 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeByteLoom: Weaving Geometry-Consistent Human-Object Interactions through Progressive Curriculum Learning
Dec 28, 2025Human-object interaction (HOI) video generation has garnered increasing attention due to its promising applications in digital humans, e-commerce, advertising, and robotics imitation learning. However, existing methods face two critical limitations: (1) a lack of effective mechanisms to inject multi-view information of the object into the model, leading to poor cross-view consistency, and (2) heavy reliance on fine-grained hand mesh annotations for modeling interaction occlusions. To address these challenges, we introduce ByteLoom, a Diffusion Transformer (DiT)-based framework that generates realistic HOI videos with geometrically consistent object illustration, using simplified human conditioning and 3D object inputs. We first propose an RCM-cache mechanism that leverages Relative Coordinate Maps (RCM) as a universal representation to maintain object's geometry consistency and precisely control 6-DoF object transformations in the meantime. To compensate HOI dataset scarcity and leverage existing datasets, we further design a training curriculum that enhances model capabilities in a progressive style and relaxes the demand of hand mesh. Extensive experiments demonstrate that our method faithfully preserves human identity and the object's multi-view geometry, while maintaining smooth motion and object manipulation.
CETCAM: Camera-Controllable Video Generation via Consistent and Extensible Tokenization
Dec 22, 2025



Achieving precise camera control in video generation remains challenging, as existing methods often rely on camera pose annotations that are difficult to scale to large and dynamic datasets and are frequently inconsistent with depth estimation, leading to train-test discrepancies. We introduce CETCAM, a camera-controllable video generation framework that eliminates the need for camera annotations through a consistent and extensible tokenization scheme. CETCAM leverages recent advances in geometry foundation models, such as VGGT, to estimate depth and camera parameters and converts them into unified, geometry-aware tokens. These tokens are seamlessly integrated into a pretrained video diffusion backbone via lightweight context blocks. Trained in two progressive stages, CETCAM first learns robust camera controllability from diverse raw video data and then refines fine-grained visual quality using curated high-fidelity datasets. Extensive experiments across multiple benchmarks demonstrate state-of-the-art geometric consistency, temporal stability, and visual realism. Moreover, CETCAM exhibits strong adaptability to additional control modalities, including inpainting and layout control, highlighting its flexibility beyond camera control. The project page is available at https://sjtuytc.github.io/CETCam_project_page.github.io/.
DreamSwapV: Mask-guided Subject Swapping for Any Customized Video Editing
Aug 20, 2025With the rapid progress of video generation, demand for customized video editing is surging, where subject swapping constitutes a key component yet remains under-explored. Prevailing swapping approaches either specialize in narrow domains--such as human-body animation or hand-object interaction--or rely on some indirect editing paradigm or ambiguous text prompts that compromise final fidelity. In this paper, we propose DreamSwapV, a mask-guided, subject-agnostic, end-to-end framework that swaps any subject in any video for customization with a user-specified mask and reference image. To inject fine-grained guidance, we introduce multiple conditions and a dedicated condition fusion module that integrates them efficiently. In addition, an adaptive mask strategy is designed to accommodate subjects of varying scales and attributes, further improving interactions between the swapped subject and its surrounding context. Through our elaborate two-phase dataset construction and training scheme, our DreamSwapV outperforms existing methods, as validated by comprehensive experiments on VBench indicators and our first introduced DreamSwapV-Benchmark.
Dynamic Anticipation and Completion for Multi-Hop Reasoning over Sparse Knowledge Graph
Oct 05, 2020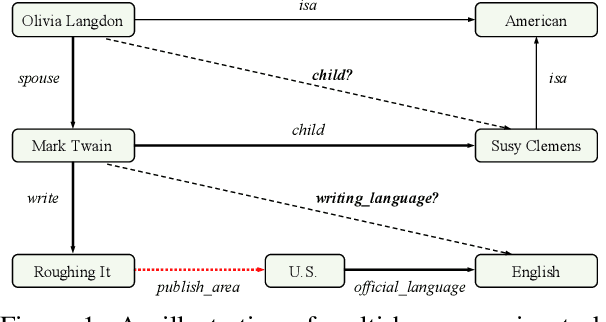
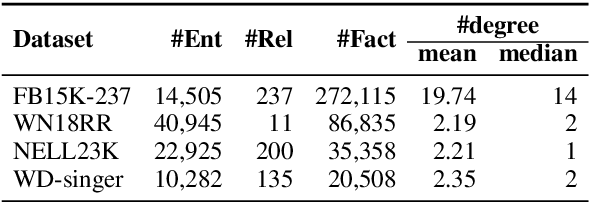
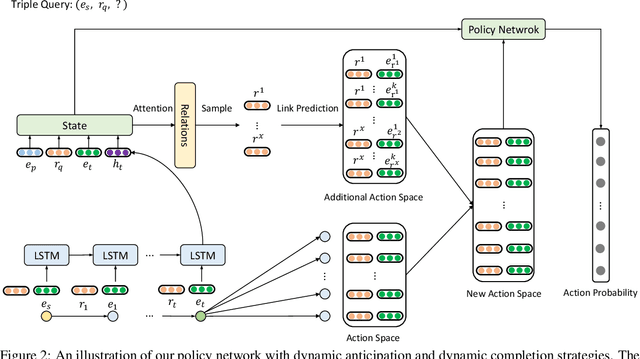
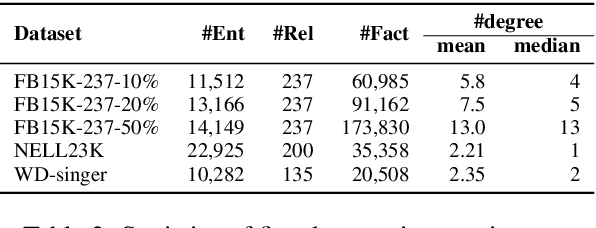
Multi-hop reasoning has been widely studied in recent years to seek an effective and interpretable method for knowledge graph (KG) completion. Most previous reasoning methods are designed for dense KGs with enough paths between entities, but cannot work well on those sparse KGs that only contain sparse paths for reasoning. On the one hand, sparse KGs contain less information, which makes it difficult for the model to choose correct paths. On the other hand, the lack of evidential paths to target entities also makes the reasoning process difficult. To solve these problems, we propose a multi-hop reasoning model named DacKGR over sparse KGs, by applying novel dynamic anticipation and completion strategies: (1) The anticipation strategy utilizes the latent prediction of embedding-based models to make our model perform more potential path search over sparse KGs. (2) Based on the anticipation information, the completion strategy dynamically adds edges as additional actions during the path search, which further alleviates the sparseness problem of KGs. The experimental results on five datasets sampled from Freebase, NELL and Wikidata show that our method outperforms state-of-the-art baselines. Our codes and datasets can be obtained from https://github.com/THU-KEG/DacKGR