta-path. Next, we use a tree-attention aggregator to incorporate the graph structure information into the aggregation module on the meta-path. Finally, we leverage a meta-path aggregator to fuse the information aggregated from different meta-paths. We conducted experiments on node classification and clustering tasks and achieved state-of-the-art results on the benchmark datasets, which shows the effectiveness of our proposed method.
KGE-CL: Contrastive Learning of Knowledge Graph Embeddings
Dec 09, 2021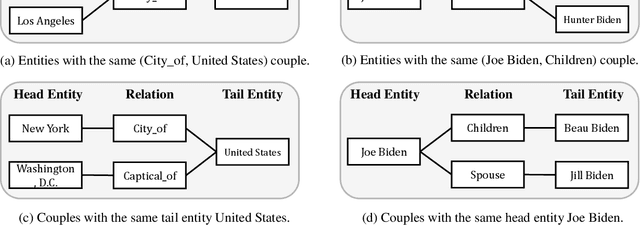

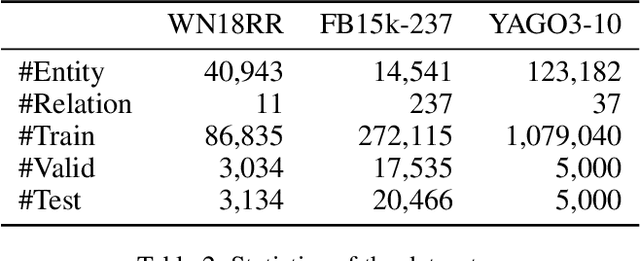
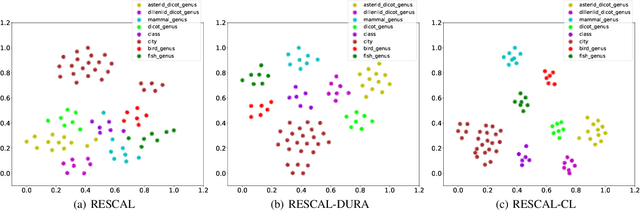
Learning the embeddings of knowledge graphs is vital in artificial intelligence, and can benefit various downstream applications, such as recommendation and question answering. In recent years, many research efforts have been proposed for knowledge graph embedding. However, most previous knowledge graph embedding methods ignore the semantic similarity between the related entities and entity-relation couples in different triples since they separately optimize each triple with the scoring function. To address this problem, we propose a simple yet efficient contrastive learning framework for knowledge graph embeddings, which can shorten the semantic distance of the related entities and entity-relation couples in different triples and thus improve the expressiveness of knowledge graph embeddings. We evaluate our proposed method on three standard knowledge graph benchmarks. It is noteworthy that our method can yield some new state-of-the-art results, achieving 51.2% MRR, 46.8% Hits@1 on the WN18RR dataset, and 59.1% MRR, 51.8% Hits@1 on the YAGO3-10 dataset.
Curriculum Offline Imitation Learning
Nov 03, 2021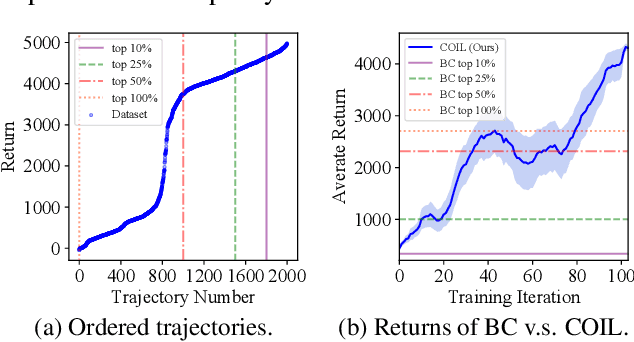
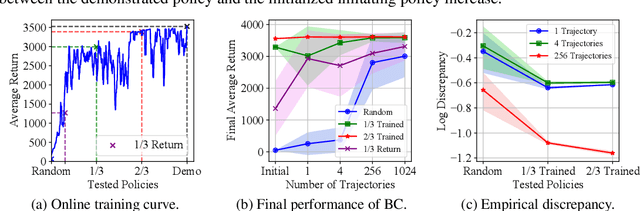
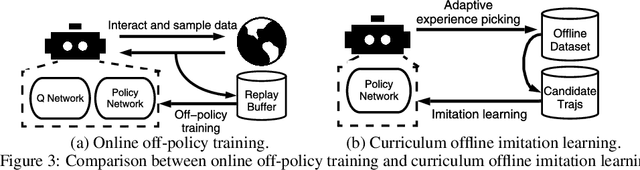

Offline reinforcement learning (RL) tasks require the agent to learn from a pre-collected dataset with no further interactions with the environment. Despite the potential to surpass the behavioral policies, RL-based methods are generally impractical due to the training instability and bootstrapping the extrapolation errors, which always require careful hyperparameter tuning via online evaluation. In contrast, offline imitation learning (IL) has no such issues since it learns the policy directly without estimating the value function by bootstrapping. However, IL is usually limited in the capability of the behavioral policy and tends to learn a mediocre behavior from the dataset collected by the mixture of policies. In this paper, we aim to take advantage of IL but mitigate such a drawback. Observing that behavior cloning is able to imitate neighboring policies with less data, we propose \textit{Curriculum Offline Imitation Learning (COIL)}, which utilizes an experience picking strategy for imitating from adaptive neighboring policies with a higher return, and improves the current policy along curriculum stages. On continuous control benchmarks, we compare COIL against both imitation-based and RL-based methods, showing that it not only avoids just learning a mediocre behavior on mixed datasets but is also even competitive with state-of-the-art offline RL methods.
Optimizing Information-theoretical Generalization Bounds via Anisotropic Noise in SGLD
Nov 03, 2021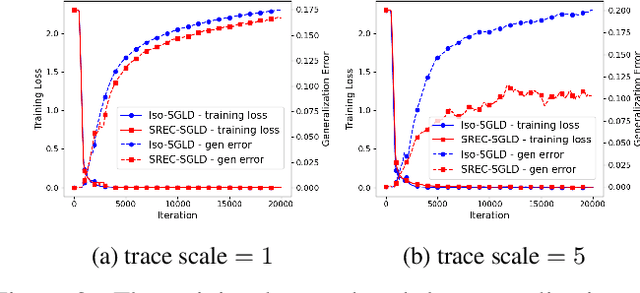
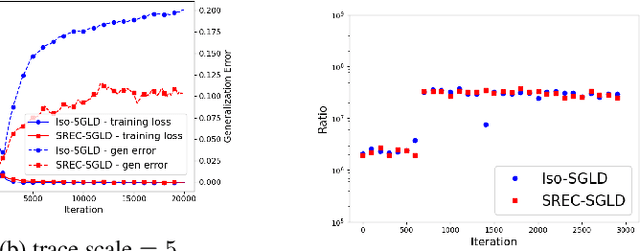
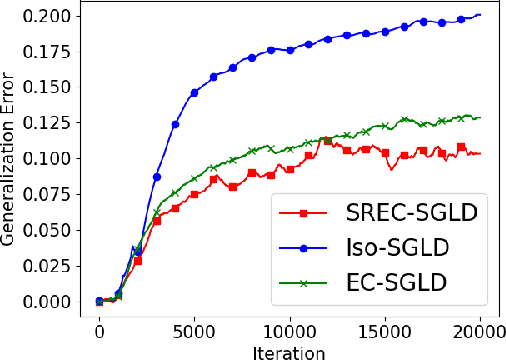
Recently, the information-theoretical framework has been proven to be able to obtain non-vacuous generalization bounds for large models trained by Stochastic Gradient Langevin Dynamics (SGLD) with isotropic noise. In this paper, we optimize the information-theoretical generalization bound by manipulating the noise structure in SGLD. We prove that with constraint to guarantee low empirical risk, the optimal noise covariance is the square root of the expected gradient covariance if both the prior and the posterior are jointly optimized. This validates that the optimal noise is quite close to the empirical gradient covariance. Technically, we develop a new information-theoretical bound that enables such an optimization analysis. We then apply matrix analysis to derive the form of optimal noise covariance. Presented constraint and results are validated by the empirical observations.
Indiscriminate Poisoning Attacks Are Shortcuts
Nov 01, 2021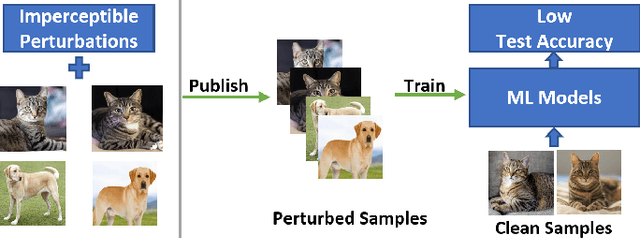
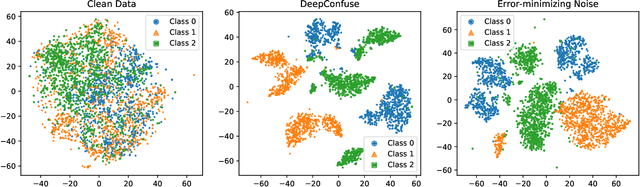
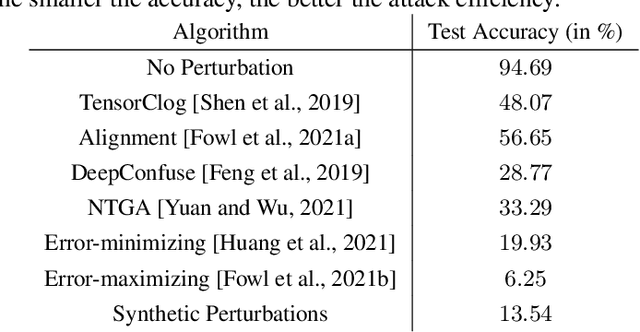

Indiscriminate data poisoning attacks, which add imperceptible perturbations to training data to maximize the test error of trained models, have become a trendy topic because they are thought to be capable of preventing unauthorized use of data. In this work, we investigate why these perturbations work in principle. We find that the perturbations of advanced poisoning attacks are almost \textbf{linear separable} when assigned with the target labels of the corresponding samples, which hence can work as \emph{shortcuts} for the learning objective. This important population property has not been unveiled before. Moreover, we further verify that linear separability is indeed the workhorse for poisoning attacks. We synthesize linear separable data as perturbations and show that such synthetic perturbations are as powerful as the deliberately crafted attacks. Our finding suggests that the \emph{shortcut learning} problem is more serious than previously believed as deep learning heavily relies on shortcuts even if they are of an imperceptible scale and mixed together with the normal features. This finding also suggests that pre-trained feature extractors would disable these poisoning attacks effectively.
Pre-training Co-evolutionary Protein Representation via A Pairwise Masked Language Model
Oct 29, 2021

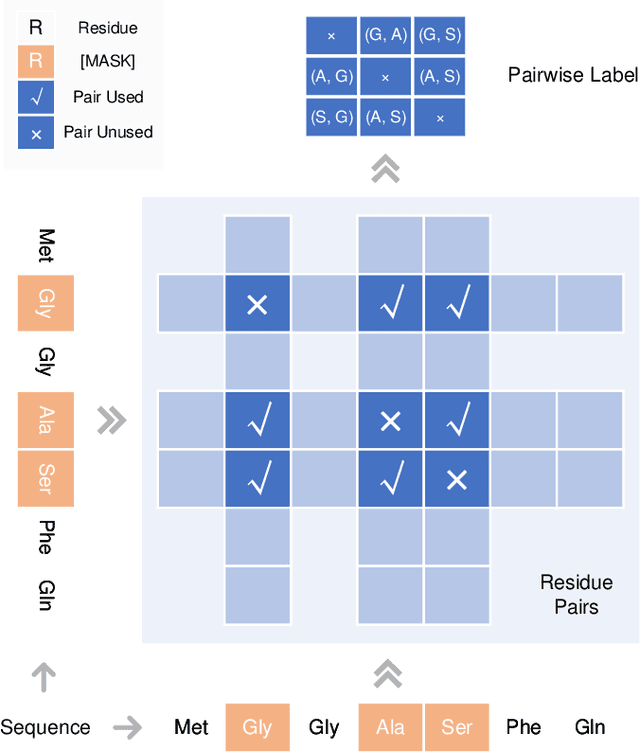

Understanding protein sequences is vital and urgent for biology, healthcare, and medicine. Labeling approaches are expensive yet time-consuming, while the amount of unlabeled data is increasing quite faster than that of the labeled data due to low-cost, high-throughput sequencing methods. In order to extract knowledge from these unlabeled data, representation learning is of significant value for protein-related tasks and has great potential for helping us learn more about protein functions and structures. The key problem in the protein sequence representation learning is to capture the co-evolutionary information reflected by the inter-residue co-variation in the sequences. Instead of leveraging multiple sequence alignment as is usually done, we propose a novel method to capture this information directly by pre-training via a dedicated language model, i.e., Pairwise Masked Language Model (PMLM). In a conventional masked language model, the masked tokens are modeled by conditioning on the unmasked tokens only, but processed independently to each other. However, our proposed PMLM takes the dependency among masked tokens into consideration, i.e., the probability of a token pair is not equal to the product of the probability of the two tokens. By applying this model, the pre-trained encoder is able to generate a better representation for protein sequences. Our result shows that the proposed method can effectively capture the inter-residue correlations and improves the performance of contact prediction by up to 9% compared to the MLM baseline under the same setting. The proposed model also significantly outperforms the MSA baseline by more than 7% on the TAPE contact prediction benchmark when pre-trained on a subset of the sequence database which the MSA is generated from, revealing the potential of the sequence pre-training method to surpass MSA based methods in general.