 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHy-MT2: A Family of Fast, Efficient and Powerful Multilingual Translation Models in the Wild
May 21, 2026Hy-MT2 is a family of fast-thinking multilingual translation models designed for complex real-world scenarios. It includes three model sizes: 1.8B, 7B, and 30B-A3B (MoE), all of which support translation among 33 languages and effectively follow translation instructions in multiple languages. For on-device deployment, with AngelSlim 1.25-bit extreme quantization, the 1.8B model requires only 440 MB of storage and improves inference speed by 1.5x. Multi-dimensional evaluations show that Hy-MT2 delivers outstanding performance across general, real-world business, domain-specific, and instruction-following translation tasks. The 7B and 30B models outperform open-source models such as DeepSeek-V4-Pro and Kimi K2.6 in fast-thinking mode, while the lightweight 1.8B model also surpasses mainstream commercial APIs from providers such as Microsoft and Doubao overall.
WRAP++: Web discoveRy Amplified Pretraining
Apr 09, 2026Synthetic data rephrasing has emerged as a powerful technique for enhancing knowledge acquisition during large language model (LLM) pretraining. However, existing approaches operate at the single-document level, rewriting individual web pages in isolation. This confines synthesized examples to intra-document knowledge, missing cross-document relationships and leaving facts with limited associative context. We propose WRAP++ (Web discoveRy Amplified Pretraining), which amplifies the associative context of factual knowledge by discovering cross-document relationships from web hyperlinks and synthesizing joint QA over each discovered document pair. Concretely, WRAP++ discovers high-confidence relational motifs including dual-links and co-mentions, and synthesizes QA that requires reasoning across both documents. This produces relational knowledge absent from either source document alone, creating diverse entry points to the same facts. Because the number of valid entity pairs grows combinatorially, this discovery-driven synthesis also amplifies data scale far beyond single-document rewriting. Instantiating WRAP++ on Wikipedia, we amplify ~8.4B tokens of raw text into 80B tokens of cross-document QA data. On SimpleQA, OLMo-based models at both 7B and 32B scales trained with WRAP++ substantially outperform single-document approaches and exhibit sustained scaling gains, underscoring the advantage of cross-document knowledge discovery and amplification.
SIGMark: Scalable In-Generation Watermark with Blind Extraction for Video Diffusion
Mar 03, 2026Artificial Intelligence Generated Content (AIGC), particularly video generation with diffusion models, has been advanced rapidly. Invisible watermarking is a key technology for protecting AI-generated videos and tracing harmful content, and thus plays a crucial role in AI safety. Beyond post-processing watermarks which inevitably degrade video quality, recent studies have proposed distortion-free in-generation watermarking for video diffusion models. However, existing in-generation approaches are non-blind: they require maintaining all the message-key pairs and performing template-based matching during extraction, which incurs prohibitive computational costs at scale. Moreover, when applied to modern video diffusion models with causal 3D Variational Autoencoders (VAEs), their robustness against temporal disturbance becomes extremely weak. To overcome these challenges, we propose SIGMark, a Scalable In-Generation watermarking framework with blind extraction for video diffusion. To achieve blind-extraction, we propose to generate watermarked initial noise using a Global set of Frame-wise PseudoRandom Coding keys (GF-PRC), reducing the cost of storing large-scale information while preserving noise distribution and diversity for distortion-free watermarking. To enhance robustness, we further design a Segment Group-Ordering module (SGO) tailored to causal 3D VAEs, ensuring robust watermark inversion during extraction under temporal disturbance. Comprehensive experiments on modern diffusion models show that SIGMark achieves very high bit-accuracy during extraction under both temporal and spatial disturbances with minimal overhead, demonstrating its scalability and robustness. Our project is available at https://jeremyzhao1998.github.io/SIGMark-release/.
Activation-Space Anchored Access Control for Multi-Class Permission Reasoning in Large Language Models
Jan 20, 2026Large language models (LLMs) are increasingly deployed over knowledge bases for efficient knowledge retrieval and question answering. However, LLMs can inadvertently answer beyond a user's permission scope, leaking sensitive content, thus making it difficult to deploy knowledge-base QA under fine-grained access control requirements. In this work, we identify a geometric regularity in intermediate activations: for the same query, representations induced by different permission scopes cluster distinctly and are readily separable. Building on this separability, we propose Activation-space Anchored Access Control (AAAC), a training-free framework for multi-class permission control. AAAC constructs an anchor bank, with one permission anchor per class, from a small offline sample set and requires no fine-tuning. At inference time, a multi-anchor steering mechanism redirects each query's activations toward the anchor-defined authorized region associated with the current user, thereby suppressing over-privileged generations by design. Finally, extensive experiments across three LLM families demonstrate that AAAC reduces permission violation rates by up to 86.5% and prompt-based attack success rates by 90.7%, while improving response usability with minor inference overhead compared to baselines.
SITP: A High-Reliability Semantic Information Transport Protocol Without Retransmission for Semantic Communication
Dec 10, 2025With the evolution of 6G networks, modern communication systems are facing unprecedented demands for high reliability and low latency. However, conventional transport protocols are designed for bit-level reliability, failing to meet the semantic robustness requirements. To address this limitation, this paper proposes a novel Semantic Information Transport Protocol (SITP), which achieves TCP-level reliability and UDP level latency by verifying only packet headers while retaining potentially corrupted payloads for semantic decoding. Building upon SITP, a cross-layer analytical model is established to quantify packet-loss probability across the physical, data-link, network, transport, and application layers. The model provides a unified probabilistic formulation linking signal noise rate (SNR) and packet-loss rate, offering theoretical foundation into end-to-end semantic transmission. Furthermore, a cross-image feature interleaving mechanism is developed to mitigate consecutive burst losses by redistributing semantic features across multiple correlated images, thereby enhancing robustness in burst-fade channels. Extensive experiments show that SITP offers lower latency than TCP with comparable reliability at low SNRs, while matching UDP-level latency and delivering superior reconstruction quality. In addition, the proposed cross-image semantic interleaving mechanism further demonstrates its effectiveness in mitigating degradation caused by bursty packet losses.
NOC4SC: A Bandwidth-Efficient Multi-User Semantic Communication Framework for Interference-Resilient Transmission
Dec 10, 2025



With the explosive growth of connected devices and emerging applications, current wireless networks are encountering unprecedented demands for massive user access, where the inter-user interference has become a critical challenge to maintaining high quality of service (QoS) in multi-user communication systems. To tackle this issue, we propose a bandwidth-efficient semantic communication paradigm termed Non-Orthogonal Codewords for Semantic Communication (NOC4SC), which enables simultaneous same-frequency transmission without spectrum spreading. By leveraging the Swin Transformer, the proposed NOC4SC framework enables each user to independently extract semantic features through a unified encoder-decoder architecture with shared network parameters across all users, which ensures that the user's data remains protected from unauthorized decoding. Furthermore, we introduce an adaptive NOC and SNR Modulation (NSM) block, which employs deep learning to dynamically regulate SNR and generate approximately orthogonal semantic features within distinct feature subspaces, thereby effectively mitigating inter-user interference. Extensive experiments demonstrate the proposed NOC4SC achieves comparable performance to the DeepJSCC-PNOMA and outperforms other multi-user SemCom baseline methods.
ACPO: Adaptive Curriculum Policy Optimization for Aligning Vision-Language Models in Complex Reasoning
Oct 01, 2025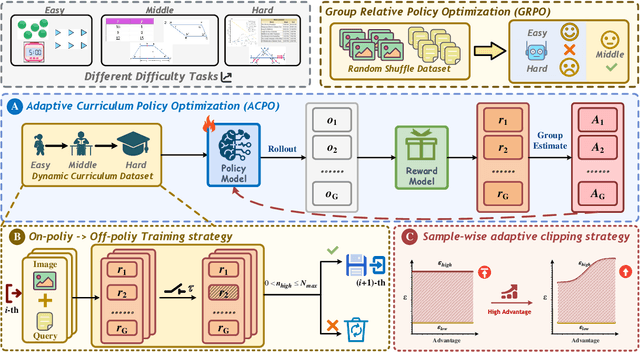


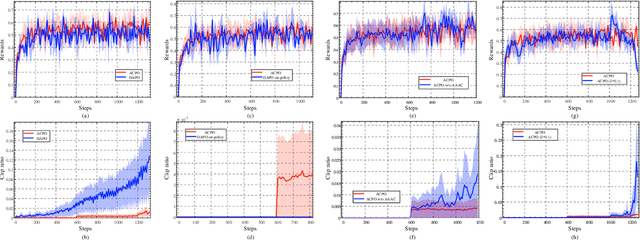
Aligning large-scale vision-language models (VLMs) for complex reasoning via reinforcement learning is often hampered by the limitations of existing policy optimization algorithms, such as static training schedules and the rigid, uniform clipping mechanism in Proximal Policy Optimization (PPO). In this work, we introduce Adaptive Curriculum Policy Optimization (ACPO), a novel framework that addresses these challenges through a dual-component adaptive learning strategy. First, ACPO employs a dynamic curriculum that orchestrates a principled transition from a stable, near on-policy exploration phase to an efficient, off-policy exploitation phase by progressively increasing sample reuse. Second, we propose an Advantage-Aware Adaptive Clipping (AAAC) mechanism that replaces the fixed clipping hyperparameter with dynamic, sample-wise bounds modulated by the normalized advantage of each token. This allows for more granular and robust policy updates, enabling larger gradients for high-potential samples while safeguarding against destructive ones. We conduct extensive experiments on a suite of challenging multimodal reasoning benchmarks, including MathVista, LogicVista, and MMMU-Pro. Results demonstrate that ACPO consistently outperforms strong baselines such as DAPO and PAPO, achieving state-of-the-art performance, accelerated convergence, and superior training stability.
Adaptive Deep Reasoning: Triggering Deep Thinking When Needed
May 26, 2025Large language models (LLMs) have shown impressive capabilities in handling complex tasks through long-chain reasoning. However, the extensive reasoning steps involved can significantly increase computational costs, posing challenges for real-world deployment. Recent efforts have focused on optimizing reasoning efficiency by shortening the Chain-of-Thought (CoT) reasoning processes through various approaches, such as length-aware prompt engineering, supervised fine-tuning on CoT data with variable lengths, and reinforcement learning with length penalties. Although these methods effectively reduce reasoning length, they still necessitate an initial reasoning phase. More recent approaches have attempted to integrate long-chain and short-chain reasoning abilities into a single model, yet they still rely on manual control to toggle between short and long CoT.In this work, we propose a novel approach that autonomously switches between short and long reasoning chains based on problem complexity. Our method begins with supervised fine-tuning of the base model to equip both long-chain and short-chain reasoning abilities. We then employ reinforcement learning to further balance short and long CoT generation while maintaining accuracy through two key strategies: first, integrating reinforcement learning with a long-short adaptive group-wise reward strategy to assess prompt complexity and provide corresponding rewards; second, implementing a logit-based reasoning mode switching loss to optimize the model's initial token choice, thereby guiding the selection of the reasoning type.Evaluations on mathematical datasets demonstrate that our model can dynamically switch between long-chain and short-chain reasoning modes without substantially sacrificing performance. This advancement enhances the practicality of reasoning in large language models for real-world applications.
Hunyuan-TurboS: Advancing Large Language Models through Mamba-Transformer Synergy and Adaptive Chain-of-Thought
May 21, 2025As Large Language Models (LLMs) rapidly advance, we introduce Hunyuan-TurboS, a novel large hybrid Transformer-Mamba Mixture of Experts (MoE) model. It synergistically combines Mamba's long-sequence processing efficiency with Transformer's superior contextual understanding. Hunyuan-TurboS features an adaptive long-short chain-of-thought (CoT) mechanism, dynamically switching between rapid responses for simple queries and deep "thinking" modes for complex problems, optimizing computational resources. Architecturally, this 56B activated (560B total) parameter model employs 128 layers (Mamba2, Attention, FFN) with an innovative AMF/MF block pattern. Faster Mamba2 ensures linear complexity, Grouped-Query Attention minimizes KV cache, and FFNs use an MoE structure. Pre-trained on 16T high-quality tokens, it supports a 256K context length and is the first industry-deployed large-scale Mamba model. Our comprehensive post-training strategy enhances capabilities via Supervised Fine-Tuning (3M instructions), a novel Adaptive Long-short CoT Fusion method, Multi-round Deliberation Learning for iterative improvement, and a two-stage Large-scale Reinforcement Learning process targeting STEM and general instruction-following. Evaluations show strong performance: overall top 7 rank on LMSYS Chatbot Arena with a score of 1356, outperforming leading models like Gemini-2.0-Flash-001 (1352) and o4-mini-2025-04-16 (1345). TurboS also achieves an average of 77.9% across 23 automated benchmarks. Hunyuan-TurboS balances high performance and efficiency, offering substantial capabilities at lower inference costs than many reasoning models, establishing a new paradigm for efficient large-scale pre-trained models.
Context Autoencoder for Self-Supervised Representation Learning
Feb 07, 2022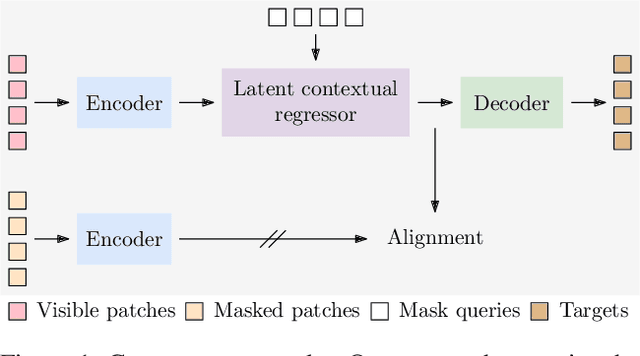
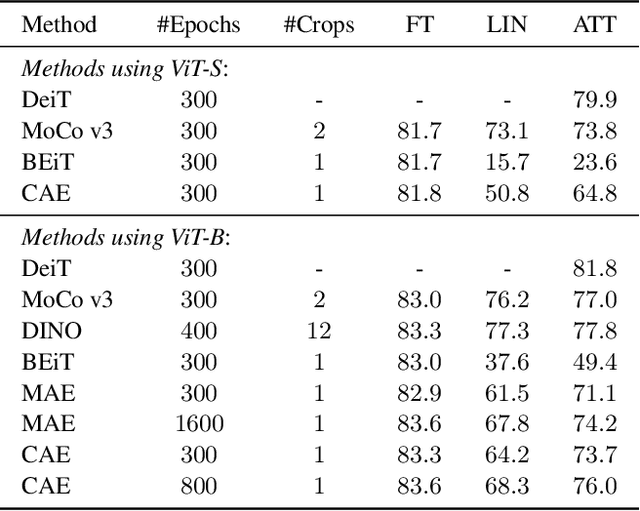


We present a novel masked image modeling (MIM) approach, context autoencoder (CAE), for self-supervised learning. We randomly partition the image into two sets: visible patches and masked patches. The CAE architecture consists of: (i) an encoder that takes visible patches as input and outputs their latent representations, (ii) a latent context regressor that predicts the masked patch representations from the visible patch representations that are not updated in this regressor, (iii) a decoder that takes the estimated masked patch representations as input and makes predictions for the masked patches, and (iv) an alignment module that aligns the masked patch representation estimation with the masked patch representations computed from the encoder. In comparison to previous MIM methods that couple the encoding and decoding roles, e.g., using a single module in BEiT, our approach attempts to~\emph{separate the encoding role (content understanding) from the decoding role (making predictions for masked patches)} using different modules, improving the content understanding capability. In addition, our approach makes predictions from the visible patches to the masked patches in \emph{the latent representation space} that is expected to take on semantics. In addition, we present the explanations about why contrastive pretraining and supervised pretraining perform similarly and why MIM potentially performs better. We demonstrate the effectiveness of our CAE through superior transfer performance in downstream tasks: semantic segmentation, and object detection and instance segmentation.