 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMerlin: Multi-View Representation Learning for Robust Multivariate Time Series Forecasting with Unfixed Missing Rates
Jun 14, 2025



Multivariate Time Series Forecasting (MTSF) involves predicting future values of multiple interrelated time series. Recently, deep learning-based MTSF models have gained significant attention for their promising ability to mine semantics (global and local information) within MTS data. However, these models are pervasively susceptible to missing values caused by malfunctioning data collectors. These missing values not only disrupt the semantics of MTS, but their distribution also changes over time. Nevertheless, existing models lack robustness to such issues, leading to suboptimal forecasting performance. To this end, in this paper, we propose Multi-View Representation Learning (Merlin), which can help existing models achieve semantic alignment between incomplete observations with different missing rates and complete observations in MTS. Specifically, Merlin consists of two key modules: offline knowledge distillation and multi-view contrastive learning. The former utilizes a teacher model to guide a student model in mining semantics from incomplete observations, similar to those obtainable from complete observations. The latter improves the student model's robustness by learning from positive/negative data pairs constructed from incomplete observations with different missing rates, ensuring semantic alignment across different missing rates. Therefore, Merlin is capable of effectively enhancing the robustness of existing models against unfixed missing rates while preserving forecasting accuracy. Experiments on four real-world datasets demonstrate the superiority of Merlin.
Generalization Error Analysis for Attack-Free and Byzantine-Resilient Decentralized Learning with Data Heterogeneity
Jun 11, 2025Decentralized learning, which facilitates joint model training across geographically scattered agents, has gained significant attention in the field of signal and information processing in recent years. While the optimization errors of decentralized learning algorithms have been extensively studied, their generalization errors remain relatively under-explored. As the generalization errors reflect the scalability of trained models on unseen data and are crucial in determining the performance of trained models in real-world applications, understanding the generalization errors of decentralized learning is of paramount importance. In this paper, we present fine-grained generalization error analysis for both attack-free and Byzantine-resilient decentralized learning with heterogeneous data as well as under mild assumptions, in contrast to prior studies that consider homogeneous data and/or rely on a stringent bounded stochastic gradient assumption. Our results shed light on the impact of data heterogeneity, model initialization and stochastic gradient noise -- factors that have not been closely investigated before -- on the generalization error of decentralized learning. We also reveal that Byzantine attacks performed by malicious agents largely affect the generalization error, and their negative impact is inherently linked to the data heterogeneity while remaining independent on the sample size. Numerical experiments on both convex and non-convex tasks are conducted to validate our theoretical findings.
Rectified Point Flow: Generic Point Cloud Pose Estimation
Jun 05, 2025



We introduce Rectified Point Flow, a unified parameterization that formulates pairwise point cloud registration and multi-part shape assembly as a single conditional generative problem. Given unposed point clouds, our method learns a continuous point-wise velocity field that transports noisy points toward their target positions, from which part poses are recovered. In contrast to prior work that regresses part-wise poses with ad-hoc symmetry handling, our method intrinsically learns assembly symmetries without symmetry labels. Together with a self-supervised encoder focused on overlapping points, our method achieves a new state-of-the-art performance on six benchmarks spanning pairwise registration and shape assembly. Notably, our unified formulation enables effective joint training on diverse datasets, facilitating the learning of shared geometric priors and consequently boosting accuracy. Project page: https://rectified-pointflow.github.io/.
OWL: Optimized Workforce Learning for General Multi-Agent Assistance in Real-World Task Automation
May 29, 2025Large Language Model (LLM)-based multi-agent systems show promise for automating real-world tasks but struggle to transfer across domains due to their domain-specific nature. Current approaches face two critical shortcomings: they require complete architectural redesign and full retraining of all components when applied to new domains. We introduce Workforce, a hierarchical multi-agent framework that decouples strategic planning from specialized execution through a modular architecture comprising: (i) a domain-agnostic Planner for task decomposition, (ii) a Coordinator for subtask management, and (iii) specialized Workers with domain-specific tool-calling capabilities. This decoupling enables cross-domain transferability during both inference and training phases: During inference, Workforce seamlessly adapts to new domains by adding or modifying worker agents; For training, we introduce Optimized Workforce Learning (OWL), which improves generalization across domains by optimizing a domain-agnostic planner with reinforcement learning from real-world feedback. To validate our approach, we evaluate Workforce on the GAIA benchmark, covering various realistic, multi-domain agentic tasks. Experimental results demonstrate Workforce achieves open-source state-of-the-art performance (69.70%), outperforming commercial systems like OpenAI's Deep Research by 2.34%. More notably, our OWL-trained 32B model achieves 52.73% accuracy (+16.37%) and demonstrates performance comparable to GPT-4o on challenging tasks. To summarize, by enabling scalable generalization and modular domain transfer, our work establishes a foundation for the next generation of general-purpose AI assistants.
P2P: Automated Paper-to-Poster Generation and Fine-Grained Benchmark
May 21, 2025



Academic posters are vital for scholarly communication, yet their manual creation is time-consuming. However, automated academic poster generation faces significant challenges in preserving intricate scientific details and achieving effective visual-textual integration. Existing approaches often struggle with semantic richness and structural nuances, and lack standardized benchmarks for evaluating generated academic posters comprehensively. To address these limitations, we introduce P2P, the first flexible, LLM-based multi-agent framework that generates high-quality, HTML-rendered academic posters directly from research papers, demonstrating strong potential for practical applications. P2P employs three specialized agents-for visual element processing, content generation, and final poster assembly-each integrated with dedicated checker modules to enable iterative refinement and ensure output quality. To foster advancements and rigorous evaluation in this domain, we construct and release P2PInstruct, the first large-scale instruction dataset comprising over 30,000 high-quality examples tailored for the academic paper-to-poster generation task. Furthermore, we establish P2PEval, a comprehensive benchmark featuring 121 paper-poster pairs and a dual evaluation methodology (Universal and Fine-Grained) that leverages LLM-as-a-Judge and detailed, human-annotated checklists. Our contributions aim to streamline research dissemination and provide the community with robust tools for developing and evaluating next-generation poster generation systems.
Infinigen-Sim: Procedural Generation of Articulated Simulation Assets
May 19, 2025

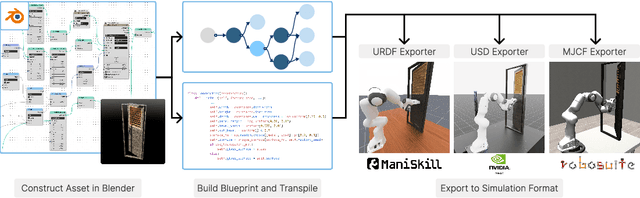
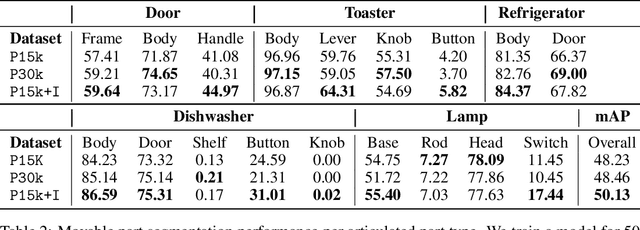
We introduce Infinigen-Sim, a toolkit which enables users to create diverse and realistic articulated object procedural generators. These tools are composed of high-level utilities for use creating articulated assets in Blender, as well as an export pipeline to integrate the resulting assets into common robotics simulators. We demonstrate our system by creating procedural generators for 5 common articulated object categories. Experiments show that assets sampled from these generators are useful for movable object segmentation, training generalizable reinforcement learning policies, and sim-to-real transfer of imitation learning policies.
PsyCounAssist: A Full-Cycle AI-Powered Psychological Counseling Assistant System
Apr 23, 2025

Psychological counseling is a highly personalized and dynamic process that requires therapists to continuously monitor emotional changes, document session insights, and maintain therapeutic continuity. In this paper, we introduce PsyCounAssist, a comprehensive AI-powered counseling assistant system specifically designed to augment psychological counseling practices. PsyCounAssist integrates multimodal emotion recognition combining speech and photoplethysmography (PPG) signals for accurate real-time affective analysis, automated structured session reporting using large language models (LLMs), and personalized AI-generated follow-up support. Deployed on Android-based tablet devices, the system demonstrates practical applicability and flexibility in real-world counseling scenarios. Experimental evaluation confirms the reliability of PPG-based emotional classification and highlights the system's potential for non-intrusive, privacy-aware emotional support. PsyCounAssist represents a novel approach to ethically and effectively integrating AI into psychological counseling workflows.
Breaking Memory Limits: Gradient Wavelet Transform Enhances LLMs Training
Jan 13, 2025



Large language models (LLMs) have shown impressive performance across a range of natural language processing tasks. However, their vast number of parameters introduces significant memory challenges during training, particularly when using memory-intensive optimizers like Adam. Existing memory-efficient algorithms often rely on techniques such as singular value decomposition projection or weight freezing. While these approaches help alleviate memory constraints, they generally produce suboptimal results compared to full-rank updates. In this paper, we investigate the memory-efficient method beyond low-rank training, proposing a novel solution called Gradient Wavelet Transform (GWT), which applies wavelet transforms to gradients in order to significantly reduce the memory requirements for maintaining optimizer states. We demonstrate that GWT can be seamlessly integrated with memory-intensive optimizers, enabling efficient training without sacrificing performance. Through extensive experiments on both pre-training and fine-tuning tasks, we show that GWT achieves state-of-the-art performance compared with advanced memory-efficient optimizers and full-rank approaches in terms of both memory usage and training performance.
Sharpness-Aware Minimization with Adaptive Regularization for Training Deep Neural Networks
Dec 22, 2024



Sharpness-Aware Minimization (SAM) has proven highly effective in improving model generalization in machine learning tasks. However, SAM employs a fixed hyperparameter associated with the regularization to characterize the sharpness of the model. Despite its success, research on adaptive regularization methods based on SAM remains scarce. In this paper, we propose the SAM with Adaptive Regularization (SAMAR), which introduces a flexible sharpness ratio rule to update the regularization parameter dynamically. We provide theoretical proof of the convergence of SAMAR for functions satisfying the Lipschitz continuity. Additionally, experiments on image recognition tasks using CIFAR-10 and CIFAR-100 demonstrate that SAMAR enhances accuracy and model generalization.
Overview of AI and Communication for 6G Network: Fundamentals, Challenges, and Future Research Opportunities
Dec 19, 2024



With the increasing demand for seamless connectivity and intelligent communication, the integration of artificial intelligence (AI) and communication for sixth-generation (6G) network is emerging as a revolutionary architecture. This paper presents a comprehensive overview of AI and communication for 6G networks, emphasizing their foundational principles, inherent challenges, and future research opportunities. We commence with a retrospective analysis of AI and the evolution of large-scale AI models, underscoring their pivotal roles in shaping contemporary communication technologies. The discourse then transitions to a detailed exposition of the envisioned integration of AI within 6G networks, delineated across three progressive developmental stages. The initial stage, AI for Network, focuses on employing AI to augment network performance, optimize efficiency, and enhance user service experiences. The subsequent stage, Network for AI, highlights the role of the network in facilitating and buttressing AI operations and presents key enabling technologies, including digital twins for AI and semantic communication. In the final stage, AI as a Service, it is anticipated that future 6G networks will innately provide AI functions as services and support application scenarios like immersive communication and intelligent industrial robots. Specifically, we have defined the quality of AI service, which refers to the measurement framework system of AI services within the network. In addition to these developmental stages, we thoroughly examine the standardization processes pertinent to AI in network contexts, highlighting key milestones and ongoing efforts. Finally, we outline promising future research opportunities that could drive the evolution and refinement of AI and communication for 6G, positioning them as a cornerstone of next-generation communication infrastructure.