 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAlgoVeri: An Aligned Benchmark for Verified Code Generation on Classical Algorithms
Feb 10, 2026Vericoding refers to the generation of formally verified code from rigorous specifications. Recent AI models show promise in vericoding, but a unified methodology for cross-paradigm evaluation is lacking. Existing benchmarks test only individual languages/tools (e.g., Dafny, Verus, and Lean) and each covers very different tasks, so the performance numbers are not directly comparable. We address this gap with AlgoVeri, a benchmark that evaluates vericoding of $77$ classical algorithms in Dafny, Verus, and Lean. By enforcing identical functional contracts, AlgoVeri reveals critical capability gaps in verification systems. While frontier models achieve tractable success in Dafny ($40.3$% for Gemini-3 Flash), where high-level abstractions and SMT automation simplify the workflow, performance collapses under the systems-level memory constraints of Verus ($24.7$%) and the explicit proof construction required by Lean (7.8%). Beyond aggregate metrics, we uncover a sharp divergence in test-time compute dynamics: Gemini-3 effectively utilizes iterative repair to boost performance (e.g., tripling pass rates in Dafny), whereas GPT-OSS saturates early. Finally, our error analysis shows that language design affects the refinement trajectory: while Dafny allows models to focus on logical correctness, Verus and Lean trap models in persistent syntactic and semantic barriers. All data and evaluation code can be found at https://github.com/haoyuzhao123/algoveri.
DWM: A Decomposable Winograd Method for Convolution Acceleration
Feb 03, 2020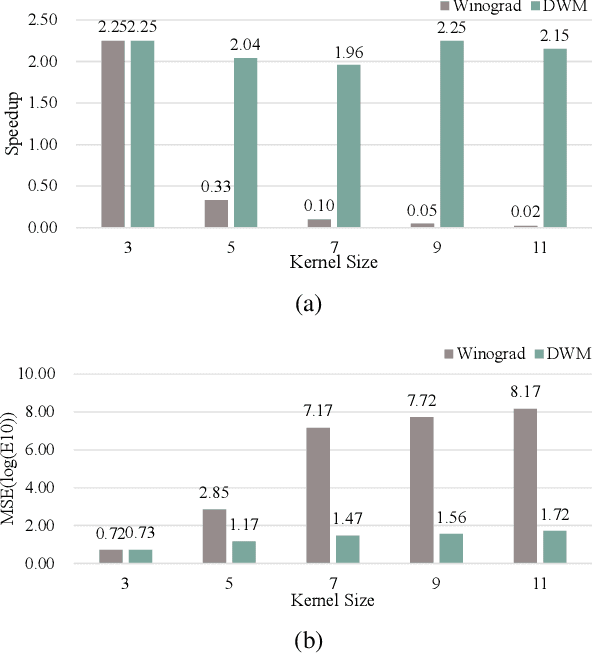
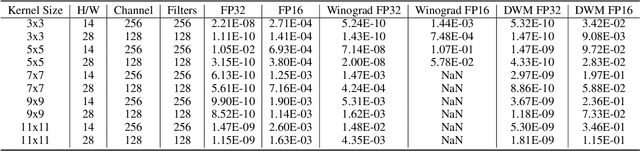
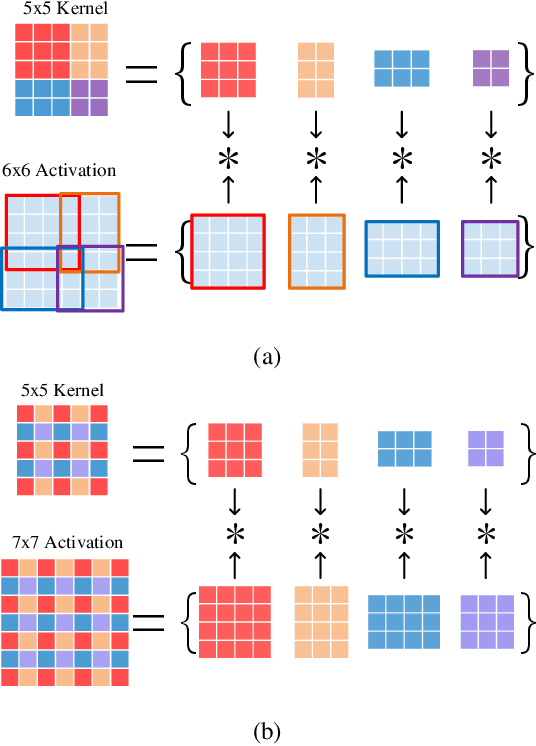

Winograd's minimal filtering algorithm has been widely used in Convolutional Neural Networks (CNNs) to reduce the number of multiplications for faster processing. However, it is only effective on convolutions with kernel size as 3x3 and stride as 1, because it suffers from significantly increased FLOPs and numerical accuracy problem for kernel size larger than 3x3 and fails on convolution with stride larger than 1. In this paper, we propose a novel Decomposable Winograd Method (DWM), which breaks through the limitation of original Winograd's minimal filtering algorithm to a wide and general convolutions. DWM decomposes kernels with large size or large stride to several small kernels with stride as 1 for further applying Winograd method, so that DWM can reduce the number of multiplications while keeping the numerical accuracy. It enables the fast exploring of larger kernel size and larger stride value in CNNs for high performance and accuracy and even the potential for new CNNs. Comparing against the original Winograd, the proposed DWM is able to support all kinds of convolutions with a speedup of ~2, without affecting the numerical accuracy.