 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHeterogeneous Generative Knowledge Distillation with Masked Image Modeling
Sep 18, 2023



Small CNN-based models usually require transferring knowledge from a large model before they are deployed in computationally resource-limited edge devices. Masked image modeling (MIM) methods achieve great success in various visual tasks but remain largely unexplored in knowledge distillation for heterogeneous deep models. The reason is mainly due to the significant discrepancy between the Transformer-based large model and the CNN-based small network. In this paper, we develop the first Heterogeneous Generative Knowledge Distillation (H-GKD) based on MIM, which can efficiently transfer knowledge from large Transformer models to small CNN-based models in a generative self-supervised fashion. Our method builds a bridge between Transformer-based models and CNNs by training a UNet-style student with sparse convolution, which can effectively mimic the visual representation inferred by a teacher over masked modeling. Our method is a simple yet effective learning paradigm to learn the visual representation and distribution of data from heterogeneous teacher models, which can be pre-trained using advanced generative methods. Extensive experiments show that it adapts well to various models and sizes, consistently achieving state-of-the-art performance in image classification, object detection, and semantic segmentation tasks. For example, in the Imagenet 1K dataset, H-GKD improves the accuracy of Resnet50 (sparse) from 76.98% to 80.01%.
Simple parameter-free self-attention approximation
Jul 22, 2023The hybrid model of self-attention and convolution is one of the methods to lighten ViT. The quadratic computational complexity of self-attention with respect to token length limits the efficiency of ViT on edge devices. We propose a self-attention approximation without training parameters, called SPSA, which captures global spatial features with linear complexity. To verify the effectiveness of SPSA combined with convolution, we conduct extensive experiments on image classification and object detection tasks.
Prompt Tuning Inversion for Text-Driven Image Editing Using Diffusion Models
May 08, 2023



Recently large-scale language-image models (e.g., text-guided diffusion models) have considerably improved the image generation capabilities to generate photorealistic images in various domains. Based on this success, current image editing methods use texts to achieve intuitive and versatile modification of images. To edit a real image using diffusion models, one must first invert the image to a noisy latent from which an edited image is sampled with a target text prompt. However, most methods lack one of the following: user-friendliness (e.g., additional masks or precise descriptions of the input image are required), generalization to larger domains, or high fidelity to the input image. In this paper, we design an accurate and quick inversion technique, Prompt Tuning Inversion, for text-driven image editing. Specifically, our proposed editing method consists of a reconstruction stage and an editing stage. In the first stage, we encode the information of the input image into a learnable conditional embedding via Prompt Tuning Inversion. In the second stage, we apply classifier-free guidance to sample the edited image, where the conditional embedding is calculated by linearly interpolating between the target embedding and the optimized one obtained in the first stage. This technique ensures a superior trade-off between editability and high fidelity to the input image of our method. For example, we can change the color of a specific object while preserving its original shape and background under the guidance of only a target text prompt. Extensive experiments on ImageNet demonstrate the superior editing performance of our method compared to the state-of-the-art baselines.
Language-aware Multiple Datasets Detection Pretraining for DETRs
Apr 07, 2023



Pretraining on large-scale datasets can boost the performance of object detectors while the annotated datasets for object detection are hard to scale up due to the high labor cost. What we possess are numerous isolated filed-specific datasets, thus, it is appealing to jointly pretrain models across aggregation of datasets to enhance data volume and diversity. In this paper, we propose a strong framework for utilizing Multiple datasets to pretrain DETR-like detectors, termed METR, without the need for manual label spaces integration. It converts the typical multi-classification in object detection into binary classification by introducing a pre-trained language model. Specifically, we design a category extraction module for extracting potential categories involved in an image and assign these categories into different queries by language embeddings. Each query is only responsible for predicting a class-specific object. Besides, to adapt our novel detection paradigm, we propose a group bipartite matching strategy that limits the ground truths to match queries assigned to the same category. Extensive experiments demonstrate that METR achieves extraordinary results on either multi-task joint training or the pretrain & finetune paradigm. Notably, our pre-trained models have high flexible transferability and increase the performance upon various DETR-like detectors on COCO val2017 benchmark. Codes will be available after this paper is published.
Rethinking the Number of Shots in Robust Model-Agnostic Meta-Learning
Nov 28, 2022



Robust Model-Agnostic Meta-Learning (MAML) is usually adopted to train a meta-model which may fast adapt to novel classes with only a few exemplars and meanwhile remain robust to adversarial attacks. The conventional solution for robust MAML is to introduce robustness-promoting regularization during meta-training stage. With such a regularization, previous robust MAML methods simply follow the typical MAML practice that the number of training shots should match with the number of test shots to achieve an optimal adaptation performance. However, although the robustness can be largely improved, previous methods sacrifice clean accuracy a lot. In this paper, we observe that introducing robustness-promoting regularization into MAML reduces the intrinsic dimension of clean sample features, which results in a lower capacity of clean representations. This may explain why the clean accuracy of previous robust MAML methods drops severely. Based on this observation, we propose a simple strategy, i.e., increasing the number of training shots, to mitigate the loss of intrinsic dimension caused by robustness-promoting regularization. Though simple, our method remarkably improves the clean accuracy of MAML without much loss of robustness, producing a robust yet accurate model. Extensive experiments demonstrate that our method outperforms prior arts in achieving a better trade-off between accuracy and robustness. Besides, we observe that our method is less sensitive to the number of fine-tuning steps during meta-training, which allows for a reduced number of fine-tuning steps to improve training efficiency.
CAE v2: Context Autoencoder with CLIP Target
Nov 17, 2022



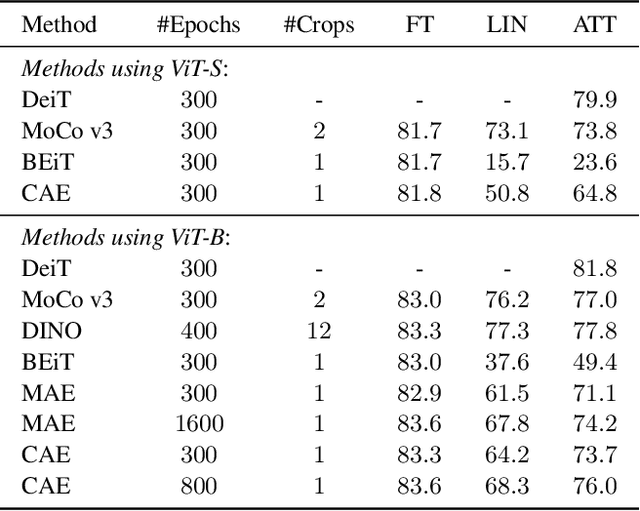
Masked image modeling (MIM) learns visual representation by masking and reconstructing image patches. Applying the reconstruction supervision on the CLIP representation has been proven effective for MIM. However, it is still under-explored how CLIP supervision in MIM influences performance. To investigate strategies for refining the CLIP-targeted MIM, we study two critical elements in MIM, i.e., the supervision position and the mask ratio, and reveal two interesting perspectives, relying on our developed simple pipeline, context autodecoder with CLIP target (CAE v2). Firstly, we observe that the supervision on visible patches achieves remarkable performance, even better than that on masked patches, where the latter is the standard format in the existing MIM methods. Secondly, the optimal mask ratio positively correlates to the model size. That is to say, the smaller the model, the lower the mask ratio needs to be. Driven by these two discoveries, our simple and concise approach CAE v2 achieves superior performance on a series of downstream tasks. For example, a vanilla ViT-Large model achieves 81.7% and 86.7% top-1 accuracy on linear probing and fine-tuning on ImageNet-1K, and 55.9% mIoU on semantic segmentation on ADE20K with the pre-training for 300 epochs. We hope our findings can be helpful guidelines for the pre-training in the MIM area, especially for the small-scale models.
Context Autoencoder for Self-Supervised Representation Learning
Feb 07, 2022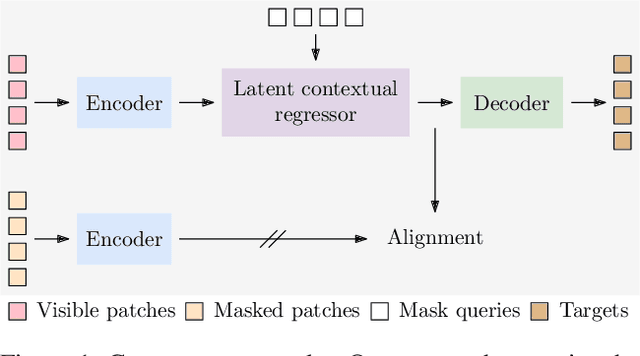


We present a novel masked image modeling (MIM) approach, context autoencoder (CAE), for self-supervised learning. We randomly partition the image into two sets: visible patches and masked patches. The CAE architecture consists of: (i) an encoder that takes visible patches as input and outputs their latent representations, (ii) a latent context regressor that predicts the masked patch representations from the visible patch representations that are not updated in this regressor, (iii) a decoder that takes the estimated masked patch representations as input and makes predictions for the masked patches, and (iv) an alignment module that aligns the masked patch representation estimation with the masked patch representations computed from the encoder. In comparison to previous MIM methods that couple the encoding and decoding roles, e.g., using a single module in BEiT, our approach attempts to~\emph{separate the encoding role (content understanding) from the decoding role (making predictions for masked patches)} using different modules, improving the content understanding capability. In addition, our approach makes predictions from the visible patches to the masked patches in \emph{the latent representation space} that is expected to take on semantics. In addition, we present the explanations about why contrastive pretraining and supervised pretraining perform similarly and why MIM potentially performs better. We demonstrate the effectiveness of our CAE through superior transfer performance in downstream tasks: semantic segmentation, and object detection and instance segmentation.
Oriented Object Detection with Transformer
Jun 06, 2021
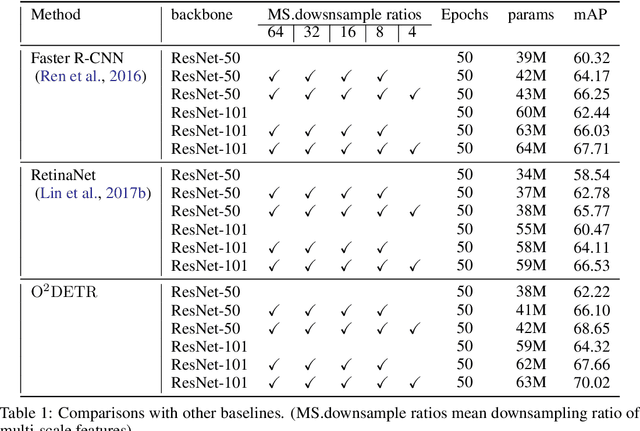
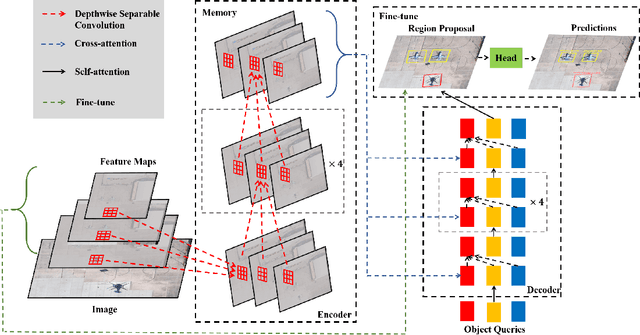
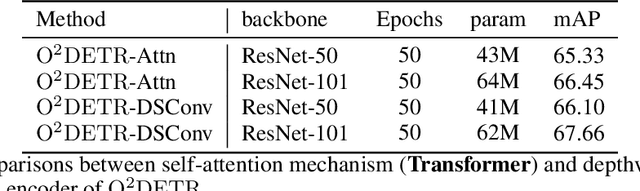
Object detection with Transformers (DETR) has achieved a competitive performance over traditional detectors, such as Faster R-CNN. However, the potential of DETR remains largely unexplored for the more challenging task of arbitrary-oriented object detection problem. We provide the first attempt and implement Oriented Object DEtection with TRansformer ($\bf O^2DETR$) based on an end-to-end network. The contributions of $\rm O^2DETR$ include: 1) we provide a new insight into oriented object detection, by applying Transformer to directly and efficiently localize objects without a tedious process of rotated anchors as in conventional detectors; 2) we design a simple but highly efficient encoder for Transformer by replacing the attention mechanism with depthwise separable convolution, which can significantly reduce the memory and computational cost of using multi-scale features in the original Transformer; 3) our $\rm O^2DETR$ can be another new benchmark in the field of oriented object detection, which achieves up to 3.85 mAP improvement over Faster R-CNN and RetinaNet. We simply fine-tune the head mounted on $\rm O^2DETR$ in a cascaded architecture and achieve a competitive performance over SOTA in the DOTA dataset.
Dual-stream Network for Visual Recognition
May 31, 2021
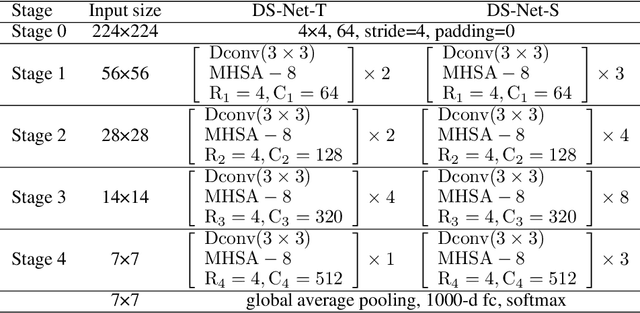
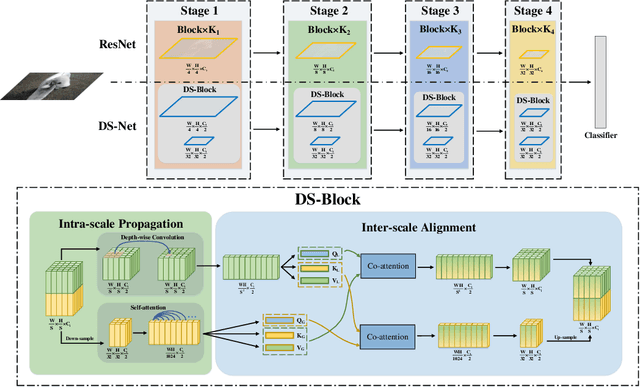
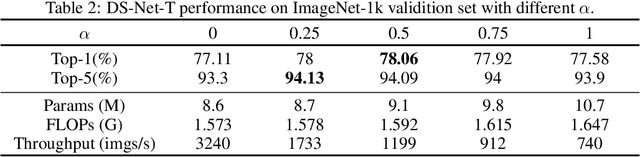
Transformers with remarkable global representation capacities achieve competitive results for visual tasks, but fail to consider high-level local pattern information in input images. In this paper, we present a generic Dual-stream Network (DS-Net) to fully explore the representation capacity of local and global pattern features for image classification. Our DS-Net can simultaneously calculate fine-grained and integrated features and efficiently fuse them. Specifically, we propose an Intra-scale Propagation module to process two different resolutions in each block and an Inter-Scale Alignment module to perform information interaction across features at dual scales. Besides, we also design a Dual-stream FPN (DS-FPN) to further enhance contextual information for downstream dense predictions. Without bells and whistles, the propsed DS-Net outperforms Deit-Small by 2.4% in terms of top-1 accuracy on ImageNet-1k and achieves state-of-the-art performance over other Vision Transformers and ResNets. For object detection and instance segmentation, DS-Net-Small respectively outperforms ResNet-50 by 6.4% and 5.5 % in terms of mAP on MSCOCO 2017, and surpasses the previous state-of-the-art scheme, which significantly demonstrates its potential to be a general backbone in vision tasks. The code will be released soon.
Probabilistic Ranking-Aware Ensembles for Enhanced Object Detections
May 07, 2021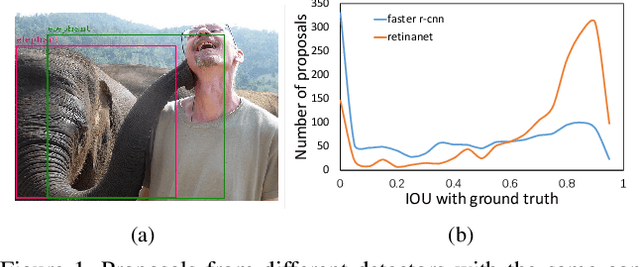

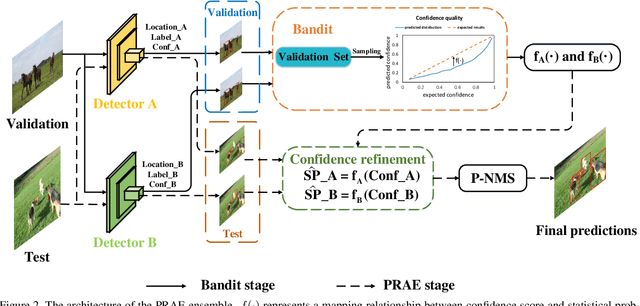

Model ensembles are becoming one of the most effective approaches for improving object detection performance already optimized for a single detector. Conventional methods directly fuse bounding boxes but typically fail to consider proposal qualities when combining detectors. This leads to a new problem of confidence discrepancy for the detector ensembles. The confidence has little effect on single detectors but significantly affects detector ensembles. To address this issue, we propose a novel ensemble called the Probabilistic Ranking Aware Ensemble (PRAE) that refines the confidence of bounding boxes from detectors. By simultaneously considering the category and the location on the same validation set, we obtain a more reliable confidence based on statistical probability. We can then rank the detected bounding boxes for assembly. We also introduce a bandit approach to address the confidence imbalance problem caused by the need to deal with different numbers of boxes at different confidence levels. We use our PRAE-based non-maximum suppression (P-NMS) to replace the conventional NMS method in ensemble learning. Experiments on the PASCAL VOC and COCO2017 datasets demonstrate that our PRAE method consistently outperforms state-of-the-art methods by significant margins.