 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge1st Place Solution for ECCV 2022 OOD-CV Challenge Image Classification Track
Jan 12, 2023OOD-CV challenge is an out-of-distribution generalization task. In this challenge, our core solution can be summarized as that Noisy Label Learning Is A Strong Test-Time Domain Adaptation Optimizer. Briefly speaking, our main pipeline can be divided into two stages, a pre-training stage for domain generalization and a test-time training stage for domain adaptation. We only exploit labeled source data in the pre-training stage and only exploit unlabeled target data in the test-time training stage. In the pre-training stage, we propose a simple yet effective Mask-Level Copy-Paste data augmentation strategy to enhance out-of-distribution generalization ability so as to resist shape, pose, context, texture, occlusion, and weather domain shifts in this challenge. In the test-time training stage, we use the pre-trained model to assign noisy label for the unlabeled target data, and propose a Label-Periodically-Updated DivideMix method for noisy label learning. After integrating Test-Time Augmentation and Model Ensemble strategies, our solution ranks the first place on the Image Classification Leaderboard of the OOD-CV Challenge. Code will be released in https://github.com/hikvision-research/OOD-CV.
1st Place Solution for ECCV 2022 OOD-CV Challenge Object Detection Track
Jan 12, 2023



OOD-CV challenge is an out-of-distribution generalization task. To solve this problem in object detection track, we propose a simple yet effective Generalize-then-Adapt (G&A) framework, which is composed of a two-stage domain generalization part and a one-stage domain adaptation part. The domain generalization part is implemented by a Supervised Model Pretraining stage using source data for model warm-up and a Weakly Semi-Supervised Model Pretraining stage using both source data with box-level label and auxiliary data (ImageNet-1K) with image-level label for performance boosting. The domain adaptation part is implemented as a Source-Free Domain Adaptation paradigm, which only uses the pre-trained model and the unlabeled target data to further optimize in a self-supervised training manner. The proposed G&A framework help us achieve the first place on the object detection leaderboard of the OOD-CV challenge. Code will be released in https://github.com/hikvision-research/OOD-CV.
NeRF-Gaze: A Head-Eye Redirection Parametric Model for Gaze Estimation
Dec 30, 2022



Gaze estimation is the fundamental basis for many visual tasks. Yet, the high cost of acquiring gaze datasets with 3D annotations hinders the optimization and application of gaze estimation models. In this work, we propose a novel Head-Eye redirection parametric model based on Neural Radiance Field, which allows dense gaze data generation with view consistency and accurate gaze direction. Moreover, our head-eye redirection parametric model can decouple the face and eyes for separate neural rendering, so it can achieve the purpose of separately controlling the attributes of the face, identity, illumination, and eye gaze direction. Thus diverse 3D-aware gaze datasets could be obtained by manipulating the latent code belonging to different face attributions in an unsupervised manner. Extensive experiments on several benchmarks demonstrate the effectiveness of our method in domain generalization and domain adaptation for gaze estimation tasks.
Rate-Distortion Optimized Post-Training Quantization for Learned Image Compression
Nov 05, 2022Quantizing floating-point neural network to its fixed-point representation is crucial for Learned Image Compression (LIC) because it ensures the decoding consistency for interoperability and reduces space-time complexity for implementation. Existing solutions often have to retrain the network for model quantization which is time consuming and impractical. This work suggests the use of Post-Training Quantization (PTQ) to directly process pretrained, off-the-shelf LIC models. We theoretically prove that minimizing the mean squared error (MSE) in PTQ is sub-optimal for compression task and thus develop a novel Rate-Distortion (R-D) Optimized PTQ (RDO-PTQ) to best retain the compression performance. Such RDO-PTQ just needs to compress few images (e.g., 10) to optimize the transformation of weight, bias, and activation of underlying LIC model from its native 32-bit floating-point (FP32) format to 8-bit fixed-point (INT8) precision for fixed-point inference onwards. Experiments reveal outstanding efficiency of the proposed method on different LICs, showing the closest coding performance to their floating-point counterparts. And, our method is a lightweight and plug-and-play approach without any need of model retraining which is attractive to practitioners.
Attention Diversification for Domain Generalization
Oct 09, 2022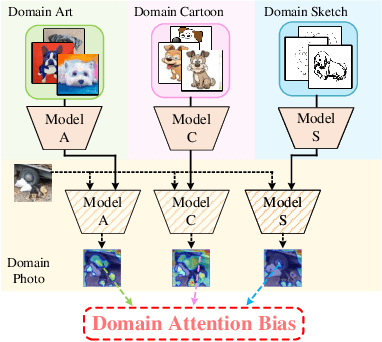
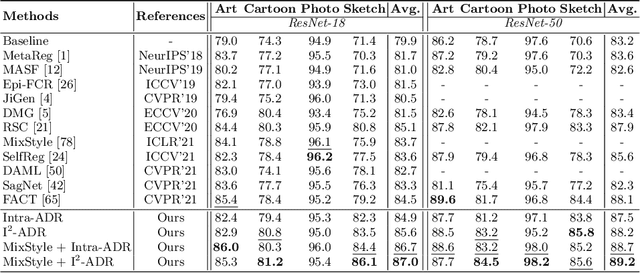
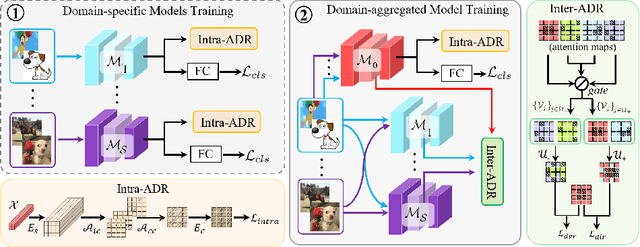
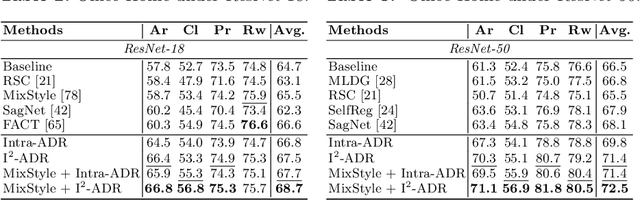
Convolutional neural networks (CNNs) have demonstrated gratifying results at learning discriminative features. However, when applied to unseen domains, state-of-the-art models are usually prone to errors due to domain shift. After investigating this issue from the perspective of shortcut learning, we find the devils lie in the fact that models trained on different domains merely bias to different domain-specific features yet overlook diverse task-related features. Under this guidance, a novel Attention Diversification framework is proposed, in which Intra-Model and Inter-Model Attention Diversification Regularization are collaborated to reassign appropriate attention to diverse task-related features. Briefly, Intra-Model Attention Diversification Regularization is equipped on the high-level feature maps to achieve in-channel discrimination and cross-channel diversification via forcing different channels to pay their most salient attention to different spatial locations. Besides, Inter-Model Attention Diversification Regularization is proposed to further provide task-related attention diversification and domain-related attention suppression, which is a paradigm of "simulate, divide and assemble": simulate domain shift via exploiting multiple domain-specific models, divide attention maps into task-related and domain-related groups, and assemble them within each group respectively to execute regularization. Extensive experiments and analyses are conducted on various benchmarks to demonstrate that our method achieves state-of-the-art performance over other competing methods. Code is available at https://github.com/hikvision-research/DomainGeneralization.
* ECCV 2022. Code available at https://github.com/hikvision-research/DomainGeneralization
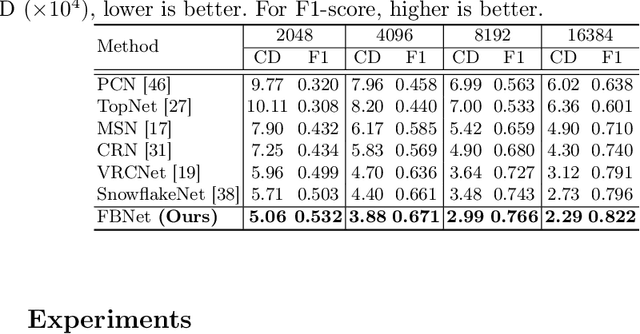
Point Cloud Upsampling via Cascaded Refinement Network
Oct 08, 2022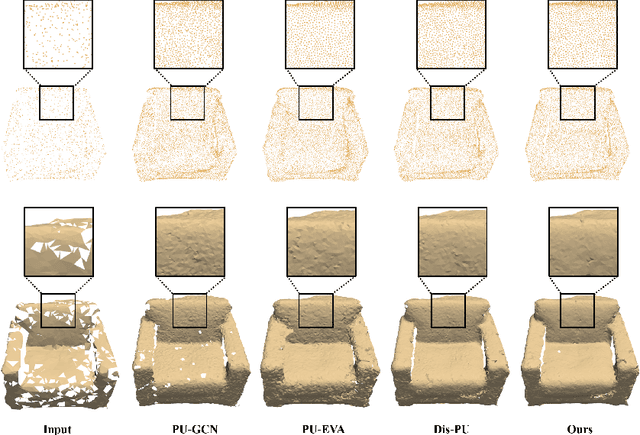
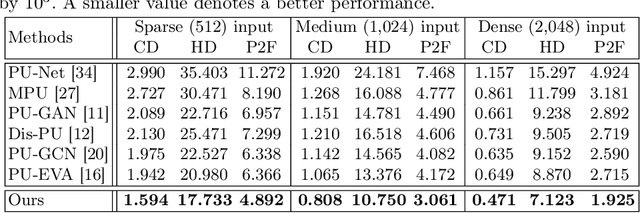
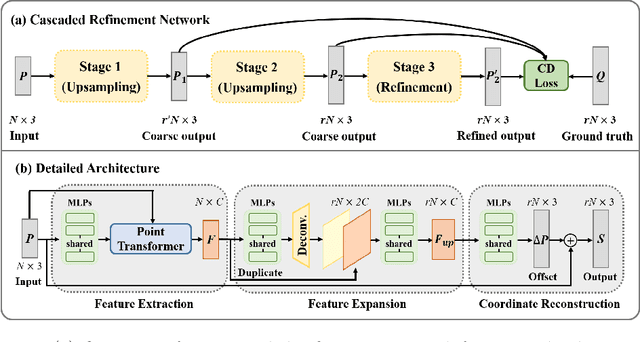
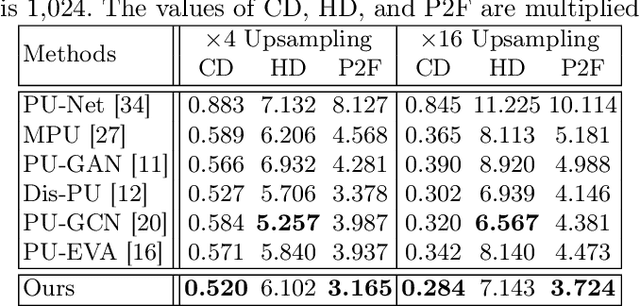
Point cloud upsampling focuses on generating a dense, uniform and proximity-to-surface point set. Most previous approaches accomplish these objectives by carefully designing a single-stage network, which makes it still challenging to generate a high-fidelity point distribution. Instead, upsampling point cloud in a coarse-to-fine manner is a decent solution. However, existing coarse-to-fine upsampling methods require extra training strategies, which are complicated and time-consuming during the training. In this paper, we propose a simple yet effective cascaded refinement network, consisting of three generation stages that have the same network architecture but achieve different objectives. Specifically, the first two upsampling stages generate the dense but coarse points progressively, while the last refinement stage further adjust the coarse points to a better position. To mitigate the learning conflicts between multiple stages and decrease the difficulty of regressing new points, we encourage each stage to predict the point offsets with respect to the input shape. In this manner, the proposed cascaded refinement network can be easily optimized without extra learning strategies. Moreover, we design a transformer-based feature extraction module to learn the informative global and local shape context. In inference phase, we can dynamically adjust the model efficiency and effectiveness, depending on the available computational resources. Extensive experiments on both synthetic and real-scanned datasets demonstrate that the proposed approach outperforms the existing state-of-the-art methods.
Multi-Scale Wavelet Transformer for Face Forgery Detection
Oct 08, 2022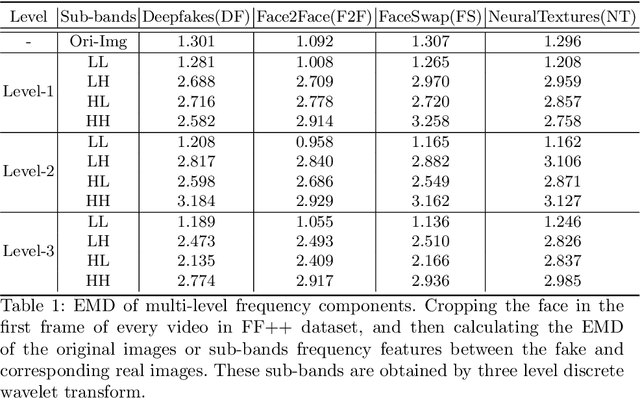


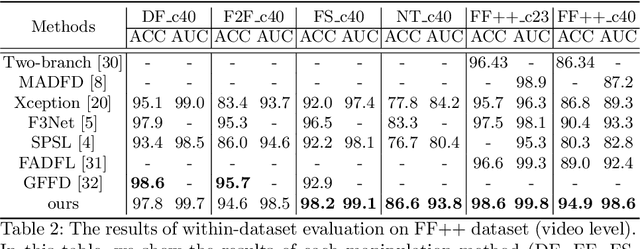
Currently, many face forgery detection methods aggregate spatial and frequency features to enhance the generalization ability and gain promising performance under the cross-dataset scenario. However, these methods only leverage one level frequency information which limits their expressive ability. To overcome these limitations, we propose a multi-scale wavelet transformer framework for face forgery detection. Specifically, to take full advantage of the multi-scale and multi-frequency wavelet representation, we gradually aggregate the multi-scale wavelet representation at different stages of the backbone network. To better fuse the frequency feature with the spatial features, frequency-based spatial attention is designed to guide the spatial feature extractor to concentrate more on forgery traces. Meanwhile, cross-modality attention is proposed to fuse the frequency features with the spatial features. These two attention modules are calculated through a unified transformer block for efficiency. A wide variety of experiments demonstrate that the proposed method is efficient and effective for both within and cross datasets.
FBNet: Feedback Network for Point Cloud Completion
Oct 08, 2022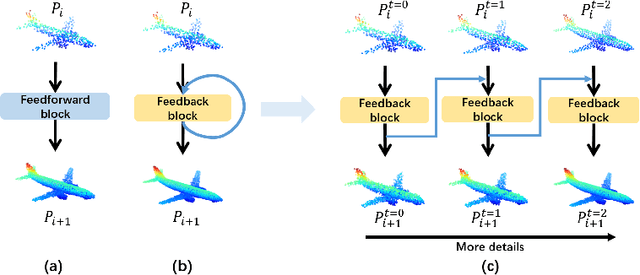
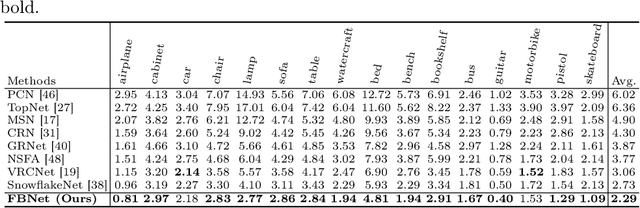
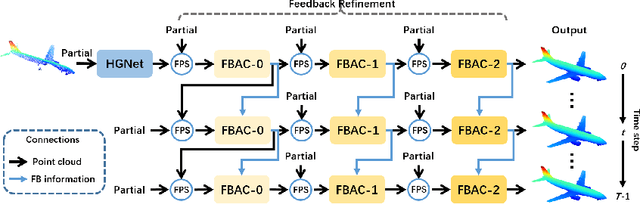
The rapid development of point cloud learning has driven point cloud completion into a new era. However, the information flows of most existing completion methods are solely feedforward, and high-level information is rarely reused to improve low-level feature learning. To this end, we propose a novel Feedback Network (FBNet) for point cloud completion, in which present features are efficiently refined by rerouting subsequent fine-grained ones. Firstly, partial inputs are fed to a Hierarchical Graph-based Network (HGNet) to generate coarse shapes. Then, we cascade several Feedback-Aware Completion (FBAC) Blocks and unfold them across time recurrently. Feedback connections between two adjacent time steps exploit fine-grained features to improve present shape generations. The main challenge of building feedback connections is the dimension mismatching between present and subsequent features. To address this, the elaborately designed point Cross Transformer exploits efficient information from feedback features via cross attention strategy and then refines present features with the enhanced feedback features. Quantitative and qualitative experiments on several datasets demonstrate the superiority of proposed FBNet compared to state-of-the-art methods on point completion task.
Unified Normalization for Accelerating and Stabilizing Transformers
Aug 02, 2022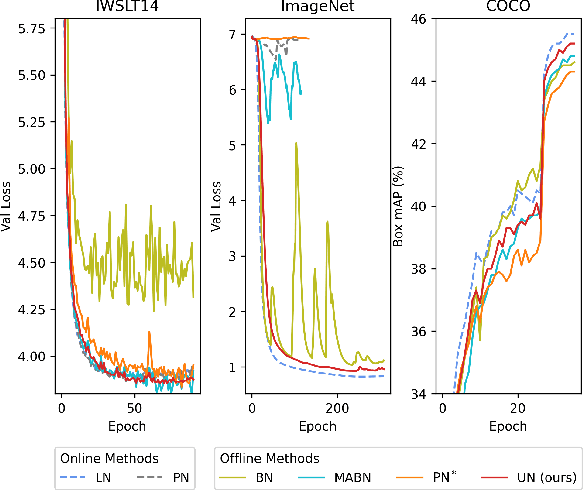
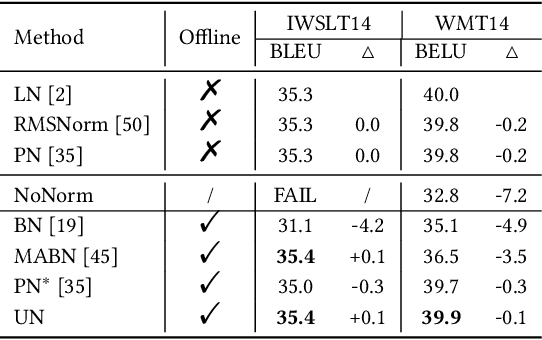
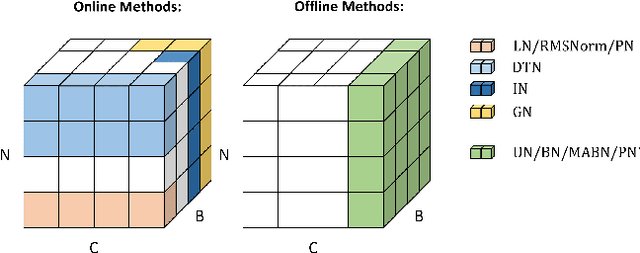
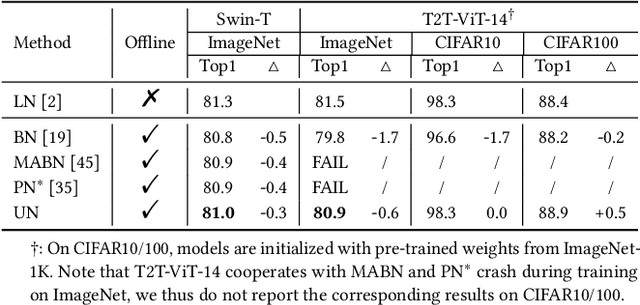
Solid results from Transformers have made them prevailing architectures in various natural language and vision tasks. As a default component in Transformers, Layer Normalization (LN) normalizes activations within each token to boost the robustness. However, LN requires on-the-fly statistics calculation in inference as well as division and square root operations, leading to inefficiency on hardware. What is more, replacing LN with other hardware-efficient normalization schemes (e.g., Batch Normalization) results in inferior performance, even collapse in training. We find that this dilemma is caused by abnormal behaviors of activation statistics, including large fluctuations over iterations and extreme outliers across layers. To tackle these issues, we propose Unified Normalization (UN), which can speed up the inference by being fused with other linear operations and achieve comparable performance on par with LN. UN strives to boost performance by calibrating the activation and gradient statistics with a tailored fluctuation smoothing strategy. Meanwhile, an adaptive outlier filtration strategy is applied to avoid collapse in training whose effectiveness is theoretically proved and experimentally verified in this paper. We demonstrate that UN can be an efficient drop-in alternative to LN by conducting extensive experiments on language and vision tasks. Besides, we evaluate the efficiency of our method on GPU. Transformers equipped with UN enjoy about 31% inference speedup and nearly 18% memory reduction. Code will be released at https://github.com/hikvision-research/Unified-Normalization.
Dynamic Low-Resolution Distillation for Cost-Efficient End-to-End Text Spotting
Jul 15, 2022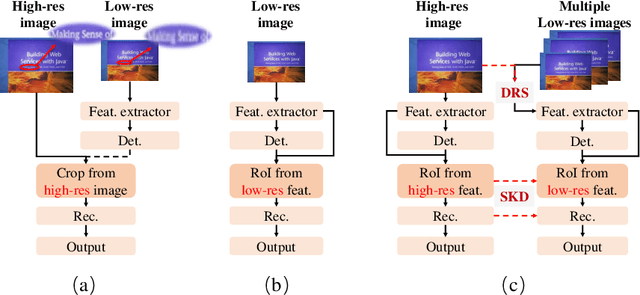
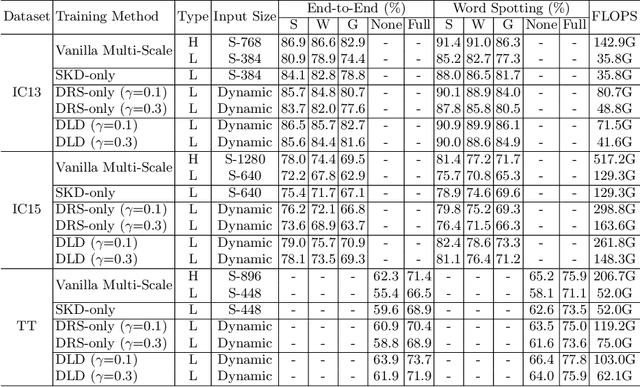
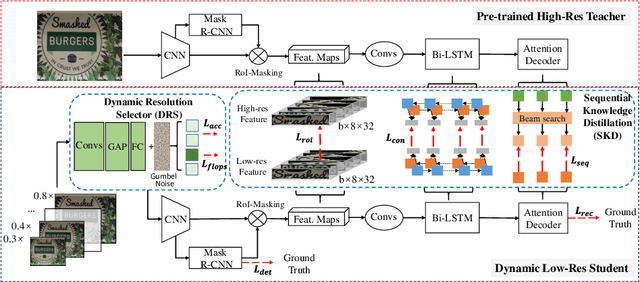
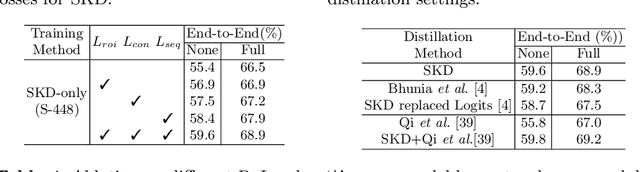
End-to-end text spotting has attached great attention recently due to its benefits on global optimization and high maintainability for real applications. However, the input scale has always been a tough trade-off since recognizing a small text instance usually requires enlarging the whole image, which brings high computational costs. In this paper, to address this problem, we propose a novel cost-efficient Dynamic Low-resolution Distillation (DLD) text spotting framework, which aims to infer images in different small but recognizable resolutions and achieve a better balance between accuracy and efficiency. Concretely, we adopt a resolution selector to dynamically decide the input resolutions for different images, which is constraint by both inference accuracy and computational cost. Another sequential knowledge distillation strategy is conducted on the text recognition branch, making the low-res input obtains comparable performance to a high-res image. The proposed method can be optimized end-to-end and adopted in any current text spotting framework to improve the practicability. Extensive experiments on several text spotting benchmarks show that the proposed method vastly improves the usability of low-res models. The code is available at https://github.com/hikopensource/DAVAR-Lab-OCR/.