 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgerPPG-VQA: A Video Quality Assessment Framework for Unsupervised rPPG Training
Apr 13, 2026Unsupervised remote photoplethysmography (rPPG) promises to leverage unlabeled video data, but its potential is hindered by a critical challenge: training on low-quality "in-the-wild" videos severely degrades model performance. An essential step missing here is to assess the suitability of the videos for rPPG model learning before using them for the task. Existing video quality assessment (VQA) methods are mainly designed for human perception and not directly applicable to the above purpose. In this work, we propose rPPG-VQA, a novel framework for assessing video suitability for rPPG. We integrate signal-level and scene-level analyses and design a dual-branch assessment architecture. The signal-level branch evaluates the physiological signal quality of the videos via robust signal-to-noise ratio (SNR) estimation with a multi-method consensus mechanism, and the scene-level branch uses a multimodal large language model (MLLM) to identify interferences like motion and unstable lighting. Furthermore, we propose a two-stage adaptive sampling (TAS) strategy that utilizes the quality score to curate optimal training datasets. Experiments show that by training on large-scale, "in-the-wild" videos filtered by our framework, we can develop unsupervised rPPG models that achieve a substantial improvement in accuracy on standard benchmarks. Our code is available at https://github.com/Tianyang-Dai/rPPG-VQA.
3D-EffiViTCaps: 3D Efficient Vision Transformer with Capsule for Medical Image Segmentation
Mar 25, 2024



Medical image segmentation (MIS) aims to finely segment various organs. It requires grasping global information from both parts and the entire image for better segmenting, and clinically there are often certain requirements for segmentation efficiency. Convolutional neural networks (CNNs) have made considerable achievements in MIS. However, they are difficult to fully collect global context information and their pooling layer may cause information loss. Capsule networks, which combine the benefits of CNNs while taking into account additional information such as relative location that CNNs do not, have lately demonstrated some advantages in MIS. Vision Transformer (ViT) employs transformers in visual tasks. Transformer based on attention mechanism has excellent global inductive modeling capabilities and is expected to capture longrange information. Moreover, there have been resent studies on making ViT more lightweight to minimize model complexity and increase efficiency. In this paper, we propose a U-shaped 3D encoder-decoder network named 3D-EffiViTCaps, which combines 3D capsule blocks with 3D EfficientViT blocks for MIS. Our encoder uses capsule blocks and EfficientViT blocks to jointly capture local and global semantic information more effectively and efficiently with less information loss, while the decoder employs CNN blocks and EfficientViT blocks to catch ffner details for segmentation. We conduct experiments on various datasets, including iSeg-2017, Hippocampus and Cardiac to verify the performance and efficiency of 3D-EffiViTCaps, which performs better than previous 3D CNN-based, 3D Capsule-based and 3D Transformer-based models. We further implement a series of ablation experiments on the main blocks. Our code is available at: https://github.com/HidNeuron/3D-EffiViTCaps.
Distilling Object Detectors with Feature Richness
Nov 02, 2021
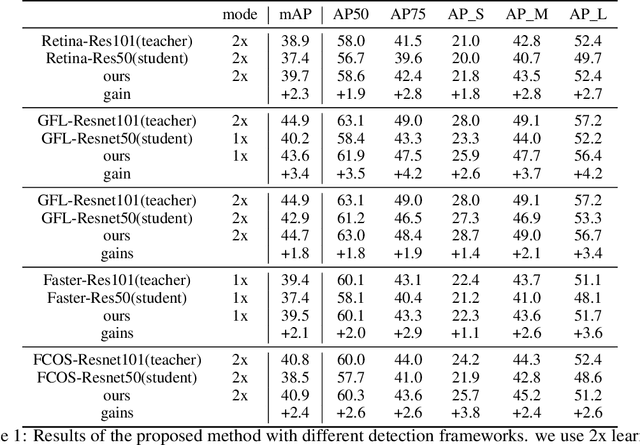
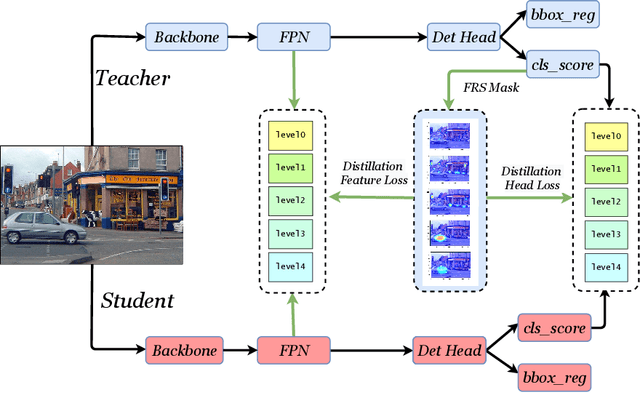
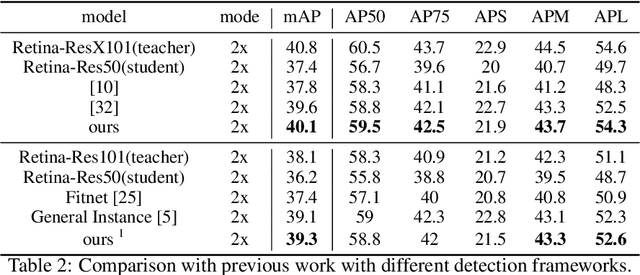
In recent years, large-scale deep models have achieved great success, but the huge computational complexity and massive storage requirements make it a great challenge to deploy them in resource-limited devices. As a model compression and acceleration method, knowledge distillation effectively improves the performance of small models by transferring the dark knowledge from the teacher detector. However, most of the existing distillation-based detection methods mainly imitating features near bounding boxes, which suffer from two limitations. First, they ignore the beneficial features outside the bounding boxes. Second, these methods imitate some features which are mistakenly regarded as the background by the teacher detector. To address the above issues, we propose a novel Feature-Richness Score (FRS) method to choose important features that improve generalized detectability during distilling. The proposed method effectively retrieves the important features outside the bounding boxes and removes the detrimental features within the bounding boxes. Extensive experiments show that our methods achieve excellent performance on both anchor-based and anchor-free detectors. For example, RetinaNet with ResNet-50 achieves 39.7% in mAP on the COCO2017 dataset, which even surpasses the ResNet-101 based teacher detector 38.9% by 0.8%.