 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWORLDMEM: Long-term Consistent World Simulation with Memory
Apr 16, 2025



World simulation has gained increasing popularity due to its ability to model virtual environments and predict the consequences of actions. However, the limited temporal context window often leads to failures in maintaining long-term consistency, particularly in preserving 3D spatial consistency. In this work, we present WorldMem, a framework that enhances scene generation with a memory bank consisting of memory units that store memory frames and states (e.g., poses and timestamps). By employing a memory attention mechanism that effectively extracts relevant information from these memory frames based on their states, our method is capable of accurately reconstructing previously observed scenes, even under significant viewpoint or temporal gaps. Furthermore, by incorporating timestamps into the states, our framework not only models a static world but also captures its dynamic evolution over time, enabling both perception and interaction within the simulated world. Extensive experiments in both virtual and real scenarios validate the effectiveness of our approach.
Vision-Language Model for Object Detection and Segmentation: A Review and Evaluation
Apr 13, 2025



Vision-Language Model (VLM) have gained widespread adoption in Open-Vocabulary (OV) object detection and segmentation tasks. Despite they have shown promise on OV-related tasks, their effectiveness in conventional vision tasks has thus far been unevaluated. In this work, we present the systematic review of VLM-based detection and segmentation, view VLM as the foundational model and conduct comprehensive evaluations across multiple downstream tasks for the first time: 1) The evaluation spans eight detection scenarios (closed-set detection, domain adaptation, crowded objects, etc.) and eight segmentation scenarios (few-shot, open-world, small object, etc.), revealing distinct performance advantages and limitations of various VLM architectures across tasks. 2) As for detection tasks, we evaluate VLMs under three finetuning granularities: \textit{zero prediction}, \textit{visual fine-tuning}, and \textit{text prompt}, and further analyze how different finetuning strategies impact performance under varied task. 3) Based on empirical findings, we provide in-depth analysis of the correlations between task characteristics, model architectures, and training methodologies, offering insights for future VLM design. 4) We believe that this work shall be valuable to the pattern recognition experts working in the fields of computer vision, multimodal learning, and vision foundation models by introducing them to the problem, and familiarizing them with the current status of the progress while providing promising directions for future research. A project associated with this review and evaluation has been created at https://github.com/better-chao/perceptual_abilities_evaluation.
HeteRAG: A Heterogeneous Retrieval-augmented Generation Framework with Decoupled Knowledge Representations
Apr 12, 2025



Retrieval-augmented generation (RAG) methods can enhance the performance of LLMs by incorporating retrieved knowledge chunks into the generation process. In general, the retrieval and generation steps usually have different requirements for these knowledge chunks. The retrieval step benefits from comprehensive information to improve retrieval accuracy, whereas excessively long chunks may introduce redundant contextual information, thereby diminishing both the effectiveness and efficiency of the generation process. However, existing RAG methods typically employ identical representations of knowledge chunks for both retrieval and generation, resulting in suboptimal performance. In this paper, we propose a heterogeneous RAG framework (\myname) that decouples the representations of knowledge chunks for retrieval and generation, thereby enhancing the LLMs in both effectiveness and efficiency. Specifically, we utilize short chunks to represent knowledge to adapt the generation step and utilize the corresponding chunk with its contextual information from multi-granular views to enhance retrieval accuracy. We further introduce an adaptive prompt tuning method for the retrieval model to adapt the heterogeneous retrieval augmented generation process. Extensive experiments demonstrate that \myname achieves significant improvements compared to baselines.
OmniCam: Unified Multimodal Video Generation via Camera Control
Apr 03, 2025

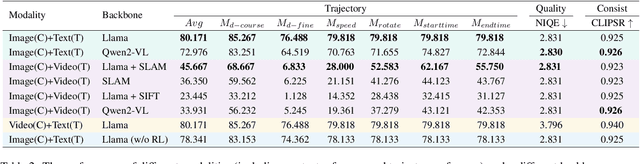
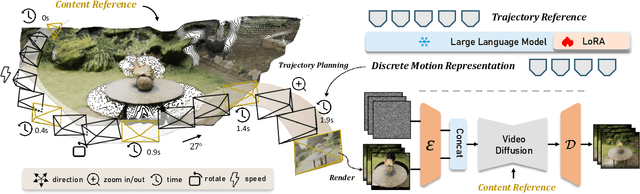
Camera control, which achieves diverse visual effects by changing camera position and pose, has attracted widespread attention. However, existing methods face challenges such as complex interaction and limited control capabilities. To address these issues, we present OmniCam, a unified multimodal camera control framework. Leveraging large language models and video diffusion models, OmniCam generates spatio-temporally consistent videos. It supports various combinations of input modalities: the user can provide text or video with expected trajectory as camera path guidance, and image or video as content reference, enabling precise control over camera motion. To facilitate the training of OmniCam, we introduce the OmniTr dataset, which contains a large collection of high-quality long-sequence trajectories, videos, and corresponding descriptions. Experimental results demonstrate that our model achieves state-of-the-art performance in high-quality camera-controlled video generation across various metrics.
A Survey on Remote Sensing Foundation Models: From Vision to Multimodality
Mar 28, 2025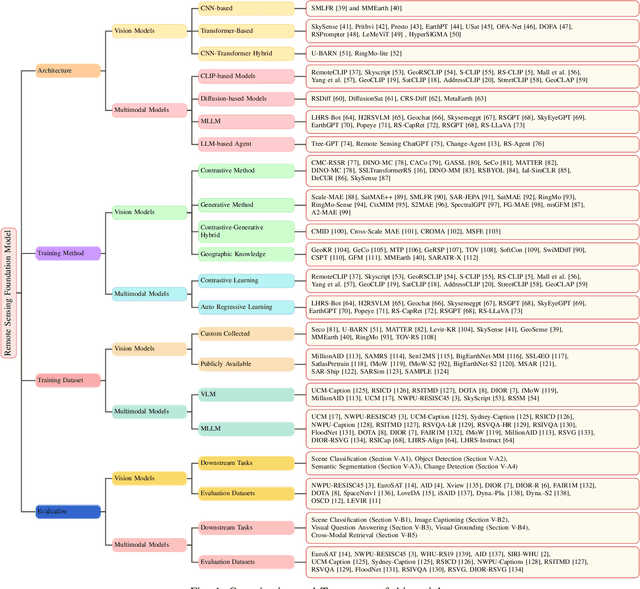
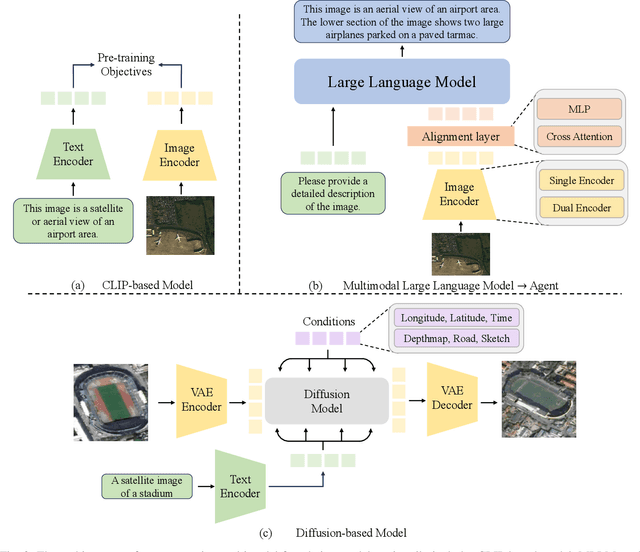

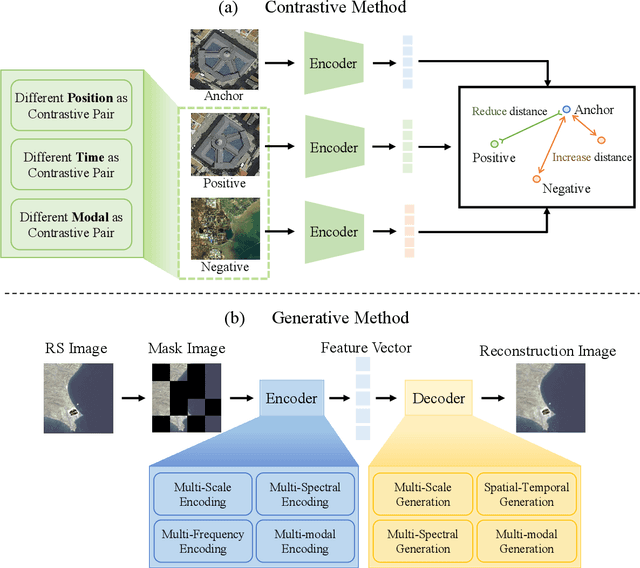
The rapid advancement of remote sensing foundation models, particularly vision and multimodal models, has significantly enhanced the capabilities of intelligent geospatial data interpretation. These models combine various data modalities, such as optical, radar, and LiDAR imagery, with textual and geographic information, enabling more comprehensive analysis and understanding of remote sensing data. The integration of multiple modalities allows for improved performance in tasks like object detection, land cover classification, and change detection, which are often challenged by the complex and heterogeneous nature of remote sensing data. However, despite these advancements, several challenges remain. The diversity in data types, the need for large-scale annotated datasets, and the complexity of multimodal fusion techniques pose significant obstacles to the effective deployment of these models. Moreover, the computational demands of training and fine-tuning multimodal models require significant resources, further complicating their practical application in remote sensing image interpretation tasks. This paper provides a comprehensive review of the state-of-the-art in vision and multimodal foundation models for remote sensing, focusing on their architecture, training methods, datasets and application scenarios. We discuss the key challenges these models face, such as data alignment, cross-modal transfer learning, and scalability, while also identifying emerging research directions aimed at overcoming these limitations. Our goal is to provide a clear understanding of the current landscape of remote sensing foundation models and inspire future research that can push the boundaries of what these models can achieve in real-world applications. The list of resources collected by the paper can be found in the https://github.com/IRIP-BUAA/A-Review-for-remote-sensing-vision-language-models.
Language-based Image Colorization: A Benchmark and Beyond
Mar 19, 2025Image colorization aims to bring colors back to grayscale images. Automatic image colorization methods, which requires no additional guidance, struggle to generate high-quality images due to color ambiguity, and provides limited user controllability. Thanks to the emergency of cross-modality datasets and models, language-based colorization methods are proposed to fully utilize the efficiency and flexibly of text descriptions to guide colorization. In view of the lack of a comprehensive review of language-based colorization literature, we conduct a thorough analysis and benchmarking. We first briefly summarize existing automatic colorization methods. Then, we focus on language-based methods and point out their core challenge on cross-modal alignment. We further divide these methods into two categories: one attempts to train a cross-modality network from scratch, while the other utilizes the pre-trained cross-modality model to establish the textual-visual correspondence. Based on the analyzed limitations of existing language-based methods, we propose a simple yet effective method based on distilled diffusion model. Extensive experiments demonstrate that our simple baseline can produces better results than previous complex methods with 14 times speed up. To the best of our knowledge, this is the first comprehensive review and benchmark on language-based image colorization field, providing meaningful insights for the community. The code is available at https://github.com/lyf1212/Color-Turbo.
Alias-Free Latent Diffusion Models:Improving Fractional Shift Equivariance of Diffusion Latent Space
Mar 12, 2025Latent Diffusion Models (LDMs) are known to have an unstable generation process, where even small perturbations or shifts in the input noise can lead to significantly different outputs. This hinders their applicability in applications requiring consistent results. In this work, we redesign LDMs to enhance consistency by making them shift-equivariant. While introducing anti-aliasing operations can partially improve shift-equivariance, significant aliasing and inconsistency persist due to the unique challenges in LDMs, including 1) aliasing amplification during VAE training and multiple U-Net inferences, and 2) self-attention modules that inherently lack shift-equivariance. To address these issues, we redesign the attention modules to be shift-equivariant and propose an equivariance loss that effectively suppresses the frequency bandwidth of the features in the continuous domain. The resulting alias-free LDM (AF-LDM) achieves strong shift-equivariance and is also robust to irregular warping. Extensive experiments demonstrate that AF-LDM produces significantly more consistent results than vanilla LDM across various applications, including video editing and image-to-image translation. Code is available at: https://github.com/SingleZombie/AFLDM
MEAT: Multiview Diffusion Model for Human Generation on Megapixels with Mesh Attention
Mar 11, 2025



Multiview diffusion models have shown considerable success in image-to-3D generation for general objects. However, when applied to human data, existing methods have yet to deliver promising results, largely due to the challenges of scaling multiview attention to higher resolutions. In this paper, we explore human multiview diffusion models at the megapixel level and introduce a solution called mesh attention to enable training at 1024x1024 resolution. Using a clothed human mesh as a central coarse geometric representation, the proposed mesh attention leverages rasterization and projection to establish direct cross-view coordinate correspondences. This approach significantly reduces the complexity of multiview attention while maintaining cross-view consistency. Building on this foundation, we devise a mesh attention block and combine it with keypoint conditioning to create our human-specific multiview diffusion model, MEAT. In addition, we present valuable insights into applying multiview human motion videos for diffusion training, addressing the longstanding issue of data scarcity. Extensive experiments show that MEAT effectively generates dense, consistent multiview human images at the megapixel level, outperforming existing multiview diffusion methods.
Balanced Image Stylization with Style Matching Score
Mar 10, 2025



We present Style Matching Score (SMS), a novel optimization method for image stylization with diffusion models. Balancing effective style transfer with content preservation is a long-standing challenge. Unlike existing efforts, our method reframes image stylization as a style distribution matching problem. The target style distribution is estimated from off-the-shelf style-dependent LoRAs via carefully designed score functions. To preserve content information adaptively, we propose Progressive Spectrum Regularization, which operates in the frequency domain to guide stylization progressively from low-frequency layouts to high-frequency details. In addition, we devise a Semantic-Aware Gradient Refinement technique that leverages relevance maps derived from diffusion semantic priors to selectively stylize semantically important regions. The proposed optimization formulation extends stylization from pixel space to parameter space, readily applicable to lightweight feedforward generators for efficient one-step stylization. SMS effectively balances style alignment and content preservation, outperforming state-of-the-art approaches, verified by extensive experiments.
OpenRSD: Towards Open-prompts for Object Detection in Remote Sensing Images
Mar 08, 2025



Remote sensing object detection has made significant progress, but most studies still focus on closed-set detection, limiting generalization across diverse datasets. Open-vocabulary object detection (OVD) provides a solution by leveraging multimodal associations between text prompts and visual features. However, existing OVD methods for remote sensing (RS) images are constrained by small-scale datasets and fail to address the unique challenges of remote sensing interpretation, include oriented object detection and the need for both high precision and real-time performance in diverse scenarios. To tackle these challenges, we propose OpenRSD, a universal open-prompt RS object detection framework. OpenRSD supports multimodal prompts and integrates multi-task detection heads to balance accuracy and real-time requirements. Additionally, we design a multi-stage training pipeline to enhance the generalization of model. Evaluated on seven public datasets, OpenRSD demonstrates superior performance in oriented and horizontal bounding box detection, with real-time inference capabilities suitable for large-scale RS image analysis. Compared to YOLO-World, OpenRSD exhibits an 8.7\% higher average precision and achieves an inference speed of 20.8 FPS. Codes and models will be released.