 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Powerful Policies by Using Consistent Dynamics Model
Jun 11, 2019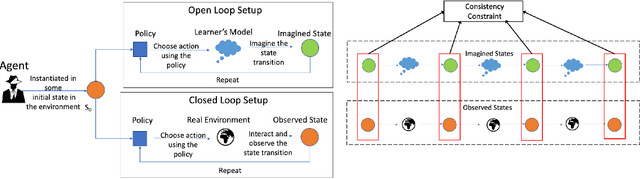
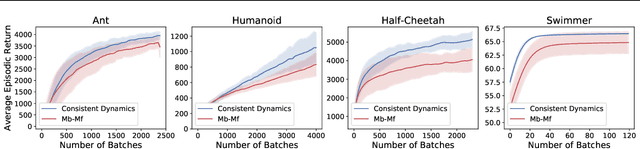
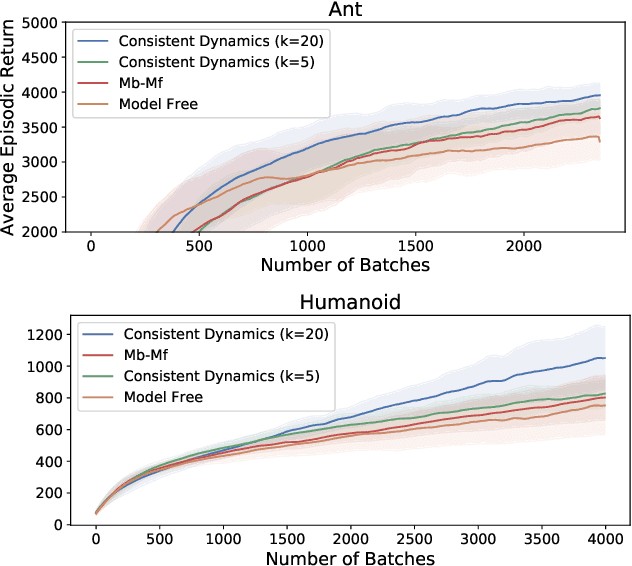
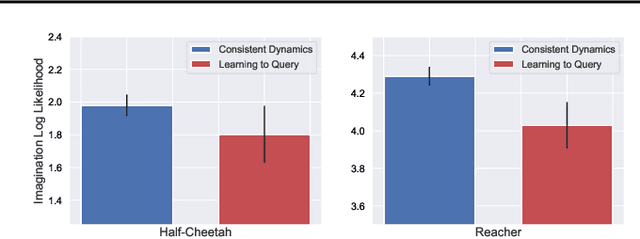
Model-based Reinforcement Learning approaches have the promise of being sample efficient. Much of the progress in learning dynamics models in RL has been made by learning models via supervised learning. But traditional model-based approaches lead to `compounding errors' when the model is unrolled step by step. Essentially, the state transitions that the learner predicts (by unrolling the model for multiple steps) and the state transitions that the learner experiences (by acting in the environment) may not be consistent. There is enough evidence that humans build a model of the environment, not only by observing the environment but also by interacting with the environment. Interaction with the environment allows humans to carry out experiments: taking actions that help uncover true causal relationships which can be used for building better dynamics models. Analogously, we would expect such interactions to be helpful for a learning agent while learning to model the environment dynamics. In this paper, we build upon this intuition by using an auxiliary cost function to ensure consistency between what the agent observes (by acting in the real world) and what it imagines (by acting in the `learned' world). We consider several tasks - Mujoco based control tasks and Atari games - and show that the proposed approach helps to train powerful policies and better dynamics models.
Watch, Try, Learn: Meta-Learning from Demonstrations and Reward
Jun 07, 2019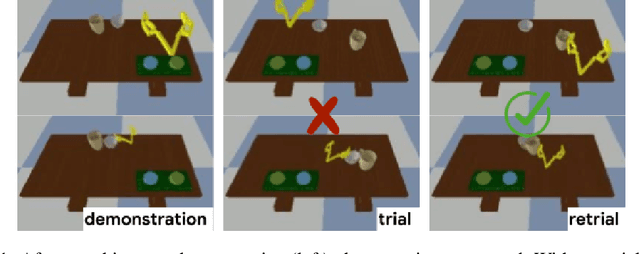
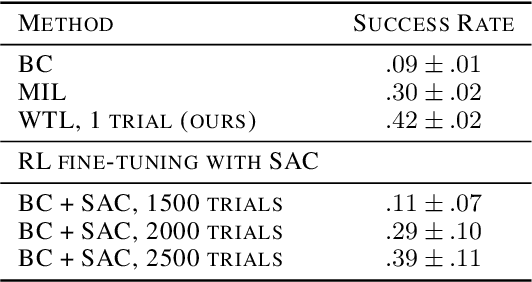
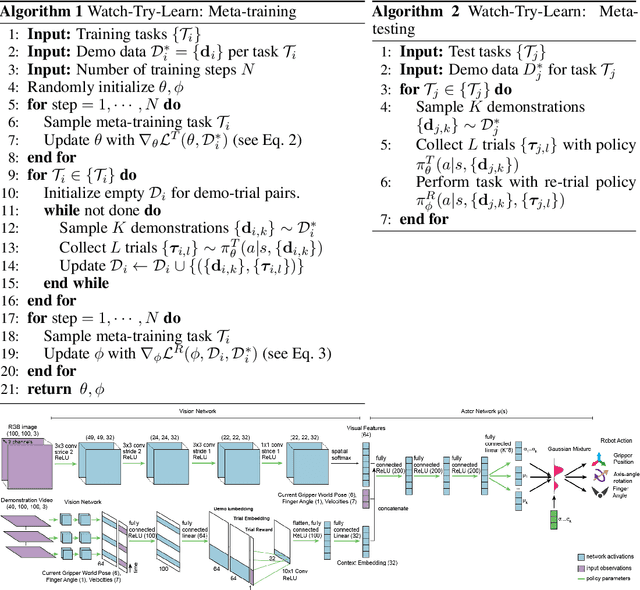
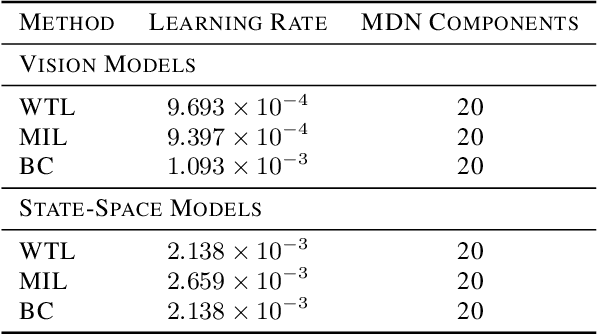
Imitation learning allows agents to learn complex behaviors from demonstrations. However, learning a complex vision-based task may require an impractical number of demonstrations. Meta-imitation learning is a promising approach towards enabling agents to learn a new task from one or a few demonstrations by leveraging experience from learning similar tasks. In the presence of task ambiguity or unobserved dynamics, demonstrations alone may not provide enough information; an agent must also try the task to successfully infer a policy. In this work, we propose a method that can learn to learn from both demonstrations and trial-and-error experience with sparse reward feedback. In comparison to meta-imitation, this approach enables the agent to effectively and efficiently improve itself autonomously beyond the demonstration data. In comparison to meta-reinforcement learning, we can scale to substantially broader distributions of tasks, as the demonstration reduces the burden of exploration. Our experiments show that our method significantly outperforms prior approaches on a set of challenging, vision-based control tasks.
Stabilizing Off-Policy Q-Learning via Bootstrapping Error Reduction
Jun 03, 2019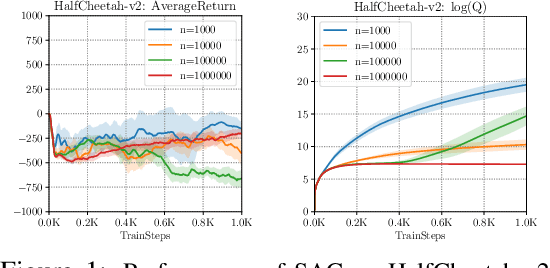
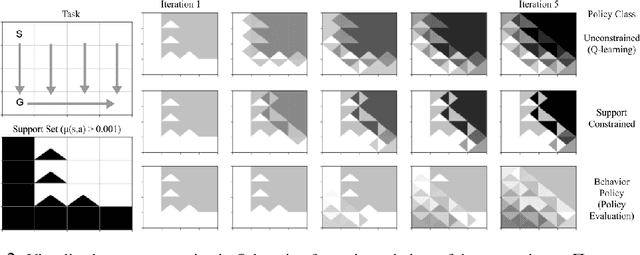
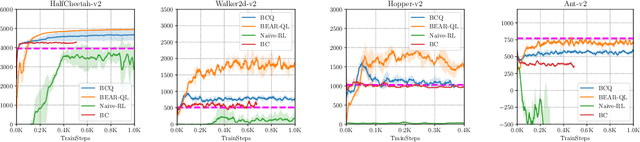
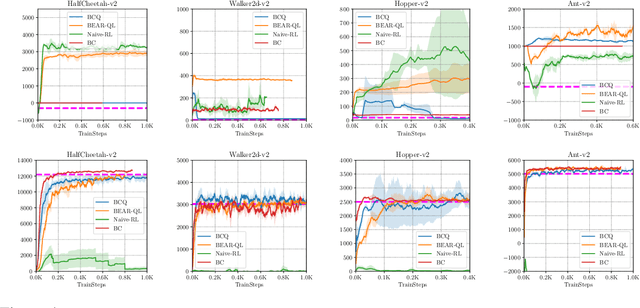
Off-policy reinforcement learning aims to leverage experience collected from prior policies for sample-efficient learning. However, in practice, commonly used off-policy approximate dynamic programming methods based on Q-learning and actor-critic methods are highly sensitive to the data distribution, and can make only limited progress without collecting additional on-policy data. As a step towards more robust off-policy algorithms, we study the setting where the off-policy experience is fixed and there is no further interaction with the environment. We identify bootstrapping error as a key source of instability in current methods. Bootstrapping error is due to bootstrapping from actions that lie outside of the training data distribution, and it accumulates via the Bellman backup operator. We theoretically analyze bootstrapping error, and demonstrate how carefully constraining action selection in the backup can mitigate it. Based on our analysis, we propose a practical algorithm, bootstrapping error accumulation reduction (BEAR). We demonstrate that BEAR is able to learn robustly from different off-policy distributions, including random and suboptimal demonstrations, on a range of continuous control tasks.
Extending Deep Model Predictive Control with Safety Augmented Value Estimation from Demonstrations
Jun 03, 2019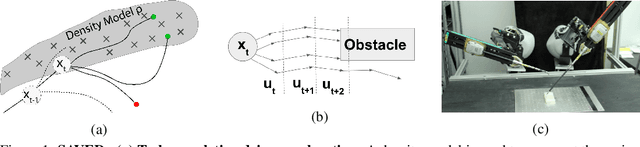
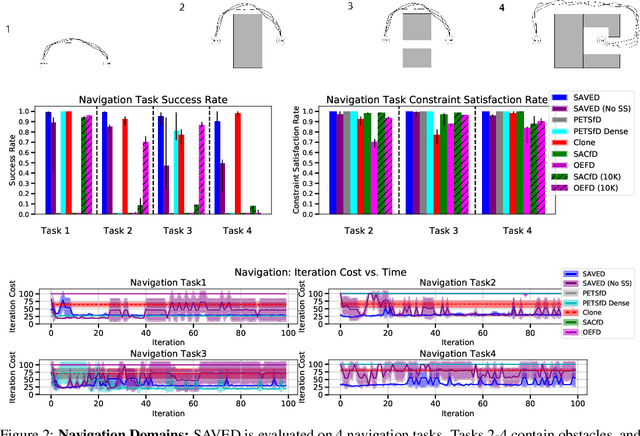

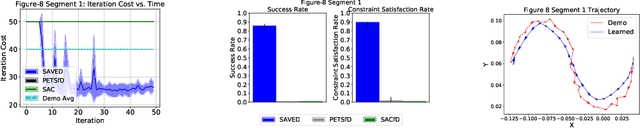
Reinforcement learning (RL) for robotics is challenging due to the difficulty in hand-engineering a dense cost function, which can lead to unintended behavior, and dynamical uncertainty, which makes it hard to enforce constraints during learning. We address these issues with a new model-based reinforcement learning algorithm, safety augmented value estimation from demonstrations (SAVED), which uses supervision that only identifies task completion and a modest set of suboptimal demonstrations to constrain exploration and learn efficiently while handling complex constraints. We derive iterative improvement guarantees for SAVED under known stochastic nonlinear systems. We then compare SAVED with 3 state-of-the-art model-based and model-free RL algorithms on 6 standard simulation benchmarks involving navigation and manipulation and 2 real-world tasks on the da Vinci surgical robot. Results suggest that SAVED outperforms prior methods in terms of success rate, constraint satisfaction, and sample efficiency, making it feasible to safely learn complex maneuvers directly on a real robot in less than an hour. For tasks on the robot, baselines succeed less than 5% of the time while SAVED has a success rate of over 75% in the first 50 training iterations.
Causal Confusion in Imitation Learning
May 28, 2019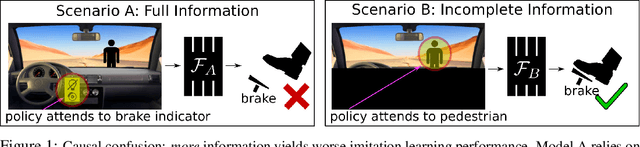
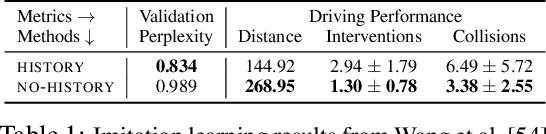
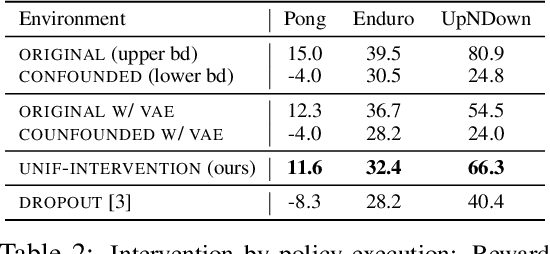
Behavioral cloning reduces policy learning to supervised learning by training a discriminative model to predict expert actions given observations. Such discriminative models are non-causal: the training procedure is unaware of the causal structure of the interaction between the expert and the environment. We point out that ignoring causality is particularly damaging because of the distributional shift in imitation learning. In particular, it leads to a counter-intuitive "causal confusion" phenomenon: access to more information can yield worse performance. We investigate how this problem arises, and propose a solution to combat it through targeted interventions---either environment interaction or expert queries---to determine the correct causal model. We show that causal confusion occurs in several benchmark control domains as well as realistic driving settings, and validate our solution against DAgger and other baselines and ablations.
Adversarial Policies: Attacking Deep Reinforcement Learning
May 25, 2019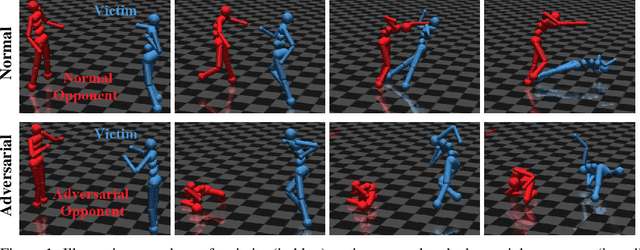

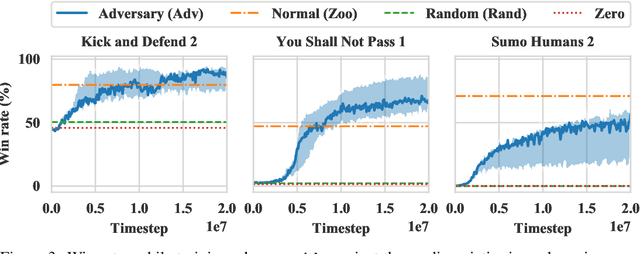
Deep reinforcement learning (RL) policies are known to be vulnerable to adversarial perturbations to their observations, similar to adversarial examples for classifiers. However, an attacker is not usually able to directly modify another agent's observations. This might lead one to wonder: is it possible to attack an RL agent simply by choosing an adversarial policy acting in a multi-agent environment so as to create natural observations that are adversarial? We demonstrate the existence of adversarial policies in zero-sum games between simulated humanoid robots with proprioceptive observations, against state-of-the-art victims trained via self-play to be robust to opponents. The adversarial policies reliably win against the victims but generate seemingly random and uncoordinated behavior. We find that these policies are more successful in high-dimensional environments, and induce substantially different activations in the victim policy network than when the victim plays against a normal opponent. Videos are available at http://adversarialpolicies.github.io.
MCP: Learning Composable Hierarchical Control with Multiplicative Compositional Policies
May 23, 2019

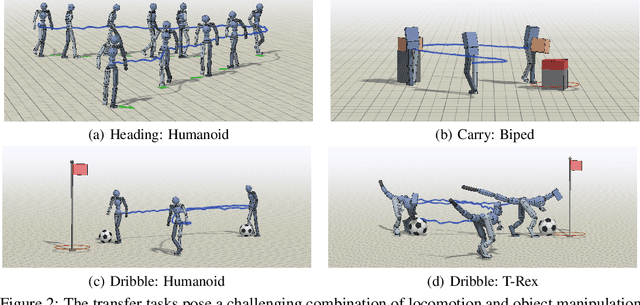
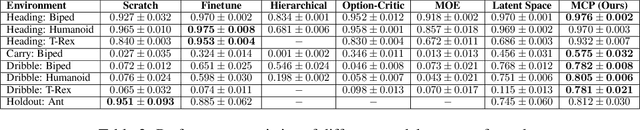
Humans are able to perform a myriad of sophisticated tasks by drawing upon skills acquired through prior experience. For autonomous agents to have this capability, they must be able to extract reusable skills from past experience that can be recombined in new ways for subsequent tasks. Furthermore, when controlling complex high-dimensional morphologies, such as humanoid bodies, tasks often require coordination of multiple skills simultaneously. Learning discrete primitives for every combination of skills quickly becomes prohibitive. Composable primitives that can be recombined to create a large variety of behaviors can be more suitable for modeling this combinatorial explosion. In this work, we propose multiplicative compositional policies (MCP), a method for learning reusable motor skills that can be composed to produce a range of complex behaviors. Our method factorizes an agent's skills into a collection of primitives, where multiple primitives can be activated simultaneously via multiplicative composition. This flexibility allows the primitives to be transferred and recombined to elicit new behaviors as necessary for novel tasks. We demonstrate that MCP is able to extract composable skills for highly complex simulated characters from pre-training tasks, such as motion imitation, and then reuse these skills to solve challenging continuous control tasks, such as dribbling a soccer ball to a goal, and picking up an object and transporting it to a target location.
REPLAB: A Reproducible Low-Cost Arm Benchmark Platform for Robotic Learning
May 17, 2019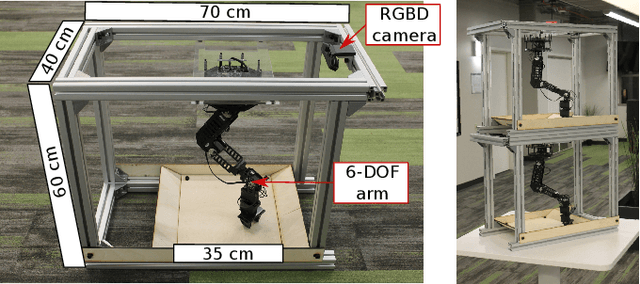



Standardized evaluation measures have aided in the progress of machine learning approaches in disciplines such as computer vision and machine translation. In this paper, we make the case that robotic learning would also benefit from benchmarking, and present the "REPLAB" platform for benchmarking vision-based manipulation tasks. REPLAB is a reproducible and self-contained hardware stack (robot arm, camera, and workspace) that costs about 2000 USD, occupies a cuboid of size 70x40x60 cm, and permits full assembly within a few hours. Through this low-cost, compact design, REPLAB aims to drive wide participation by lowering the barrier to entry into robotics and to enable easy scaling to many robots. We envision REPLAB as a framework for reproducible research across manipulation tasks, and as a step in this direction, we define a template for a grasping benchmark consisting of a task definition, evaluation protocol, performance measures, and a dataset of 92k grasp attempts. We implement, evaluate, and analyze several previously proposed grasping approaches to establish baselines for this benchmark. Finally, we also implement and evaluate a deep reinforcement learning approach for 3D reaching tasks on our REPLAB platform. Project page with assembly instructions, code, and videos: https://goo.gl/5F9dP4.
End-to-End Robotic Reinforcement Learning without Reward Engineering
May 16, 2019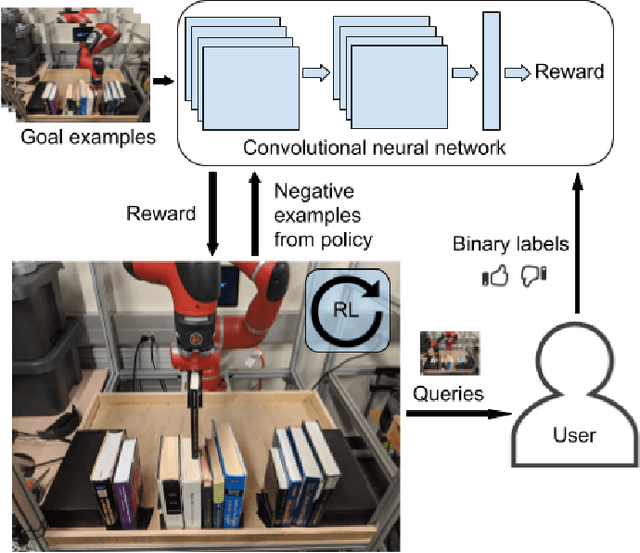
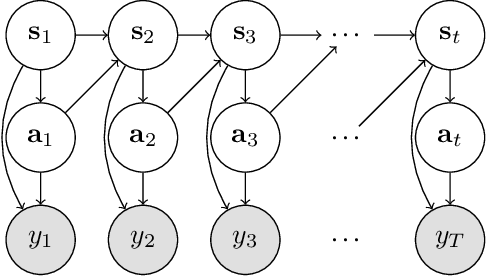
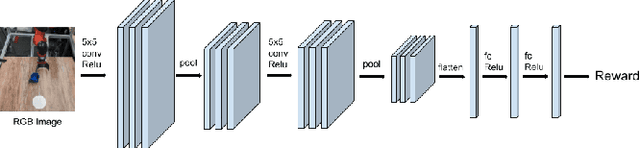

The combination of deep neural network models and reinforcement learning algorithms can make it possible to learn policies for robotic behaviors that directly read in raw sensory inputs, such as camera images, effectively subsuming both estimation and control into one model. However, real-world applications of reinforcement learning must specify the goal of the task by means of a manually programmed reward function, which in practice requires either designing the very same perception pipeline that end-to-end reinforcement learning promises to avoid, or else instrumenting the environment with additional sensors to determine if the task has been performed successfully. In this paper, we propose an approach for removing the need for manual engineering of reward specifications by enabling a robot to learn from a modest number of examples of successful outcomes, followed by actively solicited queries, where the robot shows the user a state and asks for a label to determine whether that state represents successful completion of the task. While requesting labels for every single state would amount to asking the user to manually provide the reward signal, our method requires labels for only a tiny fraction of the states seen during training, making it an efficient and practical approach for learning skills without manually engineered rewards. We evaluate our method on real-world robotic manipulation tasks where the observations consist of images viewed by the robot's camera. In our experiments, our method effectively learns to arrange objects, place books, and drape cloth, directly from images and without any manually specified reward functions, and with only 1-4 hours of interaction with the real world.
PRECOG: PREdiction Conditioned On Goals in Visual Multi-Agent Settings
May 07, 2019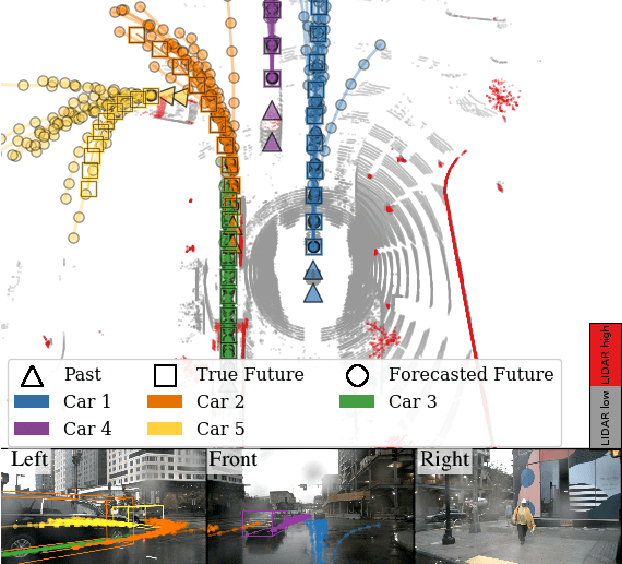
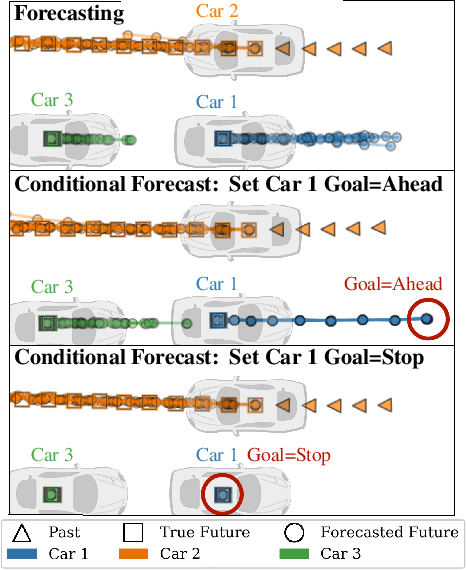
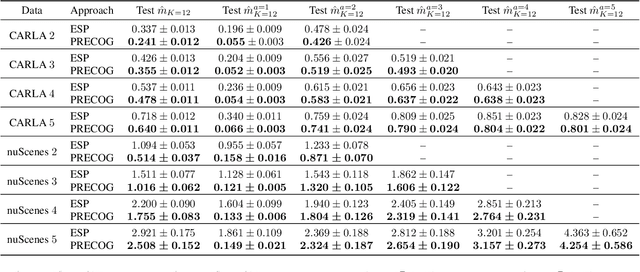
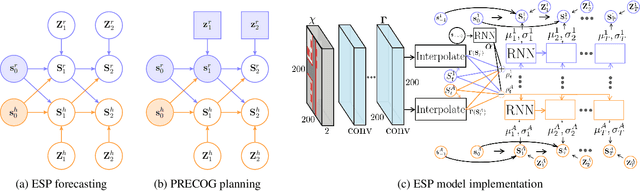
For autonomous vehicles (AVs) to behave appropriately on roads populated by human-driven vehicles, they must be able to reason about the uncertain intentions and decisions of other drivers from rich perceptual information. Towards these capabilities, we present a probabilistic forecasting model of future interactions of multiple agents. We perform both standard forecasting and conditional forecasting with respect to the AV's goals. Conditional forecasting reasons about how all agents will likely respond to specific decisions of a controlled agent. We train our model on real and simulated data to forecast vehicle trajectories given past positions and LIDAR. Our evaluation shows that our model is substantially more accurate in multi-agent driving scenarios compared to existing state-of-the-art. Beyond its general ability to perform conditional forecasting queries, we show that our model's predictions of all agents improve when conditioned on knowledge of the AV's intentions, further illustrating its capability to model agent interactions.