 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Identify Object Instances by Touch: Tactile Recognition via Multimodal Matching
Mar 08, 2019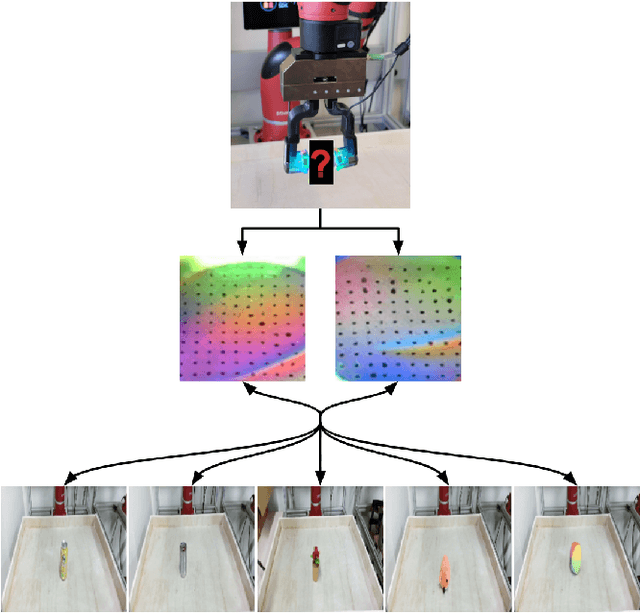


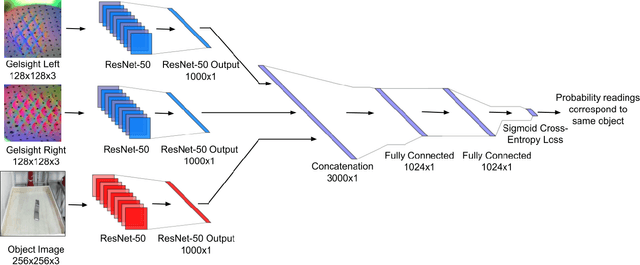
Much of the literature on robotic perception focuses on the visual modality. Vision provides a global observation of a scene, making it broadly useful. However, in the domain of robotic manipulation, vision alone can sometimes prove inadequate: in the presence of occlusions or poor lighting, visual object identification might be difficult. The sense of touch can provide robots with an alternative mechanism for recognizing objects. In this paper, we study the problem of touch-based instance recognition. We propose a novel framing of the problem as multi-modal recognition: the goal of our system is to recognize, given a visual and tactile observation, whether or not these observations correspond to the same object. To our knowledge, our work is the first to address this type of multi-modal instance recognition problem on such a large-scale with our analysis spanning 98 different objects. We employ a robot equipped with two GelSight touch sensors, one on each finger, and a self-supervised, autonomous data collection procedure to collect a dataset of tactile observations and images. Our experimental results show that it is possible to accurately recognize object instances by touch alone, including instances of novel objects that were never seen during training. Our learned model outperforms other methods on this complex task, including that of human volunteers.
Learning Latent Plans from Play
Mar 05, 2019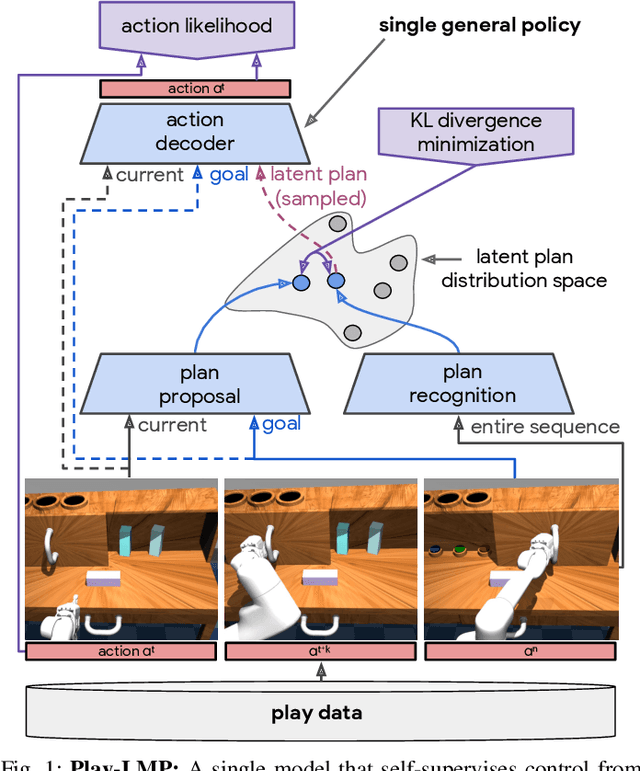
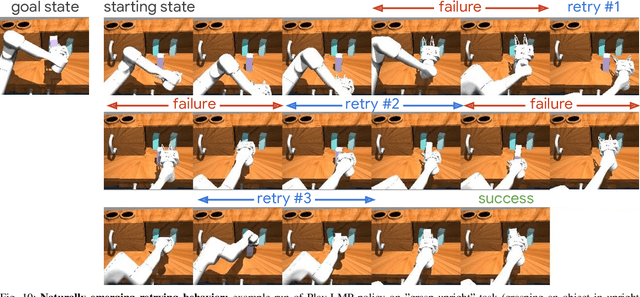
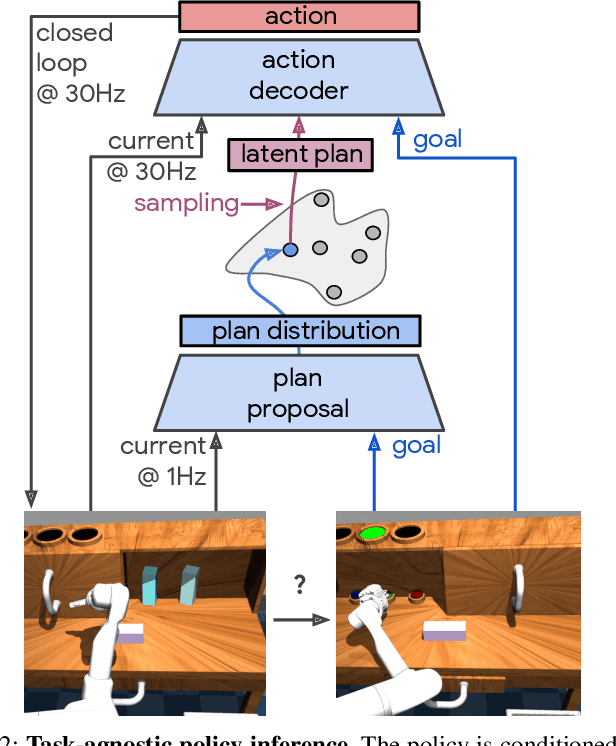

We propose learning from teleoperated play data (LfP) as a way to scale up multi-task robotic skill learning. Learning from play (LfP) offers three main advantages: 1) It is cheap. Large amounts of play data can be collected quickly as it does not require scene staging, task segmenting, or resetting to an initial state. 2) It is general. It contains both functional and non-functional behavior, relaxing the need for a predefined task distribution. 3) It is rich. Play involves repeated, varied behavior and naturally leads to high coverage of the possible interaction space. These properties distinguish play from expert demonstrations, which are rich, but expensive, and scripted unattended data collection, which is cheap, but insufficiently rich. Variety in play, however, presents a multimodality challenge to methods seeking to learn control on top. To this end, we introduce Play-LMP, a method designed to handle variability in the LfP setting by organizing it in an embedding space. Play-LMP jointly learns 1) reusable latent plan representations unsupervised from play data and 2) a single goal-conditioned policy capable of decoding inferred plans to achieve user-specified tasks. We show empirically that Play-LMP, despite not being trained on task-specific data, is capable of generalizing to 18 complex user-specified manipulation tasks with average success of 85.5%, outperforming individual models trained on expert demonstrations (success of 70.3%). Furthermore, we find that play-supervised models, unlike their expert-trained counterparts, 1) are more robust to perturbations and 2) exhibit retrying-till-success. Finally, despite never being trained with task labels, we find that our agent learns to organize its latent plan space around functional tasks. Videos of the performed experiments are available at learning-from-play.github.io
Model-Based Reinforcement Learning for Atari
Mar 05, 2019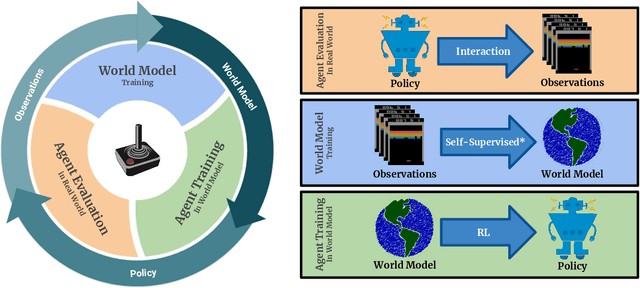
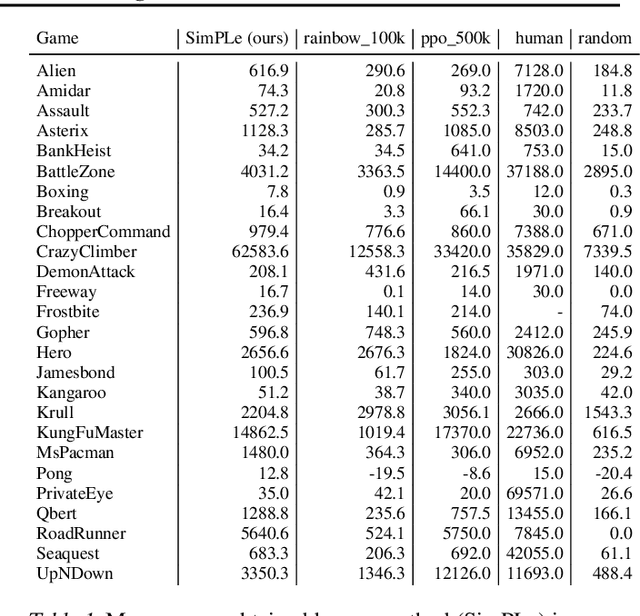
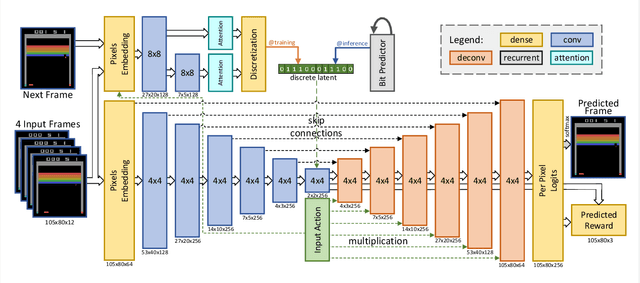
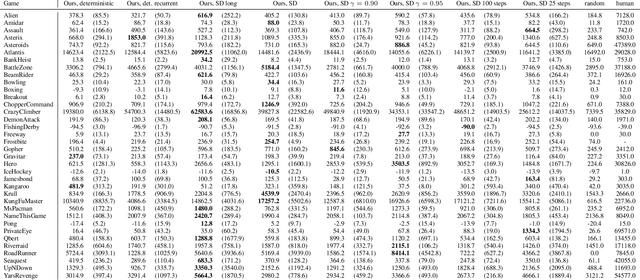
Model-free reinforcement learning (RL) can be used to learn effective policies for complex tasks, such as Atari games, even from image observations. However, this typically requires very large amounts of interaction -- substantially more, in fact, than a human would need to learn the same games. How can people learn so quickly? Part of the answer may be that people can learn how the game works and predict which actions will lead to desirable outcomes. In this paper, we explore how video prediction models can similarly enable agents to solve Atari games with orders of magnitude fewer interactions than model-free methods. We describe Simulated Policy Learning (SimPLe), a complete model-based deep RL algorithm based on video prediction models and present a comparison of several model architectures, including a novel architecture that yields the best results in our setting. Our experiments evaluate SimPLe on a range of Atari games and achieve competitive results with only 100K interactions between the agent and the environment (400K frames), which corresponds to about two hours of real-time play.
VideoFlow: A Flow-Based Generative Model for Video
Mar 04, 2019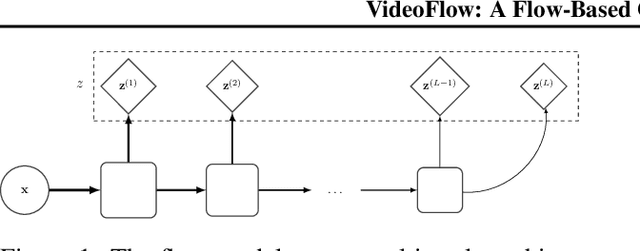

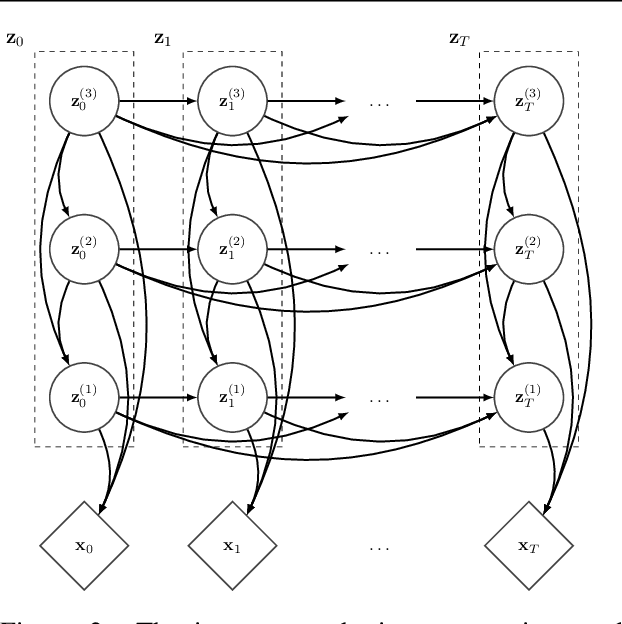
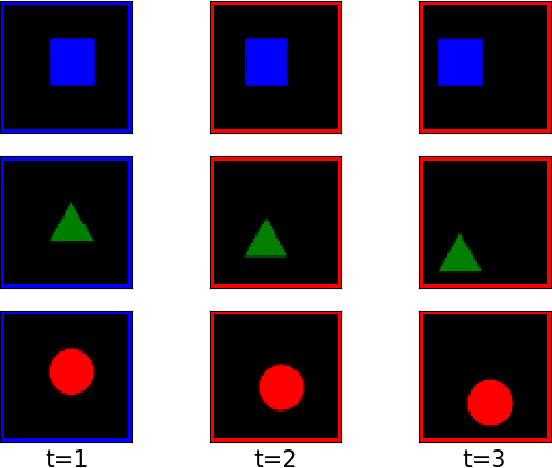
Generative models that can model and predict sequences of future events can, in principle, learn to capture complex real-world phenomena, such as physical interactions. In particular, learning predictive models of videos offers an especially appealing mechanism to enable a rich understanding of the physical world: videos of real-world interactions are plentiful and readily available, and a model that can predict future video frames can not only capture useful representations of the world, but can be useful in its own right, for problems such as model-based robotic control. However, a central challenge in video prediction is that the future is highly uncertain: a sequence of past observations of events can imply many possible futures. Although a number of recent works have studied probabilistic models that can represent uncertain futures, such models are either extremely expensive computationally (as in the case of pixel-level autoregressive models), or do not directly optimize the likelihood of the data. In this work, we propose a model for video prediction based on normalizing flows, which allows for direct optimization of the data likelihood, and produces high-quality stochastic predictions. To our knowledge, our work is the first to propose multi-frame video prediction with normalizing flows. We describe an approach for modeling the latent space dynamics, and demonstrate that flow-based generative models offer a viable and competitive approach to generative modeling of video.
Learning to Adapt in Dynamic, Real-World Environments Through Meta-Reinforcement Learning
Feb 27, 2019
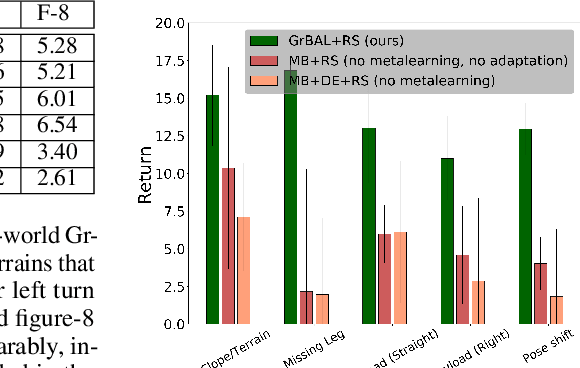


Although reinforcement learning methods can achieve impressive results in simulation, the real world presents two major challenges: generating samples is exceedingly expensive, and unexpected perturbations or unseen situations cause proficient but specialized policies to fail at test time. Given that it is impractical to train separate policies to accommodate all situations the agent may see in the real world, this work proposes to learn how to quickly and effectively adapt online to new tasks. To enable sample-efficient learning, we consider learning online adaptation in the context of model-based reinforcement learning. Our approach uses meta-learning to train a dynamics model prior such that, when combined with recent data, this prior can be rapidly adapted to the local context. Our experiments demonstrate online adaptation for continuous control tasks on both simulated and real-world agents. We first show simulated agents adapting their behavior online to novel terrains, crippled body parts, and highly-dynamic environments. We also illustrate the importance of incorporating online adaptation into autonomous agents that operate in the real world by applying our method to a real dynamic legged millirobot. We demonstrate the agent's learned ability to quickly adapt online to a missing leg, adjust to novel terrains and slopes, account for miscalibration or errors in pose estimation, and compensate for pulling payloads.
Diagnosing Bottlenecks in Deep Q-learning Algorithms
Feb 26, 2019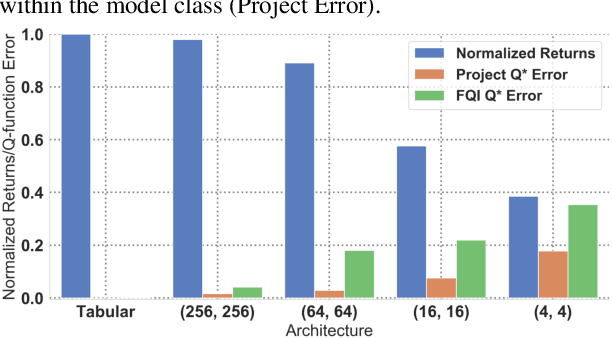
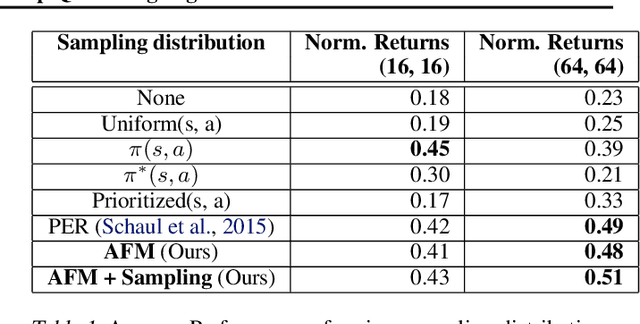
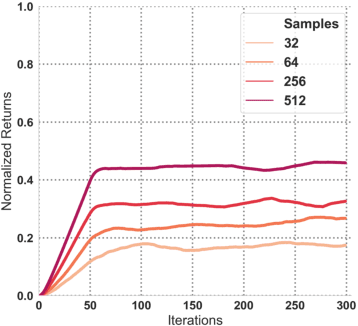
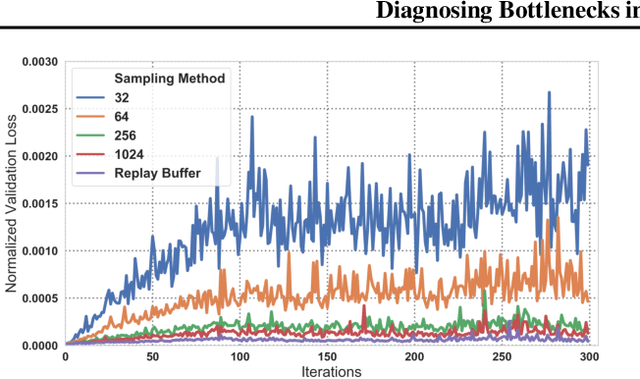
Q-learning methods represent a commonly used class of algorithms in reinforcement learning: they are generally efficient and simple, and can be combined readily with function approximators for deep reinforcement learning (RL). However, the behavior of Q-learning methods with function approximation is poorly understood, both theoretically and empirically. In this work, we aim to experimentally investigate potential issues in Q-learning, by means of a "unit testing" framework where we can utilize oracles to disentangle sources of error. Specifically, we investigate questions related to function approximation, sampling error and nonstationarity, and where available, verify if trends found in oracle settings hold true with modern deep RL methods. We find that large neural network architectures have many benefits with regards to learning stability; offer several practical compensations for overfitting; and develop a novel sampling method based on explicitly compensating for function approximation error that yields fair improvement on high-dimensional continuous control domains.
Online Meta-Learning
Feb 22, 2019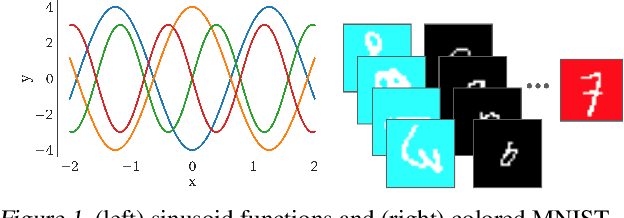
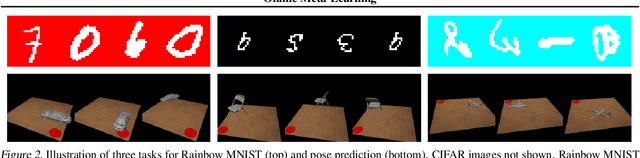
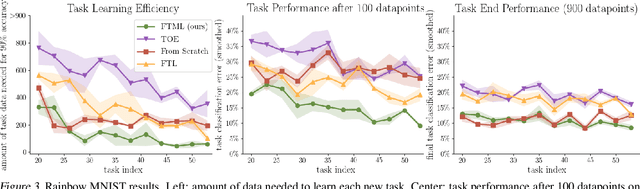
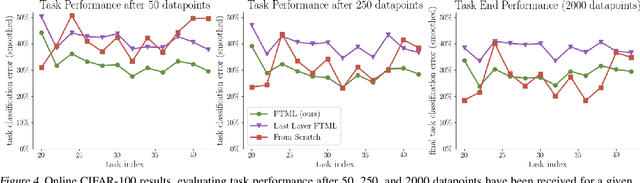
A central capability of intelligent systems is the ability to continuously build upon previous experiences to speed up and enhance learning of new tasks. Two distinct research paradigms have studied this question. Meta-learning views this problem as learning a prior over model parameters that is amenable for fast adaptation on a new task, but typically assumes the set of tasks are available together as a batch. In contrast, online (regret based) learning considers a sequential setting in which problems are revealed one after the other, but conventionally train only a single model without any task-specific adaptation. This work introduces an online meta-learning setting, which merges ideas from both the aforementioned paradigms to better capture the spirit and practice of continual lifelong learning. We propose the follow the meta leader algorithm which extends the MAML algorithm to this setting. Theoretically, this work provides an $\mathcal{O}(\log T)$ regret guarantee with only one additional higher order smoothness assumption in comparison to the standard online setting. Our experimental evaluation on three different large-scale tasks suggest that the proposed algorithm significantly outperforms alternatives based on traditional online learning approaches.
SOLAR: Deep Structured Representations for Model-Based Reinforcement Learning
Feb 20, 2019
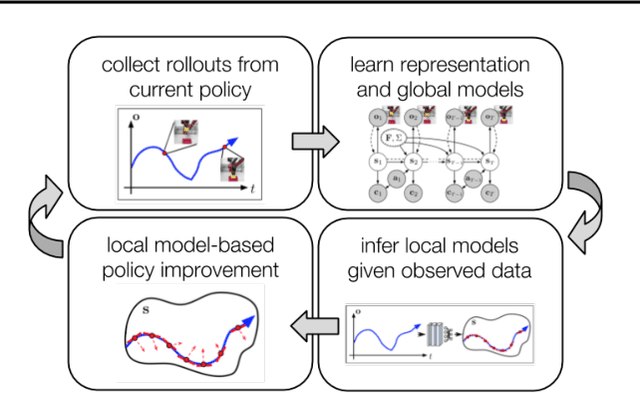
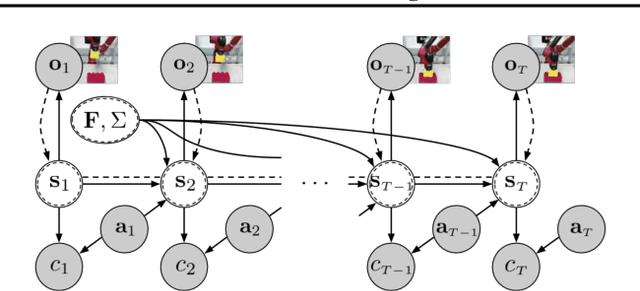

Model-based reinforcement learning (RL) has proven to be a data efficient approach for learning control tasks but is difficult to utilize in domains with complex observations such as images. In this paper, we present a method for learning representations that are suitable for iterative model-based policy improvement, in that these representations are optimized for inferring simple dynamics and cost models given data from the current policy. This enables a model-based RL method based on the linear-quadratic regulator (LQR) to be used for systems with image observations. We evaluate our approach on a suite of robotics tasks, including manipulation tasks on a real Sawyer robot arm directly from images, and we find that our method results in better final performance than other model-based RL methods while being significantly more efficient than model-free RL. Videos of our results are available at https://sites.google.com/view/icml19solar
From Language to Goals: Inverse Reinforcement Learning for Vision-Based Instruction Following
Feb 20, 2019

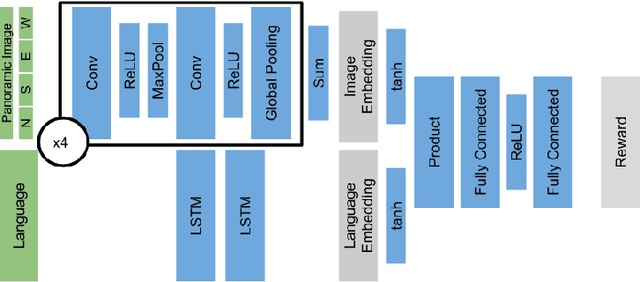
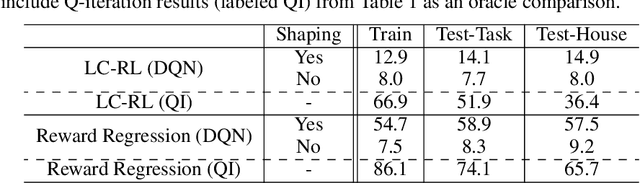
Reinforcement learning is a promising framework for solving control problems, but its use in practical situations is hampered by the fact that reward functions are often difficult to engineer. Specifying goals and tasks for autonomous machines, such as robots, is a significant challenge: conventionally, reward functions and goal states have been used to communicate objectives. But people can communicate objectives to each other simply by describing or demonstrating them. How can we build learning algorithms that will allow us to tell machines what we want them to do? In this work, we investigate the problem of grounding language commands as reward functions using inverse reinforcement learning, and argue that language-conditioned rewards are more transferable than language-conditioned policies to new environments. We propose language-conditioned reward learning (LC-RL), which grounds language commands as a reward function represented by a deep neural network. We demonstrate that our model learns rewards that transfer to novel tasks and environments on realistic, high-dimensional visual environments with natural language commands, whereas directly learning a language-conditioned policy leads to poor performance.
Hierarchical Policy Design for Sample-Efficient Learning of Robot Table Tennis Through Self-Play
Feb 17, 2019


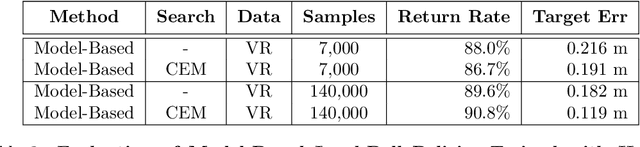
Training robots with physical bodies requires developing new methods and action representations that allow the learning agents to explore the space of policies efficiently. This work studies sample-efficient learning of complex policies in the context of robot table tennis. It incorporates learning into a hierarchical control framework using a model-free strategy layer (which requires complex reasoning about opponents that is difficult to do in a model-based way), model-based prediction of external objects (which are difficult to control directly with analytic control methods, but governed by learnable and relatively simple laws of physics), and analytic controllers for the robot itself. Human demonstrations are used to train dynamics models, which together with the analytic controller allow any robot that is physically capable to play table tennis without training episodes. Using only about 7,000 demonstrated trajectories, a striking policy can hit ball targets with about 20 cm error. Self-play is used to train cooperative and adversarial strategies on top of model-based striking skills trained from human demonstrations. After only about 24,000 strikes in self-play the agent learns to best exploit the human dynamics models for longer cooperative games. Further experiments demonstrate that more flexible variants of the policy can discover new strikes not demonstrated by humans and achieve higher performance at the expense of lower sample-efficiency. Experiments are carried out in a virtual reality environment using sensory observations that are obtainable in the real world. The high sample-efficiency demonstrated in the evaluations show that the proposed method is suitable for learning directly on physical robots without transfer of models or policies from simulation. Supplementary material available at https://sites.google.com/view/robottabletennis