 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCautious Adaptation For Reinforcement Learning in Safety-Critical Settings
Aug 15, 2020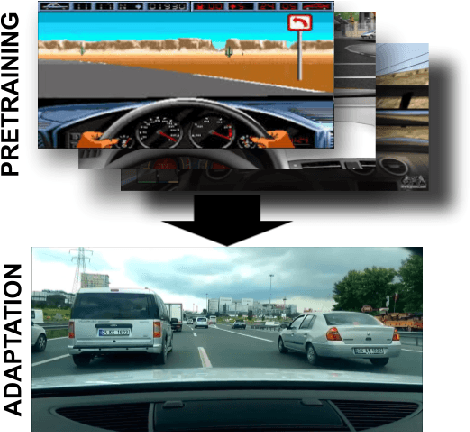


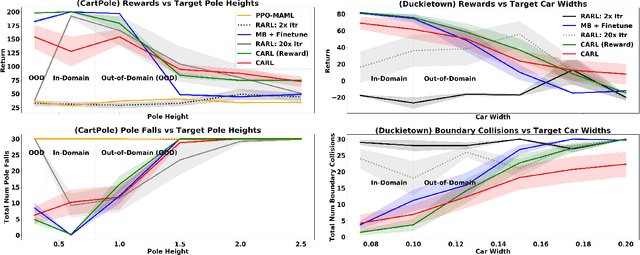
Reinforcement learning (RL) in real-world safety-critical target settings like urban driving is hazardous, imperiling the RL agent, other agents, and the environment. To overcome this difficulty, we propose a "safety-critical adaptation" task setting: an agent first trains in non-safety-critical "source" environments such as in a simulator, before it adapts to the target environment where failures carry heavy costs. We propose a solution approach, CARL, that builds on the intuition that prior experience in diverse environments equips an agent to estimate risk, which in turn enables relative safety through risk-averse, cautious adaptation. CARL first employs model-based RL to train a probabilistic model to capture uncertainty about transition dynamics and catastrophic states across varied source environments. Then, when exploring a new safety-critical environment with unknown dynamics, the CARL agent plans to avoid actions that could lead to catastrophic states. In experiments on car driving, cartpole balancing, half-cheetah locomotion, and robotic object manipulation, CARL successfully acquires cautious exploration behaviors, yielding higher rewards with fewer failures than strong RL adaptation baselines. Website at https://sites.google.com/berkeley.edu/carl.
Offline Meta-Reinforcement Learning with Advantage Weighting
Aug 13, 2020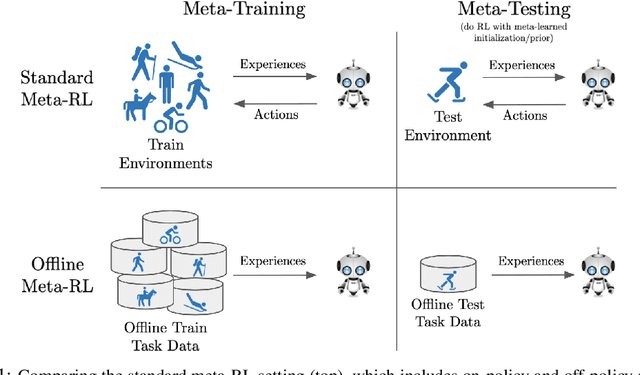
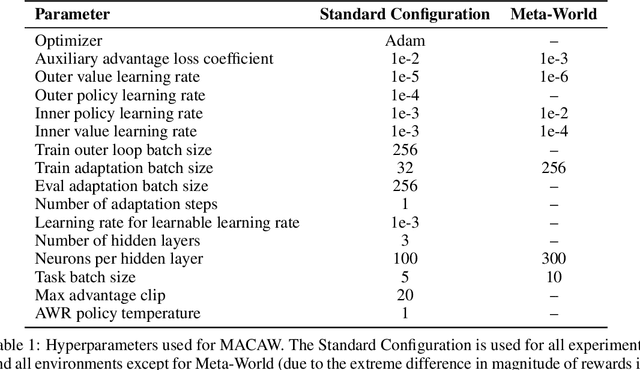
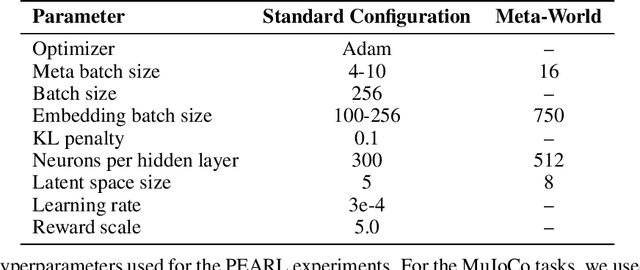
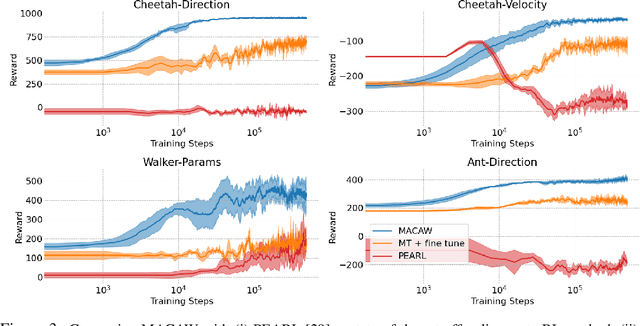
Massive datasets have proven critical to successfully applying deep learning to real-world problems, catalyzing progress on tasks such as object recognition, speech transcription, and machine translation. In this work, we study an analogous problem within reinforcement learning: can we enable an agent to leverage large, diverse experiences from previous tasks in order to quickly learn a new task? While recent work has shown some promise towards offline reinforcement learning, considerably less work has studied how we might leverage offline behavioral data when transferring to new tasks. To address this gap, we consider the problem setting of offline meta-reinforcement learning. By nature of being offline, algorithms for offline meta-RL can utilize the largest possible pool of training data available, and eliminate potentially unsafe or costly data collection during meta-training. Targeting this setting, we propose Meta-Actor Critic with Advantage Weighting (MACAW), an optimization-based meta-learning algorithm that uses simple, supervised regression objectives for both inner-loop adaptation and outer-loop meta-learning. To our knowledge, MACAW is the first successful combination of gradient-based meta-learning and value-based reinforcement learning. We empirically find that this approach enables fully offline meta-reinforcement learning and achieves notable gains over prior methods in some settings.
Assisted Perception: Optimizing Observations to Communicate State
Aug 06, 2020



We aim to help users estimate the state of the world in tasks like robotic teleoperation and navigation with visual impairments, where users may have systematic biases that lead to suboptimal behavior: they might struggle to process observations from multiple sensors simultaneously, receive delayed observations, or overestimate distances to obstacles. While we cannot directly change the user's internal beliefs or their internal state estimation process, our insight is that we can still assist them by modifying the user's observations. Instead of showing the user their true observations, we synthesize new observations that lead to more accurate internal state estimates when processed by the user. We refer to this method as assistive state estimation (ASE): an automated assistant uses the true observations to infer the state of the world, then generates a modified observation for the user to consume (e.g., through an augmented reality interface), and optimizes the modification to induce the user's new beliefs to match the assistant's current beliefs. We evaluate ASE in a user study with 12 participants who each perform four tasks: two tasks with known user biases -- bandwidth-limited image classification and a driving video game with observation delay -- and two with unknown biases that our method has to learn -- guided 2D navigation and a lunar lander teleoperation video game. A different assistance strategy emerges in each domain, such as quickly revealing informative pixels to speed up image classification, using a dynamics model to undo observation delay in driving, identifying nearby landmarks for navigation, and exaggerating a visual indicator of tilt in the lander game. The results show that ASE substantially improves the task performance of users with bandwidth constraints, observation delay, and other unknown biases.
Adaptive Risk Minimization: A Meta-Learning Approach for Tackling Group Shift
Jul 06, 2020
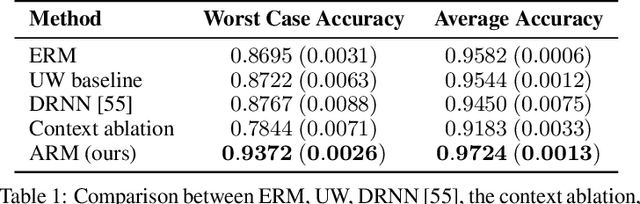
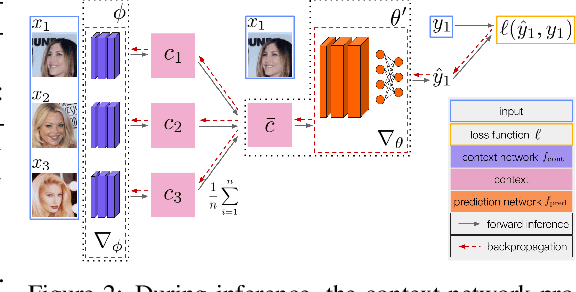
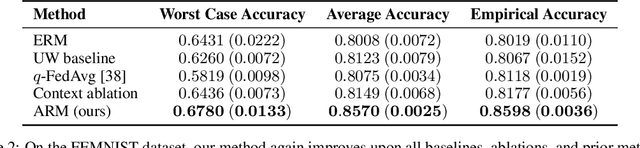
A fundamental assumption of most machine learning algorithms is that the training and test data are drawn from the same underlying distribution. However, this assumption is violated in almost all practical applications: machine learning systems are regularly tested on data that are structurally different from the training set, either due to temporal correlations, particular end users, or other factors. In this work, we consider the setting where test examples are not drawn from the training distribution. Prior work has approached this problem by attempting to be robust to all possible test time distributions, which may degrade average performance, or by "peeking" at the test examples during training, which is not always feasible. In contrast, we propose to learn models that are adaptable, such that they can adapt to distribution shift at test time using a batch of unlabeled test data points. We acquire such models by learning to adapt to training batches sampled according to different sub-distributions, which simulate structural distribution shifts that may occur at test time. We introduce the problem of adaptive risk minimization (ARM), a formalization of this setting that lends itself to meta-learning methods. Compared to a variety of methods under the paradigms of empirical risk minimization and robust optimization, our approach provides substantial empirical gains on image classification problems in the presence of distribution shift.
Decentralized Reinforcement Learning: Global Decision-Making via Local Economic Transactions
Jul 05, 2020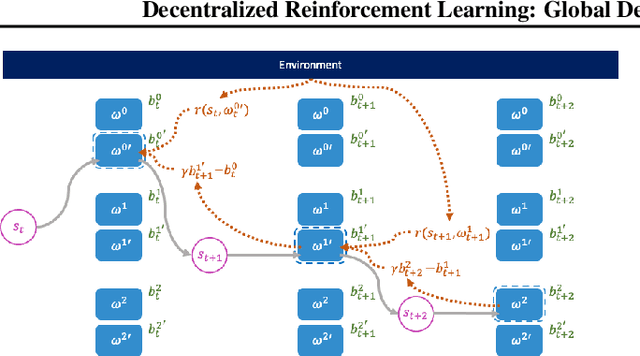
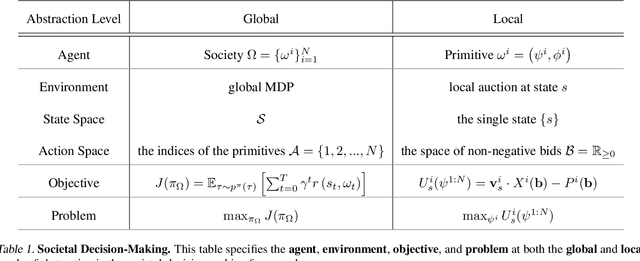
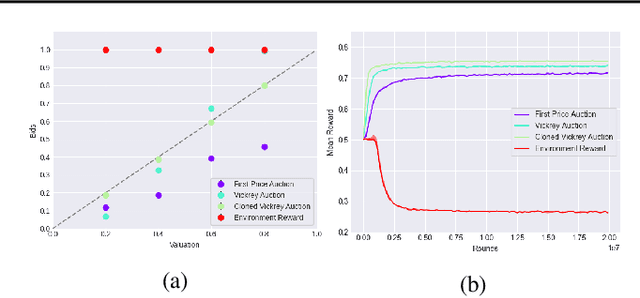
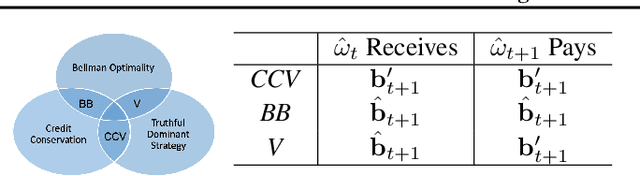
This paper seeks to establish a framework for directing a society of simple, specialized, self-interested agents to solve what traditionally are posed as monolithic single-agent sequential decision problems. What makes it challenging to use a decentralized approach to collectively optimize a central objective is the difficulty in characterizing the equilibrium strategy profile of non-cooperative games. To overcome this challenge, we design a mechanism for defining the learning environment of each agent for which we know that the optimal solution for the global objective coincides with a Nash equilibrium strategy profile of the agents optimizing their own local objectives. The society functions as an economy of agents that learn the credit assignment process itself by buying and selling to each other the right to operate on the environment state. We derive a class of decentralized reinforcement learning algorithms that are broadly applicable not only to standard reinforcement learning but also for selecting options in semi-MDPs and dynamically composing computation graphs. Lastly, we demonstrate the potential advantages of a society's inherent modular structure for more efficient transfer learning.
Object Files and Schemata: Factorizing Declarative and Procedural Knowledge in Dynamical Systems
Jun 30, 2020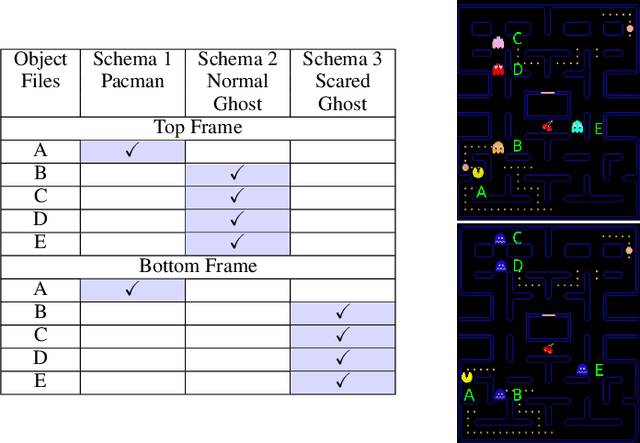
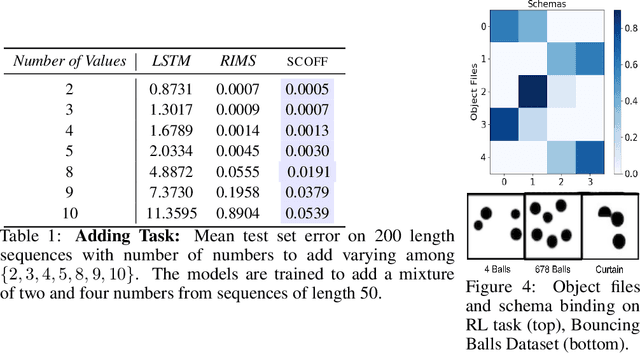
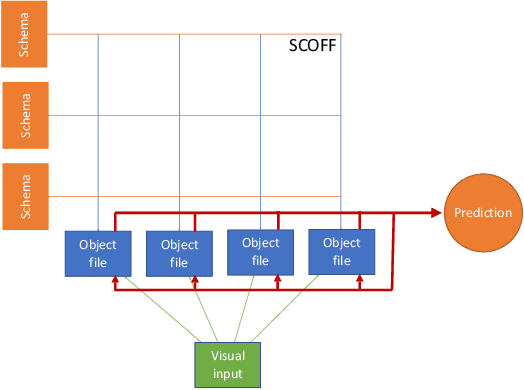

Modeling a structured, dynamic environment like a video game requires keeping track of the objects and their states (\emph{declarative} knowledge) as well as predicting how objects behave (\emph{procedural} knowledge). Black-box models with a monolithic hidden state often lack \emph{systematicity}: they fail to apply procedural knowledge consistently and uniformly. For example, in a video game, correct prediction of one enemy's trajectory does not ensure correct prediction of another's. We address this issue via an architecture that factorizes declarative and procedural knowledge and that imposes modularity within each form of knowledge. The architecture consists of active modules called \emph{object files} that maintain the state of a single object and invoke passive external knowledge sources called \emph{schemata} that prescribe state updates. To use a video game as an illustration, two enemies of the same type will share schemata but will each have their own object file to encode their distinct state (e.g., health, position). We propose to use attention to control the determination of which object files to update, the selection of schemata, and the propagation of information between object files. The resulting architecture is a drop-in replacement conforming to the same input-output interface as normal recurrent networks (e.g., LSTM, GRU) yet achieves substantially better generalization on environments that have factorized declarative and procedural knowledge, including a challenging intuitive physics benchmark.
Conservative Q-Learning for Offline Reinforcement Learning
Jun 29, 2020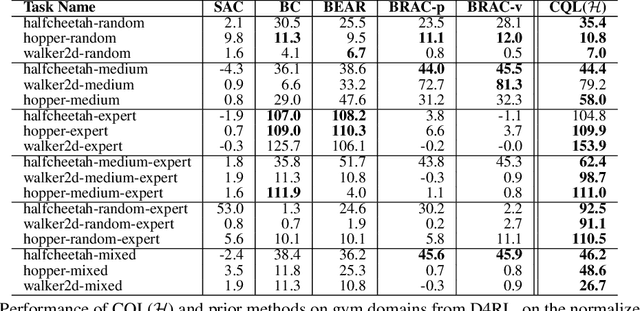

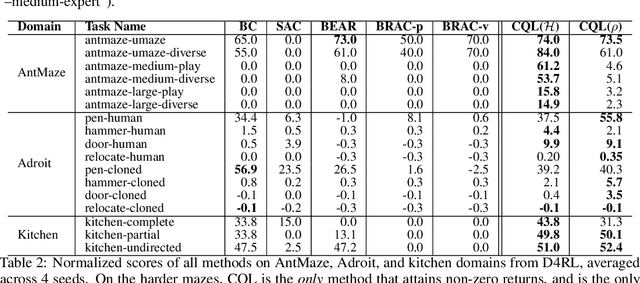
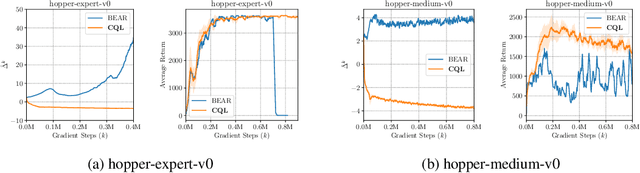
Effectively leveraging large, previously collected datasets in reinforcement learning (RL) is a key challenge for large-scale real-world applications. Offline RL algorithms promise to learn effective policies from previously-collected, static datasets without further interaction. However, in practice, offline RL presents a major challenge, and standard off-policy RL methods can fail due to overestimation of values induced by the distributional shift between the dataset and the learned policy, especially when training on complex and multi-modal data distributions. In this paper, we propose conservative Q-learning (CQL), which aims to address these limitations by learning a conservative Q-function such that the expected value of a policy under this Q-function lower-bounds its true value. We theoretically show that CQL produces a lower bound on the value of the current policy and that it can be incorporated into a principled policy improvement procedure. In practice, CQL augments the standard Bellman error objective with a simple Q-value regularizer which is straightforward to implement on top of existing deep Q-learning and actor-critic implementations. On both discrete and continuous control domains, we show that CQL substantially outperforms existing offline RL methods, often learning policies that attain 2-5 times higher final return, especially when learning from complex and multi-modal data distributions.
Can Autonomous Vehicles Identify, Recover From, and Adapt to Distribution Shifts?
Jun 26, 2020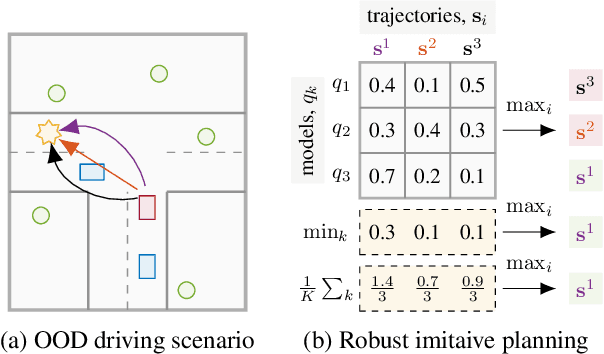


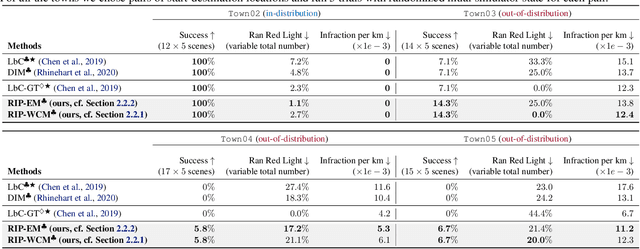
Out-of-training-distribution (OOD) scenarios are a common challenge of learning agents at deployment, typically leading to arbitrary deductions and poorly-informed decisions. In principle, detection of and adaptation to OOD scenes can mitigate their adverse effects. In this paper, we highlight the limitations of current approaches to novel driving scenes and propose an epistemic uncertainty-aware planning method, called \emph{robust imitative planning} (RIP). Our method can detect and recover from some distribution shifts, reducing the overconfident and catastrophic extrapolations in OOD scenes. If the model's uncertainty is too great to suggest a safe course of action, the model can instead query the expert driver for feedback, enabling sample-efficient online adaptation, a variant of our method we term \emph{adaptive robust imitative planning} (AdaRIP). Our methods outperform current state-of-the-art approaches in the nuScenes \emph{prediction} challenge, but since no benchmark evaluating OOD detection and adaption currently exists to assess \emph{control}, we introduce an autonomous car novel-scene benchmark, \texttt{CARNOVEL}, to evaluate the robustness of driving agents to a suite of tasks with distribution shifts.
Off-Dynamics Reinforcement Learning: Training for Transfer with Domain Classifiers
Jun 24, 2020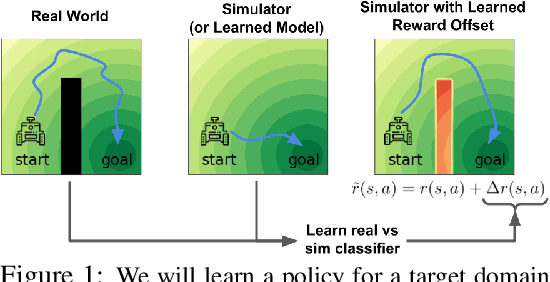
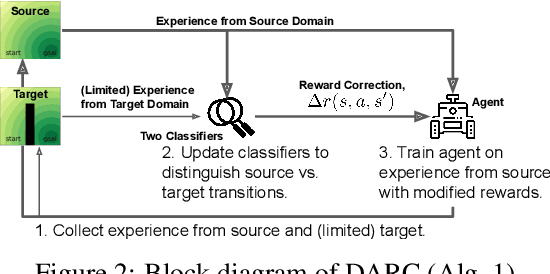
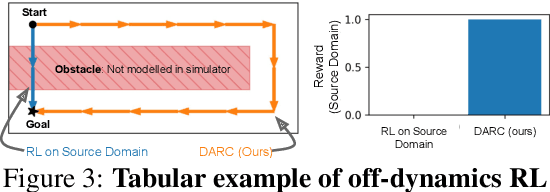
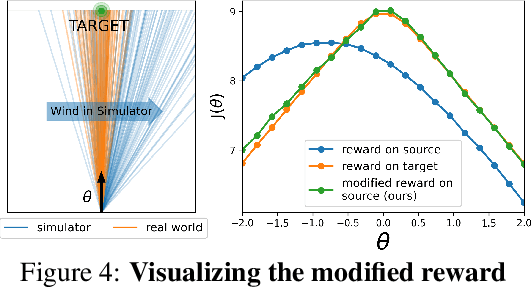
We propose a simple, practical, and intuitive approach for domain adaptation in reinforcement learning. Our approach stems from the idea that the agent's experience in the source domain should look similar to its experience in the target domain. Building off of a probabilistic view of RL, we formally show that we can achieve this goal by compensating for the difference in dynamics by modifying the reward function. This modified reward function is simple to estimate by learning auxiliary classifiers that distinguish source-domain transitions from target-domain transitions. Intuitively, the modified reward function penalizes the agent for visiting states and taking actions in the source domain which are not possible in the target domain. Said another way, the agent is penalized for transitions that would indicate that the agent is interacting with the source domain, rather than the target domain. Our approach is applicable to domains with continuous states and actions and does not require learning an explicit model of the dynamics. On discrete and continuous control tasks, we illustrate the mechanics of our approach and demonstrate its scalability to high-dimensional tasks.
Long-Horizon Visual Planning with Goal-Conditioned Hierarchical Predictors
Jun 23, 2020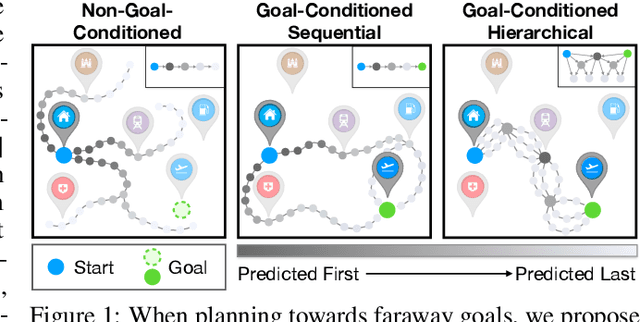
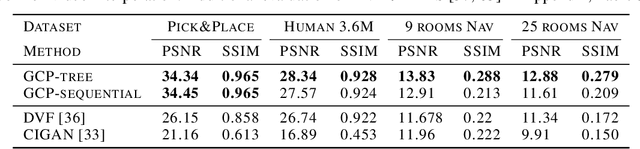

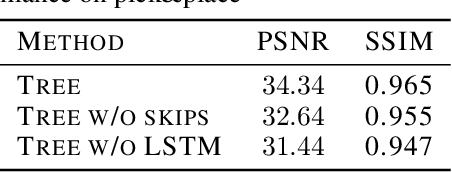
The ability to predict and plan into the future is fundamental for agents acting in the world. To reach a faraway goal, we predict trajectories at multiple timescales, first devising a coarse plan towards the goal and then gradually filling in details. In contrast, current learning approaches for visual prediction and planning fail on long-horizon tasks as they generate predictions (1) without considering goal information, and (2) at the finest temporal resolution, one step at a time. In this work we propose a framework for visual prediction and planning that is able to overcome both of these limitations. First, we formulate the problem of predicting towards a goal and propose the corresponding class of latent space goal-conditioned predictors (GCPs). GCPs significantly improve planning efficiency by constraining the search space to only those trajectories that reach the goal. Further, we show how GCPs can be naturally formulated as hierarchical models that, given two observations, predict an observation between them, and by recursively subdividing each part of the trajectory generate complete sequences. This divide-and-conquer strategy is effective at long-term prediction, and enables us to design an effective hierarchical planning algorithm that optimizes trajectories in a coarse-to-fine manner. We show that by using both goal-conditioning and hierarchical prediction, GCPs enable us to solve visual planning tasks with much longer horizon than previously possible.