 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUni-MDTrack: Learning Decoupled Memory and Dynamic States for Parameter-Efficient Visual Tracking in All Modality
Mar 15, 2026With the advent of Transformer-based one-stream trackers that possess strong capability in inter-frame relation modeling, recent research has increasingly focused on how to introduce spatio-temporal context. However, most existing methods rely on a limited number of historical frames, which not only leads to insufficient utilization of the context, but also inevitably increases the length of input and incurs prohibitive computational overhead. Methods that query an external memory bank, on the other hand, suffer from inadequate fusion between the retrieved spatio-temporal features and the backbone. Moreover, using discrete historical frames as context overlooks the rich dynamics of the target. To address the issues, we propose Uni-MDTrack, which consists of two core components: Memory-Aware Compression Prompt (MCP) module and Dynamic State Fusion (DSF) module. MCP effectively compresses rich memory features into memory-aware prompt tokens, which deeply interact with the input throughout the entire backbone, significantly enhancing the performance while maintaining a stable computational load. DSF complements the discrete memory by capturing the continuous dynamic, progressively introducing the updated dynamic state features from shallow to deep layers, while also preserving high efficiency. Uni-MDTrack also supports unified tracking across RGB, RGB-D/T/E, and RGB-Language modalities. Experiments show that in Uni-MDTrack, training only the MCP, DSF, and prediction head, keeping the proportion of trainable parameters around 30%, yields substantial performance gains, achieves state-of-the-art results on 10 datasets spanning five modalities. Furthermore, both MCP and DSF exhibit excellent generality, functioning as plug-and-play components that can boost the performance of various baseline trackers, while significantly outperforming existing parameter-efficient training approaches.
SeeDNorm: Self-Rescaled Dynamic Normalization
Oct 26, 2025Normalization layer constitutes an essential component in neural networks. In transformers, the predominantly used RMSNorm constrains vectors to a unit hypersphere, followed by dimension-wise rescaling through a learnable scaling coefficient $\gamma$ to maintain the representational capacity of the model. However, RMSNorm discards the input norm information in forward pass and a static scaling factor $\gamma$ may be insufficient to accommodate the wide variability of input data and distributional shifts, thereby limiting further performance improvements, particularly in zero-shot scenarios that large language models routinely encounter. To address this limitation, we propose SeeDNorm, which enhances the representational capability of the model by dynamically adjusting the scaling coefficient based on the current input, thereby preserving the input norm information and enabling data-dependent, self-rescaled dynamic normalization. During backpropagation, SeeDNorm retains the ability of RMSNorm to dynamically adjust gradient according to the input norm. We provide a detailed analysis of the training optimization for SeedNorm and proposed corresponding solutions to address potential instability issues that may arise when applying SeeDNorm. We validate the effectiveness of SeeDNorm across models of varying sizes in large language model pre-training as well as supervised and unsupervised computer vision tasks. By introducing a minimal number of parameters and with neglligible impact on model efficiency, SeeDNorm achieves consistently superior performance compared to previously commonly used normalization layers such as RMSNorm and LayerNorm, as well as element-wise activation alternatives to normalization layers like DyT.
EasyDistill: A Comprehensive Toolkit for Effective Knowledge Distillation of Large Language Models
May 27, 2025In this paper, we present EasyDistill, a comprehensive toolkit designed for effective black-box and white-box knowledge distillation (KD) of large language models (LLMs). Our framework offers versatile functionalities, including data synthesis, supervised fine-tuning, ranking optimization, and reinforcement learning techniques specifically tailored for KD scenarios. The toolkit accommodates KD functionalities for both System 1 (fast, intuitive) and System 2 (slow, analytical) models. With its modular design and user-friendly interface, EasyDistill empowers researchers and industry practitioners to seamlessly experiment with and implement state-of-the-art KD strategies for LLMs. In addition, EasyDistill provides a series of robust distilled models and KD-based industrial solutions developed by us, along with the corresponding open-sourced datasets, catering to a variety of use cases. Furthermore, we describe the seamless integration of EasyDistill into Alibaba Cloud's Platform for AI (PAI). Overall, the EasyDistill toolkit makes advanced KD techniques for LLMs more accessible and impactful within the NLP community.
Reasoning with OmniThought: A Large CoT Dataset with Verbosity and Cognitive Difficulty Annotations
May 16, 2025

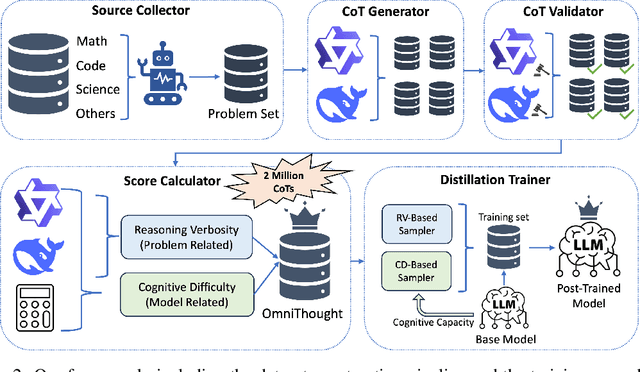
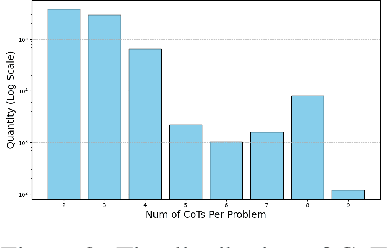
The emergence of large reasoning models (LRMs) has transformed Natural Language Processing by excelling in complex tasks such as mathematical problem-solving and code generation. These models leverage chain-of-thought (CoT) processes, enabling them to emulate human-like reasoning strategies. However, the advancement of LRMs is hindered by the lack of comprehensive CoT datasets. Current resources often fail to provide extensive reasoning problems with coherent CoT processes distilled from multiple teacher models and do not account for multifaceted properties describing the internal characteristics of CoTs. To address these challenges, we introduce OmniThought, a large-scale dataset featuring 2 million CoT processes generated and validated by two powerful LRMs as teacher models. Each CoT process in OmniThought is annotated with novel Reasoning Verbosity (RV) and Cognitive Difficulty (CD) scores, which describe the appropriateness of CoT verbosity and cognitive difficulty level for models to comprehend these reasoning processes. We further establish a self-reliant pipeline to curate this dataset. Extensive experiments using Qwen2.5 models of various sizes demonstrate the positive impact of our proposed scores on LRM training effectiveness. Based on the proposed OmniThought dataset, we further train and release a series of high-performing LRMs, specifically equipped with stronger reasoning abilities and optimal CoT output length and difficulty level. Our contributions significantly enhance the development and training of LRMs for solving complex tasks.
SkeletonX: Data-Efficient Skeleton-based Action Recognition via Cross-sample Feature Aggregation
Apr 16, 2025While current skeleton action recognition models demonstrate impressive performance on large-scale datasets, their adaptation to new application scenarios remains challenging. These challenges are particularly pronounced when facing new action categories, diverse performers, and varied skeleton layouts, leading to significant performance degeneration. Additionally, the high cost and difficulty of collecting skeleton data make large-scale data collection impractical. This paper studies one-shot and limited-scale learning settings to enable efficient adaptation with minimal data. Existing approaches often overlook the rich mutual information between labeled samples, resulting in sub-optimal performance in low-data scenarios. To boost the utility of labeled data, we identify the variability among performers and the commonality within each action as two key attributes. We present SkeletonX, a lightweight training pipeline that integrates seamlessly with existing GCN-based skeleton action recognizers, promoting effective training under limited labeled data. First, we propose a tailored sample pair construction strategy on two key attributes to form and aggregate sample pairs. Next, we develop a concise and effective feature aggregation module to process these pairs. Extensive experiments are conducted on NTU RGB+D, NTU RGB+D 120, and PKU-MMD with various GCN backbones, demonstrating that the pipeline effectively improves performance when trained from scratch with limited data. Moreover, it surpasses previous state-of-the-art methods in the one-shot setting, with only 1/10 of the parameters and much fewer FLOPs. The code and data are available at: https://github.com/zzysteve/SkeletonX
Training Small Reasoning LLMs with Cognitive Preference Alignment
Apr 14, 2025The reasoning capabilities of large language models (LLMs), such as OpenAI's o1 and DeepSeek-R1, have seen substantial advancements through deep thinking. However, these enhancements come with significant resource demands, underscoring the need to explore strategies to train effective reasoning LLMs with far fewer parameters. A critical challenge is that smaller models have different capacities and cognitive trajectories than their larger counterparts. Hence, direct distillation of chain-of-thought (CoT) results from large LLMs to smaller ones can be sometimes ineffective and requires a huge amount of annotated data. In this paper, we introduce a novel framework called Critique-Rethink-Verify (CRV), designed for training smaller yet powerful reasoning LLMs. Our CRV framework consists of multiple LLM agents, each specializing in unique abilities: (i) critiquing the CoTs according to the cognitive capabilities of smaller models, (ii) rethinking and refining these CoTs based on the critiques, and (iii) verifying the correctness of the refined results. We further propose the cognitive preference optimization (CogPO) algorithm to enhance the reasoning abilities of smaller models by aligning thoughts of these models with their cognitive capacities. Comprehensive evaluations on challenging reasoning benchmarks demonstrate the efficacy of CRV and CogPO, which outperforms other training methods by a large margin.
Vision-Language Model for Object Detection and Segmentation: A Review and Evaluation
Apr 13, 2025



Vision-Language Model (VLM) have gained widespread adoption in Open-Vocabulary (OV) object detection and segmentation tasks. Despite they have shown promise on OV-related tasks, their effectiveness in conventional vision tasks has thus far been unevaluated. In this work, we present the systematic review of VLM-based detection and segmentation, view VLM as the foundational model and conduct comprehensive evaluations across multiple downstream tasks for the first time: 1) The evaluation spans eight detection scenarios (closed-set detection, domain adaptation, crowded objects, etc.) and eight segmentation scenarios (few-shot, open-world, small object, etc.), revealing distinct performance advantages and limitations of various VLM architectures across tasks. 2) As for detection tasks, we evaluate VLMs under three finetuning granularities: \textit{zero prediction}, \textit{visual fine-tuning}, and \textit{text prompt}, and further analyze how different finetuning strategies impact performance under varied task. 3) Based on empirical findings, we provide in-depth analysis of the correlations between task characteristics, model architectures, and training methodologies, offering insights for future VLM design. 4) We believe that this work shall be valuable to the pattern recognition experts working in the fields of computer vision, multimodal learning, and vision foundation models by introducing them to the problem, and familiarizing them with the current status of the progress while providing promising directions for future research. A project associated with this review and evaluation has been created at https://github.com/better-chao/perceptual_abilities_evaluation.
Learning Historical Status Prompt for Accurate and Robust Visual Tracking
Nov 03, 2023



Most trackers perform template and search region similarity matching to find the most similar object to the template during tracking. However, they struggle to make prediction when the target appearance changes due to the limited historical information introduced by roughly cropping the current search region based on the predicted result of previous frame. In this paper, we identify that the central impediment to improving the performance of existing trackers is the incapacity to integrate abundant and effective historical information. To address this issue, we propose a Historical Information Prompter (HIP) to enhance the provision of historical information. We also build HIPTrack upon HIP module. HIP is a plug-and-play module that make full use of search region features to introduce historical appearance information. It also incorporates historical position information by constructing refined mask of the target. HIP is a lightweight module to generate historical information prompts. By integrating historical information prompts, HIPTrack significantly enhances the tracking performance without the need to retrain the backbone. Experimental results demonstrate that our method outperforms all state-of-the-art approaches on LaSOT, LaSOT ext, GOT10k and NfS. Futhermore, HIP module exhibits strong generality and can be seamlessly integrated into trackers to improve tracking performance. The source code and models will be released for further research.
SparseTT: Visual Tracking with Sparse Transformers
May 08, 2022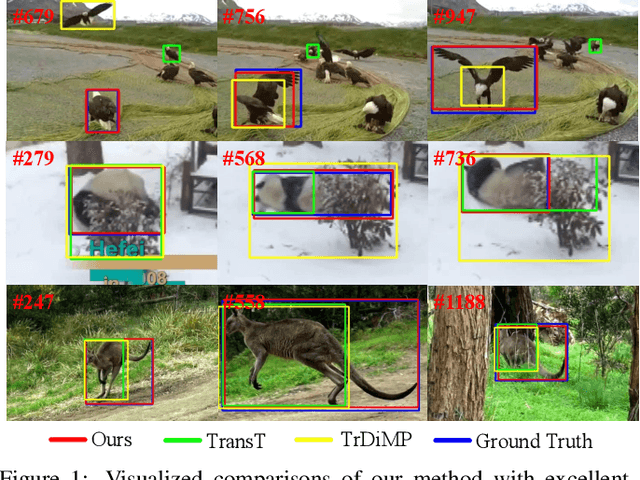
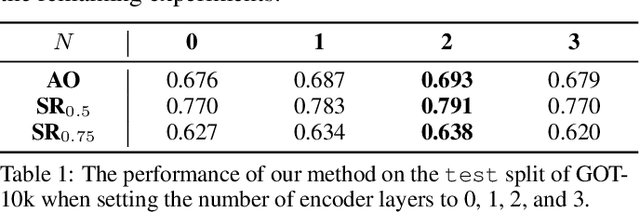
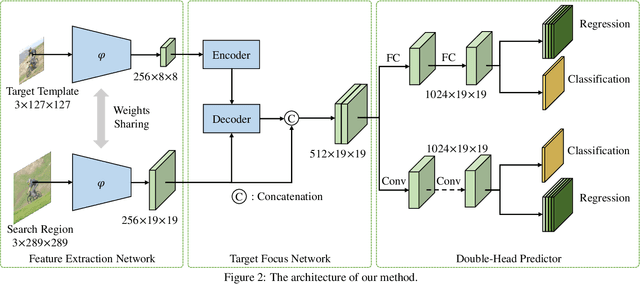
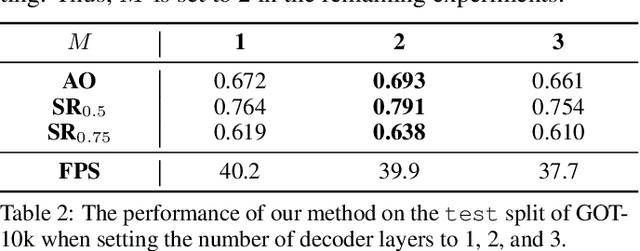
Transformers have been successfully applied to the visual tracking task and significantly promote tracking performance. The self-attention mechanism designed to model long-range dependencies is the key to the success of Transformers. However, self-attention lacks focusing on the most relevant information in the search regions, making it easy to be distracted by background. In this paper, we relieve this issue with a sparse attention mechanism by focusing the most relevant information in the search regions, which enables a much accurate tracking. Furthermore, we introduce a double-head predictor to boost the accuracy of foreground-background classification and regression of target bounding boxes, which further improve the tracking performance. Extensive experiments show that, without bells and whistles, our method significantly outperforms the state-of-the-art approaches on LaSOT, GOT-10k, TrackingNet, and UAV123, while running at 40 FPS. Notably, the training time of our method is reduced by 75% compared to that of TransT. The source code and models are available at https://github.com/fzh0917/SparseTT.