 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLADB: Latent Aligned Diffusion Bridges for Semi-Supervised Domain Translation
Sep 10, 2025Diffusion models excel at generating high-quality outputs but face challenges in data-scarce domains, where exhaustive retraining or costly paired data are often required. To address these limitations, we propose Latent Aligned Diffusion Bridges (LADB), a semi-supervised framework for sample-to-sample translation that effectively bridges domain gaps using partially paired data. By aligning source and target distributions within a shared latent space, LADB seamlessly integrates pretrained source-domain diffusion models with a target-domain Latent Aligned Diffusion Model (LADM), trained on partially paired latent representations. This approach enables deterministic domain mapping without the need for full supervision. Compared to unpaired methods, which often lack controllability, and fully paired approaches that require large, domain-specific datasets, LADB strikes a balance between fidelity and diversity by leveraging a mixture of paired and unpaired latent-target couplings. Our experimental results demonstrate superior performance in depth-to-image translation under partial supervision. Furthermore, we extend LADB to handle multi-source translation (from depth maps and segmentation masks) and multi-target translation in a class-conditioned style transfer task, showcasing its versatility in handling diverse and heterogeneous use cases. Ultimately, we present LADB as a scalable and versatile solution for real-world domain translation, particularly in scenarios where data annotation is costly or incomplete.
Contrast-Free Ultrasound Microvascular Imaging via Radiality and Similarity Weighting
Sep 08, 2025



Microvascular imaging has advanced significantly with ultrafast data acquisition and improved clutter filtering, enhancing the sensitivity of power Doppler imaging to small vessels. However, the image quality remains limited by spatial resolution and elevated background noise, both of which impede visualization and accurate quantification. To address these limitations, this study proposes a high-resolution cross-correlation Power Doppler (HR-XPD) method that integrates spatial radiality weighting with Doppler signal coherence analysis, thereby enhancing spatial resolution while suppressing artifacts and background noise. Quantitative evaluations in simulation and in vivo experiments on healthy human liver, transplanted human kidney, and pig kidney demonstrated that HR-XPD significantly improves microvascular resolvability and contrast compared to conventional PD. In vivo results showed up to a 2 to 3-fold enhancement in spatial resolution and an increase in contrast by up to 20 dB. High-resolution vascular details were clearly depicted within a short acquisition time of only 0.3 s-1.2 s without the use of contrast agents. These findings indicate that HR-XPD provides an effective, contrast-free, and high-resolution microvascular imaging approach with broad applicability in both preclinical and clinical research.
OneRec-V2 Technical Report
Aug 28, 2025



Recent breakthroughs in generative AI have transformed recommender systems through end-to-end generation. OneRec reformulates recommendation as an autoregressive generation task, achieving high Model FLOPs Utilization. While OneRec-V1 has shown significant empirical success in real-world deployment, two critical challenges hinder its scalability and performance: (1) inefficient computational allocation where 97.66% of resources are consumed by sequence encoding rather than generation, and (2) limitations in reinforcement learning relying solely on reward models. To address these challenges, we propose OneRec-V2, featuring: (1) Lazy Decoder-Only Architecture: Eliminates encoder bottlenecks, reducing total computation by 94% and training resources by 90%, enabling successful scaling to 8B parameters. (2) Preference Alignment with Real-World User Interactions: Incorporates Duration-Aware Reward Shaping and Adaptive Ratio Clipping to better align with user preferences using real-world feedback. Extensive A/B tests on Kuaishou demonstrate OneRec-V2's effectiveness, improving App Stay Time by 0.467%/0.741% while balancing multi-objective recommendations. This work advances generative recommendation scalability and alignment with real-world feedback, representing a step forward in the development of end-to-end recommender systems.
OneRec Technical Report
Jun 16, 2025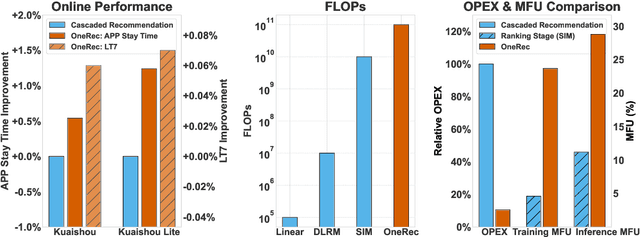

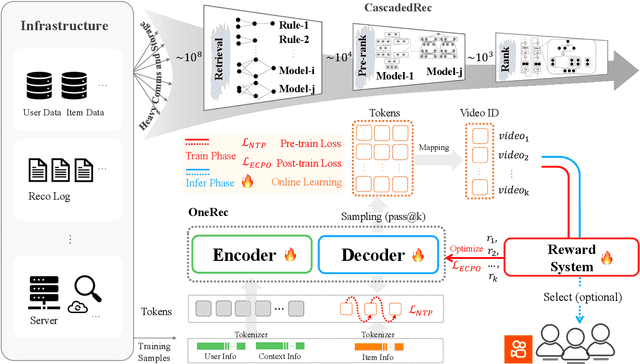
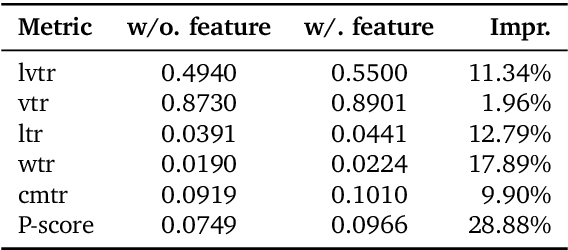
Recommender systems have been widely used in various large-scale user-oriented platforms for many years. However, compared to the rapid developments in the AI community, recommendation systems have not achieved a breakthrough in recent years. For instance, they still rely on a multi-stage cascaded architecture rather than an end-to-end approach, leading to computational fragmentation and optimization inconsistencies, and hindering the effective application of key breakthrough technologies from the AI community in recommendation scenarios. To address these issues, we propose OneRec, which reshapes the recommendation system through an end-to-end generative approach and achieves promising results. Firstly, we have enhanced the computational FLOPs of the current recommendation model by 10 $\times$ and have identified the scaling laws for recommendations within certain boundaries. Secondly, reinforcement learning techniques, previously difficult to apply for optimizing recommendations, show significant potential in this framework. Lastly, through infrastructure optimizations, we have achieved 23.7% and 28.8% Model FLOPs Utilization (MFU) on flagship GPUs during training and inference, respectively, aligning closely with the LLM community. This architecture significantly reduces communication and storage overhead, resulting in operating expense that is only 10.6% of traditional recommendation pipelines. Deployed in Kuaishou/Kuaishou Lite APP, it handles 25% of total queries per second, enhancing overall App Stay Time by 0.54% and 1.24%, respectively. Additionally, we have observed significant increases in metrics such as 7-day Lifetime, which is a crucial indicator of recommendation experience. We also provide practical lessons and insights derived from developing, optimizing, and maintaining a production-scale recommendation system with significant real-world impact.
Embracing Imperfection: Simulating Students with Diverse Cognitive Levels Using LLM-based Agents
May 26, 2025Large language models (LLMs) are revolutionizing education, with LLM-based agents playing a key role in simulating student behavior. A major challenge in student simulation is modeling the diverse learning patterns of students at various cognitive levels. However, current LLMs, typically trained as ``helpful assistants'', target at generating perfect responses. As a result, they struggle to simulate students with diverse cognitive abilities, as they often produce overly advanced answers, missing the natural imperfections that characterize student learning and resulting in unrealistic simulations. To address this issue, we propose a training-free framework for student simulation. We begin by constructing a cognitive prototype for each student using a knowledge graph, which captures their understanding of concepts from past learning records. This prototype is then mapped to new tasks to predict student performance. Next, we simulate student solutions based on these predictions and iteratively refine them using a beam search method to better replicate realistic mistakes. To validate our approach, we construct the \texttt{Student\_100} dataset, consisting of $100$ students working on Python programming and $5,000$ learning records. Experimental results show that our method consistently outperforms baseline models, achieving $100\%$ improvement in simulation accuracy.
Breaking Complexity Barriers: High-Resolution Image Restoration with Rank Enhanced Linear Attention
May 22, 2025Transformer-based models have made remarkable progress in image restoration (IR) tasks. However, the quadratic complexity of self-attention in Transformer hinders its applicability to high-resolution images. Existing methods mitigate this issue with sparse or window-based attention, yet inherently limit global context modeling. Linear attention, a variant of softmax attention, demonstrates promise in global context modeling while maintaining linear complexity, offering a potential solution to the above challenge. Despite its efficiency benefits, vanilla linear attention suffers from a significant performance drop in IR, largely due to the low-rank nature of its attention map. To counter this, we propose Rank Enhanced Linear Attention (RELA), a simple yet effective method that enriches feature representations by integrating a lightweight depthwise convolution. Building upon RELA, we propose an efficient and effective image restoration Transformer, named LAformer. LAformer achieves effective global perception by integrating linear attention and channel attention, while also enhancing local fitting capabilities through a convolutional gated feed-forward network. Notably, LAformer eliminates hardware-inefficient operations such as softmax and window shifting, enabling efficient processing of high-resolution images. Extensive experiments across 7 IR tasks and 21 benchmarks demonstrate that LAformer outperforms SOTA methods and offers significant computational advantages.
LEAM: A Prompt-only Large Language Model-enabled Antenna Modeling Method
Apr 25, 2025Antenna modeling is a time-consuming and complex process, decreasing the speed of antenna analysis and design. In this paper, a large language model (LLM)- enabled antenna modeling method, called LEAM, is presented to address this challenge. LEAM enables automatic antenna model generation based on language descriptions via prompt input, images, descriptions from academic papers, patents, and technical reports (either one or multiple). The effectiveness of LEAM is demonstrated by three examples: a Vivaldi antenna generated from a complete user description, a slotted patch antenna generated from an incomplete user description and the operating frequency, and a monopole slotted antenna generated from images and descriptions scanned from the literature. For all the examples, correct antenna models are generated in a few minutes. The code can be accessed via https://github.com/TaoWu974/LEAM.
Disentangled Graph Representation Based on Substructure-Aware Graph Optimal Matching Kernel Convolutional Networks
Apr 23, 2025



Graphs effectively characterize relational data, driving graph representation learning methods that uncover underlying predictive information. As state-of-the-art approaches, Graph Neural Networks (GNNs) enable end-to-end learning for diverse tasks. Recent disentangled graph representation learning enhances interpretability by decoupling independent factors in graph data. However, existing methods often implicitly and coarsely characterize graph structures, limiting structural pattern analysis within the graph. This paper proposes the Graph Optimal Matching Kernel Convolutional Network (GOMKCN) to address this limitation. We view graphs as node-centric subgraphs, where each subgraph acts as a structural factor encoding position-specific information. This transforms graph prediction into structural pattern recognition. Inspired by CNNs, GOMKCN introduces the Graph Optimal Matching Kernel (GOMK) as a convolutional operator, computing similarities between subgraphs and learnable graph filters. Mathematically, GOMK maps subgraphs and filters into a Hilbert space, representing graphs as point sets. Disentangled representations emerge from projecting subgraphs onto task-optimized filters, which adaptively capture relevant structural patterns via gradient descent. Crucially, GOMK incorporates local correspondences in similarity measurement, resolving the trade-off between differentiability and accuracy in graph kernels. Experiments validate that GOMKCN achieves superior accuracy and interpretability in graph pattern mining and prediction. The framework advances the theoretical foundation for disentangled graph representation learning.
Enabling Heterogeneous Adversarial Transferability via Feature Permutation Attacks
Mar 26, 2025



Adversarial attacks in black-box settings are highly practical, with transfer-based attacks being the most effective at generating adversarial examples (AEs) that transfer from surrogate models to unseen target models. However, their performance significantly degrades when transferring across heterogeneous architectures -- such as CNNs, MLPs, and Vision Transformers (ViTs) -- due to fundamental architectural differences. To address this, we propose Feature Permutation Attack (FPA), a zero-FLOP, parameter-free method that enhances adversarial transferability across diverse architectures. FPA introduces a novel feature permutation (FP) operation, which rearranges pixel values in selected feature maps to simulate long-range dependencies, effectively making CNNs behave more like ViTs and MLPs. This enhances feature diversity and improves transferability both across heterogeneous architectures and within homogeneous CNNs. Extensive evaluations on 14 state-of-the-art architectures show that FPA achieves maximum absolute gains in attack success rates of 7.68% on CNNs, 14.57% on ViTs, and 14.48% on MLPs, outperforming existing black-box attacks. Additionally, FPA is highly generalizable and can seamlessly integrate with other transfer-based attacks to further boost their performance. Our findings establish FPA as a robust, efficient, and computationally lightweight strategy for enhancing adversarial transferability across heterogeneous architectures.
TransiT: Transient Transformer for Non-line-of-sight Videography
Mar 14, 2025



High quality and high speed videography using Non-Line-of-Sight (NLOS) imaging benefit autonomous navigation, collision prevention, and post-disaster search and rescue tasks. Current solutions have to balance between the frame rate and image quality. High frame rates, for example, can be achieved by reducing either per-point scanning time or scanning density, but at the cost of lowering the information density at individual frames. Fast scanning process further reduces the signal-to-noise ratio and different scanning systems exhibit different distortion characteristics. In this work, we design and employ a new Transient Transformer architecture called TransiT to achieve real-time NLOS recovery under fast scans. TransiT directly compresses the temporal dimension of input transients to extract features, reducing computation costs and meeting high frame rate requirements. It further adopts a feature fusion mechanism as well as employs a spatial-temporal Transformer to help capture features of NLOS transient videos. Moreover, TransiT applies transfer learning to bridge the gap between synthetic and real-measured data. In real experiments, TransiT manages to reconstruct from sparse transients of $16 \times 16$ measured at an exposure time of 0.4 ms per point to NLOS videos at a $64 \times 64$ resolution at 10 frames per second. We will make our code and dataset available to the community.