 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePaperBanana: Automating Academic Illustration for AI Scientists
Jan 30, 2026Despite rapid advances in autonomous AI scientists powered by language models, generating publication-ready illustrations remains a labor-intensive bottleneck in the research workflow. To lift this burden, we introduce PaperBanana, an agentic framework for automated generation of publication-ready academic illustrations. Powered by state-of-the-art VLMs and image generation models, PaperBanana orchestrates specialized agents to retrieve references, plan content and style, render images, and iteratively refine via self-critique. To rigorously evaluate our framework, we introduce PaperBananaBench, comprising 292 test cases for methodology diagrams curated from NeurIPS 2025 publications, covering diverse research domains and illustration styles. Comprehensive experiments demonstrate that PaperBanana consistently outperforms leading baselines in faithfulness, conciseness, readability, and aesthetics. We further show that our method effectively extends to the generation of high-quality statistical plots. Collectively, PaperBanana paves the way for the automated generation of publication-ready illustrations.
JudgeRLVR: Judge First, Generate Second for Efficient Reasoning
Jan 13, 2026Reinforcement Learning with Verifiable Rewards (RLVR) has become a standard paradigm for reasoning in Large Language Models. However, optimizing solely for final-answer correctness often drives models into aimless, verbose exploration, where they rely on exhaustive trial-and-error tactics rather than structured planning to reach solutions. While heuristic constraints like length penalties can reduce verbosity, they often truncate essential reasoning steps, creating a difficult trade-off between efficiency and verification. In this paper, we argue that discriminative capability is a prerequisite for efficient generation: by learning to distinguish valid solutions, a model can internalize a guidance signal that prunes the search space. We propose JudgeRLVR, a two-stage judge-then-generate paradigm. In the first stage, we train the model to judge solution responses with verifiable answers. In the second stage, we fine-tune the same model with vanilla generating RLVR initialized from the judge. Compared to Vanilla RLVR using the same math-domain training data, JudgeRLVR achieves a better quality--efficiency trade-off for Qwen3-30B-A3B: on in-domain math, it delivers about +3.7 points average accuracy gain with -42\% average generation length; on out-of-domain benchmarks, it delivers about +4.5 points average accuracy improvement, demonstrating enhanced generalization.
DocLens : A Tool-Augmented Multi-Agent Framework for Long Visual Document Understanding
Nov 14, 2025Comprehending long visual documents, where information is distributed across extensive pages of text and visual elements, is a critical but challenging task for modern Vision-Language Models (VLMs). Existing approaches falter on a fundamental challenge: evidence localization. They struggle to retrieve relevant pages and overlook fine-grained details within visual elements, leading to limited performance and model hallucination. To address this, we propose DocLens, a tool-augmented multi-agent framework that effectively ``zooms in'' on evidence like a lens. It first navigates from the full document to specific visual elements on relevant pages, then employs a sampling-adjudication mechanism to generate a single, reliable answer. Paired with Gemini-2.5-Pro, DocLens achieves state-of-the-art performance on MMLongBench-Doc and FinRAGBench-V, surpassing even human experts. The framework's superiority is particularly evident on vision-centric and unanswerable queries, demonstrating the power of its enhanced localization capabilities.
FinRAGBench-V: A Benchmark for Multimodal RAG with Visual Citation in the Financial Domain
May 23, 2025Retrieval-Augmented Generation (RAG) plays a vital role in the financial domain, powering applications such as real-time market analysis, trend forecasting, and interest rate computation. However, most existing RAG research in finance focuses predominantly on textual data, overlooking the rich visual content in financial documents, resulting in the loss of key analytical insights. To bridge this gap, we present FinRAGBench-V, a comprehensive visual RAG benchmark tailored for finance which effectively integrates multimodal data and provides visual citation to ensure traceability. It includes a bilingual retrieval corpus with 60,780 Chinese and 51,219 English pages, along with a high-quality, human-annotated question-answering (QA) dataset spanning heterogeneous data types and seven question categories. Moreover, we introduce RGenCite, an RAG baseline that seamlessly integrates visual citation with generation. Furthermore, we propose an automatic citation evaluation method to systematically assess the visual citation capabilities of Multimodal Large Language Models (MLLMs). Extensive experiments on RGenCite underscore the challenging nature of FinRAGBench-V, providing valuable insights for the development of multimodal RAG systems in finance.
KNN-SSD: Enabling Dynamic Self-Speculative Decoding via Nearest Neighbor Layer Set Optimization
May 22, 2025Speculative Decoding (SD) has emerged as a widely used paradigm to accelerate the inference of large language models (LLMs) without compromising generation quality. It works by efficiently drafting multiple tokens using a compact model and then verifying them in parallel using the target LLM. Notably, Self-Speculative Decoding proposes skipping certain layers to construct the draft model, which eliminates the need for additional parameters or training. Despite its strengths, we observe in this work that drafting with layer skipping exhibits significant sensitivity to domain shifts, leading to a substantial drop in acceleration performance. To enhance the domain generalizability of this paradigm, we introduce KNN-SSD, an algorithm that leverages K-Nearest Neighbor (KNN) search to match different skipped layers with various domain inputs. We evaluated our algorithm in various models and multiple tasks, observing that its application leads to 1.3x-1.6x speedup in LLM inference.
MPO: Boosting LLM Agents with Meta Plan Optimization
Mar 04, 2025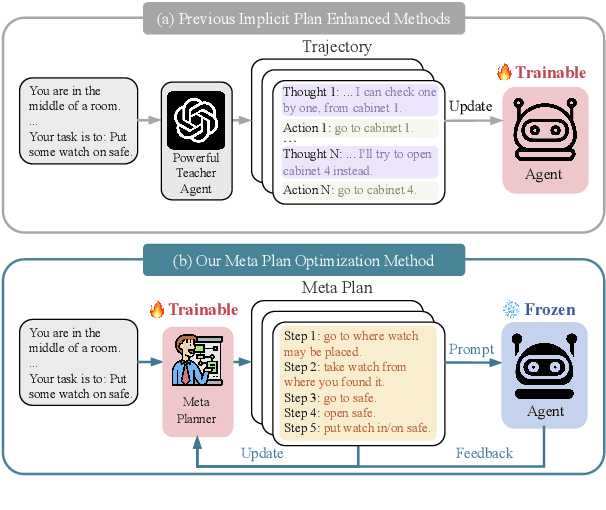

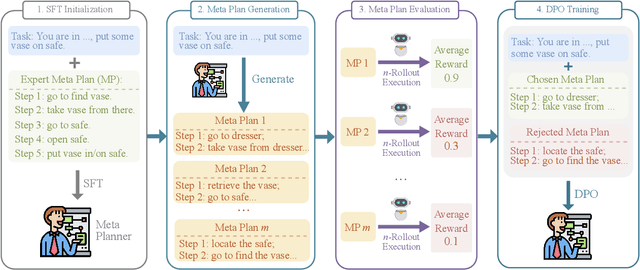
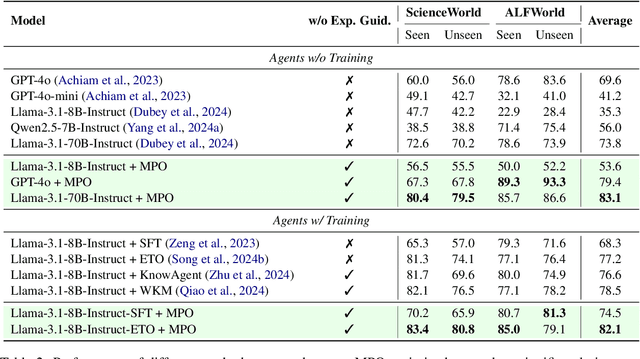
Recent advancements in large language models (LLMs) have enabled LLM-based agents to successfully tackle interactive planning tasks. However, despite their successes, existing approaches often suffer from planning hallucinations and require retraining for each new agent. To address these challenges, we propose the Meta Plan Optimization (MPO) framework, which enhances agent planning capabilities by directly incorporating explicit guidance. Unlike previous methods that rely on complex knowledge, which either require significant human effort or lack quality assurance, MPO leverages high-level general guidance through meta plans to assist agent planning and enables continuous optimization of the meta plans based on feedback from the agent's task execution. Our experiments conducted on two representative tasks demonstrate that MPO significantly outperforms existing baselines. Moreover, our analysis indicates that MPO provides a plug-and-play solution that enhances both task completion efficiency and generalization capabilities in previous unseen scenarios.
Chain-of-Thought Matters: Improving Long-Context Language Models with Reasoning Path Supervision
Feb 28, 2025



Recent advances in Large Language Models (LLMs) have highlighted the challenge of handling long-context tasks, where models need to reason over extensive input contexts to aggregate target information. While Chain-of-Thought (CoT) prompting has shown promise for multi-step reasoning, its effectiveness for long-context scenarios remains underexplored. Through systematic investigation across diverse tasks, we demonstrate that CoT's benefits generalize across most long-context scenarios and amplify with increasing context length. Motivated by this critical observation, we propose LongRePS, a process-supervised framework that teaches models to generate high-quality reasoning paths for enhanced long-context performance. Our framework incorporates a self-sampling mechanism to bootstrap reasoning paths and a novel quality assessment protocol specifically designed for long-context scenarios. Experimental results on various long-context benchmarks demonstrate the effectiveness of our approach, achieving significant improvements over outcome supervision baselines on both in-domain tasks (+13.6/+3.8 points for LLaMA/Qwen on MuSiQue) and cross-domain generalization (+9.3/+8.1 points on average across diverse QA tasks). Our code, data and trained models are made public to facilitate future research.
LongAttn: Selecting Long-context Training Data via Token-level Attention
Feb 24, 2025



With the development of large language models (LLMs), there has been an increasing need for significant advancements in handling long contexts. To enhance long-context capabilities, constructing high-quality training data with long-range dependencies is crucial. Existing methods to select long-context data often rely on sentence-level analysis, which can be greatly optimized in both performance and efficiency. In this paper, we propose a novel token-level framework, LongAttn, which leverages the self-attention mechanism of LLMs to measure the long-range dependencies for the data. By calculating token-level dependency strength and distribution uniformity of token scores, LongAttn effectively quantifies long-range dependencies, enabling more accurate and efficient data selection. We filter LongABC-32K from open-source long-context datasets (ArXiv, Book, and Code). Through our comprehensive experiments, LongAttn has demonstrated its excellent effectiveness, scalability, and efficiency. To facilitate future research in long-context data, we released our code and the high-quality long-context training data LongABC-32K.
More Tokens, Lower Precision: Towards the Optimal Token-Precision Trade-off in KV Cache Compression
Dec 17, 2024As large language models (LLMs) process increasing context windows, the memory usage of KV cache has become a critical bottleneck during inference. The mainstream KV compression methods, including KV pruning and KV quantization, primarily focus on either token or precision dimension and seldom explore the efficiency of their combination. In this paper, we comprehensively investigate the token-precision trade-off in KV cache compression. Experiments demonstrate that storing more tokens in the KV cache with lower precision, i.e., quantized pruning, can significantly enhance the long-context performance of LLMs. Furthermore, in-depth analysis regarding token-precision trade-off from a series of key aspects exhibit that, quantized pruning achieves substantial improvements in retrieval-related tasks and consistently performs well across varying input lengths. Moreover, quantized pruning demonstrates notable stability across different KV pruning methods, quantization strategies, and model scales. These findings provide valuable insights into the token-precision trade-off in KV cache compression. We plan to release our code in the near future.
VLRewardBench: A Challenging Benchmark for Vision-Language Generative Reward Models
Nov 26, 2024



Vision-language generative reward models (VL-GenRMs) play a crucial role in aligning and evaluating multimodal AI systems, yet their own evaluation remains under-explored. Current assessment methods primarily rely on AI-annotated preference labels from traditional VL tasks, which can introduce biases and often fail to effectively challenge state-of-the-art models. To address these limitations, we introduce VL-RewardBench, a comprehensive benchmark spanning general multimodal queries, visual hallucination detection, and complex reasoning tasks. Through our AI-assisted annotation pipeline combining sample selection with human verification, we curate 1,250 high-quality examples specifically designed to probe model limitations. Comprehensive evaluation across 16 leading large vision-language models, demonstrates VL-RewardBench's effectiveness as a challenging testbed, where even GPT-4o achieves only 65.4% accuracy, and state-of-the-art open-source models such as Qwen2-VL-72B, struggle to surpass random-guessing. Importantly, performance on VL-RewardBench strongly correlates (Pearson's r > 0.9) with MMMU-Pro accuracy using Best-of-N sampling with VL-GenRMs. Analysis experiments uncover three critical insights for improving VL-GenRMs: (i) models predominantly fail at basic visual perception tasks rather than reasoning tasks; (ii) inference-time scaling benefits vary dramatically by model capacity; and (iii) training VL-GenRMs to learn to judge substantially boosts judgment capability (+14.7% accuracy for a 7B VL-GenRM). We believe VL-RewardBench along with the experimental insights will become a valuable resource for advancing VL-GenRMs.