 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgesimPLE: a visuotactile method learned in simulation to precisely pick, localize, regrasp, and place objects
Jul 24, 2023



Existing robotic systems have a clear tension between generality and precision. Deployed solutions for robotic manipulation tend to fall into the paradigm of one robot solving a single task, lacking precise generalization, i.e., the ability to solve many tasks without compromising on precision. This paper explores solutions for precise and general pick-and-place. In precise pick-and-place, i.e. kitting, the robot transforms an unstructured arrangement of objects into an organized arrangement, which can facilitate further manipulation. We propose simPLE (simulation to Pick Localize and PLacE) as a solution to precise pick-and-place. simPLE learns to pick, regrasp and place objects precisely, given only the object CAD model and no prior experience. We develop three main components: task-aware grasping, visuotactile perception, and regrasp planning. Task-aware grasping computes affordances of grasps that are stable, observable, and favorable to placing. The visuotactile perception model relies on matching real observations against a set of simulated ones through supervised learning. Finally, we compute the desired robot motion by solving a shortest path problem on a graph of hand-to-hand regrasps. On a dual-arm robot equipped with visuotactile sensing, we demonstrate pick-and-place of 15 diverse objects with simPLE. The objects span a wide range of shapes and simPLE achieves successful placements into structured arrangements with 1mm clearance over 90% of the time for 6 objects, and over 80% of the time for 11 objects. Videos are available at http://mcube.mit.edu/research/simPLE.html .
Providing Assurance and Scrutability on Shared Data and Machine Learning Models with Verifiable Credentials
May 13, 2021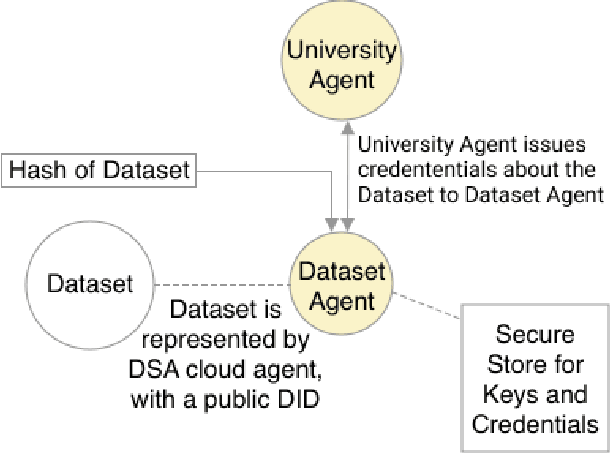
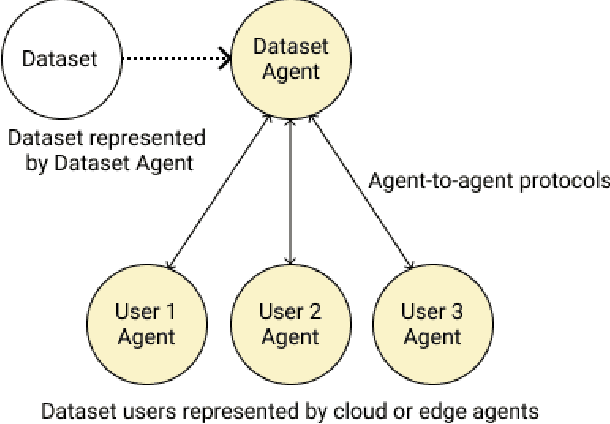
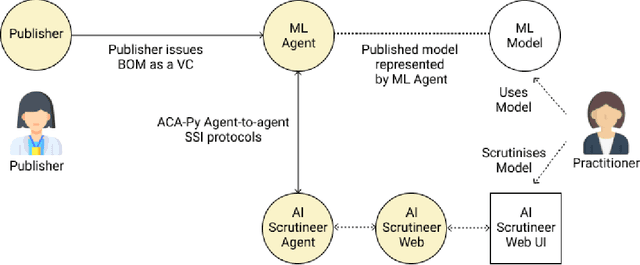
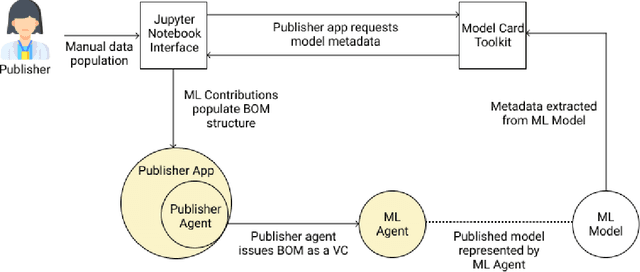
Adopting shared data resources requires scientists to place trust in the originators of the data. When shared data is later used in the development of artificial intelligence (AI) systems or machine learning (ML) models, the trust lineage extends to the users of the system, typically practitioners in fields such as healthcare and finance. Practitioners rely on AI developers to have used relevant, trustworthy data, but may have limited insight and recourse. This paper introduces a software architecture and implementation of a system based on design patterns from the field of self-sovereign identity. Scientists can issue signed credentials attesting to qualities of their data resources. Data contributions to ML models are recorded in a bill of materials (BOM), which is stored with the model as a verifiable credential. The BOM provides a traceable record of the supply chain for an AI system, which facilitates on-going scrutiny of the qualities of the contributing components. The verified BOM, and its linkage to certified data qualities, is used in the AI Scrutineer, a web-based tool designed to offer practitioners insight into ML model constituents and highlight any problems with adopted datasets, should they be found to have biased data or be otherwise discredited.
GelSlim3.0: High-Resolution Measurement of Shape, Force and Slip in a Compact Tactile-Sensing Finger
Mar 23, 2021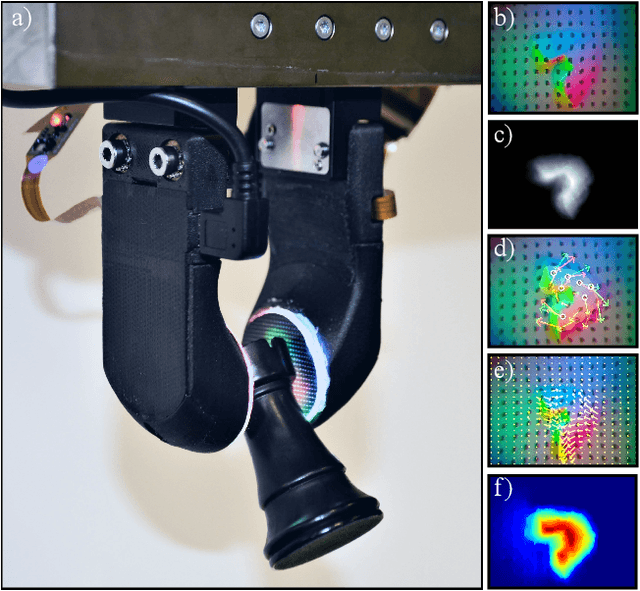
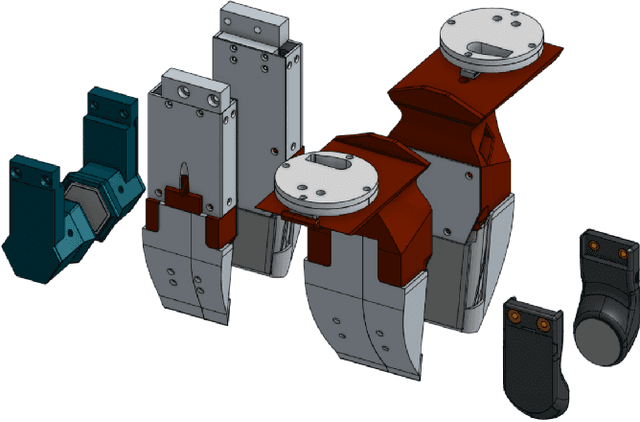
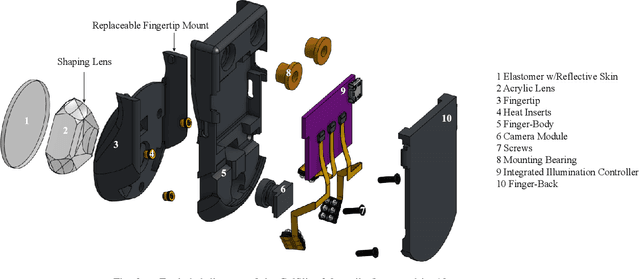
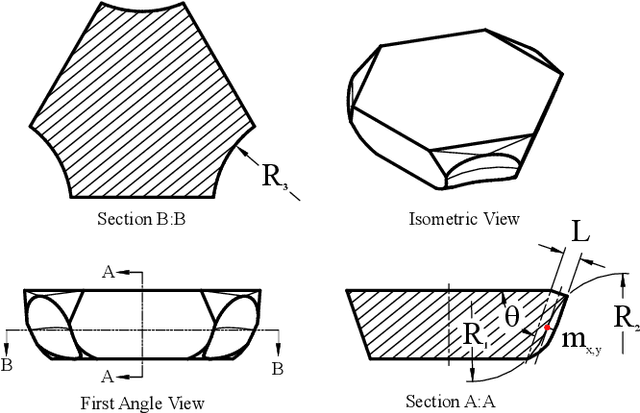
This work presents a new version of the tactile-sensing finger GelSlim 3.0, which integrates the ability to sense high-resolution shape, force, and slip in a compact form factor for use with small parallel jaw grippers in cluttered bin-picking scenarios. The novel design incorporates the capability to use real-time analytic methods to measure shape, estimate the contact 3D force distribution, and detect incipient slip. To achieve a compact integration, we optimize the optical path from illumination source to camera and other geometric variables in a optical simulation environment. In particular, we optimize the illumination sources and a light shaping lens around the constraints imposed by the photometric stereo algorithm used for depth reconstruction. The optimized optical configuration is integrated into a finger design composed of robust and easily replaceable snap-to-fit fingetip module that allow for ease of manufacture, assembly, use, and repair. To stimulate future research in tactile-sensing and provide the robotics community access to reliable and easily-reproducible tactile finger with a diversity of sensing modalities, we open-source the design and software at https://github.com/mcubelab/gelslim.
A framework for fostering transparency in shared artificial intelligence models by increasing visibility of contributions
Mar 05, 2021
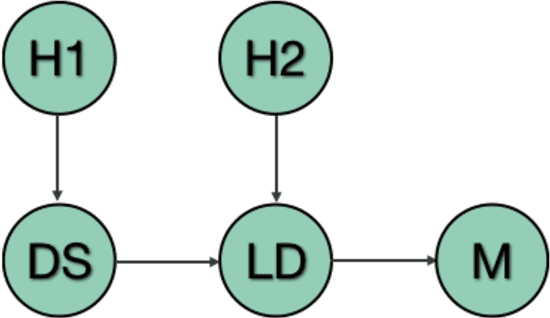

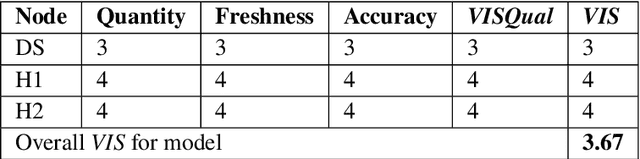
Increased adoption of artificial intelligence (AI) systems into scientific workflows will result in an increasing technical debt as the distance between the data scientists and engineers who develop AI system components and scientists, researchers and other users grows. This could quickly become problematic, particularly where guidance or regulations change and once-acceptable best practice becomes outdated, or where data sources are later discredited as biased or inaccurate. This paper presents a novel method for deriving a quantifiable metric capable of ranking the overall transparency of the process pipelines used to generate AI systems, such that users, auditors and other stakeholders can gain confidence that they will be able to validate and trust the data sources and contributors in the AI systems that they rely on. The methodology for calculating the metric, and the type of criteria that could be used to make judgements on the visibility of contributions to systems are evaluated through models published at ModelHub and PyTorch Hub, popular archives for sharing science resources, and is found to be helpful in driving consideration of the contributions made to generating AI systems and approaches towards effective documentation and improving transparency in machine learning assets shared within scientific communities.
Quantifying Transparency of Machine Learning Systems through Analysis of Contributions
Jul 08, 2019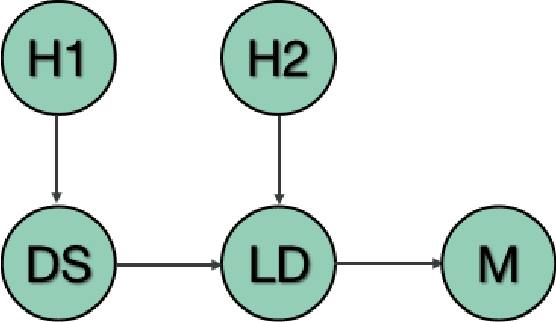

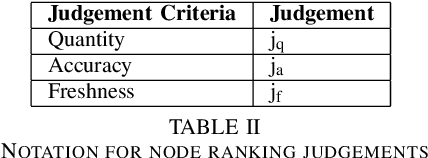
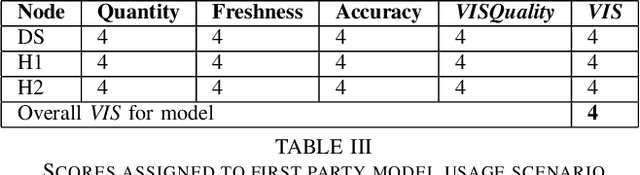
Increased adoption and deployment of machine learning (ML) models into business, healthcare and other organisational processes, will result in a growing disconnect between the engineers and researchers who developed the models and the model's users and other stakeholders, such as regulators or auditors. This disconnect is inevitable, as models begin to be used over a number of years or are shared among third parties through user communities or via commercial marketplaces, and it will become increasingly difficult for users to maintain ongoing insight into the suitability of the parties who created the model, or the data that was used to train it. This could become problematic, particularly where regulations change and once-acceptable standards become outdated, or where data sources are discredited, perhaps judged to be biased or corrupted, either deliberately or unwittingly. In this paper we present a method for arriving at a quantifiable metric capable of ranking the transparency of the process pipelines used to generate ML models and other data assets, such that users, auditors and other stakeholders can gain confidence that they will be able to validate and trust the data sources and human contributors in the systems that they rely on for their business operations. The methodology for calculating the transparency metric, and the type of criteria that could be used to make judgements on the visibility of contributions to systems are explained and illustrated through an example scenario.
Defining the Collective Intelligence Supply Chain
Sep 25, 2018Organisations are increasingly open to scrutiny, and need to be able to prove that they operate in a fair and ethical way. Accountability should extend to the production and use of the data and knowledge assets used in AI systems, as it would for any raw material or process used in production of physical goods. This paper considers collective intelligence, comprising data and knowledge generated by crowd-sourced workforces, which can be used as core components of AI systems. A proposal is made for the development of a supply chain model for tracking the creation and use of crowdsourced collective intelligence assets, with a blockchain based decentralised architecture identified as an appropriate means of providing validation, accountability and fairness.
Robotic Pick-and-Place of Novel Objects in Clutter with Multi-Affordance Grasping and Cross-Domain Image Matching
Apr 01, 2018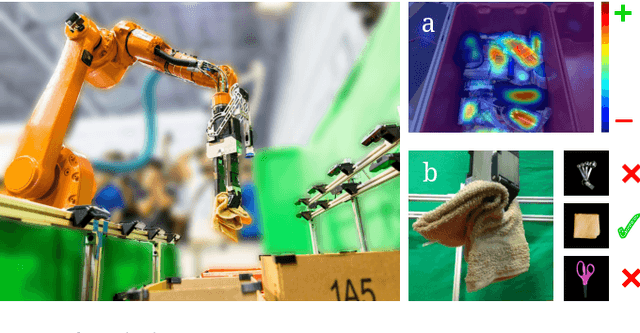


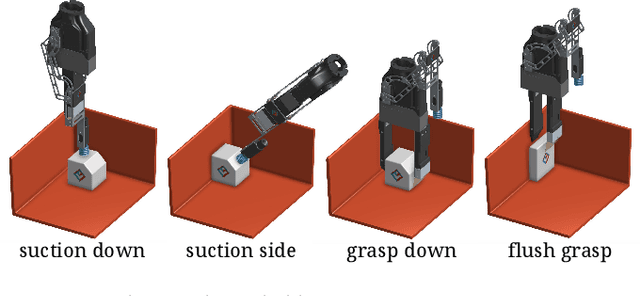
This paper presents a robotic pick-and-place system that is capable of grasping and recognizing both known and novel objects in cluttered environments. The key new feature of the system is that it handles a wide range of object categories without needing any task-specific training data for novel objects. To achieve this, it first uses a category-agnostic affordance prediction algorithm to select and execute among four different grasping primitive behaviors. It then recognizes picked objects with a cross-domain image classification framework that matches observed images to product images. Since product images are readily available for a wide range of objects (e.g., from the web), the system works out-of-the-box for novel objects without requiring any additional training data. Exhaustive experimental results demonstrate that our multi-affordance grasping achieves high success rates for a wide variety of objects in clutter, and our recognition algorithm achieves high accuracy for both known and novel grasped objects. The approach was part of the MIT-Princeton Team system that took 1st place in the stowing task at the 2017 Amazon Robotics Challenge. All code, datasets, and pre-trained models are available online at http://arc.cs.princeton.edu