 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTopology-Independent Robustness of the Weighted Mean under Label Poisoning Attacks in Heterogeneous Decentralized Learning
Jan 06, 2026Robustness to malicious attacks is crucial for practical decentralized signal processing and machine learning systems. A typical example of such attacks is label poisoning, meaning that some agents possess corrupted local labels and share models trained on these poisoned data. To defend against malicious attacks, existing works often focus on designing robust aggregators; meanwhile, the weighted mean aggregator is typically considered a simple, vulnerable baseline. This paper analyzes the robustness of decentralized gradient descent under label poisoning attacks, considering both robust and weighted mean aggregators. Theoretical results reveal that the learning errors of robust aggregators depend on the network topology, whereas the performance of weighted mean aggregator is topology-independent. Remarkably, the weighted mean aggregator, although often considered vulnerable, can outperform robust aggregators under sufficient heterogeneity, particularly when: (i) the global contamination rate (i.e., the fraction of poisoned agents for the entire network) is smaller than the local contamination rate (i.e., the maximal fraction of poisoned neighbors for the regular agents); (ii) the network of regular agents is disconnected; or (iii) the network of regular agents is sparse and the local contamination rate is high. Empirical results support our theoretical findings, highlighting the important role of network topology in the robustness to label poisoning attacks.
Generalization Error Analysis for Attack-Free and Byzantine-Resilient Decentralized Learning with Data Heterogeneity
Jun 11, 2025Decentralized learning, which facilitates joint model training across geographically scattered agents, has gained significant attention in the field of signal and information processing in recent years. While the optimization errors of decentralized learning algorithms have been extensively studied, their generalization errors remain relatively under-explored. As the generalization errors reflect the scalability of trained models on unseen data and are crucial in determining the performance of trained models in real-world applications, understanding the generalization errors of decentralized learning is of paramount importance. In this paper, we present fine-grained generalization error analysis for both attack-free and Byzantine-resilient decentralized learning with heterogeneous data as well as under mild assumptions, in contrast to prior studies that consider homogeneous data and/or rely on a stringent bounded stochastic gradient assumption. Our results shed light on the impact of data heterogeneity, model initialization and stochastic gradient noise -- factors that have not been closely investigated before -- on the generalization error of decentralized learning. We also reveal that Byzantine attacks performed by malicious agents largely affect the generalization error, and their negative impact is inherently linked to the data heterogeneity while remaining independent on the sample size. Numerical experiments on both convex and non-convex tasks are conducted to validate our theoretical findings.
Exploring the Landscape of Text-to-SQL with Large Language Models: Progresses, Challenges and Opportunities
May 28, 2025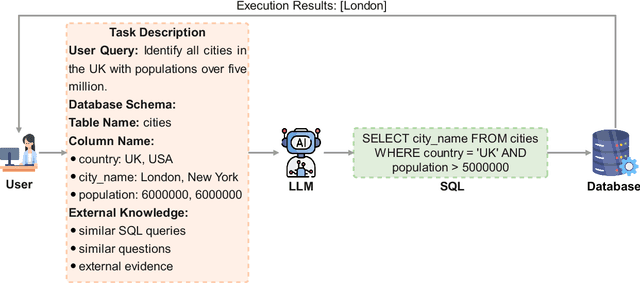
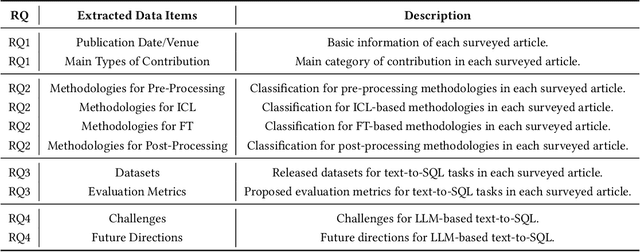
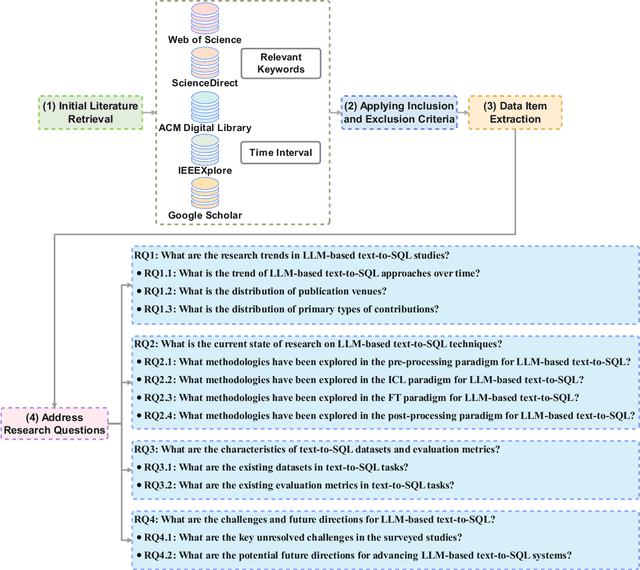
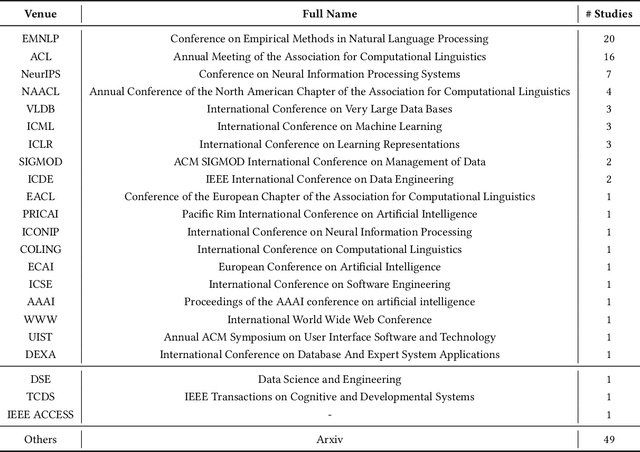
Converting natural language (NL) questions into SQL queries, referred to as Text-to-SQL, has emerged as a pivotal technology for facilitating access to relational databases, especially for users without SQL knowledge. Recent progress in large language models (LLMs) has markedly propelled the field of natural language processing (NLP), opening new avenues to improve text-to-SQL systems. This study presents a systematic review of LLM-based text-to-SQL, focusing on four key aspects: (1) an analysis of the research trends in LLM-based text-to-SQL; (2) an in-depth analysis of existing LLM-based text-to-SQL techniques from diverse perspectives; (3) summarization of existing text-to-SQL datasets and evaluation metrics; and (4) discussion on potential obstacles and avenues for future exploration in this domain. This survey seeks to furnish researchers with an in-depth understanding of LLM-based text-to-SQL, sparking new innovations and advancements in this field.
Physics-Assisted and Topology-Informed Deep Learning for Weather Prediction
May 08, 2025Although deep learning models have demonstrated remarkable potential in weather prediction, most of them overlook either the \textbf{physics} of the underlying weather evolution or the \textbf{topology} of the Earth's surface. In light of these disadvantages, we develop PASSAT, a novel Physics-ASSisted And Topology-informed deep learning model for weather prediction. PASSAT attributes the weather evolution to two key factors: (i) the advection process that can be characterized by the advection equation and the Navier-Stokes equation; (ii) the Earth-atmosphere interaction that is difficult to both model and calculate. PASSAT also takes the topology of the Earth's surface into consideration, other than simply treating it as a plane. With these considerations, PASSAT numerically solves the advection equation and the Navier-Stokes equation on the spherical manifold, utilizes a spherical graph neural network to capture the Earth-atmosphere interaction, and generates the initial velocity fields that are critical to solving the advection equation from the same spherical graph neural network. In the $5.625^\circ$-resolution ERA5 data set, PASSAT outperforms both the state-of-the-art deep learning-based weather prediction models and the operational numerical weather prediction model IFS T42. Code and checkpoint are available at https://github.com/Yumenomae/PASSAT_5p625.
Optimal Complexity in Byzantine-Robust Distributed Stochastic Optimization with Data Heterogeneity
Mar 20, 2025In this paper, we establish tight lower bounds for Byzantine-robust distributed first-order stochastic optimization methods in both strongly convex and non-convex stochastic optimization. We reveal that when the distributed nodes have heterogeneous data, the convergence error comprises two components: a non-vanishing Byzantine error and a vanishing optimization error. We establish the lower bounds on the Byzantine error and on the minimum number of queries to a stochastic gradient oracle required to achieve an arbitrarily small optimization error. Nevertheless, we identify significant discrepancies between our established lower bounds and the existing upper bounds. To fill this gap, we leverage the techniques of Nesterov's acceleration and variance reduction to develop novel Byzantine-robust distributed stochastic optimization methods that provably match these lower bounds, up to logarithmic factors, implying that our established lower bounds are tight.
Single-Timescale Multi-Sequence Stochastic Approximation Without Fixed Point Smoothness: Theories and Applications
Oct 17, 2024Stochastic approximation (SA) that involves multiple coupled sequences, known as multiple-sequence SA (MSSA), finds diverse applications in the fields of signal processing and machine learning. However, existing theoretical understandings {of} MSSA are limited: the multi-timescale analysis implies a slow convergence rate, whereas the single-timescale analysis relies on a stringent fixed point smoothness assumption. This paper establishes tighter single-timescale analysis for MSSA, without assuming smoothness of the fixed points. Our theoretical findings reveal that, when all involved operators are strongly monotone, MSSA converges at a rate of $\tilde{\mathcal{O}}(K^{-1})$, where $K$ denotes the total number of iterations. In addition, when all involved operators are strongly monotone except for the main one, MSSA converges at a rate of $\mathcal{O}(K^{-\frac{1}{2}})$. These theoretical findings align with those established for single-sequence SA. Applying these theoretical findings to bilevel optimization and communication-efficient distributed learning offers relaxed assumptions and/or simpler algorithms with performance guarantees, as validated by numerical experiments.
Generalization Error Matters in Decentralized Learning Under Byzantine Attacks
Jul 11, 2024Recently, decentralized learning has emerged as a popular peer-to-peer signal and information processing paradigm that enables model training across geographically distributed agents in a scalable manner, without the presence of any central server. When some of the agents are malicious (also termed as Byzantine), resilient decentralized learning algorithms are able to limit the impact of these Byzantine agents without knowing their number and identities, and have guaranteed optimization errors. However, analysis of the generalization errors, which are critical to implementations of the trained models, is still lacking. In this paper, we provide the first analysis of the generalization errors for a class of popular Byzantine-resilient decentralized stochastic gradient descent (DSGD) algorithms. Our theoretical results reveal that the generalization errors cannot be entirely eliminated because of the presence of the Byzantine agents, even if the number of training samples are infinitely large. Numerical experiments are conducted to confirm our theoretical results.
Mean Aggregator Is More Robust Than Robust Aggregators Under Label Poisoning Attacks
Apr 21, 2024



Robustness to malicious attacks is of paramount importance for distributed learning. Existing works often consider the classical Byzantine attacks model, which assumes that some workers can send arbitrarily malicious messages to the server and disturb the aggregation steps of the distributed learning process. To defend against such worst-case Byzantine attacks, various robust aggregators have been proven effective and much superior to the often-used mean aggregator. In this paper, we show that robust aggregators are too conservative for a class of weak but practical malicious attacks, as known as label poisoning attacks, where the sample labels of some workers are poisoned. Surprisingly, we are able to show that the mean aggregator is more robust than the state-of-the-art robust aggregators in theory, given that the distributed data are sufficiently heterogeneous. In fact, the learning error of the mean aggregator is proven to be optimal in order. Experimental results corroborate our theoretical findings, demonstrating the superiority of the mean aggregator under label poisoning attacks.
On the Tradeoff between Privacy Preservation and Byzantine-Robustness in Decentralized Learning
Aug 28, 2023



This paper jointly considers privacy preservation and Byzantine-robustness in decentralized learning. In a decentralized network, honest-but-curious agents faithfully follow the prescribed algorithm, but expect to infer their neighbors' private data from messages received during the learning process, while dishonest-and-Byzantine agents disobey the prescribed algorithm, and deliberately disseminate wrong messages to their neighbors so as to bias the learning process. For this novel setting, we investigate a generic privacy-preserving and Byzantine-robust decentralized stochastic gradient descent (SGD) framework, in which Gaussian noise is injected to preserve privacy and robust aggregation rules are adopted to counteract Byzantine attacks. We analyze its learning error and privacy guarantee, discovering an essential tradeoff between privacy preservation and Byzantine-robustness in decentralized learning -- the learning error caused by defending against Byzantine attacks is exacerbated by the Gaussian noise added to preserve privacy. Numerical experiments are conducted and corroborate our theoretical findings.
Byzantine-Robust Decentralized Stochastic Optimization with Stochastic Gradient Noise-Independent Learning Error
Aug 10, 2023



This paper studies Byzantine-robust stochastic optimization over a decentralized network, where every agent periodically communicates with its neighbors to exchange local models, and then updates its own local model by stochastic gradient descent (SGD). The performance of such a method is affected by an unknown number of Byzantine agents, which conduct adversarially during the optimization process. To the best of our knowledge, there is no existing work that simultaneously achieves a linear convergence speed and a small learning error. We observe that the learning error is largely dependent on the intrinsic stochastic gradient noise. Motivated by this observation, we introduce two variance reduction methods, stochastic average gradient algorithm (SAGA) and loopless stochastic variance-reduced gradient (LSVRG), to Byzantine-robust decentralized stochastic optimization for eliminating the negative effect of the stochastic gradient noise. The two resulting methods, BRAVO-SAGA and BRAVO-LSVRG, enjoy both linear convergence speeds and stochastic gradient noise-independent learning errors. Such learning errors are optimal for a class of methods based on total variation (TV)-norm regularization and stochastic subgradient update. We conduct extensive numerical experiments to demonstrate their effectiveness under various Byzantine attacks.