 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRepNet-VSR: Reparameterizable Architecture for High-Fidelity Video Super-Resolution
Apr 22, 2025



As a fundamental challenge in visual computing, video super-resolution (VSR) focuses on reconstructing highdefinition video sequences from their degraded lowresolution counterparts. While deep convolutional neural networks have demonstrated state-of-the-art performance in spatial-temporal super-resolution tasks, their computationally intensive nature poses significant deployment challenges for resource-constrained edge devices, particularly in real-time mobile video processing scenarios where power efficiency and latency constraints coexist. In this work, we propose a Reparameterizable Architecture for High Fidelity Video Super Resolution method, named RepNet-VSR, for real-time 4x video super-resolution. On the REDS validation set, the proposed model achieves 27.79 dB PSNR when processing 180p to 720p frames in 103 ms per 10 frames on a MediaTek Dimensity NPU. The competition results demonstrate an excellent balance between restoration quality and deployment efficiency. The proposed method scores higher than the previous champion algorithm of MAI video super-resolution challenge.
Ex3: Automatic Novel Writing by Extracting, Excelsior and Expanding
Aug 16, 2024



Generating long-term texts such as novels using artificial intelligence has always been a challenge. A common approach is to use large language models (LLMs) to construct a hierarchical framework that first plans and then writes. Despite the fact that the generated novels reach a sufficient length, they exhibit poor logical coherence and appeal in their plots and deficiencies in character and event depiction, ultimately compromising the overall narrative quality. In this paper, we propose a method named Extracting Excelsior and Expanding. Ex3 initially extracts structure information from raw novel data. By combining this structure information with the novel data, an instruction-following dataset is meticulously crafted. This dataset is then utilized to fine-tune the LLM, aiming for excelsior generation performance. In the final stage, a tree-like expansion method is deployed to facilitate the generation of arbitrarily long novels. Evaluation against previous methods showcases Ex3's ability to produce higher-quality long-form novels.
Semi-supervised Video Semantic Segmentation Using Unreliable Pseudo Labels for PVUW2024
Jun 02, 2024



Pixel-level Scene Understanding is one of the fundamental problems in computer vision, which aims at recognizing object classes, masks and semantics of each pixel in the given image. Compared with image scene parsing, video scene parsing introduces temporal information, which can effectively improve the consistency and accuracy of prediction,because the real-world is actually video-based rather than a static state. In this paper, we adopt semi-supervised video semantic segmentation method based on unreliable pseudo labels. Then, We ensemble the teacher network model with the student network model to generate pseudo labels and retrain the student network. Our method achieves the mIoU scores of 63.71% and 67.83% on development test and final test respectively. Finally, we obtain the 1st place in the Video Scene Parsing in the Wild Challenge at CVPR 2024.
2nd Place Solution for PVUW Challenge 2024: Video Panoptic Segmentation
Jun 01, 2024



Video Panoptic Segmentation (VPS) is a challenging task that is extends from image panoptic segmentation.VPS aims to simultaneously classify, track, segment all objects in a video, including both things and stuff. Due to its wide application in many downstream tasks such as video understanding, video editing, and autonomous driving. In order to deal with the task of video panoptic segmentation in the wild, we propose a robust integrated video panoptic segmentation solution. We use DVIS++ framework as our baseline to generate the initial masks. Then,we add an additional image semantic segmentation model to further improve the performance of semantic classes.Finally, our method achieves state-of-the-art performance with a VPQ score of 56.36 and 57.12 in the development and test phases, respectively, and ultimately ranked 2nd in the VPS track of the PVUW Challenge at CVPR2024.
Real-Time 4K Super-Resolution of Compressed AVIF Images. AIS 2024 Challenge Survey
Apr 25, 2024



This paper introduces a novel benchmark as part of the AIS 2024 Real-Time Image Super-Resolution (RTSR) Challenge, which aims to upscale compressed images from 540p to 4K resolution (4x factor) in real-time on commercial GPUs. For this, we use a diverse test set containing a variety of 4K images ranging from digital art to gaming and photography. The images are compressed using the modern AVIF codec, instead of JPEG. All the proposed methods improve PSNR fidelity over Lanczos interpolation, and process images under 10ms. Out of the 160 participants, 25 teams submitted their code and models. The solutions present novel designs tailored for memory-efficiency and runtime on edge devices. This survey describes the best solutions for real-time SR of compressed high-resolution images.
Recyclable Semi-supervised Method Based on Multi-model Ensemble for Video Scene Parsing
Jun 05, 2023



Pixel-level Scene Understanding is one of the fundamental problems in computer vision, which aims at recognizing object classes, masks and semantics of each pixel in the given image. Since the real-world is actually video-based rather than a static state, learning to perform video semantic segmentation is more reasonable and practical for realistic applications. In this paper, we adopt Mask2Former as architecture and ViT-Adapter as backbone. Then, we propose a recyclable semi-supervised training method based on multi-model ensemble. Our method achieves the mIoU scores of 62.97% and 65.83% on Development test and final test respectively. Finally, we obtain the 2nd place in the Video Scene Parsing in the Wild Challenge at CVPR 2023.
Power Efficient Video Super-Resolution on Mobile NPUs with Deep Learning, Mobile AI & AIM 2022 challenge: Report
Nov 07, 2022



Video super-resolution is one of the most popular tasks on mobile devices, being widely used for an automatic improvement of low-bitrate and low-resolution video streams. While numerous solutions have been proposed for this problem, they are usually quite computationally demanding, demonstrating low FPS rates and power efficiency on mobile devices. In this Mobile AI challenge, we address this problem and propose the participants to design an end-to-end real-time video super-resolution solution for mobile NPUs optimized for low energy consumption. The participants were provided with the REDS training dataset containing video sequences for a 4X video upscaling task. The runtime and power efficiency of all models was evaluated on the powerful MediaTek Dimensity 9000 platform with a dedicated AI processing unit capable of accelerating floating-point and quantized neural networks. All proposed solutions are fully compatible with the above NPU, demonstrating an up to 500 FPS rate and 0.2 [Watt / 30 FPS] power consumption. A detailed description of all models developed in the challenge is provided in this paper.
NTIRE 2022 Challenge on Super-Resolution and Quality Enhancement of Compressed Video: Dataset, Methods and Results
Apr 25, 2022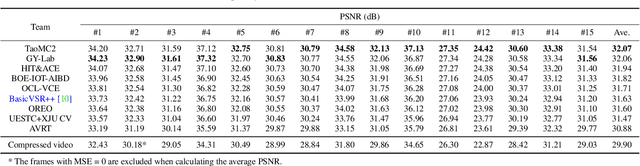
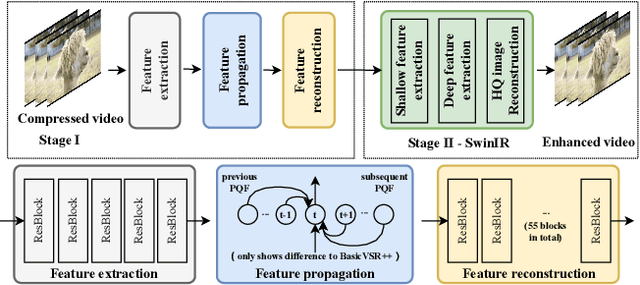
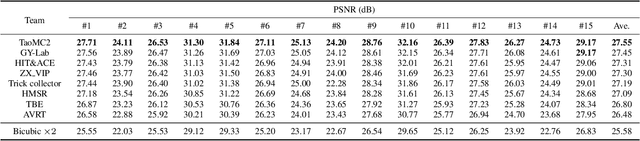

This paper reviews the NTIRE 2022 Challenge on Super-Resolution and Quality Enhancement of Compressed Video. In this challenge, we proposed the LDV 2.0 dataset, which includes the LDV dataset (240 videos) and 95 additional videos. This challenge includes three tracks. Track 1 aims at enhancing the videos compressed by HEVC at a fixed QP. Track 2 and Track 3 target both the super-resolution and quality enhancement of HEVC compressed video. They require x2 and x4 super-resolution, respectively. The three tracks totally attract more than 600 registrations. In the test phase, 8 teams, 8 teams and 12 teams submitted the final results to Tracks 1, 2 and 3, respectively. The proposed methods and solutions gauge the state-of-the-art of super-resolution and quality enhancement of compressed video. The proposed LDV 2.0 dataset is available at https://github.com/RenYang-home/LDV_dataset. The homepage of this challenge (including open-sourced codes) is at https://github.com/RenYang-home/NTIRE22_VEnh_SR.
Distilling Object Detectors with Feature Richness
Nov 02, 2021
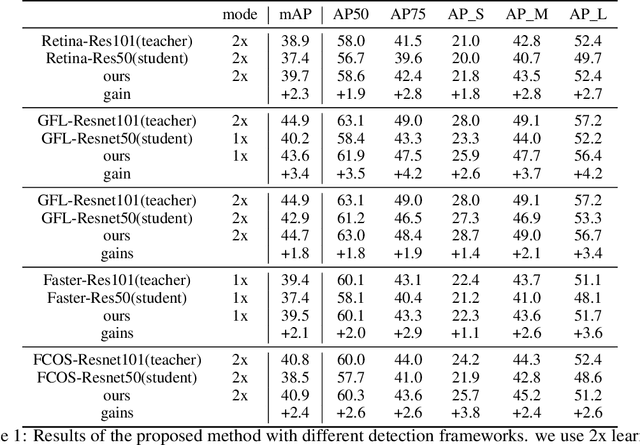
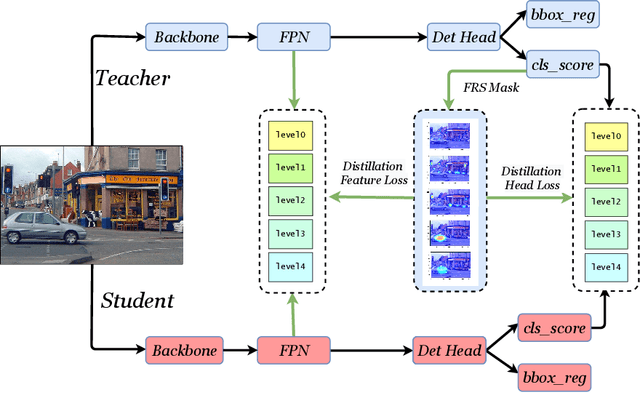
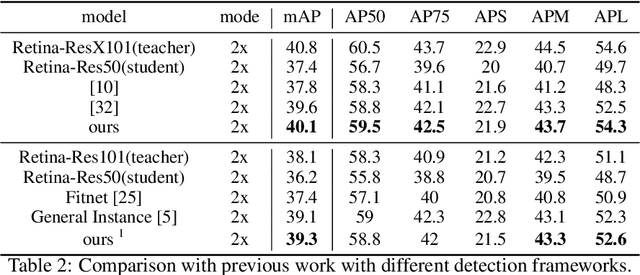
In recent years, large-scale deep models have achieved great success, but the huge computational complexity and massive storage requirements make it a great challenge to deploy them in resource-limited devices. As a model compression and acceleration method, knowledge distillation effectively improves the performance of small models by transferring the dark knowledge from the teacher detector. However, most of the existing distillation-based detection methods mainly imitating features near bounding boxes, which suffer from two limitations. First, they ignore the beneficial features outside the bounding boxes. Second, these methods imitate some features which are mistakenly regarded as the background by the teacher detector. To address the above issues, we propose a novel Feature-Richness Score (FRS) method to choose important features that improve generalized detectability during distilling. The proposed method effectively retrieves the important features outside the bounding boxes and removes the detrimental features within the bounding boxes. Extensive experiments show that our methods achieve excellent performance on both anchor-based and anchor-free detectors. For example, RetinaNet with ResNet-50 achieves 39.7% in mAP on the COCO2017 dataset, which even surpasses the ResNet-101 based teacher detector 38.9% by 0.8%.
DWM: A Decomposable Winograd Method for Convolution Acceleration
Feb 03, 2020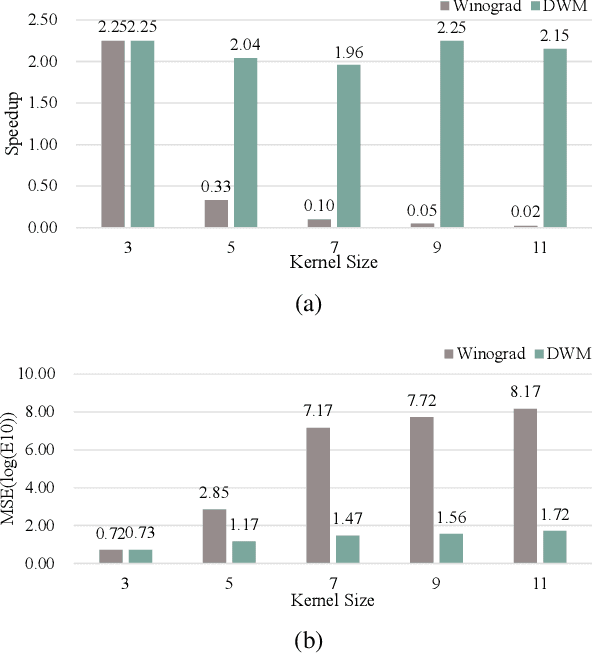
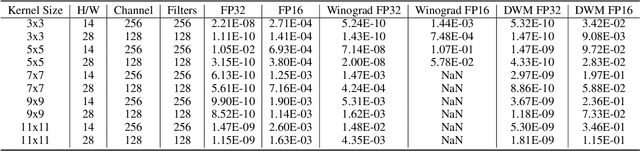
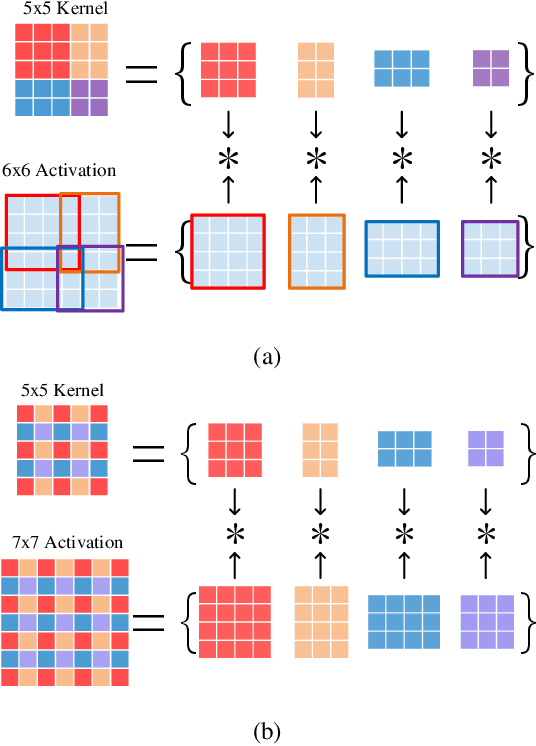

Winograd's minimal filtering algorithm has been widely used in Convolutional Neural Networks (CNNs) to reduce the number of multiplications for faster processing. However, it is only effective on convolutions with kernel size as 3x3 and stride as 1, because it suffers from significantly increased FLOPs and numerical accuracy problem for kernel size larger than 3x3 and fails on convolution with stride larger than 1. In this paper, we propose a novel Decomposable Winograd Method (DWM), which breaks through the limitation of original Winograd's minimal filtering algorithm to a wide and general convolutions. DWM decomposes kernels with large size or large stride to several small kernels with stride as 1 for further applying Winograd method, so that DWM can reduce the number of multiplications while keeping the numerical accuracy. It enables the fast exploring of larger kernel size and larger stride value in CNNs for high performance and accuracy and even the potential for new CNNs. Comparing against the original Winograd, the proposed DWM is able to support all kinds of convolutions with a speedup of ~2, without affecting the numerical accuracy.