 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZero-Shot Depth from Defocus
Mar 27, 2026Depth from Defocus (DfD) is the task of estimating a dense metric depth map from a focus stack. Unlike previous works overfitting to a certain dataset, this paper focuses on the challenging and practical setting of zero-shot generalization. We first propose a new real-world DfD benchmark ZEDD, which contains 8.3x more scenes and significantly higher quality images and ground-truth depth maps compared to previous benchmarks. We also design a novel network architecture named FOSSA. FOSSA is a Transformer-based architecture with novel designs tailored to the DfD task. The key contribution is a stack attention layer with a focus distance embedding, allowing efficient information exchange across the focus stack. Finally, we develop a new training data pipeline allowing us to utilize existing large-scale RGBD datasets to generate synthetic focus stacks. Experiment results on ZEDD and other benchmarks show a significant improvement over the baselines, reducing errors by up to 55.7%. The ZEDD benchmark is released at https://zedd.cs.princeton.edu. The code and checkpoints are released at https://github.com/princeton-vl/FOSSA.
Princeton365: A Diverse Dataset with Accurate Camera Pose
Jun 10, 2025We introduce Princeton365, a large-scale diverse dataset of 365 videos with accurate camera pose. Our dataset bridges the gap between accuracy and data diversity in current SLAM benchmarks by introducing a novel ground truth collection framework that leverages calibration boards and a 360-camera. We collect indoor, outdoor, and object scanning videos with synchronized monocular and stereo RGB video outputs as well as IMU. We further propose a new scene scale-aware evaluation metric for SLAM based on the the optical flow induced by the camera pose estimation error. In contrast to the current metrics, our new metric allows for comparison between the performance of SLAM methods across scenes as opposed to existing metrics such as Average Trajectory Error (ATE), allowing researchers to analyze the failure modes of their methods. We also propose a challenging Novel View Synthesis benchmark that covers cases not covered by current NVS benchmarks, such as fully non-Lambertian scenes with 360-degree camera trajectories. Please visit https://princeton365.cs.princeton.edu for the dataset, code, videos, and submission.
Infinigen-Sim: Procedural Generation of Articulated Simulation Assets
May 19, 2025

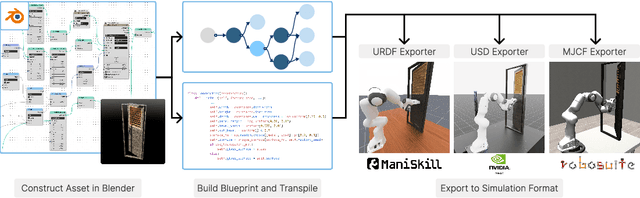
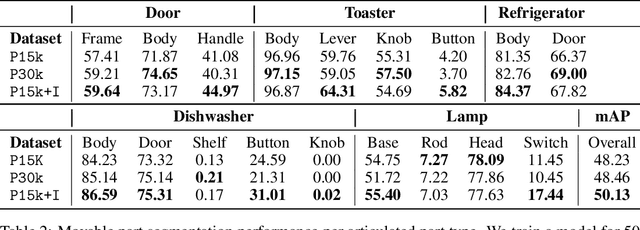
We introduce Infinigen-Sim, a toolkit which enables users to create diverse and realistic articulated object procedural generators. These tools are composed of high-level utilities for use creating articulated assets in Blender, as well as an export pipeline to integrate the resulting assets into common robotics simulators. We demonstrate our system by creating procedural generators for 5 common articulated object categories. Experiments show that assets sampled from these generators are useful for movable object segmentation, training generalizable reinforcement learning policies, and sim-to-real transfer of imitation learning policies.
Seeing and Seeing Through the Glass: Real and Synthetic Data for Multi-Layer Depth Estimation
Mar 14, 2025Transparent objects are common in daily life, and understanding their multi-layer depth information -- perceiving both the transparent surface and the objects behind it -- is crucial for real-world applications that interact with transparent materials. In this paper, we introduce LayeredDepth, the first dataset with multi-layer depth annotations, including a real-world benchmark and a synthetic data generator, to support the task of multi-layer depth estimation. Our real-world benchmark consists of 1,500 images from diverse scenes, and evaluating state-of-the-art depth estimation methods on it reveals that they struggle with transparent objects. The synthetic data generator is fully procedural and capable of providing training data for this task with an unlimited variety of objects and scene compositions. Using this generator, we create a synthetic dataset with 15,300 images. Baseline models training solely on this synthetic dataset produce good cross-domain multi-layer depth estimation. Fine-tuning state-of-the-art single-layer depth models on it substantially improves their performance on transparent objects, with quadruplet accuracy on our benchmark increased from 55.14% to 75.20%. All images and validation annotations are available under CC0 at https://layereddepth.cs.princeton.edu.
OMNI-DC: Highly Robust Depth Completion with Multiresolution Depth Integration
Nov 28, 2024



Depth completion (DC) aims to predict a dense depth map from an RGB image and sparse depth observations. Existing methods for DC generalize poorly on new datasets or unseen sparse depth patterns, limiting their practical applications. We propose OMNI-DC, a highly robust DC model that generalizes well across various scenarios. Our method incorporates a novel multi-resolution depth integration layer and a probability-based loss, enabling it to deal with sparse depth maps of varying densities. Moreover, we train OMNI-DC on a mixture of synthetic datasets with a scale normalization technique. To evaluate our model, we establish a new evaluation protocol named Robust-DC for zero-shot testing under various sparse depth patterns. Experimental results on Robust-DC and conventional benchmarks show that OMNI-DC significantly outperforms the previous state of the art. The checkpoints, training code, and evaluations are available at https://github.com/princeton-vl/OMNI-DC.
Towards Foundation Models for 3D Vision: How Close Are We?
Oct 14, 2024



Building a foundation model for 3D vision is a complex challenge that remains unsolved. Towards that goal, it is important to understand the 3D reasoning capabilities of current models as well as identify the gaps between these models and humans. Therefore, we construct a new 3D visual understanding benchmark that covers fundamental 3D vision tasks in the Visual Question Answering (VQA) format. We evaluate state-of-the-art Vision-Language Models (VLMs), specialized models, and human subjects on it. Our results show that VLMs generally perform poorly, while the specialized models are accurate but not robust, failing under geometric perturbations. In contrast, human vision continues to be the most reliable 3D visual system. We further demonstrate that neural networks align more closely with human 3D vision mechanisms compared to classical computer vision methods, and Transformer-based networks such as ViT align more closely with human 3D vision mechanisms than CNNs. We hope our study will benefit the future development of foundation models for 3D vision.
Infinigen Indoors: Photorealistic Indoor Scenes using Procedural Generation
Jun 17, 2024



We introduce Infinigen Indoors, a Blender-based procedural generator of photorealistic indoor scenes. It builds upon the existing Infinigen system, which focuses on natural scenes, but expands its coverage to indoor scenes by introducing a diverse library of procedural indoor assets, including furniture, architecture elements, appliances, and other day-to-day objects. It also introduces a constraint-based arrangement system, which consists of a domain-specific language for expressing diverse constraints on scene composition, and a solver that generates scene compositions that maximally satisfy the constraints. We provide an export tool that allows the generated 3D objects and scenes to be directly used for training embodied agents in real-time simulators such as Omniverse and Unreal. Infinigen Indoors is open-sourced under the BSD license. Please visit https://infinigen.org for code and videos.
OGNI-DC: Robust Depth Completion with Optimization-Guided Neural Iterations
Jun 17, 2024



Depth completion is the task of generating a dense depth map given an image and a sparse depth map as inputs. It has important applications in various downstream tasks. In this paper, we present OGNI-DC, a novel framework for depth completion. The key to our method is "Optimization-Guided Neural Iterations" (OGNI). It consists of a recurrent unit that refines a depth gradient field and a differentiable depth integrator that integrates the depth gradients into a depth map. OGNI-DC exhibits strong generalization, outperforming baselines by a large margin on unseen datasets and across various sparsity levels. Moreover, OGNI-DC has high accuracy, achieving state-of-the-art performance on the NYUv2 and the KITTI benchmarks. Code is available at https://github.com/princeton-vl/OGNI-DC.
Infinite Photorealistic Worlds using Procedural Generation
Jun 26, 2023



We introduce Infinigen, a procedural generator of photorealistic 3D scenes of the natural world. Infinigen is entirely procedural: every asset, from shape to texture, is generated from scratch via randomized mathematical rules, using no external source and allowing infinite variation and composition. Infinigen offers broad coverage of objects and scenes in the natural world including plants, animals, terrains, and natural phenomena such as fire, cloud, rain, and snow. Infinigen can be used to generate unlimited, diverse training data for a wide range of computer vision tasks including object detection, semantic segmentation, optical flow, and 3D reconstruction. We expect Infinigen to be a useful resource for computer vision research and beyond. Please visit https://infinigen.org for videos, code and pre-generated data.
View Synthesis with Sculpted Neural Points
May 12, 2022
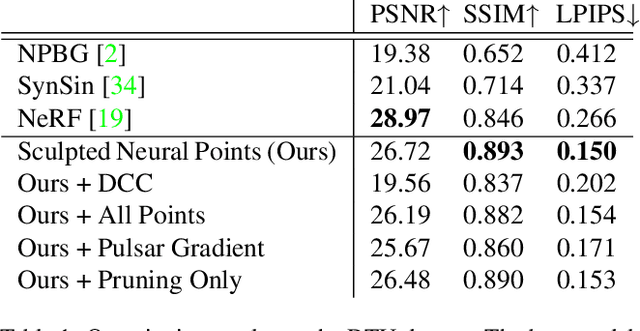


We address the task of view synthesis, which can be posed as recovering a rendering function that renders new views from a set of existing images. In many recent works such as NeRF, this rendering function is parameterized using implicit neural representations of scene geometry. Implicit neural representations have achieved impressive visual quality but have drawbacks in computational efficiency. In this work, we propose a new approach that performs view synthesis using point clouds. It is the first point-based method to achieve better visual quality than NeRF while being more than 100x faster in rendering speed. Our approach builds on existing works on differentiable point-based rendering but introduces a novel technique we call "Sculpted Neural Points (SNP)", which significantly improves the robustness to errors and holes in the reconstructed point cloud. Experiments show that on the task of view synthesis, our sculpting technique closes the gap between point-based and implicit representation-based methods. Code is available at https://github.com/princeton-vl/SNP and supplementary video at https://youtu.be/dBwCQP9uNws.