 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSegviGen: Repurposing 3D Generative Model for Part Segmentation
Mar 17, 2026We introduce SegviGen, a framework that repurposes native 3D generative models for 3D part segmentation. Existing pipelines either lift strong 2D priors into 3D via distillation or multi-view mask aggregation, often suffering from cross-view inconsistency and blurred boundaries, or explore native 3D discriminative segmentation, which typically requires large-scale annotated 3D data and substantial training resources. In contrast, SegviGen leverages the structured priors encoded in pretrained 3D generative model to induce segmentation through distinctive part colorization, establishing a novel and efficient framework for part segmentation. Specifically, SegviGen encodes a 3D asset and predicts part-indicative colors on active voxels of a geometry-aligned reconstruction. It supports interactive part segmentation, full segmentation, and full segmentation with 2D guidance in a unified framework. Extensive experiments show that SegviGen improves over the prior state of the art by 40% on interactive part segmentation and by 15% on full segmentation, while using only 0.32% of the labeled training data. It demonstrates that pretrained 3D generative priors transfer effectively to 3D part segmentation, enabling strong performance with limited supervision. See our project page at https://fenghora.github.io/SegviGen-Page/.
Incremental Maintenance of DatalogMTL Materialisations
Nov 19, 2025DatalogMTL extends the classical Datalog language with metric temporal logic (MTL), enabling expressive reasoning over temporal data. While existing reasoning approaches, such as materialisation based and automata based methods, offer soundness and completeness, they lack support for handling efficient dynamic updates, a crucial requirement for real-world applications that involve frequent data updates. In this work, we propose DRedMTL, an incremental reasoning algorithm for DatalogMTL with bounded intervals. Our algorithm builds upon the classical DRed algorithm, which incrementally updates the materialisation of a Datalog program. Unlike a Datalog materialisation which is in essence a finite set of facts, a DatalogMTL materialisation has to be represented as a finite set of facts plus periodic intervals indicating how the full materialisation can be constructed through unfolding. To cope with this, our algorithm is equipped with specifically designed operators to efficiently handle such periodic representations of DatalogMTL materialisations. We have implemented this approach and tested it on several publicly available datasets. Experimental results show that DRedMTL often significantly outperforms rematerialisation, sometimes by orders of magnitude.
Goal-Driven Reasoning in DatalogMTL with Magic Sets
Dec 10, 2024

DatalogMTL is a powerful rule-based language for temporal reasoning. Due to its high expressive power and flexible modeling capabilities, it is suitable for a wide range of applications, including tasks from industrial and financial sectors. However, due its high computational complexity, practical reasoning in DatalogMTL is highly challenging. To address this difficulty, we introduce a new reasoning method for DatalogMTL which exploits the magic sets technique -- a rewriting approach developed for (non-temporal) Datalog to simulate top-down evaluation with bottom-up reasoning. We implement this approach and evaluate it on several publicly available benchmarks, showing that the proposed approach significantly and consistently outperforms performance of the state-of-the-art reasoning techniques.
PalmBench: A Comprehensive Benchmark of Compressed Large Language Models on Mobile Platforms
Oct 05, 2024



Deploying large language models (LLMs) locally on mobile devices is advantageous in scenarios where transmitting data to remote cloud servers is either undesirable due to privacy concerns or impractical due to network connection. Recent advancements (MLC, 2023a; Gerganov, 2023) have facilitated the local deployment of LLMs. However, local deployment also presents challenges, particularly in balancing quality (generative performance), latency, and throughput within the hardware constraints of mobile devices. In this paper, we introduce our lightweight, all-in-one automated benchmarking framework that allows users to evaluate LLMs on mobile devices. We provide a comprehensive benchmark of various popular LLMs with different quantization configurations (both weights and activations) across multiple mobile platforms with varying hardware capabilities. Unlike traditional benchmarks that assess full-scale models on high-end GPU clusters, we focus on evaluating resource efficiency (memory and power consumption) and harmful output for compressed models on mobile devices. Our key observations include i) differences in energy efficiency and throughput across mobile platforms; ii) the impact of quantization on memory usage, GPU execution time, and power consumption; and iii) accuracy and performance degradation of quantized models compared to their non-quantized counterparts; and iv) the frequency of hallucinations and toxic content generated by compressed LLMs on mobile devices.
SigmaRL: A Sample-Efficient and Generalizable Multi-Agent Reinforcement Learning Framework for Motion Planning
Aug 14, 2024



This paper introduces an open-source, decentralized framework named SigmaRL, designed to enhance both sample efficiency and generalization of multi-agent Reinforcement Learning (RL) for motion planning of connected and automated vehicles. Most RL agents exhibit a limited capacity to generalize, often focusing narrowly on specific scenarios, and are usually evaluated in similar or even the same scenarios seen during training. Various methods have been proposed to address these challenges, including experience replay and regularization. However, how observation design in RL affects sample efficiency and generalization remains an under-explored area. We address this gap by proposing five strategies to design information-dense observations, focusing on general features that are applicable to most traffic scenarios. We train our RL agents using these strategies on an intersection and evaluate their generalization through numerical experiments across completely unseen traffic scenarios, including a new intersection, an on-ramp, and a roundabout. Incorporating these information-dense observations reduces training times to under one hour on a single CPU, and the evaluation results reveal that our RL agents can effectively zero-shot generalize. Code: github.com/cas-lab-munich/SigmaRL
Optimised Storage for Datalog Reasoning
Dec 19, 2023



Materialisation facilitates Datalog reasoning by precomputing all consequences of the facts and the rules so that queries can be directly answered over the materialised facts. However, storing all materialised facts may be infeasible in practice, especially when the rules are complex and the given set of facts is large. We observe that for certain combinations of rules, there exist data structures that compactly represent the reasoning result and can be efficiently queried when necessary. In this paper, we present a general framework that allows for the integration of such optimised storage schemes with standard materialisation algorithms. Moreover, we devise optimised storage schemes targeting at transitive rules and union rules, two types of (combination of) rules that commonly occur in practice. Our experimental evaluation shows that our approach significantly improves memory consumption, sometimes by orders of magnitude, while remaining competitive in terms of query answering time.
Enhancing Datalog Reasoning with Hypertree Decompositions
May 15, 2023



Datalog reasoning based on the semina\"ive evaluation strategy evaluates rules using traditional join plans, which often leads to redundancy and inefficiency in practice, especially when the rules are complex. Hypertree decompositions help identify efficient query plans and reduce similar redundancy in query answering. However, it is unclear how this can be applied to materialisation and incremental reasoning with recursive Datalog programs. Moreover, hypertree decompositions require additional data structures and thus introduce nonnegligible overhead in both runtime and memory consumption. In this paper, we provide algorithms that exploit hypertree decompositions for the materialisation and incremental evaluation of Datalog programs. Furthermore, we combine this approach with standard Datalog reasoning algorithms in a modular fashion so that the overhead caused by the decompositions is reduced. Our empirical evaluation shows that, when the program contains complex rules, the combined approach is usually significantly faster than the baseline approach, sometimes by orders of magnitude.
MeTeoR: Practical Reasoning in Datalog with Metric Temporal Operators
Jan 12, 2022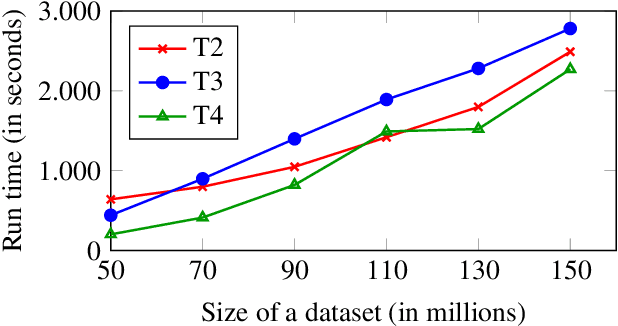

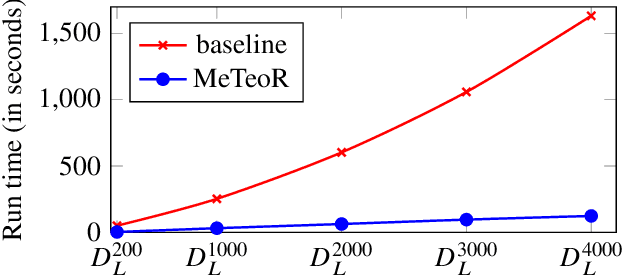
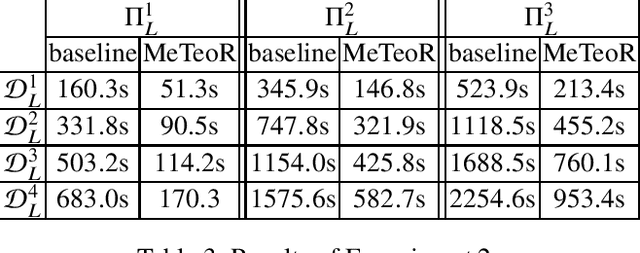
DatalogMTL is an extension of Datalog with operators from metric temporal logic which has received significant attention in recent years. It is a highly expressive knowledge representation language that is well-suited for applications in temporal ontology-based query answering and stream processing. Reasoning in DatalogMTL is, however, of high computational complexity, making implementation challenging and hindering its adoption in applications. In this paper, we present a novel approach for practical reasoning in DatalogMTL which combines materialisation (a.k.a. forward chaining) with automata-based techniques. We have implemented this approach in a reasoner called MeTeoR and evaluated its performance using a temporal extension of the Lehigh University Benchmark and a benchmark based on real-world meteorological data. Our experiments show that MeTeoR is a scalable system which enables reasoning over complex temporal rules and datasets involving tens of millions of temporal facts.
OWL2Vec*: Embedding of OWL Ontologies
Sep 30, 2020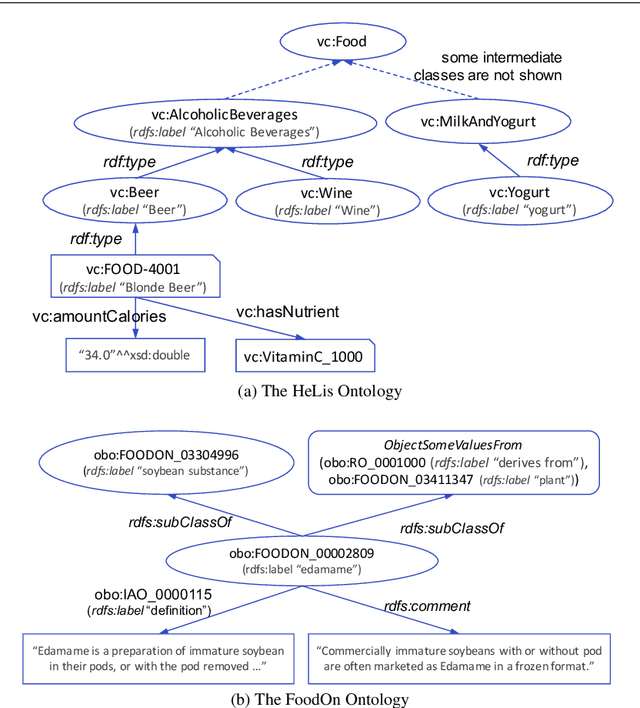

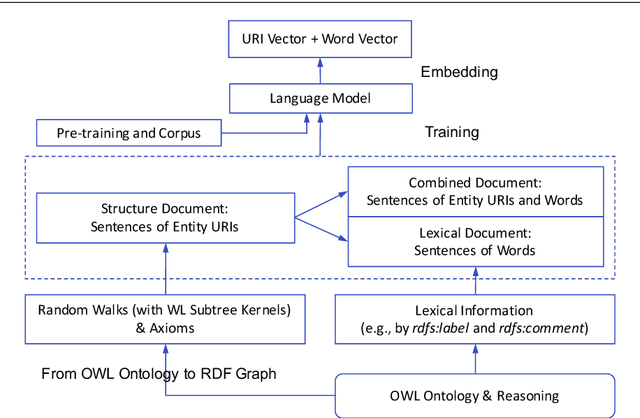

Semantic embedding of knowledge graphs has been widely studied and used for prediction and statistical analysis tasks across various domains such as Natural Language Processing and the Semantic Web. However, less attention has been paid to developing robust methods for embedding OWL (Web Ontology Language) ontologies. In this paper, we propose a language model based ontology embedding method named OWL2Vec*, which encodes the semantics of an ontology by taking into account its graph structure, lexical information and logic constructors. Our empirical evaluation with three real world datasets suggests that OWL2Vec* benefits from these three different aspects of an ontology in class membership prediction and class subsumption prediction tasks. Furthermore, OWL2Vec* often significantly outperforms the state-of-the-art methods in our experiments.
Interpretable Machine Learning Model for Early Prediction of Mortality in Elderly Patients with Multiple Organ Dysfunction Syndrome (MODS): a Multicenter Retrospective Study and Cross Validation
Jan 28, 2020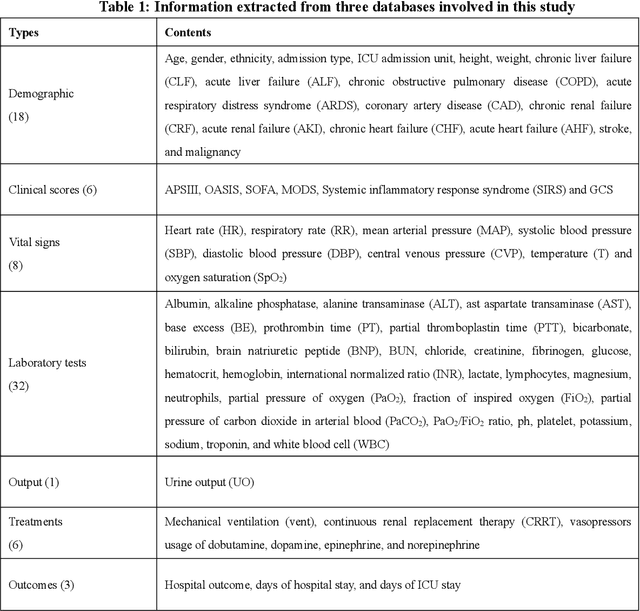
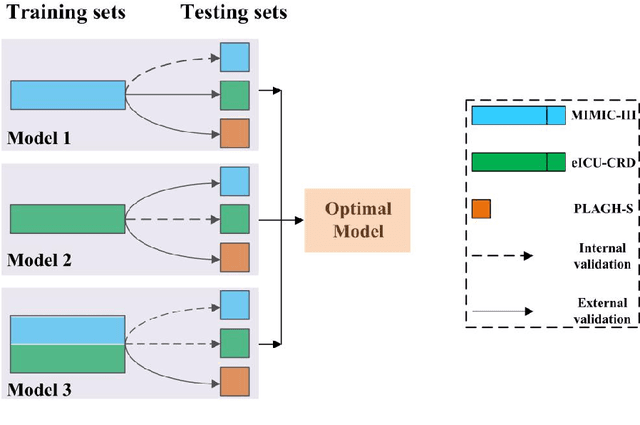
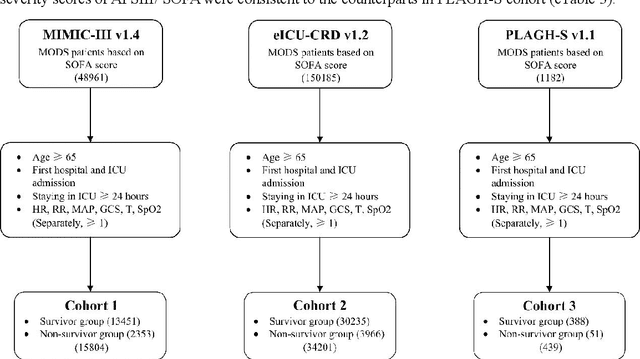
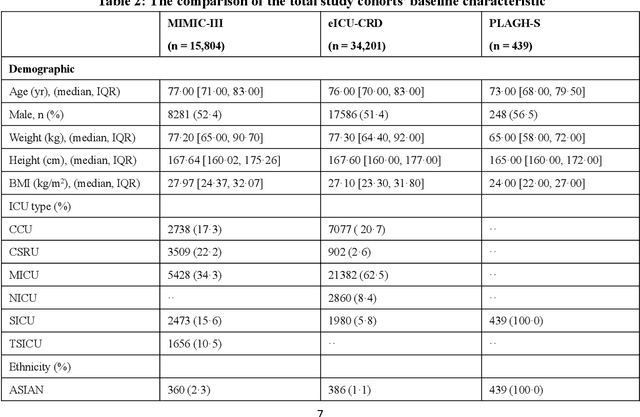
Background: Elderly patients with MODS have high risk of death and poor prognosis. The performance of current scoring systems assessing the severity of MODS and its mortality remains unsatisfactory. This study aims to develop an interpretable and generalizable model for early mortality prediction in elderly patients with MODS. Methods: The MIMIC-III, eICU-CRD and PLAGH-S databases were employed for model generation and evaluation. We used the eXtreme Gradient Boosting model with the SHapley Additive exPlanations method to conduct early and interpretable predictions of patients' hospital outcome. Three types of data source combinations and five typical evaluation indexes were adopted to develop a generalizable model. Findings: The interpretable model, with optimal performance developed by using MIMIC-III and eICU-CRD datasets, was separately validated in MIMIC-III, eICU-CRD and PLAGH-S datasets (no overlapping with training set). The performances of the model in predicting hospital mortality as validated by the three datasets were: AUC of 0.858, sensitivity of 0.834 and specificity of 0.705; AUC of 0.849, sensitivity of 0.763 and specificity of 0.784; and AUC of 0.838, sensitivity of 0.882 and specificity of 0.691, respectively. Comparisons of AUC between this model and baseline models with MIMIC-III dataset validation showed superior performances of this model; In addition, comparisons in AUC between this model and commonly used clinical scores showed significantly better performance of this model. Interpretation: The interpretable machine learning model developed in this study using fused datasets with large sample sizes was robust and generalizable. This model outperformed the baseline models and several clinical scores for early prediction of mortality in elderly ICU patients. The interpretative nature of this model provided clinicians with the ranking of mortality risk features.