 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQwenLong-L1.5: Post-Training Recipe for Long-Context Reasoning and Memory Management
Dec 15, 2025We introduce QwenLong-L1.5, a model that achieves superior long-context reasoning capabilities through systematic post-training innovations. The key technical breakthroughs of QwenLong-L1.5 are as follows: (1) Long-Context Data Synthesis Pipeline: We develop a systematic synthesis framework that generates challenging reasoning tasks requiring multi-hop grounding over globally distributed evidence. By deconstructing documents into atomic facts and their underlying relationships, and then programmatically composing verifiable reasoning questions, our approach creates high-quality training data at scale, moving substantially beyond simple retrieval tasks to enable genuine long-range reasoning capabilities. (2) Stabilized Reinforcement Learning for Long-Context Training: To overcome the critical instability in long-context RL, we introduce task-balanced sampling with task-specific advantage estimation to mitigate reward bias, and propose Adaptive Entropy-Controlled Policy Optimization (AEPO) that dynamically regulates exploration-exploitation trade-offs. (3) Memory-Augmented Architecture for Ultra-Long Contexts: Recognizing that even extended context windows cannot accommodate arbitrarily long sequences, we develop a memory management framework with multi-stage fusion RL training that seamlessly integrates single-pass reasoning with iterative memory-based processing for tasks exceeding 4M tokens. Based on Qwen3-30B-A3B-Thinking, QwenLong-L1.5 achieves performance comparable to GPT-5 and Gemini-2.5-Pro on long-context reasoning benchmarks, surpassing its baseline by 9.90 points on average. On ultra-long tasks (1M~4M tokens), QwenLong-L1.5's memory-agent framework yields a 9.48-point gain over the agent baseline. Additionally, the acquired long-context reasoning ability translates to enhanced performance in general domains like scientific reasoning, memory tool using, and extended dialogue.
WebWeaver: Structuring Web-Scale Evidence with Dynamic Outlines for Open-Ended Deep Research
Sep 16, 2025



This paper tackles open-ended deep research (OEDR), a complex challenge where AI agents must synthesize vast web-scale information into insightful reports. Current approaches are plagued by dual-fold limitations: static research pipelines that decouple planning from evidence acquisition and one-shot generation paradigms that easily suffer from long-context failure issues like "loss in the middle" and hallucinations. To address these challenges, we introduce WebWeaver, a novel dual-agent framework that emulates the human research process. The planner operates in a dynamic cycle, iteratively interleaving evidence acquisition with outline optimization to produce a comprehensive, source-grounded outline linking to a memory bank of evidence. The writer then executes a hierarchical retrieval and writing process, composing the report section by section. By performing targeted retrieval of only the necessary evidence from the memory bank for each part, it effectively mitigates long-context issues. Our framework establishes a new state-of-the-art across major OEDR benchmarks, including DeepResearch Bench, DeepConsult, and DeepResearchGym. These results validate our human-centric, iterative methodology, demonstrating that adaptive planning and focused synthesis are crucial for producing high-quality, reliable, and well-structured reports.
QwenLong-CPRS: Towards $\infty$-LLMs with Dynamic Context Optimization
May 23, 2025This technical report presents QwenLong-CPRS, a context compression framework designed for explicit long-context optimization, addressing prohibitive computation overhead during the prefill stage and the "lost in the middle" performance degradation of large language models (LLMs) during long sequence processing. Implemented through a novel dynamic context optimization mechanism, QwenLong-CPRS enables multi-granularity context compression guided by natural language instructions, achieving both efficiency gains and improved performance. Evolved from the Qwen architecture series, QwenLong-CPRS introduces four key innovations: (1) Natural language-guided dynamic optimization, (2) Bidirectional reasoning layers for enhanced boundary awareness, (3) Token critic mechanisms with language modeling heads, and (4) Window-parallel inference. Comprehensive evaluations across five benchmarks (4K-2M word contexts) demonstrate QwenLong-CPRS's threefold effectiveness: (1) Consistent superiority over other context management methods like RAG and sparse attention in both accuracy and efficiency. (2) Architecture-agnostic integration with all flagship LLMs, including GPT-4o, Gemini2.0-pro, Claude3.7-sonnet, DeepSeek-v3, and Qwen2.5-max, achieves 21.59$\times$ context compression alongside 19.15-point average performance gains; (3) Deployed with Qwen2.5-32B-Instruct, QwenLong-CPRS surpasses leading proprietary LLMs by 4.85 and 10.88 points on Ruler-128K and InfiniteBench, establishing new SOTA performance.
MM-StoryAgent: Immersive Narrated Storybook Video Generation with a Multi-Agent Paradigm across Text, Image and Audio
Mar 07, 2025



The rapid advancement of large language models (LLMs) and artificial intelligence-generated content (AIGC) has accelerated AI-native applications, such as AI-based storybooks that automate engaging story production for children. However, challenges remain in improving story attractiveness, enriching storytelling expressiveness, and developing open-source evaluation benchmarks and frameworks. Therefore, we propose and opensource MM-StoryAgent, which creates immersive narrated video storybooks with refined plots, role-consistent images, and multi-channel audio. MM-StoryAgent designs a multi-agent framework that employs LLMs and diverse expert tools (generative models and APIs) across several modalities to produce expressive storytelling videos. The framework enhances story attractiveness through a multi-stage writing pipeline. In addition, it improves the immersive storytelling experience by integrating sound effects with visual, music and narrative assets. MM-StoryAgent offers a flexible, open-source platform for further development, where generative modules can be substituted. Both objective and subjective evaluation regarding textual story quality and alignment between modalities validate the effectiveness of our proposed MM-StoryAgent system. The demo and source code are available.
A Simple yet Effective Training-free Prompt-free Approach to Chinese Spelling Correction Based on Large Language Models
Oct 05, 2024



This work proposes a simple training-free prompt-free approach to leverage large language models (LLMs) for the Chinese spelling correction (CSC) task, which is totally different from all previous CSC approaches. The key idea is to use an LLM as a pure language model in a conventional manner. The LLM goes through the input sentence from the beginning, and at each inference step, produces a distribution over its vocabulary for deciding the next token, given a partial sentence. To ensure that the output sentence remains faithful to the input sentence, we design a minimal distortion model that utilizes pronunciation or shape similarities between the original and replaced characters. Furthermore, we propose two useful reward strategies to address practical challenges specific to the CSC task. Experiments on five public datasets demonstrate that our approach significantly improves LLM performance, enabling them to compete with state-of-the-art domain-general CSC models.
Towards Better Graph-based Cross-document Relation Extraction via Non-bridge Entity Enhancement and Prediction Debiasing
Jun 24, 2024Cross-document Relation Extraction aims to predict the relation between target entities located in different documents. In this regard, the dominant models commonly retain useful information for relation prediction via bridge entities, which allows the model to elaborately capture the intrinsic interdependence between target entities. However, these studies ignore the non-bridge entities, each of which co-occurs with only one target entity and offers the semantic association between target entities for relation prediction. Besides, the commonly-used dataset--CodRED contains substantial NA instances, leading to the prediction bias during inference. To address these issues, in this paper, we propose a novel graph-based cross-document RE model with non-bridge entity enhancement and prediction debiasing. Specifically, we use a unified entity graph to integrate numerous non-bridge entities with target entities and bridge entities, modeling various associations between them, and then use a graph recurrent network to encode this graph. Finally, we introduce a novel debiasing strategy to calibrate the original prediction distribution. Experimental results on the closed and open settings show that our model significantly outperforms all baselines, including the GPT-3.5-turbo and InstructUIE, achieving state-of-the-art performance. Particularly, our model obtains 66.23% and 55.87% AUC points in the official leaderboard\footnote{\url{https://codalab.lisn.upsaclay.fr/competitions/3770#results}} under the two settings, respectively, ranking the first place in all submissions since December 2023. Our code is available at https://github.com/DeepLearnXMU/CoRE-NEPD.
Type-Driven Multi-Turn Corrections for Grammatical Error Correction
Mar 17, 2022

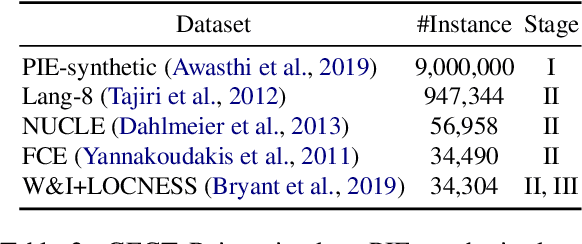
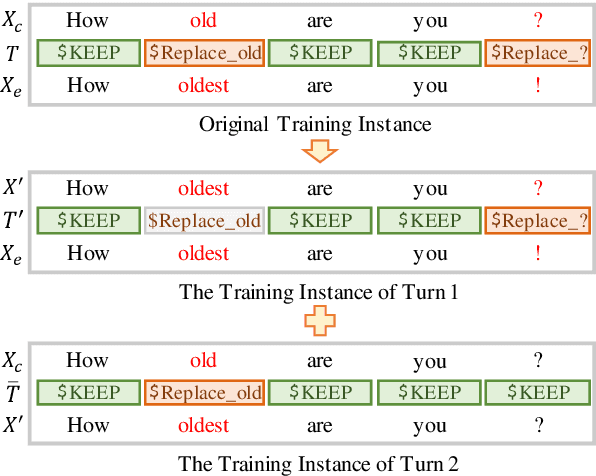
Grammatical Error Correction (GEC) aims to automatically detect and correct grammatical errors. In this aspect, dominant models are trained by one-iteration learning while performing multiple iterations of corrections during inference. Previous studies mainly focus on the data augmentation approach to combat the exposure bias, which suffers from two drawbacks. First, they simply mix additionally-constructed training instances and original ones to train models, which fails to help models be explicitly aware of the procedure of gradual corrections. Second, they ignore the interdependence between different types of corrections. In this paper, we propose a Type-Driven Multi-Turn Corrections approach for GEC. Using this approach, from each training instance, we additionally construct multiple training instances, each of which involves the correction of a specific type of errors. Then, we use these additionally-constructed training instances and the original one to train the model in turn. Experimental results and in-depth analysis show that our approach significantly benefits the model training. Particularly, our enhanced model achieves state-of-the-art single-model performance on English GEC benchmarks. We release our code at Github.
Improving Graph-based Sentence Ordering with Iteratively Predicted Pairwise Orderings
Oct 13, 2021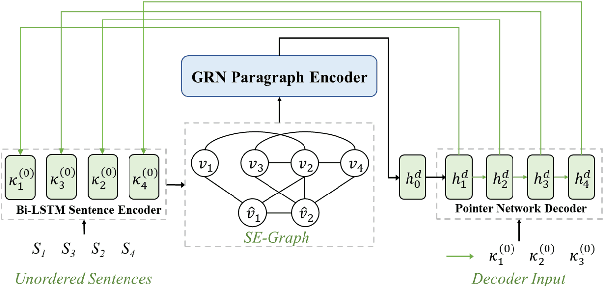
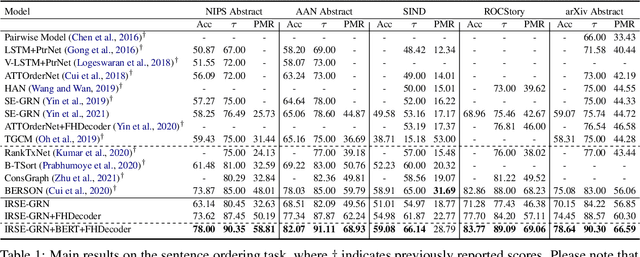
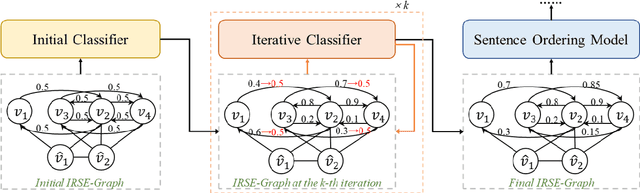
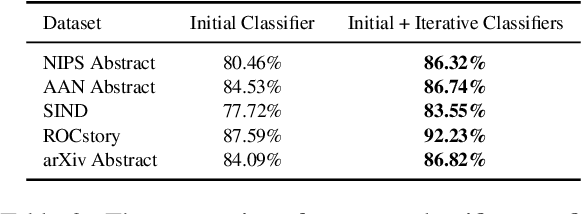
Dominant sentence ordering models can be classified into pairwise ordering models and set-to-sequence models. However, there is little attempt to combine these two types of models, which inituitively possess complementary advantages. In this paper, we propose a novel sentence ordering framework which introduces two classifiers to make better use of pairwise orderings for graph-based sentence ordering. Specially, given an initial sentence-entity graph, we first introduce a graph-based classifier to predict pairwise orderings between linked sentences. Then, in an iterative manner, based on the graph updated by previously predicted high-confident pairwise orderings, another classifier is used to predict the remaining uncertain pairwise orderings. At last, we adapt a GRN-based sentence ordering model on the basis of final graph. Experiments on five commonly-used datasets demonstrate the effectiveness and generality of our model. Particularly, when equipped with BERT and FHDecoder, our model achieves state-of-the-art performance.