 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Illumination: Lighting Prediction for Indoor Environments
Jun 18, 2019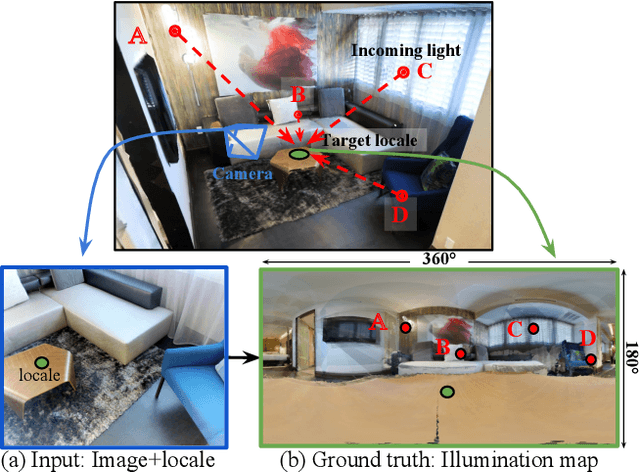
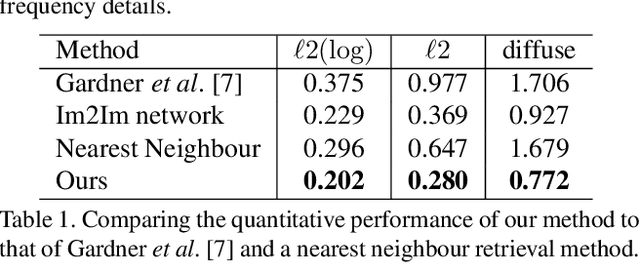
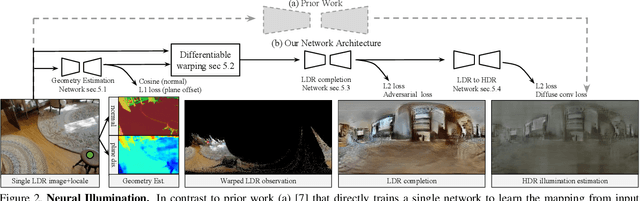

This paper addresses the task of estimating the light arriving from all directions to a 3D point observed at a selected pixel in an RGB image. This task is challenging because it requires predicting a mapping from a partial scene observation by a camera to a complete illumination map for a selected position, which depends on the 3D location of the selection, the distribution of unobserved light sources, the occlusions caused by scene geometry, etc. Previous methods attempt to learn this complex mapping directly using a single black-box neural network, which often fails to estimate high-frequency lighting details for scenes with complicated 3D geometry. Instead, we propose "Neural Illumination" a new approach that decomposes illumination prediction into several simpler differentiable sub-tasks: 1) geometry estimation, 2) scene completion, and 3) LDR-to-HDR estimation. The advantage of this approach is that the sub-tasks are relatively easy to learn and can be trained with direct supervision, while the whole pipeline is fully differentiable and can be fine-tuned with end-to-end supervision. Experiments show that our approach performs significantly better quantitatively and qualitatively than prior work.
Learning Shape Templates with Structured Implicit Functions
Apr 12, 2019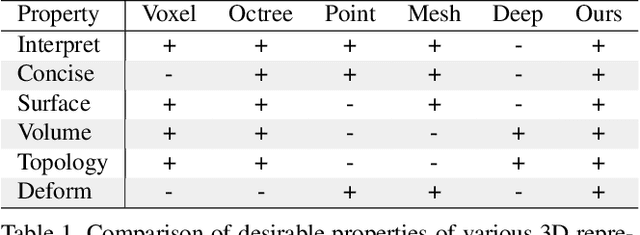


Template 3D shapes are useful for many tasks in graphics and vision, including fitting observation data, analyzing shape collections, and transferring shape attributes. Because of the variety of geometry and topology of real-world shapes, previous methods generally use a library of hand-made templates. In this paper, we investigate learning a general shape template from data. To allow for widely varying geometry and topology, we choose an implicit surface representation based on composition of local shape elements. While long known to computer graphics, this representation has not yet been explored in the context of machine learning for vision. We show that structured implicit functions are suitable for learning and allow a network to smoothly and simultaneously fit multiple classes of shapes. The learned shape template supports applications such as shape exploration, correspondence, abstraction, interpolation, and semantic segmentation from an RGB image.
FrameNet: Learning Local Canonical Frames of 3D Surfaces from a Single RGB Image
Mar 29, 2019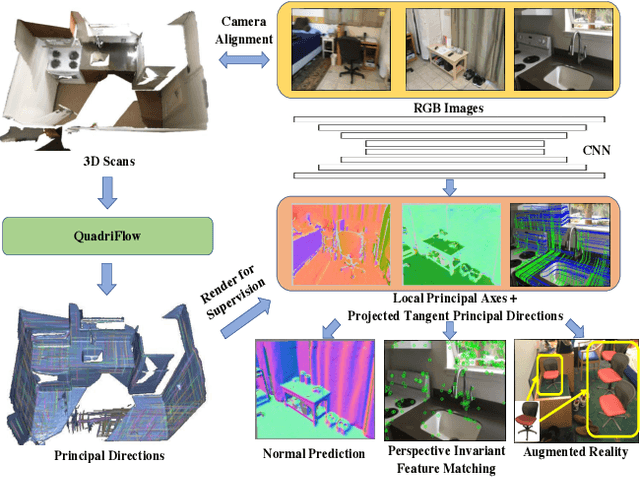
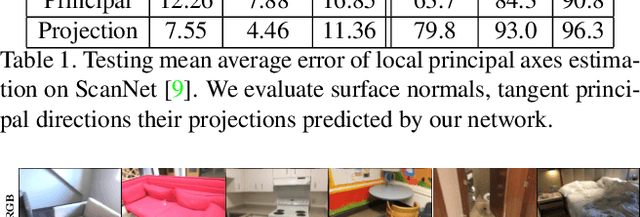

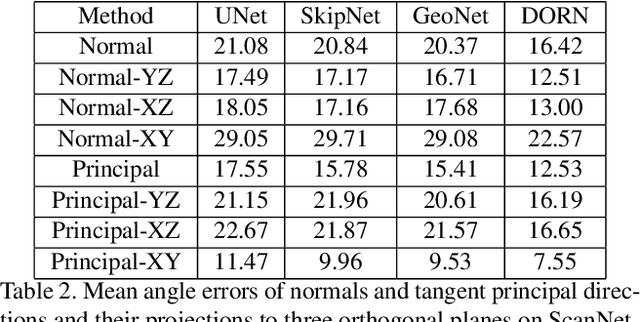
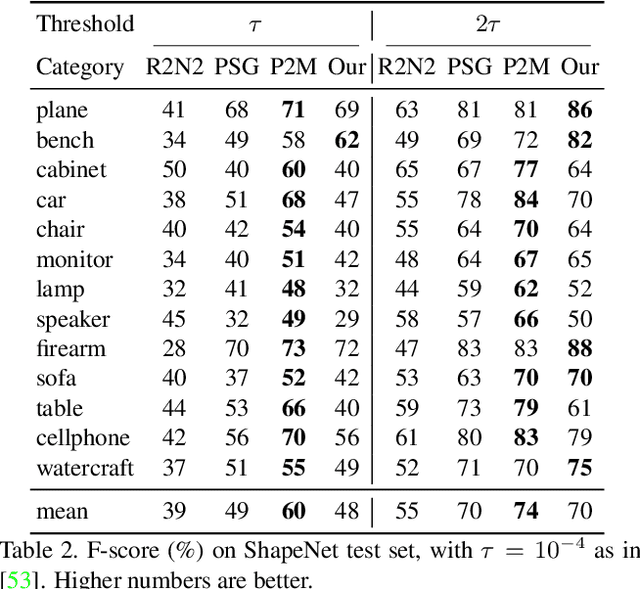
In this work, we introduce the novel problem of identifying dense canonical 3D coordinate frames from a single RGB image. We observe that each pixel in an image corresponds to a surface in the underlying 3D geometry, where a canonical frame can be identified as represented by three orthogonal axes, one along its normal direction and two in its tangent plane. We propose an algorithm to predict these axes from RGB. Our first insight is that canonical frames computed automatically with recently introduced direction field synthesis methods can provide training data for the task. Our second insight is that networks designed for surface normal prediction provide better results when trained jointly to predict canonical frames, and even better when trained to also predict 2D projections of canonical frames. We conjecture this is because projections of canonical tangent directions often align with local gradients in images, and because those directions are tightly linked to 3D canonical frames through projective geometry and orthogonality constraints. In our experiments, we find that our method predicts 3D canonical frames that can be used in applications ranging from surface normal estimation, feature matching, and augmented reality.
TossingBot: Learning to Throw Arbitrary Objects with Residual Physics
Mar 27, 2019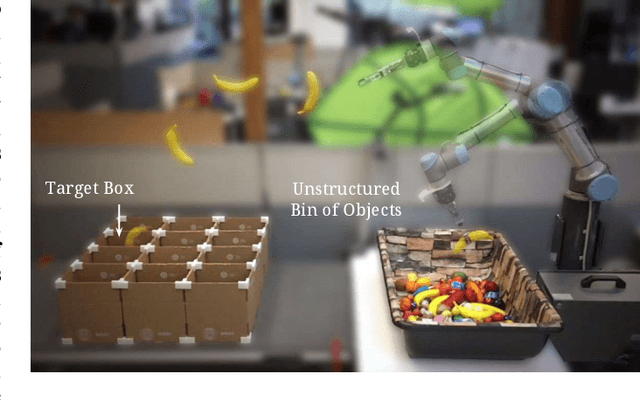
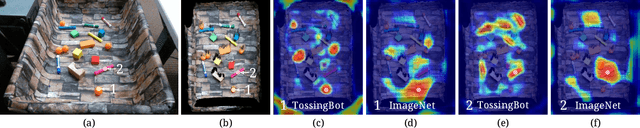
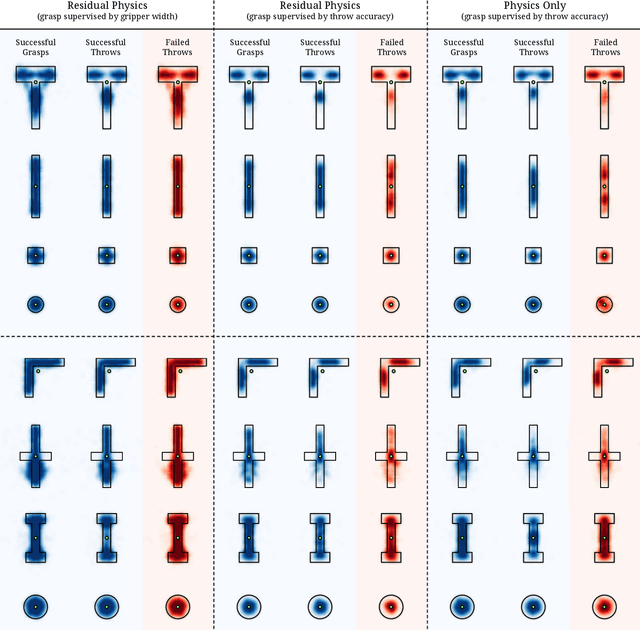
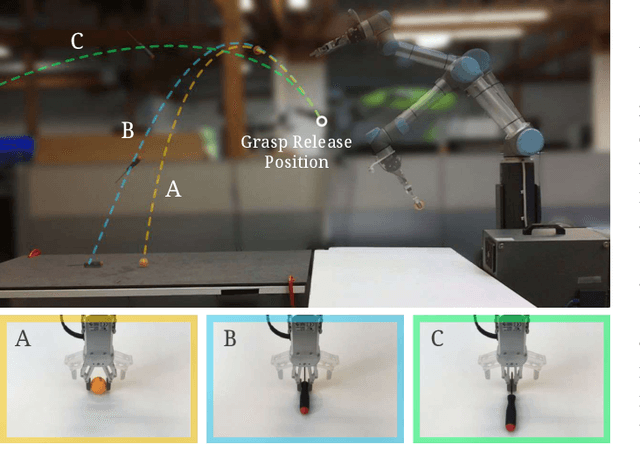
We investigate whether a robot arm can learn to pick and throw arbitrary objects into selected boxes quickly and accurately. Throwing has the potential to increase the physical reachability and picking speed of a robot arm. However, precisely throwing arbitrary objects in unstructured settings presents many challenges: from acquiring reliable pre-throw conditions (e.g. initial pose of object in manipulator) to handling varying object-centric properties (e.g. mass distribution, friction, shape) and dynamics (e.g. aerodynamics). In this work, we propose an end-to-end formulation that jointly learns to infer control parameters for grasping and throwing motion primitives from visual observations (images of arbitrary objects in a bin) through trial and error. Within this formulation, we investigate the synergies between grasping and throwing (i.e., learning grasps that enable more accurate throws) and between simulation and deep learning (i.e., using deep networks to predict residuals on top of control parameters predicted by a physics simulator). The resulting system, TossingBot, is able to grasp and throw arbitrary objects into boxes located outside its maximum reach range at 500+ mean picks per hour (600+ grasps per hour with 85% throwing accuracy); and generalizes to new objects and target locations. Videos are available at https://tossingbot.cs.princeton.edu
TextureNet: Consistent Local Parametrizations for Learning from High-Resolution Signals on Meshes
Nov 30, 2018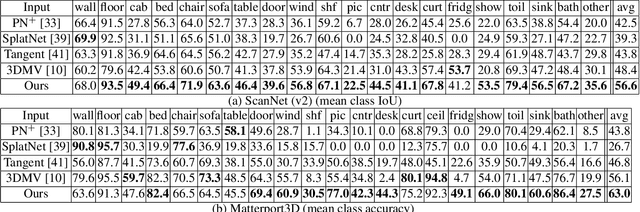
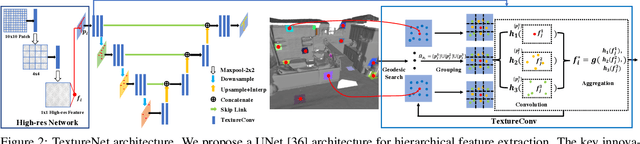
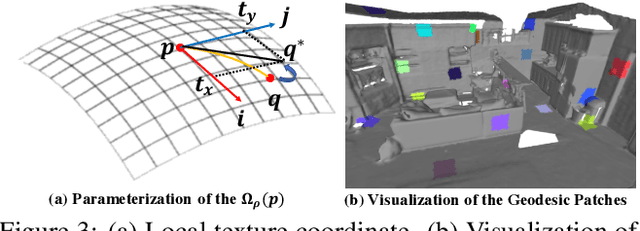
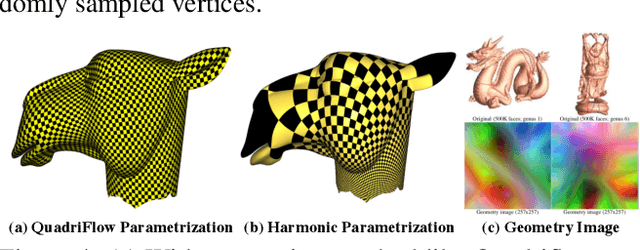
We introduce, TextureNet, a neural network architecture designed to extract features from high-resolution signals associated with 3D surface meshes (e.g., color texture maps). The key idea is to utilize a 4-rotational symmetric (4-RoSy) field to define a domain for convolution on a surface. Though 4-RoSy fields have several properties favorable for convolution on surfaces (low distortion, few singularities, consistent parameterization, etc.), orientations are ambiguous up to 4-fold rotation at any sample point. So, we introduce a new convolutional operator invariant to the 4-RoSy ambiguity and use it in a network to extract features from high-resolution signals on geodesic neighborhoods of a surface. In comparison to alternatives, such as PointNet based methods which lack a notion of orientation, the coherent structure given by these neighborhoods results in significantly stronger features. As an example application, we demonstrate the benefits of our architecture for 3D semantic segmentation of textured 3D meshes. The results show that our method outperforms all existing methods on the basis of mean IoU by a significant margin in both geometry-only (6.4%) and RGB+Geometry (6.9-8.2%) settings.
Learning Synergies between Pushing and Grasping with Self-supervised Deep Reinforcement Learning
Sep 30, 2018
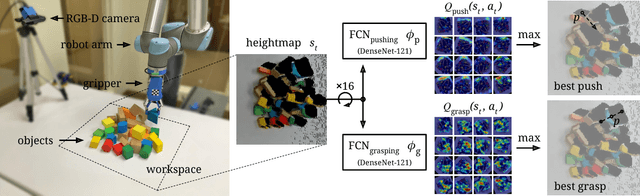
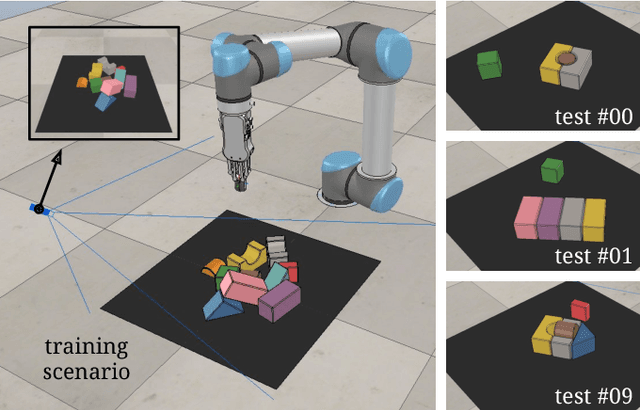
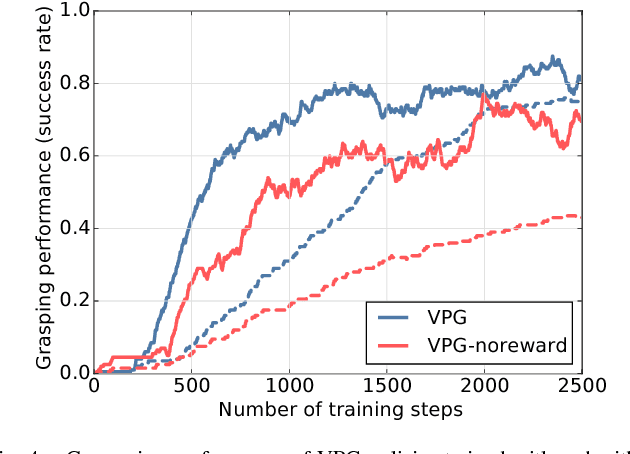
Skilled robotic manipulation benefits from complex synergies between non-prehensile (e.g. pushing) and prehensile (e.g. grasping) actions: pushing can help rearrange cluttered objects to make space for arms and fingers; likewise, grasping can help displace objects to make pushing movements more precise and collision-free. In this work, we demonstrate that it is possible to discover and learn these synergies from scratch through model-free deep reinforcement learning. Our method involves training two fully convolutional networks that map from visual observations to actions: one infers the utility of pushes for a dense pixel-wise sampling of end effector orientations and locations, while the other does the same for grasping. Both networks are trained jointly in a Q-learning framework and are entirely self-supervised by trial and error, where rewards are provided from successful grasps. In this way, our policy learns pushing motions that enable future grasps, while learning grasps that can leverage past pushes. During picking experiments in both simulation and real-world scenarios, we find that our system quickly learns complex behaviors amid challenging cases of clutter, and achieves better grasping success rates and picking efficiencies than baseline alternatives after only a few hours of training. We further demonstrate that our method is capable of generalizing to novel objects. Qualitative results (videos), code, pre-trained models, and simulation environments are available at http://vpg.cs.princeton.edu
Structure-Aware Shape Synthesis
Aug 04, 2018

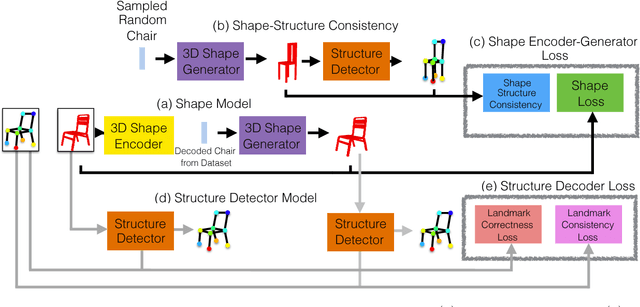
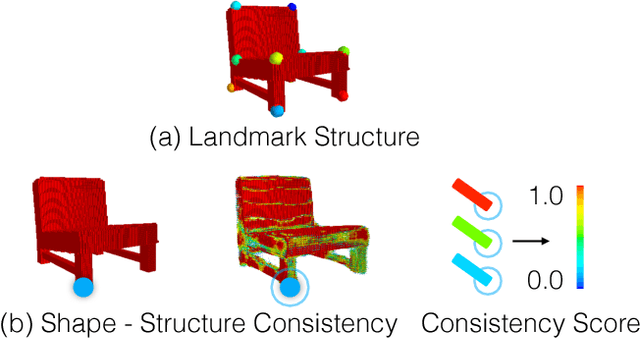
We propose a new procedure to guide training of a data-driven shape generative model using a structure-aware loss function. Complex 3D shapes often can be summarized using a coarsely defined structure which is consistent and robust across variety of observations. However, existing synthesis techniques do not account for structure during training, and thus often generate implausible and structurally unrealistic shapes. During training, we enforce structural constraints in order to enforce consistency and structure across the entire manifold. We propose a novel methodology for training 3D generative models that incorporates structural information into an end-to-end training pipeline.
PlaneMatch: Patch Coplanarity Prediction for Robust RGB-D Reconstruction
Jul 27, 2018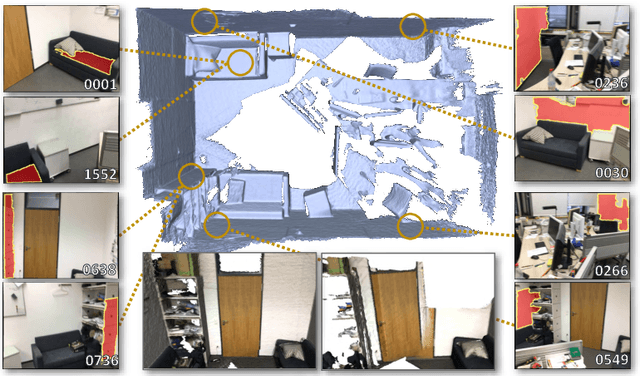
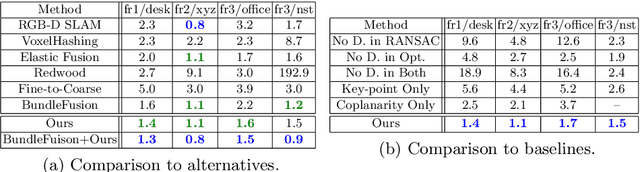

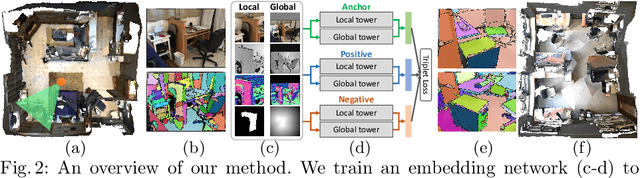
We introduce a novel RGB-D patch descriptor designed for detecting coplanar surfaces in SLAM reconstruction. The core of our method is a deep convolutional neural net that takes in RGB, depth, and normal information of a planar patch in an image and outputs a descriptor that can be used to find coplanar patches from other images.We train the network on 10 million triplets of coplanar and non-coplanar patches, and evaluate on a new coplanarity benchmark created from commodity RGB-D scans. Experiments show that our learned descriptor outperforms alternatives extended for this new task by a significant margin. In addition, we demonstrate the benefits of coplanarity matching in a robust RGBD reconstruction formulation.We find that coplanarity constraints detected with our method are sufficient to get reconstruction results comparable to state-of-the-art frameworks on most scenes, but outperform other methods on standard benchmarks when combined with a simple keypoint method.
* ECCV 2018 oral paper; Supplemental material included
ActiveStereoNet: End-to-End Self-Supervised Learning for Active Stereo Systems
Jul 16, 2018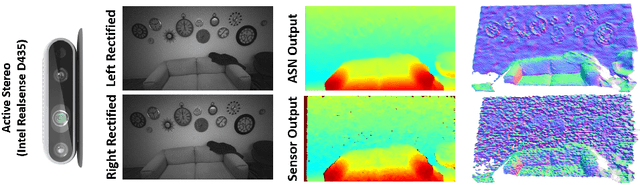
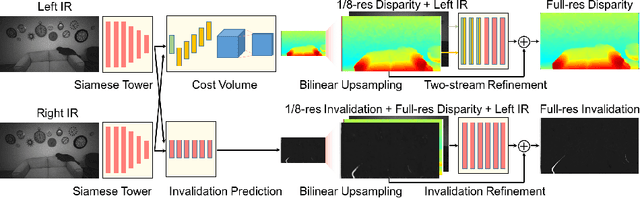

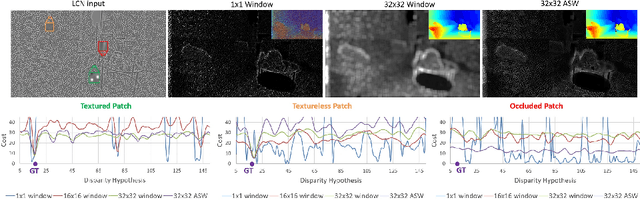
In this paper we present ActiveStereoNet, the first deep learning solution for active stereo systems. Due to the lack of ground truth, our method is fully self-supervised, yet it produces precise depth with a subpixel precision of $1/30th$ of a pixel; it does not suffer from the common over-smoothing issues; it preserves the edges; and it explicitly handles occlusions. We introduce a novel reconstruction loss that is more robust to noise and texture-less patches, and is invariant to illumination changes. The proposed loss is optimized using a window-based cost aggregation with an adaptive support weight scheme. This cost aggregation is edge-preserving and smooths the loss function, which is key to allow the network to reach compelling results. Finally we show how the task of predicting invalid regions, such as occlusions, can be trained end-to-end without ground-truth. This component is crucial to reduce blur and particularly improves predictions along depth discontinuities. Extensive quantitatively and qualitatively evaluations on real and synthetic data demonstrate state of the art results in many challenging scenes.
Deep Depth Completion of a Single RGB-D Image
May 02, 2018

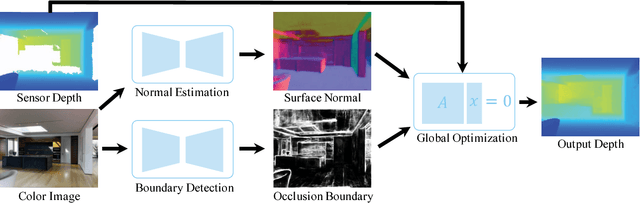
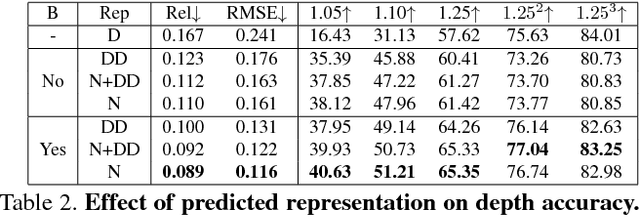
The goal of our work is to complete the depth channel of an RGB-D image. Commodity-grade depth cameras often fail to sense depth for shiny, bright, transparent, and distant surfaces. To address this problem, we train a deep network that takes an RGB image as input and predicts dense surface normals and occlusion boundaries. Those predictions are then combined with raw depth observations provided by the RGB-D camera to solve for depths for all pixels, including those missing in the original observation. This method was chosen over others (e.g., inpainting depths directly) as the result of extensive experiments with a new depth completion benchmark dataset, where holes are filled in training data through the rendering of surface reconstructions created from multiview RGB-D scans. Experiments with different network inputs, depth representations, loss functions, optimization methods, inpainting methods, and deep depth estimation networks show that our proposed approach provides better depth completions than these alternatives.