 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWavReward: Spoken Dialogue Models With Generalist Reward Evaluators
May 14, 2025End-to-end spoken dialogue models such as GPT-4o-audio have recently garnered significant attention in the speech domain. However, the evaluation of spoken dialogue models' conversational performance has largely been overlooked. This is primarily due to the intelligent chatbots convey a wealth of non-textual information which cannot be easily measured using text-based language models like ChatGPT. To address this gap, we propose WavReward, a reward feedback model based on audio language models that can evaluate both the IQ and EQ of spoken dialogue systems with speech input. Specifically, 1) based on audio language models, WavReward incorporates the deep reasoning process and the nonlinear reward mechanism for post-training. By utilizing multi-sample feedback via the reinforcement learning algorithm, we construct a specialized evaluator tailored to spoken dialogue models. 2) We introduce ChatReward-30K, a preference dataset used to train WavReward. ChatReward-30K includes both comprehension and generation aspects of spoken dialogue models. These scenarios span various tasks, such as text-based chats, nine acoustic attributes of instruction chats, and implicit chats. WavReward outperforms previous state-of-the-art evaluation models across multiple spoken dialogue scenarios, achieving a substantial improvement about Qwen2.5-Omni in objective accuracy from 55.1$\%$ to 91.5$\%$. In subjective A/B testing, WavReward also leads by a margin of 83$\%$. Comprehensive ablation studies confirm the necessity of each component of WavReward. All data and code will be publicly at https://github.com/jishengpeng/WavReward after the paper is accepted.
OmniSep: Unified Omni-Modality Sound Separation with Query-Mixup
Oct 28, 2024



The scaling up has brought tremendous success in the fields of vision and language in recent years. When it comes to audio, however, researchers encounter a major challenge in scaling up the training data, as most natural audio contains diverse interfering signals. To address this limitation, we introduce Omni-modal Sound Separation (OmniSep), a novel framework capable of isolating clean soundtracks based on omni-modal queries, encompassing both single-modal and multi-modal composed queries. Specifically, we introduce the Query-Mixup strategy, which blends query features from different modalities during training. This enables OmniSep to optimize multiple modalities concurrently, effectively bringing all modalities under a unified framework for sound separation. We further enhance this flexibility by allowing queries to influence sound separation positively or negatively, facilitating the retention or removal of specific sounds as desired. Finally, OmniSep employs a retrieval-augmented approach known as Query-Aug, which enables open-vocabulary sound separation. Experimental evaluations on MUSIC, VGGSOUND-CLEAN+, and MUSIC-CLEAN+ datasets demonstrate effectiveness of OmniSep, achieving state-of-the-art performance in text-, image-, and audio-queried sound separation tasks. For samples and further information, please visit the demo page at \url{https://omnisep.github.io/}.
OmniFlatten: An End-to-end GPT Model for Seamless Voice Conversation
Oct 23, 2024



Full-duplex spoken dialogue systems significantly advance over traditional turn-based dialogue systems, as they allow simultaneous bidirectional communication, closely mirroring human-human interactions. However, achieving low latency and natural interactions in full-duplex dialogue systems remains a significant challenge, especially considering human conversation dynamics such as interruptions, backchannels, and overlapping speech. In this paper, we introduce a novel End-to-End GPT-based model OmniFlatten for full-duplex conversation, capable of effectively modeling the complex behaviors inherent to natural conversations with low latency. To achieve full-duplex communication capabilities, we propose a multi-stage post-training scheme that progressively adapts a text-based large language model (LLM) backbone into a speech-text dialogue LLM, capable of generating text and speech in real time, without modifying the architecture of the backbone LLM. The training process comprises three stages: modality alignment, half-duplex dialogue learning, and full-duplex dialogue learning. Throughout all training stages, we standardize the data using a flattening operation, which allows us to unify the training methods and the model architecture across different modalities and tasks. Our approach offers a straightforward modeling technique and a promising research direction for developing efficient and natural end-to-end full-duplex spoken dialogue systems. Audio samples of dialogues generated by OmniFlatten can be found at this web site (https://omniflatten.github.io/).
MuVi: Video-to-Music Generation with Semantic Alignment and Rhythmic Synchronization
Oct 16, 2024



Generating music that aligns with the visual content of a video has been a challenging task, as it requires a deep understanding of visual semantics and involves generating music whose melody, rhythm, and dynamics harmonize with the visual narratives. This paper presents MuVi, a novel framework that effectively addresses these challenges to enhance the cohesion and immersive experience of audio-visual content. MuVi analyzes video content through a specially designed visual adaptor to extract contextually and temporally relevant features. These features are used to generate music that not only matches the video's mood and theme but also its rhythm and pacing. We also introduce a contrastive music-visual pre-training scheme to ensure synchronization, based on the periodicity nature of music phrases. In addition, we demonstrate that our flow-matching-based music generator has in-context learning ability, allowing us to control the style and genre of the generated music. Experimental results show that MuVi demonstrates superior performance in both audio quality and temporal synchronization. The generated music video samples are available at https://muvi-v2m.github.io.
WavTokenizer: an Efficient Acoustic Discrete Codec Tokenizer for Audio Language Modeling
Aug 29, 2024



Language models have been effectively applied to modeling natural signals, such as images, video, speech, and audio. A crucial component of these models is the codec tokenizer, which compresses high-dimensional natural signals into lower-dimensional discrete tokens. In this paper, we introduce WavTokenizer, which offers several advantages over previous SOTA acoustic codec models in the audio domain: 1)extreme compression. By compressing the layers of quantizers and the temporal dimension of the discrete codec, one-second audio of 24kHz sampling rate requires only a single quantizer with 40 or 75 tokens. 2)improved subjective quality. Despite the reduced number of tokens, WavTokenizer achieves state-of-the-art reconstruction quality with outstanding UTMOS scores and inherently contains richer semantic information. Specifically, we achieve these results by designing a broader VQ space, extended contextual windows, and improved attention networks, as well as introducing a powerful multi-scale discriminator and an inverse Fourier transform structure. We conducted extensive reconstruction experiments in the domains of speech, audio, and music. WavTokenizer exhibited strong performance across various objective and subjective metrics compared to state-of-the-art models. We also tested semantic information, VQ utilization, and adaptability to generative models. Comprehensive ablation studies confirm the necessity of each module in WavTokenizer. The related code, demos, and pre-trained models are available at https://github.com/jishengpeng/WavTokenizer.
Integrating Audio, Visual, and Semantic Information for Enhanced Multimodal Speaker Diarization
Aug 22, 2024



Speaker diarization, the process of segmenting an audio stream or transcribed speech content into homogenous partitions based on speaker identity, plays a crucial role in the interpretation and analysis of human speech. Most existing speaker diarization systems rely exclusively on unimodal acoustic information, making the task particularly challenging due to the innate ambiguities of audio signals. Recent studies have made tremendous efforts towards audio-visual or audio-semantic modeling to enhance performance. However, even the incorporation of up to two modalities often falls short in addressing the complexities of spontaneous and unstructured conversations. To exploit more meaningful dialogue patterns, we propose a novel multimodal approach that jointly utilizes audio, visual, and semantic cues to enhance speaker diarization. Our method elegantly formulates the multimodal modeling as a constrained optimization problem. First, we build insights into the visual connections among active speakers and the semantic interactions within spoken content, thereby establishing abundant pairwise constraints. Then we introduce a joint pairwise constraint propagation algorithm to cluster speakers based on these visual and semantic constraints. This integration effectively leverages the complementary strengths of different modalities, refining the affinity estimation between individual speaker embeddings. Extensive experiments conducted on multiple multimodal datasets demonstrate that our approach consistently outperforms state-of-the-art speaker diarization methods.
CosyVoice: A Scalable Multilingual Zero-shot Text-to-speech Synthesizer based on Supervised Semantic Tokens
Jul 09, 2024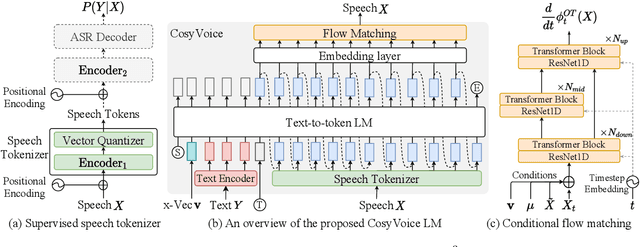

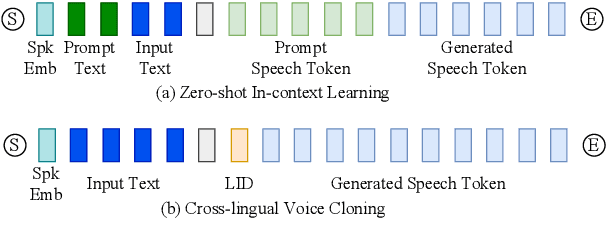
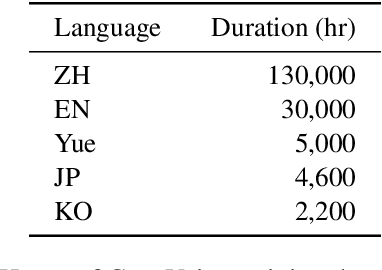
Recent years have witnessed a trend that large language model (LLM) based text-to-speech (TTS) emerges into the mainstream due to their high naturalness and zero-shot capacity. In this paradigm, speech signals are discretized into token sequences, which are modeled by an LLM with text as prompts and reconstructed by a token-based vocoder to waveforms. Obviously, speech tokens play a critical role in LLM-based TTS models. Current speech tokens are learned in an unsupervised manner, which lacks explicit semantic information and alignment to the text. In this paper, we propose to represent speech with supervised semantic tokens, which are derived from a multilingual speech recognition model by inserting vector quantization into the encoder. Based on the tokens, we further propose a scalable zero-shot TTS synthesizer, CosyVoice, which consists of an LLM for text-to-token generation and a conditional flow matching model for token-to-speech synthesis. Experimental results show that supervised semantic tokens significantly outperform existing unsupervised tokens in terms of content consistency and speaker similarity for zero-shot voice cloning. Moreover, we find that utilizing large-scale data further improves the synthesis performance, indicating the scalable capacity of CosyVoice. To the best of our knowledge, this is the first attempt to involve supervised speech tokens into TTS models.
Accompanied Singing Voice Synthesis with Fully Text-controlled Melody
Jul 02, 2024



Text-to-song (TTSong) is a music generation task that synthesizes accompanied singing voices. Current TTSong methods, inherited from singing voice synthesis (SVS), require melody-related information that can sometimes be impractical, such as music scores or MIDI sequences. We present MelodyLM, the first TTSong model that generates high-quality song pieces with fully text-controlled melodies, achieving minimal user requirements and maximum control flexibility. MelodyLM explicitly models MIDI as the intermediate melody-related feature and sequentially generates vocal tracks in a language model manner, conditioned on textual and vocal prompts. The accompaniment music is subsequently synthesized by a latent diffusion model with hybrid conditioning for temporal alignment. With minimal requirements, users only need to input lyrics and a reference voice to synthesize a song sample. For full control, just input textual prompts or even directly input MIDI. Experimental results indicate that MelodyLM achieves superior performance in terms of both objective and subjective metrics. Audio samples are available at https://melodylm666.github.io.
Self-Distillation Prototypes Network: Learning Robust Speaker Representations without Supervision
Jun 17, 2024Training speaker-discriminative and robust speaker verification systems without explicit speaker labels remains a persisting challenge. In this paper, we propose a new self-supervised speaker verification approach, Self-Distillation Prototypes Network (SDPN), which effectively facilitates self-supervised speaker representation learning. SDPN assigns the representation of the augmented views of an utterance to the same prototypes as the representation of the original view, thereby enabling effective knowledge transfer between the views. Originally, due to the lack of negative pairs in the SDPN training process, the network tends to align positive pairs very closely in the embedding space, a phenomenon known as model collapse. To alleviate this problem, we introduce a diversity regularization term to embeddings in SDPN. Comprehensive experiments on the VoxCeleb datasets demonstrate the superiority of SDPN in self-supervised speaker verification. SDPN sets a new state-of-the-art on the VoxCeleb1 speaker verification evaluation benchmark, achieving Equal Error Rate 1.80%, 1.99%, and 3.62% for trial VoxCeleb1-O, VoxCeleb1-E and VoxCeleb1-H respectively, without using any speaker labels in training.
Skip-Layer Attention: Bridging Abstract and Detailed Dependencies in Transformers
Jun 17, 2024



The Transformer architecture has significantly advanced deep learning, particularly in natural language processing, by effectively managing long-range dependencies. However, as the demand for understanding complex relationships grows, refining the Transformer's architecture becomes critical. This paper introduces Skip-Layer Attention (SLA) to enhance Transformer models by enabling direct attention between non-adjacent layers. This method improves the model's ability to capture dependencies between high-level abstract features and low-level details. By facilitating direct attention between these diverse feature levels, our approach overcomes the limitations of current Transformers, which often rely on suboptimal intra-layer attention. Our implementation extends the Transformer's functionality by enabling queries in a given layer to interact with keys and values from both the current layer and one preceding layer, thus enhancing the diversity of multi-head attention without additional computational burden. Extensive experiments demonstrate that our enhanced Transformer model achieves superior performance in language modeling tasks, highlighting the effectiveness of our skip-layer attention mechanism.