 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGraspGen-X: Cross-Embodiment 6-DOF Diffusion-based Grasping
May 31, 2026We study cross-embodiment 6-DOF robot grasping. Unlike prior works, we require the model not only to generalize to novel objects / scenes but also to novel gripper morphologies and physical grasping processes. Our method extends diffusion model based generative 6-DOF grasping models to condition on the additional gripper's representation. We propose a swept-volume heuristic for encoding the gripper. We train our cross-embodiment model with procedural grippers and a large-scale dataset of 2 Billion grasps. In simulation experiments, our model has the best zero-shot generalization to novel real-world grippers and objects over baseline methods. Our model also serves as a good initialization for fine-tuning to adapt to novel grippers. In ablations, we demonstrate the efficiency of our sweep-volume gripper representation and our procedural gripper training dataset. Last, we show zero-shot generalization to real-world novel grippers for 6-DOF grasping, surpassing baselines in cross-embodiment generalization.
Evaluating Robustness of Monocular Depth Estimation with Procedural Scene Perturbations
Jul 01, 2025Recent years have witnessed substantial progress on monocular depth estimation, particularly as measured by the success of large models on standard benchmarks. However, performance on standard benchmarks does not offer a complete assessment, because most evaluate accuracy but not robustness. In this work, we introduce PDE (Procedural Depth Evaluation), a new benchmark which enables systematic robustness evaluation. PDE uses procedural generation to create 3D scenes that test robustness to various controlled perturbations, including object, camera, material and lighting changes. Our analysis yields interesting findings on what perturbations are challenging for state-of-the-art depth models, which we hope will inform further research. Code and data are available at https://github.com/princeton-vl/proc-depth-eval.
AnyBody: A Benchmark Suite for Cross-Embodiment Manipulation
May 21, 2025Generalizing control policies to novel embodiments remains a fundamental challenge in enabling scalable and transferable learning in robotics. While prior works have explored this in locomotion, a systematic study in the context of manipulation tasks remains limited, partly due to the lack of standardized benchmarks. In this paper, we introduce a benchmark for learning cross-embodiment manipulation, focusing on two foundational tasks-reach and push-across a diverse range of morphologies. The benchmark is designed to test generalization along three axes: interpolation (testing performance within a robot category that shares the same link structure), extrapolation (testing on a robot with a different link structure), and composition (testing on combinations of link structures). On the benchmark, we evaluate the ability of different RL policies to learn from multiple morphologies and to generalize to novel ones. Our study aims to answer whether morphology-aware training can outperform single-embodiment baselines, whether zero-shot generalization to unseen morphologies is feasible, and how consistently these patterns hold across different generalization regimes. The results highlight the current limitations of multi-embodiment learning and provide insights into how architectural and training design choices influence policy generalization.
Infinigen-Sim: Procedural Generation of Articulated Simulation Assets
May 19, 2025

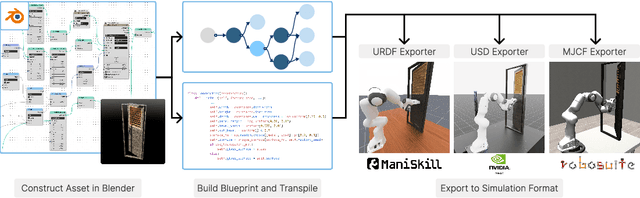
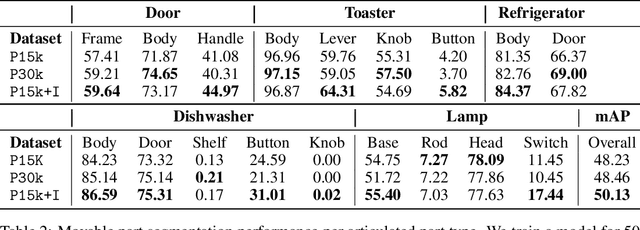
We introduce Infinigen-Sim, a toolkit which enables users to create diverse and realistic articulated object procedural generators. These tools are composed of high-level utilities for use creating articulated assets in Blender, as well as an export pipeline to integrate the resulting assets into common robotics simulators. We demonstrate our system by creating procedural generators for 5 common articulated object categories. Experiments show that assets sampled from these generators are useful for movable object segmentation, training generalizable reinforcement learning policies, and sim-to-real transfer of imitation learning policies.
Zero-shot Sim2Real Transfer for Magnet-Based Tactile Sensor on Insertion Tasks
May 05, 2025



Tactile sensing is an important sensing modality for robot manipulation. Among different types of tactile sensors, magnet-based sensors, like u-skin, balance well between high durability and tactile density. However, the large sim-to-real gap of tactile sensors prevents robots from acquiring useful tactile-based manipulation skills from simulation data, a recipe that has been successful for achieving complex and sophisticated control policies. Prior work has implemented binarization techniques to bridge the sim-to-real gap for dexterous in-hand manipulation. However, binarization inherently loses much information that is useful in many other tasks, e.g., insertion. In our work, we propose GCS, a novel sim-to-real technique to learn contact-rich skills with dense, distributed, 3-axis tactile readings. We evaluate our approach on blind insertion tasks and show zero-shot sim-to-real transfer of RL policies with raw tactile reading as input.
Infinigen Indoors: Photorealistic Indoor Scenes using Procedural Generation
Jun 17, 2024



We introduce Infinigen Indoors, a Blender-based procedural generator of photorealistic indoor scenes. It builds upon the existing Infinigen system, which focuses on natural scenes, but expands its coverage to indoor scenes by introducing a diverse library of procedural indoor assets, including furniture, architecture elements, appliances, and other day-to-day objects. It also introduces a constraint-based arrangement system, which consists of a domain-specific language for expressing diverse constraints on scene composition, and a solver that generates scene compositions that maximally satisfy the constraints. We provide an export tool that allows the generated 3D objects and scenes to be directly used for training embodied agents in real-time simulators such as Omniverse and Unreal. Infinigen Indoors is open-sourced under the BSD license. Please visit https://infinigen.org for code and videos.
FetchBench: A Simulation Benchmark for Robot Fetching
Jun 17, 2024Fetching, which includes approaching, grasping, and retrieving, is a critical challenge for robot manipulation tasks. Existing methods primarily focus on table-top scenarios, which do not adequately capture the complexities of environments where both grasping and planning are essential. To address this gap, we propose a new benchmark FetchBench, featuring diverse procedural scenes that integrate both grasping and motion planning challenges. Additionally, FetchBench includes a data generation pipeline that collects successful fetch trajectories for use in imitation learning methods. We implement multiple baselines from the traditional sense-plan-act pipeline to end-to-end behavior models. Our empirical analysis reveals that these methods achieve a maximum success rate of only 20%, indicating substantial room for improvement. Additionally, we identify key bottlenecks within the sense-plan-act pipeline and make recommendations based on the systematic analysis.
Infinite Photorealistic Worlds using Procedural Generation
Jun 26, 2023



We introduce Infinigen, a procedural generator of photorealistic 3D scenes of the natural world. Infinigen is entirely procedural: every asset, from shape to texture, is generated from scratch via randomized mathematical rules, using no external source and allowing infinite variation and composition. Infinigen offers broad coverage of objects and scenes in the natural world including plants, animals, terrains, and natural phenomena such as fire, cloud, rain, and snow. Infinigen can be used to generate unlimited, diverse training data for a wide range of computer vision tasks including object detection, semantic segmentation, optical flow, and 3D reconstruction. We expect Infinigen to be a useful resource for computer vision research and beyond. Please visit https://infinigen.org for videos, code and pre-generated data.
Learning Domain Invariant Representations in Goal-conditioned Block MDPs
Oct 28, 2021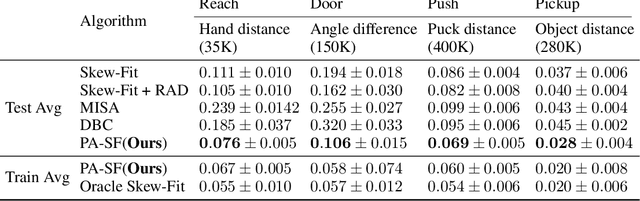
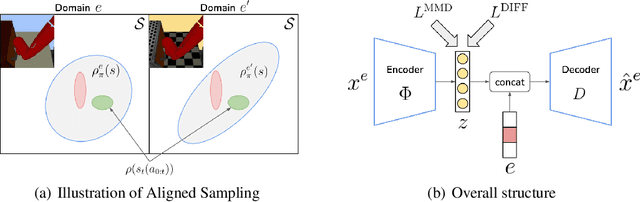

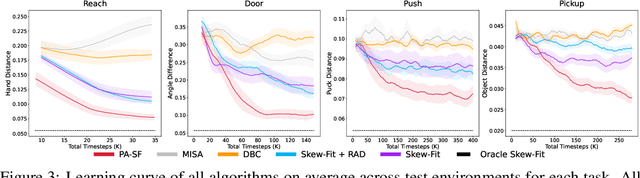
Deep Reinforcement Learning (RL) is successful in solving many complex Markov Decision Processes (MDPs) problems. However, agents often face unanticipated environmental changes after deployment in the real world. These changes are often spurious and unrelated to the underlying problem, such as background shifts for visual input agents. Unfortunately, deep RL policies are usually sensitive to these changes and fail to act robustly against them. This resembles the problem of domain generalization in supervised learning. In this work, we study this problem for goal-conditioned RL agents. We propose a theoretical framework in the Block MDP setting that characterizes the generalizability of goal-conditioned policies to new environments. Under this framework, we develop a practical method PA-SkewFit that enhances domain generalization. The empirical evaluation shows that our goal-conditioned RL agent can perform well in various unseen test environments, improving by 50% over baselines.
* 33 pages
On the Estimation Bias in Double Q-Learning
Sep 29, 2021
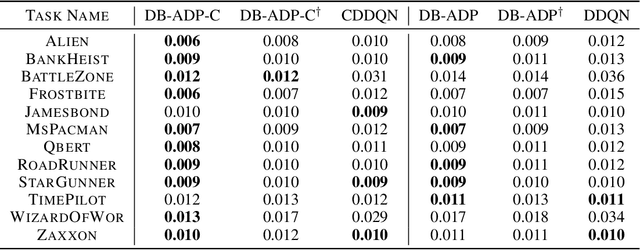
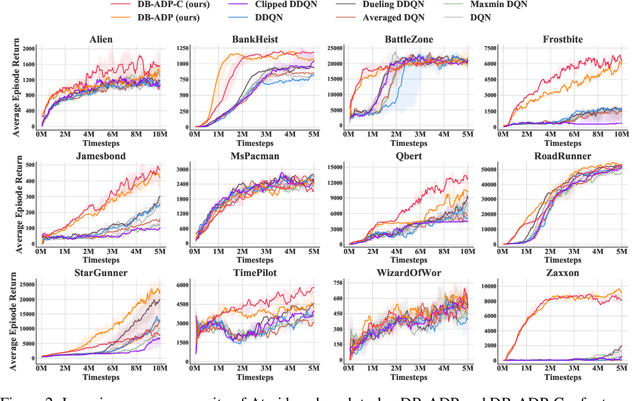
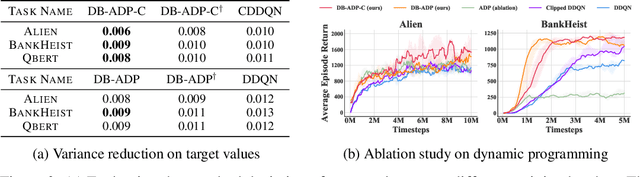
Double Q-learning is a classical method for reducing overestimation bias, which is caused by taking maximum estimated values in the Bellman operation. Its variants in the deep Q-learning paradigm have shown great promise in producing reliable value prediction and improving learning performance. However, as shown by prior work, double Q-learning is not fully unbiased and suffers from underestimation bias. In this paper, we show that such underestimation bias may lead to multiple non-optimal fixed points under an approximated Bellman operator. To address the concerns of converging to non-optimal stationary solutions, we propose a simple but effective approach as a partial fix for the underestimation bias in double Q-learning. This approach leverages an approximate dynamic programming to bound the target value. We extensively evaluate our proposed method in the Atari benchmark tasks and demonstrate its significant improvement over baseline algorithms.