 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgedaBNN: A Super Fast Inference Framework for Binary Neural Networks on ARM devices
Aug 16, 2019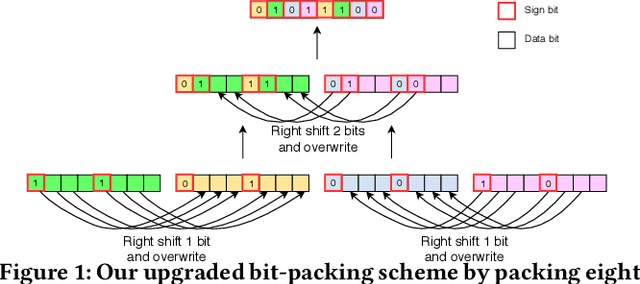

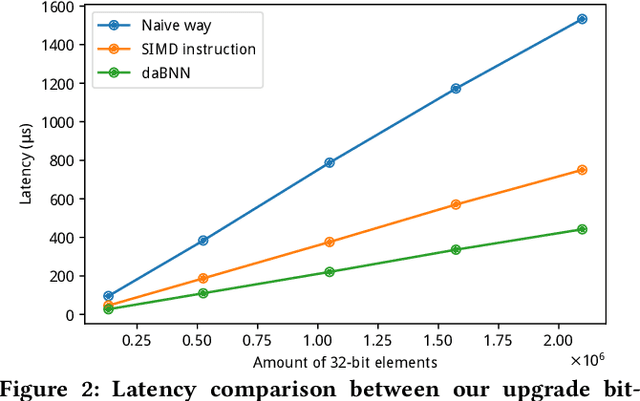
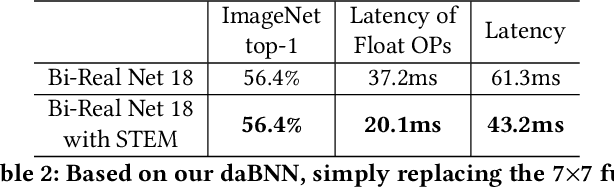
It is always well believed that Binary Neural Networks (BNNs) could drastically accelerate the inference efficiency by replacing the arithmetic operations in float-valued Deep Neural Networks (DNNs) with bit-wise operations. Nevertheless, there has not been open-source implementation in support of this idea on low-end ARM devices (e.g., mobile phones and embedded devices). In this work, we propose daBNN --- a super fast inference framework that implements BNNs on ARM devices. Several speed-up and memory refinement strategies for bit-packing, binarized convolution, and memory layout are uniquely devised to enhance inference efficiency. Compared to the recent open-source BNN inference framework, BMXNet, our daBNN is $7\times$$\sim$$23\times$ faster on a single binary convolution, and about $6\times$ faster on Bi-Real Net 18 (a BNN variant of ResNet-18). The daBNN is a BSD-licensed inference framework, and its source code, sample projects and pre-trained models are available on-line: https://github.com/JDAI-CV/dabnn.
Convolutional Auto-encoding of Sentence Topics for Image Paragraph Generation
Aug 01, 2019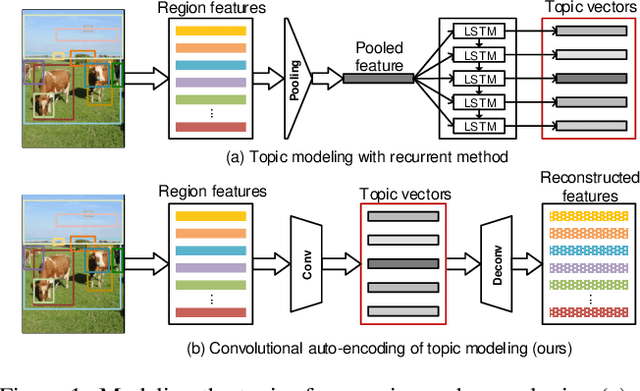

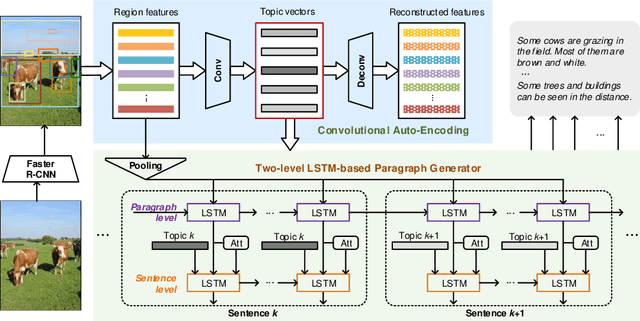
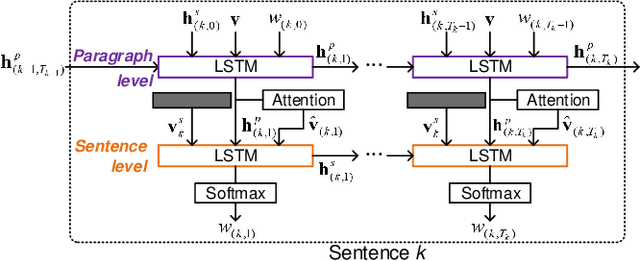
Image paragraph generation is the task of producing a coherent story (usually a paragraph) that describes the visual content of an image. The problem nevertheless is not trivial especially when there are multiple descriptive and diverse gists to be considered for paragraph generation, which often happens in real images. A valid question is how to encapsulate such gists/topics that are worthy of mention from an image, and then describe the image from one topic to another but holistically with a coherent structure. In this paper, we present a new design --- Convolutional Auto-Encoding (CAE) that purely employs convolutional and deconvolutional auto-encoding framework for topic modeling on the region-level features of an image. Furthermore, we propose an architecture, namely CAE plus Long Short-Term Memory (dubbed as CAE-LSTM), that novelly integrates the learnt topics in support of paragraph generation. Technically, CAE-LSTM capitalizes on a two-level LSTM-based paragraph generation framework with attention mechanism. The paragraph-level LSTM captures the inter-sentence dependency in a paragraph, while sentence-level LSTM is to generate one sentence which is conditioned on each learnt topic. Extensive experiments are conducted on Stanford image paragraph dataset, and superior results are reported when comparing to state-of-the-art approaches. More remarkably, CAE-LSTM increases CIDEr performance from 20.93% to 25.15%.
Regularizing Proxies with Multi-Adversarial Training for Unsupervised Domain-Adaptive Semantic Segmentation
Jul 29, 2019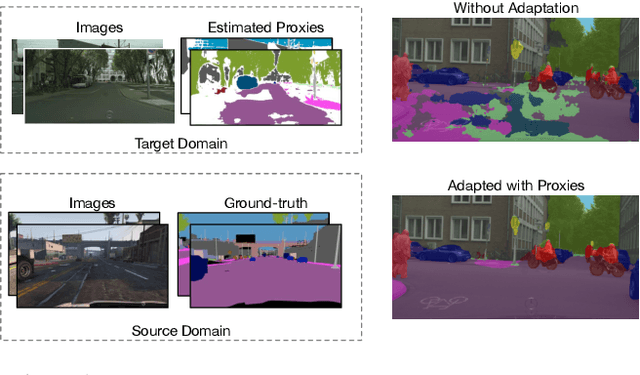
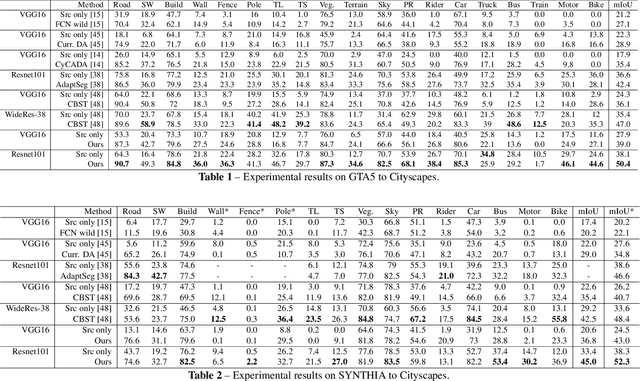
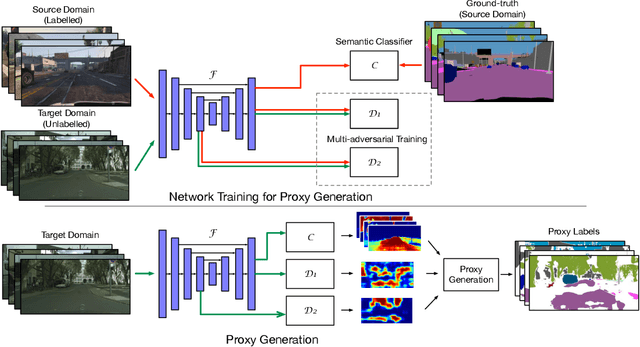
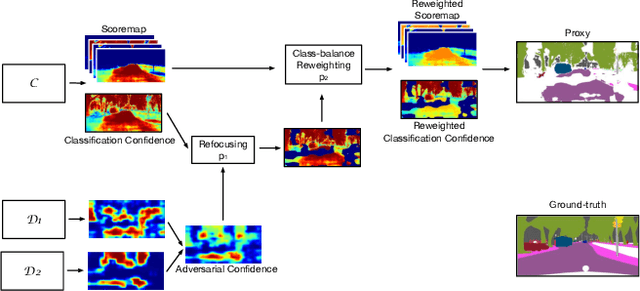
Training a semantic segmentation model requires a large amount of pixel-level annotation, hampering its application at scale. With computer graphics, we can generate almost unlimited training data with precise annotation. However,a deep model trained with synthetic data usually cannot directly generalize well to realistic images due to domain shift. It has been observed that highly confident labels for the unlabeled real images may be predicted relying on the labeled synthetic data. To tackle the unsupervised domain adaptation problem, we explore the possibilities to generate high-quality labels as proxy labels to supervise the training on target data. Specifically, we propose a novel proxy-based method using multi-adversarial training. We first train the model using synthetic data (source domain). Multiple discriminators are used to align the features be-tween the source and target domain (real images) at different levels. Then we focus on obtaining and selecting high-quality proxy labels by incorporating both the confidence of the class predictor and that from the adversarial discriminators. Our discriminators not only work as a regularizer to encourage feature alignment but also provide an alternative confidence measure for generating proxy labels. Relying on the generated high-quality proxies, our model can be trained in a "supervised manner" on the target do-main. On two major tasks, GTA5->Cityscapes and SYNTHIA->Cityscapes, our method achieves state-of-the-art results, outperforming the previous by a large margin.
Hard-Aware Fashion Attribute Classification
Jul 25, 2019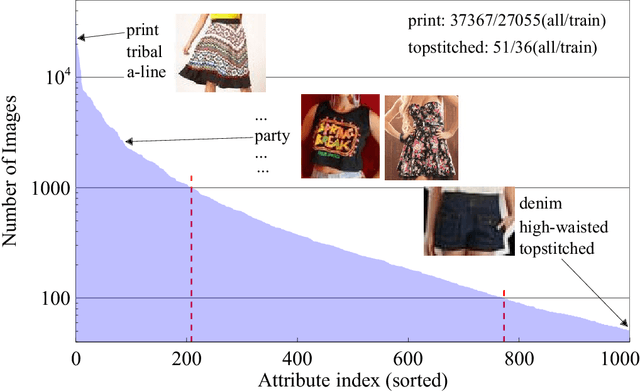
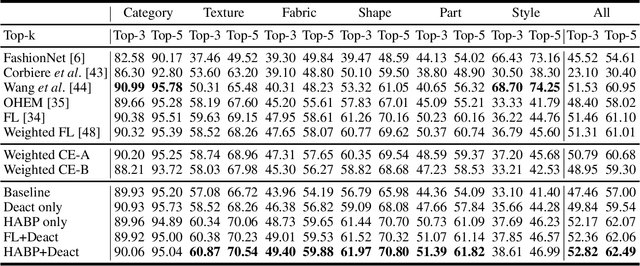
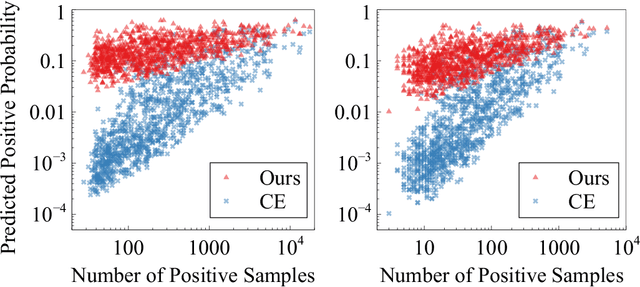
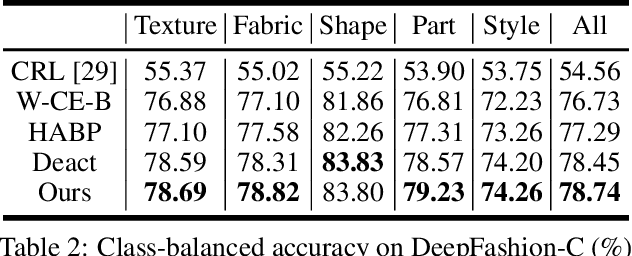
Fashion attribute classification is of great importance to many high-level tasks such as fashion item search, fashion trend analysis, fashion recommendation, etc. The task is challenging due to the extremely imbalanced data distribution, particularly the attributes with only a few positive samples. In this paper, we introduce a hard-aware pipeline to make full use of "hard" samples/attributes. We first propose Hard-Aware BackPropagation (HABP) to efficiently and adaptively focus on training "hard" data. Then for the identified hard labels, we propose to synthesize more complementary samples for training. To stabilize training, we extend semi-supervised GAN by directly deactivating outputs for synthetic complementary samples (Deact). In general, our method is more effective in addressing "hard" cases. HABP weights more on "hard" samples. For "hard" attributes with insufficient training data, Deact brings more stable synthetic samples for training and further improve the performance. Our method is verified on large scale fashion dataset, outperforming other state-of-the-art without any additional supervisions.
Learning Spatio-Temporal Representation with Local and Global Diffusion
Jun 13, 2019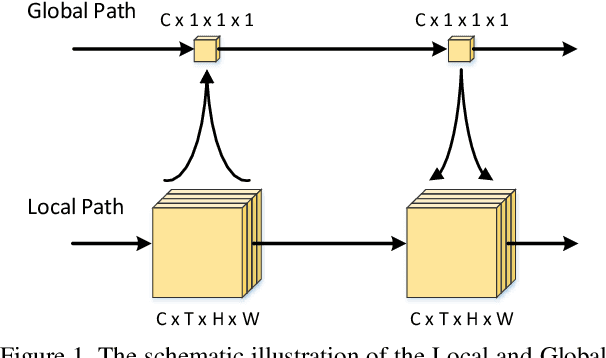
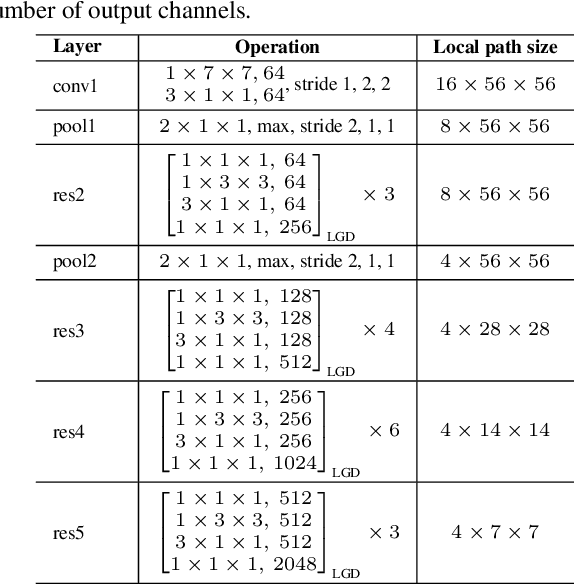
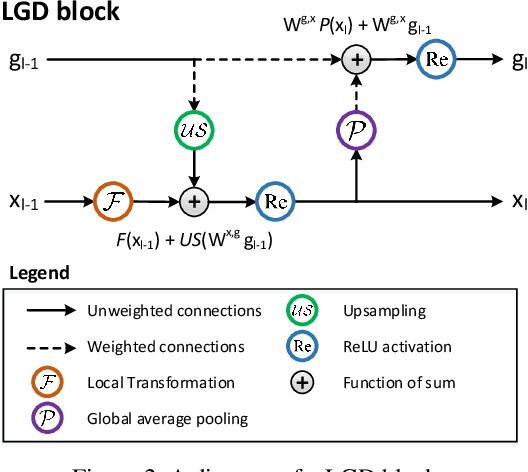
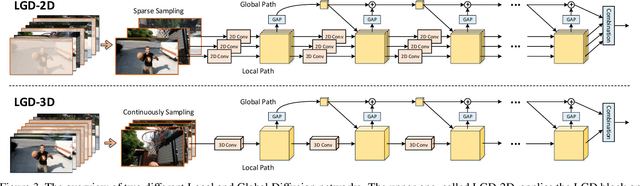
Convolutional Neural Networks (CNN) have been regarded as a powerful class of models for visual recognition problems. Nevertheless, the convolutional filters in these networks are local operations while ignoring the large-range dependency. Such drawback becomes even worse particularly for video recognition, since video is an information-intensive media with complex temporal variations. In this paper, we present a novel framework to boost the spatio-temporal representation learning by Local and Global Diffusion (LGD). Specifically, we construct a novel neural network architecture that learns the local and global representations in parallel. The architecture is composed of LGD blocks, where each block updates local and global features by modeling the diffusions between these two representations. Diffusions effectively interact two aspects of information, i.e., localized and holistic, for more powerful way of representation learning. Furthermore, a kernelized classifier is introduced to combine the representations from two aspects for video recognition. Our LGD networks achieve clear improvements on the large-scale Kinetics-400 and Kinetics-600 video classification datasets against the best competitors by 3.5% and 0.7%. We further examine the generalization of both the global and local representations produced by our pre-trained LGD networks on four different benchmarks for video action recognition and spatio-temporal action detection tasks. Superior performances over several state-of-the-art techniques on these benchmarks are reported. Code is available at: https://github.com/ZhaofanQiu/local-and-global-diffusion-networks.
Group Re-Identification with Multi-grained Matching and Integration
May 26, 2019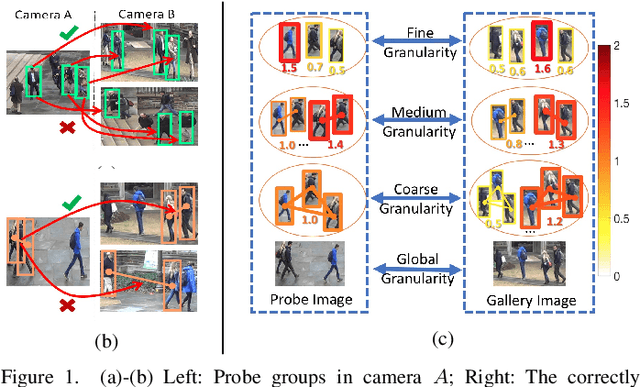
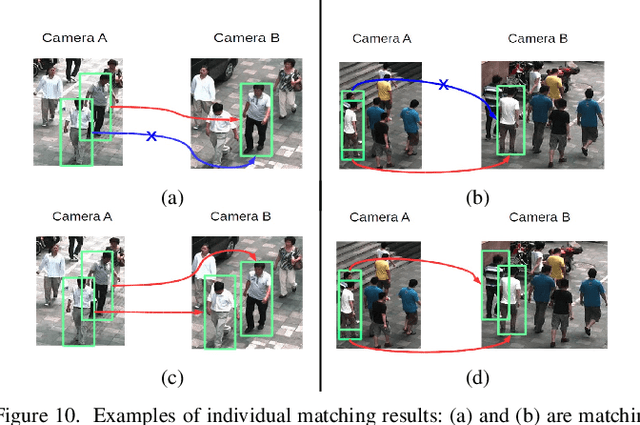
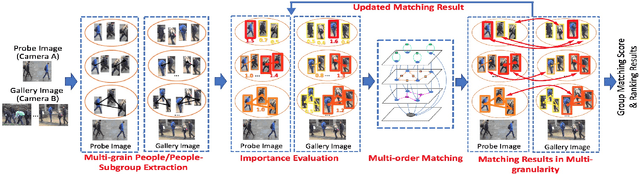
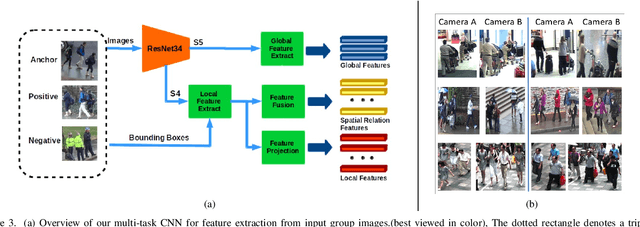
The task of re-identifying groups of people underdifferent camera views is an important yet less-studied problem.Group re-identification (Re-ID) is a very challenging task sinceit is not only adversely affected by common issues in traditionalsingle object Re-ID problems such as viewpoint and human posevariations, but it also suffers from changes in group layout andgroup membership. In this paper, we propose a novel conceptof group granularity by characterizing a group image by multi-grained objects: individual persons and sub-groups of two andthree people within a group. To achieve robust group Re-ID,we first introduce multi-grained representations which can beextracted via the development of two separate schemes, i.e. onewith hand-crafted descriptors and another with deep neuralnetworks. The proposed representation seeks to characterize bothappearance and spatial relations of multi-grained objects, and isfurther equipped with importance weights which capture varia-tions in intra-group dynamics. Optimal group-wise matching isfacilitated by a multi-order matching process which in turn,dynamically updates the importance weights in iterative fashion.We evaluated on three multi-camera group datasets containingcomplex scenarios and large dynamics, with experimental resultsdemonstrating the effectiveness of our approach. The published dataset can be found in \url{http://min.sjtu.edu.cn/lwydemo/GroupReID.html}
Predictive Ensemble Learning with Application to Scene Text Detection
May 16, 2019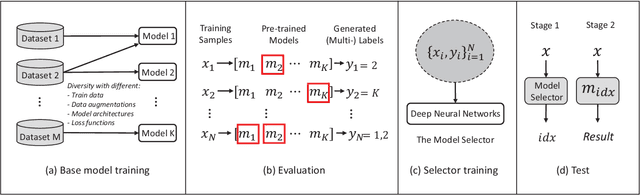

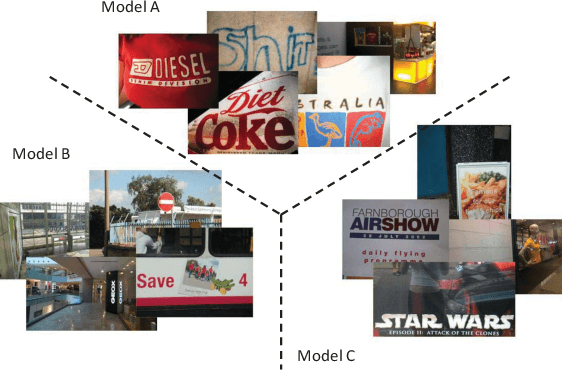
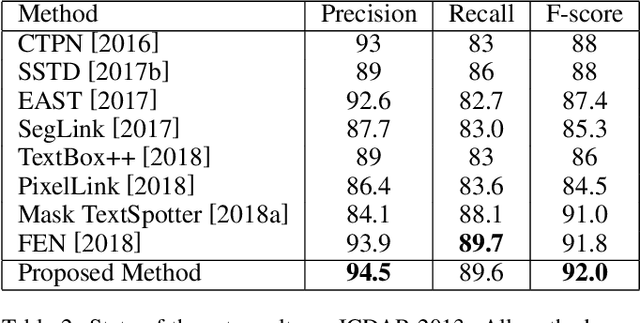
Deep learning based approaches have achieved significant progresses in different tasks like classification, detection, segmentation, and so on. Ensemble learning is widely known to further improve performance by combining multiple complementary models. It is easy to apply ensemble learning for classification tasks, for example, based on averaging, voting, or other methods. However, for other tasks (like object detection) where the outputs are varying in quantity and unable to be simply compared, the ensemble of multiple models become difficult. In this paper, we propose a new method called Predictive Ensemble Learning (PEL), based on powerful predictive ability of deep neural networks, to directly predict the best performing model among a pool of base models for each test example, thus transforming ensemble learning to a traditional classification task. Taking scene text detection as the application, where no suitable ensemble learning strategy exists, PEL can significantly improve the performance, compared to either individual state-of-the-art models, or the fusion of multiple models by non-maximum suppression. Experimental results show the possibility and potential of PEL in predicting different models' performance based only on a query example, which can be extended for ensemble learning in many other complex tasks.
A High-Efficiency Framework for Constructing Large-Scale Face Parsing Benchmark
May 13, 2019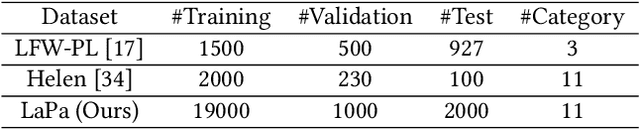


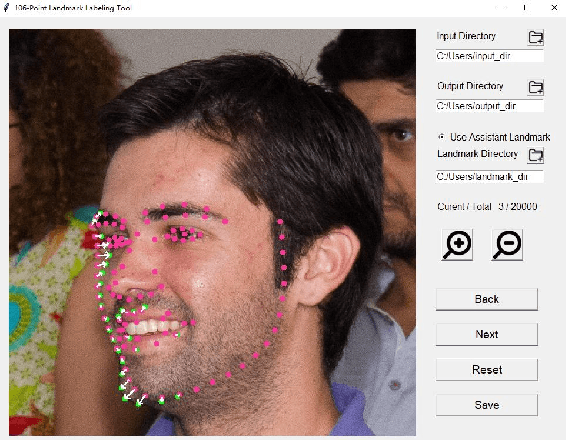
Face parsing, which is to assign a semantic label to each pixel in face images, has recently attracted increasing interest due to its huge application potentials. Although many face related fields (e.g., face recognition and face detection) have been well studied for many years, the existing datasets for face parsing are still severely limited in terms of the scale and quality, e.g., the widely used Helen dataset only contains 2,330 images. This is mainly because pixel-level annotation is a high cost and time-consuming work, especially for the facial parts without clear boundaries. The lack of accurate annotated datasets becomes a major obstacle in the progress of face parsing task. It is a feasible way to utilize dense facial landmarks to guide the parsing annotation. However, annotating dense landmarks on human face encounters the same issues as the parsing annotation. To overcome the above problems, in this paper, we develop a high-efficiency framework for face parsing annotation, which considerably simplifies and speeds up the parsing annotation by two consecutive modules. Benefit from the proposed framework, we construct a new Dense Landmark Guided Face Parsing (LaPa) benchmark. It consists of 22,000 face images with large variations in expression, pose, occlusion, etc. Each image is provided with accurate annotation of a 11-category pixel-level label map along with coordinates of 106-point landmarks. To the best of our knowledge, it is currently the largest public dataset for face parsing. To make full use of our LaPa dataset with abundant face shape and boundary priors, we propose a simple yet effective Boundary-Sensitive Parsing Network (BSPNet). Our network is taken as a baseline model on the proposed LaPa dataset, and meanwhile, it achieves the state-of-the-art performance on the Helen dataset without resorting to extra face alignment.
Temporal Deformable Convolutional Encoder-Decoder Networks for Video Captioning
May 03, 2019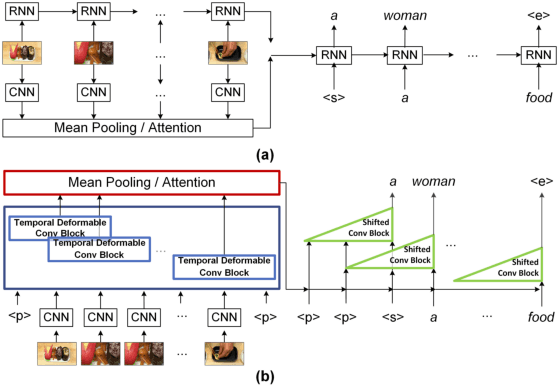
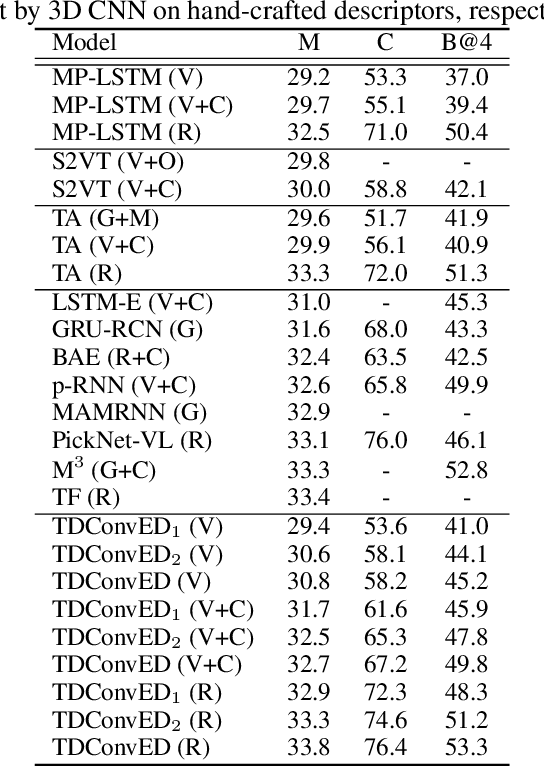
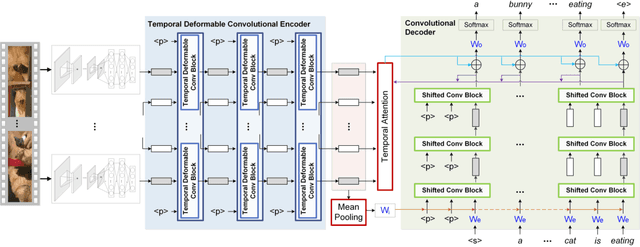
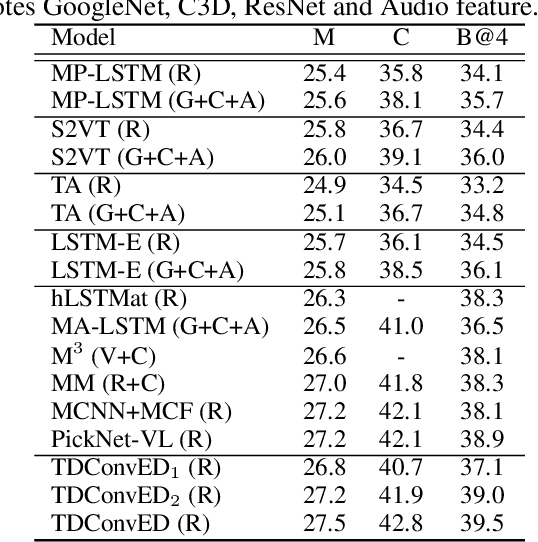
It is well believed that video captioning is a fundamental but challenging task in both computer vision and artificial intelligence fields. The prevalent approach is to map an input video to a variable-length output sentence in a sequence to sequence manner via Recurrent Neural Network (RNN). Nevertheless, the training of RNN still suffers to some degree from vanishing/exploding gradient problem, making the optimization difficult. Moreover, the inherently recurrent dependency in RNN prevents parallelization within a sequence during training and therefore limits the computations. In this paper, we present a novel design --- Temporal Deformable Convolutional Encoder-Decoder Networks (dubbed as TDConvED) that fully employ convolutions in both encoder and decoder networks for video captioning. Technically, we exploit convolutional block structures that compute intermediate states of a fixed number of inputs and stack several blocks to capture long-term relationships. The structure in encoder is further equipped with temporal deformable convolution to enable free-form deformation of temporal sampling. Our model also capitalizes on temporal attention mechanism for sentence generation. Extensive experiments are conducted on both MSVD and MSR-VTT video captioning datasets, and superior results are reported when comparing to conventional RNN-based encoder-decoder techniques. More remarkably, TDConvED increases CIDEr-D performance from 58.8% to 67.2% on MSVD.
Pointing Novel Objects in Image Captioning
Apr 25, 2019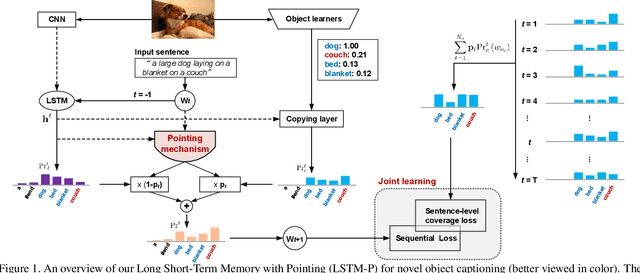
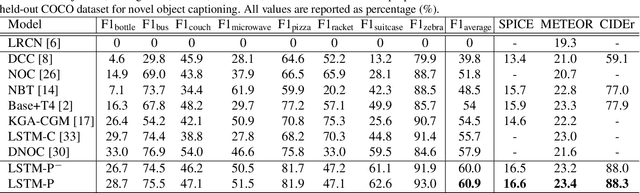

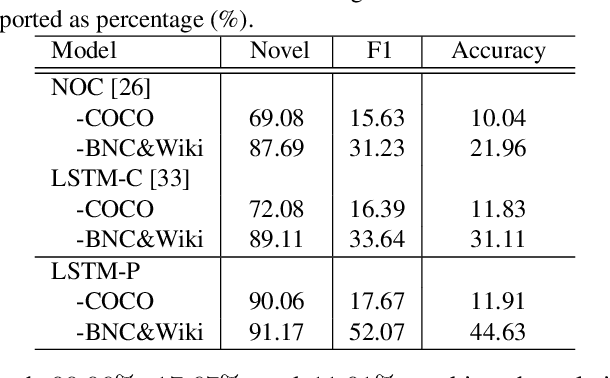
Image captioning has received significant attention with remarkable improvements in recent advances. Nevertheless, images in the wild encapsulate rich knowledge and cannot be sufficiently described with models built on image-caption pairs containing only in-domain objects. In this paper, we propose to address the problem by augmenting standard deep captioning architectures with object learners. Specifically, we present Long Short-Term Memory with Pointing (LSTM-P) --- a new architecture that facilitates vocabulary expansion and produces novel objects via pointing mechanism. Technically, object learners are initially pre-trained on available object recognition data. Pointing in LSTM-P then balances the probability between generating a word through LSTM and copying a word from the recognized objects at each time step in decoder stage. Furthermore, our captioning encourages global coverage of objects in the sentence. Extensive experiments are conducted on both held-out COCO image captioning and ImageNet datasets for describing novel objects, and superior results are reported when comparing to state-of-the-art approaches. More remarkably, we obtain an average of 60.9% in F1 score on held-out COCO~dataset.