 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiffCSE: Difference-based Contrastive Learning for Sentence Embeddings
Apr 21, 2022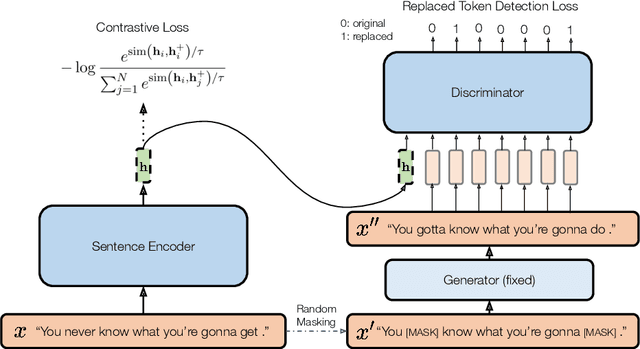
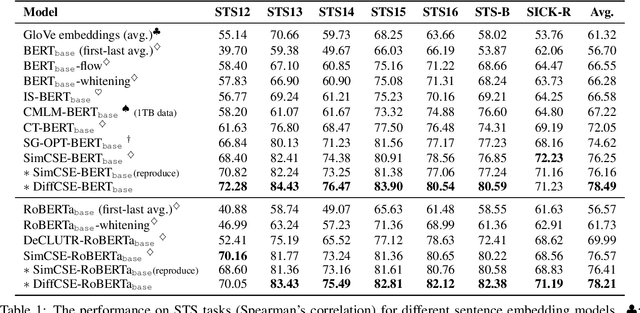
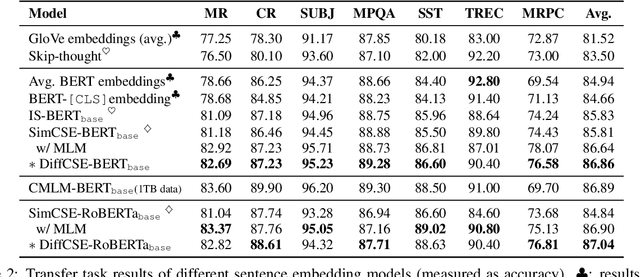
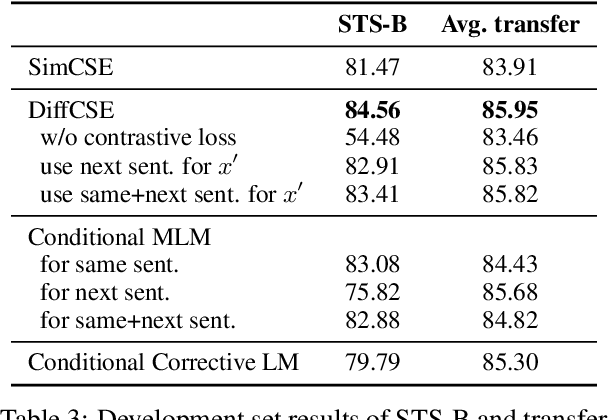
We propose DiffCSE, an unsupervised contrastive learning framework for learning sentence embeddings. DiffCSE learns sentence embeddings that are sensitive to the difference between the original sentence and an edited sentence, where the edited sentence is obtained by stochastically masking out the original sentence and then sampling from a masked language model. We show that DiffSCE is an instance of equivariant contrastive learning (Dangovski et al., 2021), which generalizes contrastive learning and learns representations that are insensitive to certain types of augmentations and sensitive to other "harmful" types of augmentations. Our experiments show that DiffCSE achieves state-of-the-art results among unsupervised sentence representation learning methods, outperforming unsupervised SimCSE by 2.3 absolute points on semantic textual similarity tasks.
Improving Self-Supervised Speech Representations by Disentangling Speakers
Apr 20, 2022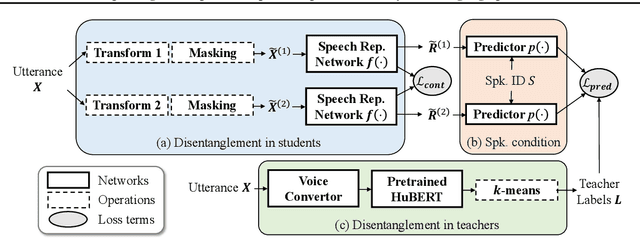

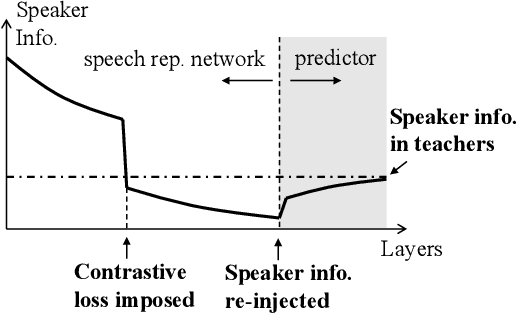
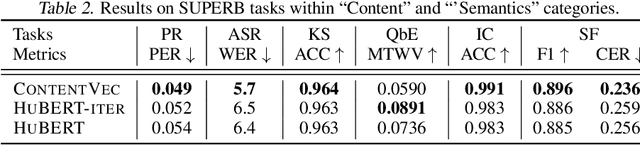
Self-supervised learning in speech involves training a speech representation network on a large-scale unannotated speech corpus, and then applying the learned representations to downstream tasks. Since the majority of the downstream tasks of SSL learning in speech largely focus on the content information in speech, the most desirable speech representations should be able to disentangle unwanted variations, such as speaker variations, from the content. However, disentangling speakers is very challenging, because removing the speaker information could easily result in a loss of content as well, and the damage of the latter usually far outweighs the benefit of the former. In this paper, we propose a new SSL method that can achieve speaker disentanglement without severe loss of content. Our approach is adapted from the HuBERT framework, and incorporates disentangling mechanisms to regularize both the teacher labels and the learned representations. We evaluate the benefit of speaker disentanglement on a set of content-related downstream tasks, and observe a consistent and notable performance advantage of our speaker-disentangled representations.
Incremental Prompting: Episodic Memory Prompt for Lifelong Event Detection
Apr 15, 2022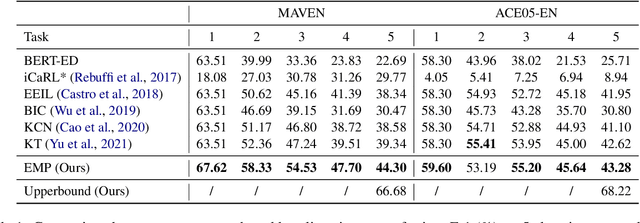
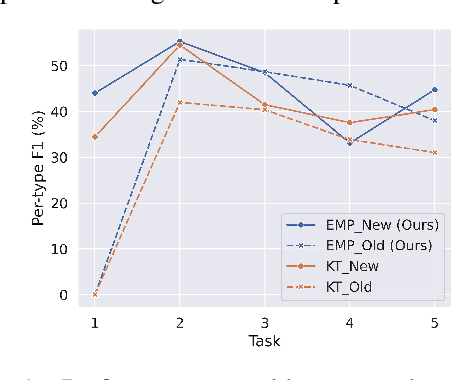
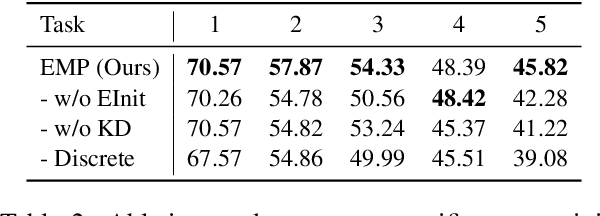
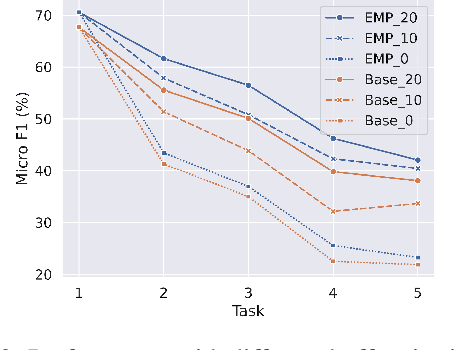
Lifelong event detection aims to incrementally update a model with new event types and data while retaining the capability on previously learned old types. One critical challenge is that the model would catastrophically forget old types when continually trained on new data. In this paper, we introduce Episodic Memory Prompts (EMP) to explicitly preserve the learned task-specific knowledge. Our method adopts continuous prompt for each task and they are optimized to instruct the model prediction and learn event-specific representation. The EMPs learned in previous tasks are carried along with the model in subsequent tasks, and can serve as a memory module that keeps the old knowledge and transferring to new tasks. Experiment results demonstrate the effectiveness of our method. Furthermore, we also conduct a comprehensive analysis of the new and old event types in lifelong learning.
WAVPROMPT: Towards Few-Shot Spoken Language Understanding with Frozen Language Models
Apr 14, 2022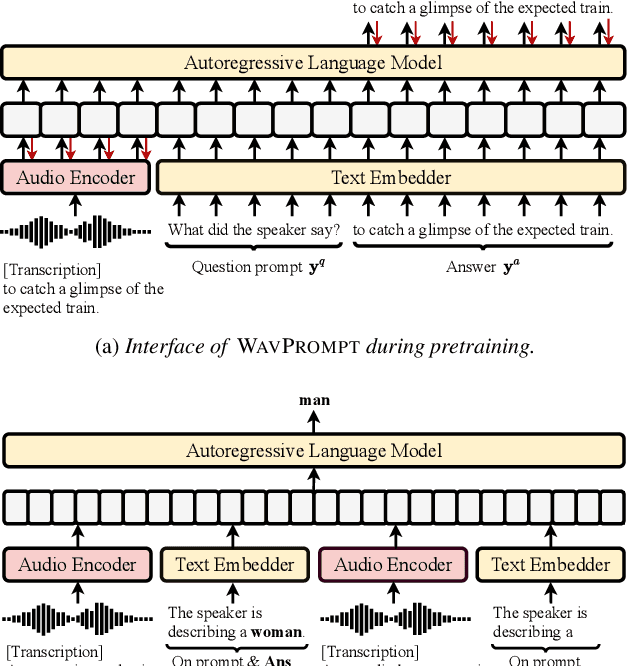
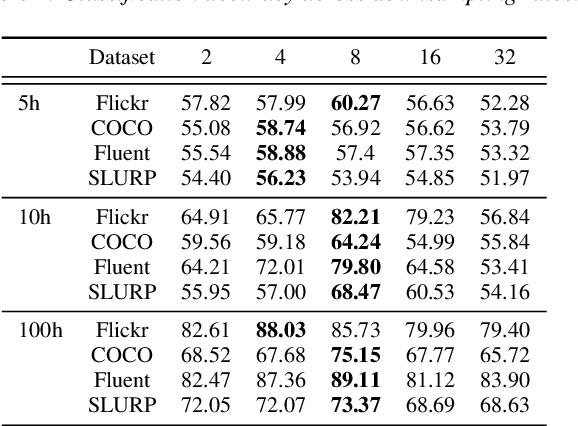

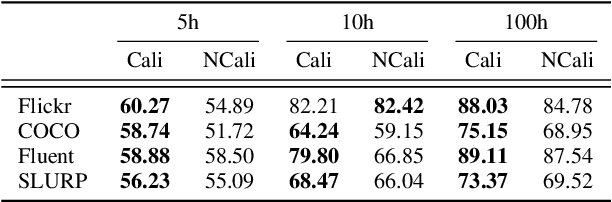
Large-scale auto-regressive language models pretrained on massive text have demonstrated their impressive ability to perform new natural language tasks with only a few text examples, without the need for fine-tuning. Recent studies further show that such a few-shot learning ability can be extended to the text-image setting by training an encoder to encode the images into embeddings functioning like the text embeddings of the language model. Interested in exploring the possibility of transferring the few-shot learning ability to the audio-text setting, we propose a novel speech understanding framework, WavPrompt, where we finetune a wav2vec model to generate a sequence of audio embeddings understood by the language model. We show that WavPrompt is a few-shot learner that can perform speech understanding tasks better than a naive text baseline. We conduct detailed ablation studies on different components and hyperparameters to empirically identify the best model configuration. In addition, we conduct a non-speech understanding experiment to show WavPrompt can extract more information than just the transcriptions. Code is available at https://github.com/Hertin/WavPrompt
Unsupervised Text-to-Speech Synthesis by Unsupervised Automatic Speech Recognition
Mar 29, 2022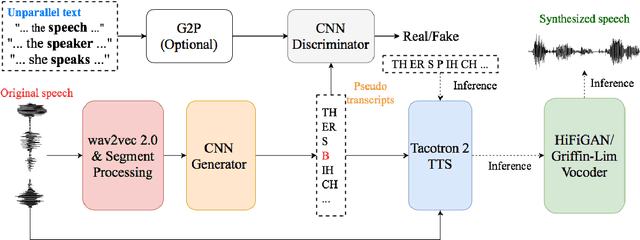

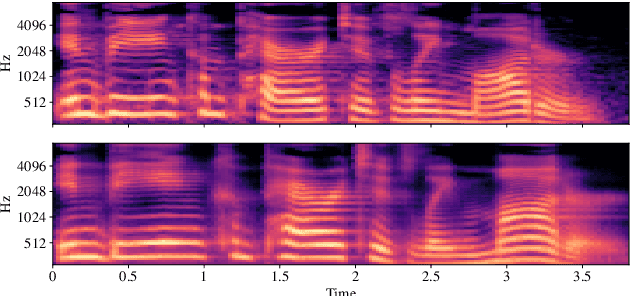
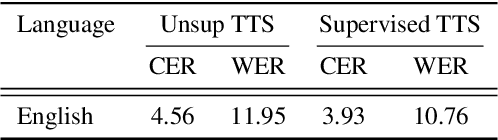
An unsupervised text-to-speech synthesis (TTS) system learns to generate the speech waveform corresponding to any written sentence in a language by observing: 1) a collection of untranscribed speech waveforms in that language; 2) a collection of texts written in that language without access to any transcribed speech. Developing such a system can significantly improve the availability of speech technology to languages without a large amount of parallel speech and text data. This paper proposes an unsupervised TTS system by leveraging recent advances in unsupervised automatic speech recognition (ASR). Our unsupervised system can achieve comparable performance to the supervised system in seven languages with about 10-20 hours of speech each. A careful study on the effect of text units and vocoders has also been conducted to better understand what factors may affect unsupervised TTS performance. The samples generated by our models can be found at https://cactuswiththoughts.github.io/UnsupTTS-Demo.
How to Robustify Black-Box ML Models? A Zeroth-Order Optimization Perspective
Mar 27, 2022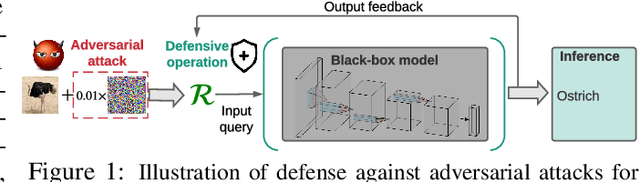
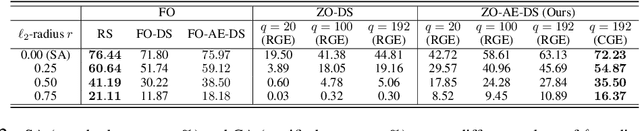
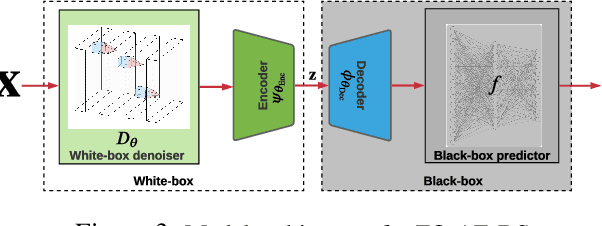
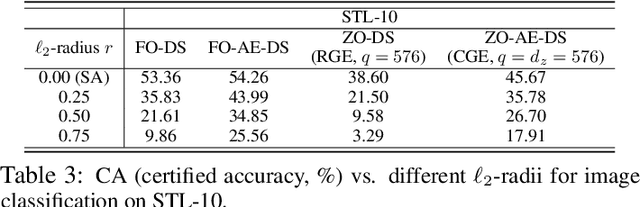
The lack of adversarial robustness has been recognized as an important issue for state-of-the-art machine learning (ML) models, e.g., deep neural networks (DNNs). Thereby, robustifying ML models against adversarial attacks is now a major focus of research. However, nearly all existing defense methods, particularly for robust training, made the white-box assumption that the defender has the access to the details of an ML model (or its surrogate alternatives if available), e.g., its architectures and parameters. Beyond existing works, in this paper we aim to address the problem of black-box defense: How to robustify a black-box model using just input queries and output feedback? Such a problem arises in practical scenarios, where the owner of the predictive model is reluctant to share model information in order to preserve privacy. To this end, we propose a general notion of defensive operation that can be applied to black-box models, and design it through the lens of denoised smoothing (DS), a first-order (FO) certified defense technique. To allow the design of merely using model queries, we further integrate DS with the zeroth-order (gradient-free) optimization. However, a direct implementation of zeroth-order (ZO) optimization suffers a high variance of gradient estimates, and thus leads to ineffective defense. To tackle this problem, we next propose to prepend an autoencoder (AE) to a given (black-box) model so that DS can be trained using variance-reduced ZO optimization. We term the eventual defense as ZO-AE-DS. In practice, we empirically show that ZO-AE- DS can achieve improved accuracy, certified robustness, and query complexity over existing baselines. And the effectiveness of our approach is justified under both image classification and image reconstruction tasks. Codes are available at https://github.com/damon-demon/Black-Box-Defense.
Adversarial Support Alignment
Mar 16, 2022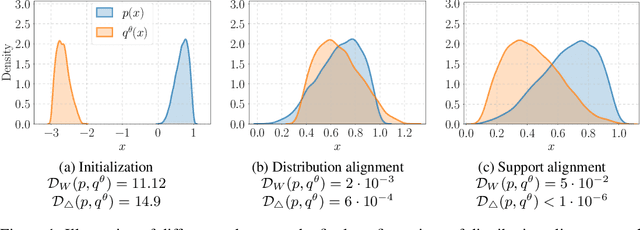
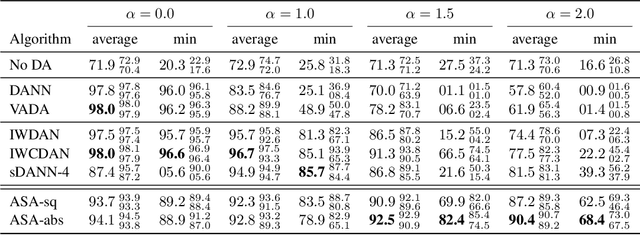
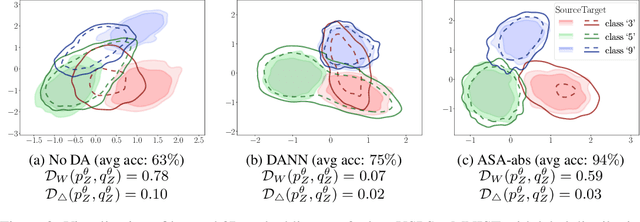
We study the problem of aligning the supports of distributions. Compared to the existing work on distribution alignment, support alignment does not require the densities to be matched. We propose symmetric support difference as a divergence measure to quantify the mismatch between supports. We show that select discriminators (e.g. discriminator trained for Jensen-Shannon divergence) are able to map support differences as support differences in their one-dimensional output space. Following this result, our method aligns supports by minimizing a symmetrized relaxed optimal transport cost in the discriminator 1D space via an adversarial process. Furthermore, we show that our approach can be viewed as a limit of existing notions of alignment by increasing transportation assignment tolerance. We quantitatively evaluate the method across domain adaptation tasks with shifts in label distributions. Our experiments show that the proposed method is more robust against these shifts than other alignment-based baselines.
Optimizer Amalgamation
Mar 15, 2022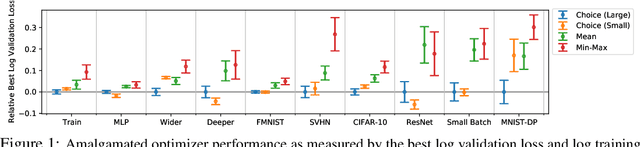
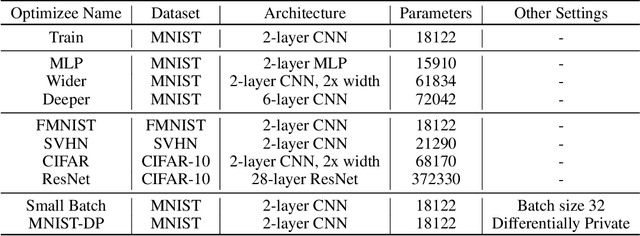
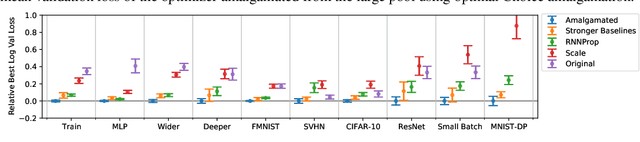
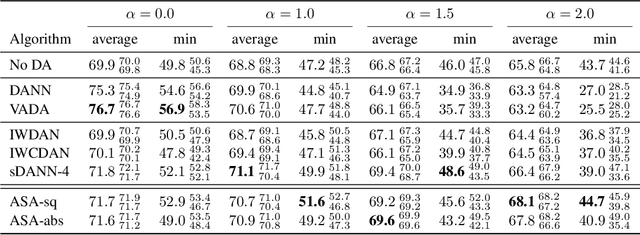
Selecting an appropriate optimizer for a given problem is of major interest for researchers and practitioners. Many analytical optimizers have been proposed using a variety of theoretical and empirical approaches; however, none can offer a universal advantage over other competitive optimizers. We are thus motivated to study a new problem named Optimizer Amalgamation: how can we best combine a pool of "teacher" optimizers into a single "student" optimizer that can have stronger problem-specific performance? In this paper, we draw inspiration from the field of "learning to optimize" to use a learnable amalgamation target. First, we define three differentiable amalgamation mechanisms to amalgamate a pool of analytical optimizers by gradient descent. Then, in order to reduce variance of the amalgamation process, we also explore methods to stabilize the amalgamation process by perturbing the amalgamation target. Finally, we present experiments showing the superiority of our amalgamated optimizer compared to its amalgamated components and learning to optimize baselines, and the efficacy of our variance reducing perturbations. Our code and pre-trained models are publicly available at http://github.com/VITA-Group/OptimizerAmalgamation.
Revisiting and Advancing Fast Adversarial Training Through The Lens of Bi-Level Optimization
Jan 25, 2022
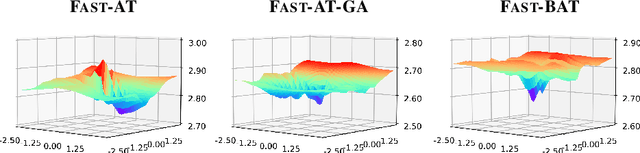
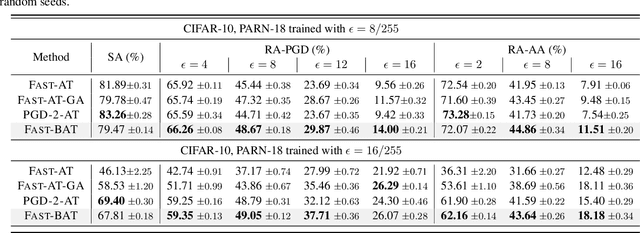
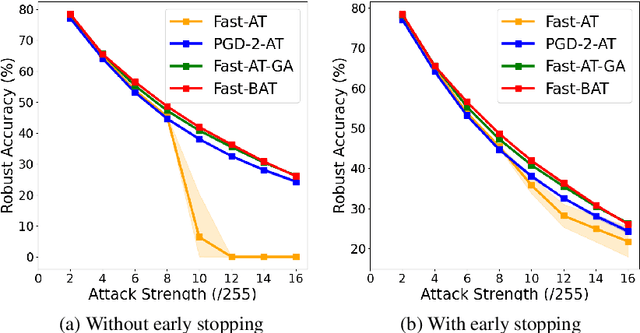
Adversarial training (AT) is a widely recognized defense mechanism to gain the robustness of deep neural networks against adversarial attacks. It is built on min-max optimization (MMO), where the minimizer (i.e., defender) seeks a robust model to minimize the worst-case training loss in the presence of adversarial examples crafted by the maximizer (i.e., attacker). However, the conventional MMO method makes AT hard to scale. Thus, Fast-AT and other recent algorithms attempt to simplify MMO by replacing its maximization step with the single gradient sign-based attack generation step. Although easy to implement, FAST-AT lacks theoretical guarantees, and its empirical performance is unsatisfactory due to the issue of robust catastrophic overfitting when training with strong adversaries. In this paper, we advance Fast-AT from the fresh perspective of bi-level optimization (BLO). We first show that the commonly-used Fast-AT is equivalent to using a stochastic gradient algorithm to solve a linearized BLO problem involving a sign operation. However, the discrete nature of the sign operation makes it difficult to understand the algorithm performance. Inspired by BLO, we design and analyze a new set of robust training algorithms termed Fast Bi-level AT (Fast-BAT), which effectively defends sign-based projected gradient descent (PGD) attacks without using any gradient sign method or explicit robust regularization. In practice, we show that our method yields substantial robustness improvements over multiple baselines across multiple models and datasets.
Understanding Interlocking Dynamics of Cooperative Rationalization
Oct 26, 2021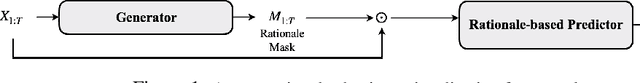
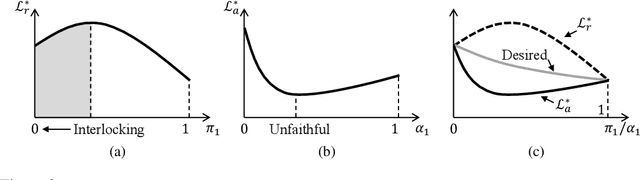
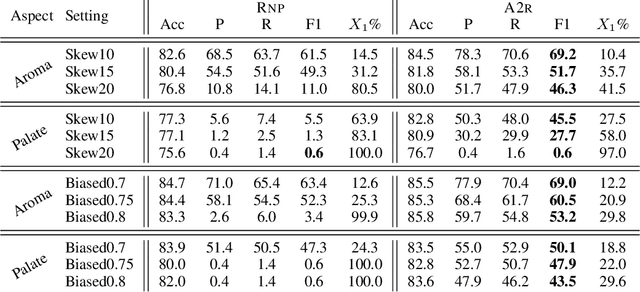
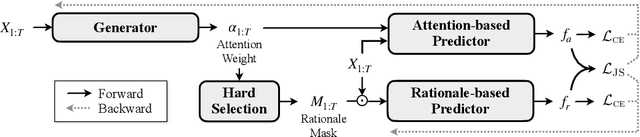
Selective rationalization explains the prediction of complex neural networks by finding a small subset of the input that is sufficient to predict the neural model output. The selection mechanism is commonly integrated into the model itself by specifying a two-component cascaded system consisting of a rationale generator, which makes a binary selection of the input features (which is the rationale), and a predictor, which predicts the output based only on the selected features. The components are trained jointly to optimize prediction performance. In this paper, we reveal a major problem with such cooperative rationalization paradigm -- model interlocking. Interlocking arises when the predictor overfits to the features selected by the generator thus reinforcing the generator's selection even if the selected rationales are sub-optimal. The fundamental cause of the interlocking problem is that the rationalization objective to be minimized is concave with respect to the generator's selection policy. We propose a new rationalization framework, called A2R, which introduces a third component into the architecture, a predictor driven by soft attention as opposed to selection. The generator now realizes both soft and hard attention over the features and these are fed into the two different predictors. While the generator still seeks to support the original predictor performance, it also minimizes a gap between the two predictors. As we will show theoretically, since the attention-based predictor exhibits a better convexity property, A2R can overcome the concavity barrier. Our experiments on two synthetic benchmarks and two real datasets demonstrate that A2R can significantly alleviate the interlock problem and find explanations that better align with human judgments. We release our code at https://github.com/Gorov/Understanding_Interlocking.