 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeoEdit: Local Frames for Fast, Training-Free On-Manifold Editing in Diffusion Models
Apr 27, 2026Diffusion models are a leading paradigm for data generation, but training-free editing typically re-runs the full denoising trajectory for every edit strength, making iterative refinement expensive. To address this issue, we instead edit near the data manifold, where small local updates can replace repeated re-synthesis. To enable this, we estimate a local manifold tangent space directly from perturbed samples and prove that this sample-based estimator closely approximates the true tangent. Building on this guarantee, we devise a Jacobian-free algorithm that constructs a tangent frame via small perturbations to the initial noise and alternates small tangent moves with diffusion-based projections. Updates within this frame follow principled on-manifold directions while suppressing off-manifold drift, enabling fine-grained edits without full re-diffusion or additional training. Edit strength is controlled by the number of steps for rapid, continuous adjustments that preserve fidelity and plug into existing samplers. Empirically, the resulting tangent directions yield smooth, semantic unsupervised traversals and effective CLIP-guided optimization, demonstrating practical interactive continuous editing.
Robust Cross-View Geo-Localization via Content-Viewpoint Disentanglement
May 17, 2025Cross-view geo-localization (CVGL) aims to match images of the same geographic location captured from different perspectives, such as drones and satellites. Despite recent advances, CVGL remains highly challenging due to significant appearance changes and spatial distortions caused by viewpoint variations. Existing methods typically assume that cross-view images can be directly aligned within a shared feature space by maximizing feature similarity through contrastive learning. Nonetheless, this assumption overlooks the inherent conflicts induced by viewpoint discrepancies, resulting in extracted features containing inconsistent information that hinders precise localization. In this study, we take a manifold learning perspective and model the feature space of cross-view images as a composite manifold jointly governed by content and viewpoint information. Building upon this insight, we propose $\textbf{CVD}$, a new CVGL framework that explicitly disentangles $\textit{content}$ and $\textit{viewpoint}$ factors. To promote effective disentanglement, we introduce two constraints: $\textit{(i)}$ An intra-view independence constraint, which encourages statistical independence between the two factors by minimizing their mutual information. $\textit{(ii)}$ An inter-view reconstruction constraint that reconstructs each view by cross-combining $\textit{content}$ and $\textit{viewpoint}$ from paired images, ensuring factor-specific semantics are preserved. As a plug-and-play module, CVD can be seamlessly integrated into existing geo-localization pipelines. Extensive experiments on four benchmarks, i.e., University-1652, SUES-200, CVUSA, and CVACT, demonstrate that CVD consistently improves both localization accuracy and generalization across multiple baselines.
FBNet: Feedback Network for Point Cloud Completion
Oct 08, 2022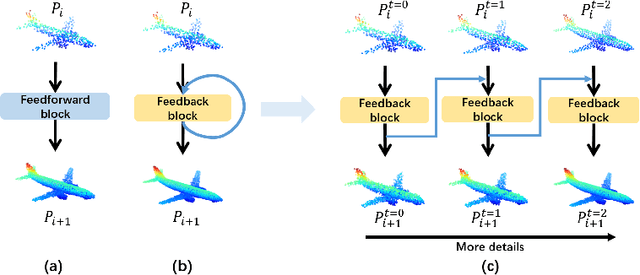
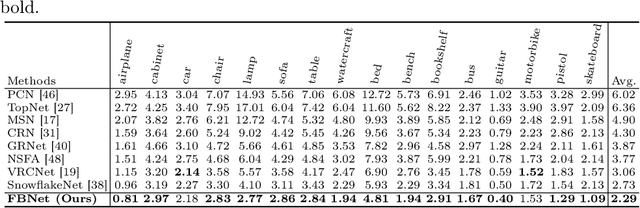
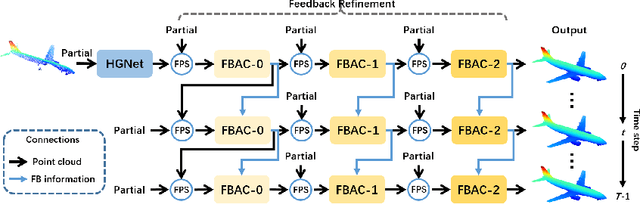
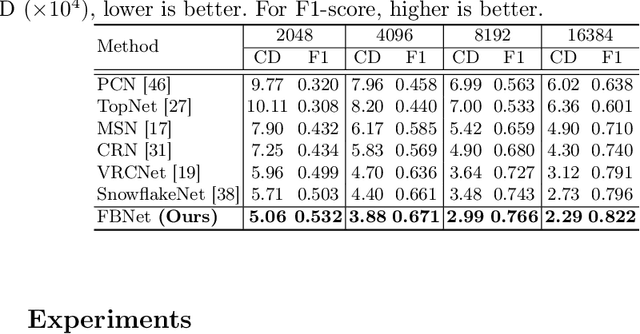
The rapid development of point cloud learning has driven point cloud completion into a new era. However, the information flows of most existing completion methods are solely feedforward, and high-level information is rarely reused to improve low-level feature learning. To this end, we propose a novel Feedback Network (FBNet) for point cloud completion, in which present features are efficiently refined by rerouting subsequent fine-grained ones. Firstly, partial inputs are fed to a Hierarchical Graph-based Network (HGNet) to generate coarse shapes. Then, we cascade several Feedback-Aware Completion (FBAC) Blocks and unfold them across time recurrently. Feedback connections between two adjacent time steps exploit fine-grained features to improve present shape generations. The main challenge of building feedback connections is the dimension mismatching between present and subsequent features. To address this, the elaborately designed point Cross Transformer exploits efficient information from feedback features via cross attention strategy and then refines present features with the enhanced feedback features. Quantitative and qualitative experiments on several datasets demonstrate the superiority of proposed FBNet compared to state-of-the-art methods on point completion task.