 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuo Vadis, Visual In-Context Learning? A Unified Benchmark Across Domains and Tasks
Jun 09, 2026Visual in-context learning has been proposed as a pathway towards dynamic models that can generate predictions based on a provided context and thereby can adapt to new vision tasks at test-time. Yet, the evaluation of the adaptation capabilities of these models has been limited to narrow setups that mainly mirror tasks or image domains from pre-training for which real adaptation is not required. We address this gap by constructing a broad Visual In-Context BEnchmark (VIBE) with a focus on diverse imaging domains and a wide range of tasks. With this, we are able to get a much clearer picture of the adaptive capabilities of visual in-context models when faced with new image- and task distributions. We stress test six models on $14$ datasets and $12$ tasks (in total, we explore $106$ dataset-task combinations) and compare them under a unified, reproducible evaluation protocol, in an one-shot setting. Our evaluation uncovers key insights on the state of visual in-context learning, including limitations, systematic failure modes and promising directions. To foster broader evaluation, we will openly release our VIBE toolkit.
IMPACT-CYCLE: A Contract-Based Multi-Agent System for Claim-Level Supervisory Correction of Long-Video Semantic Memory
Apr 22, 2026Correcting errors in long-video understanding is disproportionately costly: existing multimodal pipelines produce opaque, end-to-end outputs that expose no intermediate state for inspection, forcing annotators to revisit raw video and reconstruct temporal logic from scratch. The core bottleneck is not generation quality alone, but the absence of a supervisory interface through which human effort can be proportional to the scope of each error. We present IMPACT-CYCLE, a supervisory multi-agent system that reformulates long-video understanding as iterative claim-level maintenance of a shared semantic memory -- a structured, versioned state encoding typed claims, a claim dependency graph, and a provenance log. Role-specialized agents operating under explicit authority contracts decompose verification into local object-relation correctness, cross-temporal consistency, and global semantic coherence, with corrections confined to structurally dependent claims. When automated evidence is insufficient, the system escalates to human arbitration as the supervisory authority with final override rights; dependency-closure re-verification then ensures correction cost remains proportional to error scope. Experiments on VidOR show substantially improved downstream reasoning (VQA: 0.71 to 0.79) and a 4.8x reduction in human arbitration cost, with workload significantly lower than manual annotation. Code will be released at https://github.com/MKong17/IMPACT_CYCLE.
Rethinking Video Human-Object Interaction: Set Prediction over Time for Unified Detection and Anticipation
Apr 12, 2026Video-based human-object interaction (HOI) understanding requires both detecting ongoing interactions and anticipating their future evolution. However, existing methods usually treat anticipation as a downstream forecasting task built on externally constructed human-object pairs, limiting joint reasoning between detection and prediction. In addition, sparse keyframe annotations in current benchmarks can temporally misalign nominal future labels from actual future dynamics, reducing the reliability of anticipation evaluation. To address these issues, we introduce DETAnt-HOI, a temporally corrected benchmark derived from VidHOI and Action Genome for more faithful multi-horizon evaluation, and HOI-DA, a pair-centric framework that jointly performs subject-object localization, present HOI detection, and future anticipation by modeling future interactions as residual transitions from current pair states. Experiments show consistent improvements in both detection and anticipation, with larger gains at longer horizons. Our results highlight that anticipation is most effective when learned jointly with detection as a structural constraint on pair-level video representation learning. Benchmark and code will be publicly available.
Towards Multi-Source Domain Generalization for Sleep Staging with Noisy Labels
Apr 11, 2026Automatic sleep staging is a multimodal learning problem involving heterogeneous physiological signals such as EEG and EOG, which often suffer from domain shifts across institutions, devices, and populations. In practice, these data are also affected by noisy annotations, yet label-noise-robust multi-source domain generalization remains underexplored. We present the first benchmark for Noisy Labels in Multi-Source Domain-Generalized Sleep Staging (NL-DGSS) and show that existing noisy-label learning methods degrade substantially when domain shifts and label noise coexist. To address this challenge, we propose FF-TRUST, a domain-invariant multimodal sleep staging framework with Joint Time-Frequency Early Learning Regularization (JTF-ELR). By jointly exploiting temporal and spectral consistency together with confidence-diversity regularization, FF-TRUST improves robustness under noisy supervision. Experiments on five public datasets demonstrate consistent state-of-the-art performance under diverse symmetric and asymmetric noise settings. The benchmark and code will be made publicly available at https://github.com/KNWang970918/FF-TRUST.git.
More than the Sum: Panorama-Language Models for Adverse Omni-Scenes
Mar 10, 2026Existing vision-language models (VLMs) are tailored for pinhole imagery, stitching multiple narrow field-of-view inputs to piece together a complete omni-scene understanding. Yet, such multi-view perception overlooks the holistic spatial and contextual relationships that a single panorama inherently preserves. In this work, we introduce the Panorama-Language Modeling (PLM)paradigm, a unified $360^\circ$ vision-language reasoning that is more than the sum of its pinhole counterparts. Besides, we present PanoVQA, a large-scale panoramic VQA dataset that involves adverse omni-scenes, enabling comprehensive reasoning under object occlusions and driving accidents. To establish a foundation for PLM, we develop a plug-and-play panoramic sparse attention module that allows existing pinhole-based VLMs to process equirectangular panoramas without retraining. Extensive experiments demonstrate that our PLM achieves superior robustness and holistic reasoning under challenging omni-scenes, yielding understanding greater than the sum of its narrow parts. Project page: https://github.com/InSAI-Lab/PanoVQA.
SGR3 Model: Scene Graph Retrieval-Reasoning Model in 3D
Mar 04, 20263D scene graphs provide a structured representation of object entities and their relationships, enabling high-level interpretation and reasoning for robots while remaining intuitively understandable to humans. Existing approaches for 3D scene graph generation typically combine scene reconstruction with graph neural networks (GNNs). However, such pipelines require multi-modal data that may not always be available, and their reliance on heuristic graph construction can constrain the prediction of relationship triplets. In this work, we introduce a Scene Graph Retrieval-Reasoning Model in 3D (SGR3 Model), a training-free framework that leverages multi-modal large language models (MLLMs) with retrieval-augmented generation (RAG) for semantic scene graph generation. SGR3 Model bypasses the need for explicit 3D reconstruction. Instead, it enhances relational reasoning by incorporating semantically aligned scene graphs retrieved via a ColPali-style cross-modal framework. To improve retrieval robustness, we further introduce a weighted patch-level similarity selection mechanism that mitigates the negative impact of blurry or semantically uninformative regions. Experiments demonstrate that SGR3 Model achieves competitive performance compared to training-free baselines and on par with GNN-based expert models. Moreover, an ablation study on the retrieval module and knowledge base scale reveals that retrieved external information is explicitly integrated into the token generation process, rather than being implicitly internalized through abstraction.
MICA: Multi-Agent Industrial Coordination Assistant
Sep 17, 2025Industrial workflows demand adaptive and trustworthy assistance that can operate under limited computing, connectivity, and strict privacy constraints. In this work, we present MICA (Multi-Agent Industrial Coordination Assistant), a perception-grounded and speech-interactive system that delivers real-time guidance for assembly, troubleshooting, part queries, and maintenance. MICA coordinates five role-specialized language agents, audited by a safety checker, to ensure accurate and compliant support. To achieve robust step understanding, we introduce Adaptive Step Fusion (ASF), which dynamically blends expert reasoning with online adaptation from natural speech feedback. Furthermore, we establish a new multi-agent coordination benchmark across representative task categories and propose evaluation metrics tailored to industrial assistance, enabling systematic comparison of different coordination topologies. Our experiments demonstrate that MICA consistently improves task success, reliability, and responsiveness over baseline structures, while remaining deployable on practical offline hardware. Together, these contributions highlight MICA as a step toward deployable, privacy-preserving multi-agent assistants for dynamic factory environments. The source code will be made publicly available at https://github.com/Kratos-Wen/MICA.
Hallucinating 360°: Panoramic Street-View Generation via Local Scenes Diffusion and Probabilistic Prompting
Jul 09, 2025



Panoramic perception holds significant potential for autonomous driving, enabling vehicles to acquire a comprehensive 360{\deg} surround view in a single shot. However, autonomous driving is a data-driven task. Complete panoramic data acquisition requires complex sampling systems and annotation pipelines, which are time-consuming and labor-intensive. Although existing street view generation models have demonstrated strong data regeneration capabilities, they can only learn from the fixed data distribution of existing datasets and cannot achieve high-quality, controllable panoramic generation. In this paper, we propose the first panoramic generation method Percep360 for autonomous driving. Percep360 enables coherent generation of panoramic data with control signals based on the stitched panoramic data. Percep360 focuses on two key aspects: coherence and controllability. Specifically, to overcome the inherent information loss caused by the pinhole sampling process, we propose the Local Scenes Diffusion Method (LSDM). LSDM reformulates the panorama generation as a spatially continuous diffusion process, bridging the gaps between different data distributions. Additionally, to achieve the controllable generation of panoramic images, we propose a Probabilistic Prompting Method (PPM). PPM dynamically selects the most relevant control cues, enabling controllable panoramic image generation. We evaluate the effectiveness of the generated images from three perspectives: image quality assessment (i.e., no-reference and with reference), controllability, and their utility in real-world Bird's Eye View (BEV) segmentation. Notably, the generated data consistently outperforms the original stitched images in no-reference quality metrics and enhances downstream perception models. The source code will be publicly available at https://github.com/Bryant-Teng/Percep360.
Tuning LLMs by RAG Principles: Towards LLM-native Memory
Mar 20, 2025



Memory, additional information beyond the training of large language models (LLMs), is crucial to various real-world applications, such as personal assistant. The two mainstream solutions to incorporate memory into the generation process are long-context LLMs and retrieval-augmented generation (RAG). In this paper, we first systematically compare these two types of solutions on three renovated/new datasets and show that (1) long-context solutions, although more expensive, shall be easier to capture the big picture and better answer queries which require considering the memory as a whole; and (2) when the queries concern specific information, RAG solutions shall be more competitive especially when the keywords can be explicitly matched. Therefore, we propose a novel method RAG-Tuned-LLM which fine-tunes a relative small (e.g., 7B) LLM using the data generated following the RAG principles, so it can combine the advantages of both solutions. Extensive experiments on three datasets demonstrate that RAG-Tuned-LLM can beat long-context LLMs and RAG methods across a wide range of query types.
AI-native Memory 2.0: Second Me
Mar 11, 2025


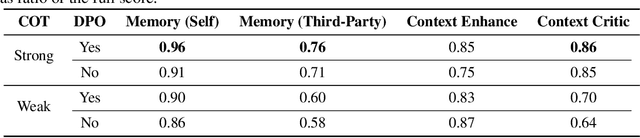
Human interaction with the external world fundamentally involves the exchange of personal memory, whether with other individuals, websites, applications, or, in the future, AI agents. A significant portion of this interaction is redundant, requiring users to repeatedly provide the same information across different contexts. Existing solutions, such as browser-stored credentials, autofill mechanisms, and unified authentication systems, have aimed to mitigate this redundancy by serving as intermediaries that store and retrieve commonly used user data. The advent of large language models (LLMs) presents an opportunity to redefine memory management through an AI-native paradigm: SECOND ME. SECOND ME acts as an intelligent, persistent memory offload system that retains, organizes, and dynamically utilizes user-specific knowledge. By serving as an intermediary in user interactions, it can autonomously generate context-aware responses, prefill required information, and facilitate seamless communication with external systems, significantly reducing cognitive load and interaction friction. Unlike traditional memory storage solutions, SECOND ME extends beyond static data retention by leveraging LLM-based memory parameterization. This enables structured organization, contextual reasoning, and adaptive knowledge retrieval, facilitating a more systematic and intelligent approach to memory management. As AI-driven personal agents like SECOND ME become increasingly integrated into digital ecosystems, SECOND ME further represents a critical step toward augmenting human-world interaction with persistent, contextually aware, and self-optimizing memory systems. We have open-sourced the fully localizable deployment system at GitHub: https://github.com/Mindverse/Second-Me.