 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMADE: Benchmark Environments for Closed-Loop Materials Discovery
Jan 28, 2026Existing benchmarks for computational materials discovery primarily evaluate static predictive tasks or isolated computational sub-tasks. While valuable, these evaluations neglect the inherently iterative and adaptive nature of scientific discovery. We introduce MAterials Discovery Environments (MADE), a novel framework for benchmarking end-to-end autonomous materials discovery pipelines. MADE simulates closed-loop discovery campaigns in which an agent or algorithm proposes, evaluates, and refines candidate materials under a constrained oracle budget, capturing the sequential and resource-limited nature of real discovery workflows. We formalize discovery as a search for thermodynamically stable compounds relative to a given convex hull, and evaluate efficacy and efficiency via comparison to baseline algorithms. The framework is flexible; users can compose discovery agents from interchangeable components such as generative models, filters, and planners, enabling the study of arbitrary workflows ranging from fixed pipelines to fully agentic systems with tool use and adaptive decision making. We demonstrate this by conducting systematic experiments across a family of systems, enabling ablation of components in discovery pipelines, and comparison of how methods scale with system complexity.
Deep Bayesian Active Learning for Preference Modeling in Large Language Models
Jun 14, 2024



Leveraging human preferences for steering the behavior of Large Language Models (LLMs) has demonstrated notable success in recent years. Nonetheless, data selection and labeling are still a bottleneck for these systems, particularly at large scale. Hence, selecting the most informative points for acquiring human feedback may considerably reduce the cost of preference labeling and unleash the further development of LLMs. Bayesian Active Learning provides a principled framework for addressing this challenge and has demonstrated remarkable success in diverse settings. However, previous attempts to employ it for Preference Modeling did not meet such expectations. In this work, we identify that naive epistemic uncertainty estimation leads to the acquisition of redundant samples. We address this by proposing the Bayesian Active Learner for Preference Modeling (BAL-PM), a novel stochastic acquisition policy that not only targets points of high epistemic uncertainty according to the preference model but also seeks to maximize the entropy of the acquired prompt distribution in the feature space spanned by the employed LLM. Notably, our experiments demonstrate that BAL-PM requires 33% to 68% fewer preference labels in two popular human preference datasets and exceeds previous stochastic Bayesian acquisition policies.
Challenges and Considerations in the Evaluation of Bayesian Causal Discovery
Jun 05, 2024



Representing uncertainty in causal discovery is a crucial component for experimental design, and more broadly, for safe and reliable causal decision making. Bayesian Causal Discovery (BCD) offers a principled approach to encapsulating this uncertainty. Unlike non-Bayesian causal discovery, which relies on a single estimated causal graph and model parameters for assessment, evaluating BCD presents challenges due to the nature of its inferred quantity - the posterior distribution. As a result, the research community has proposed various metrics to assess the quality of the approximate posterior. However, there is, to date, no consensus on the most suitable metric(s) for evaluation. In this work, we reexamine this question by dissecting various metrics and understanding their limitations. Through extensive empirical evaluation, we find that many existing metrics fail to exhibit a strong correlation with the quality of approximation to the true posterior, especially in scenarios with low sample sizes where BCD is most desirable. We highlight the suitability (or lack thereof) of these metrics under two distinct factors: the identifiability of the underlying causal model and the quantity of available data. Both factors affect the entropy of the true posterior, indicating that the current metrics are less fitting in settings of higher entropy. Our findings underline the importance of a more nuanced evaluation of new methods by taking into account the nature of the true posterior, as well as guide and motivate the development of new evaluation procedures for this challenge.
Amortized Active Causal Induction with Deep Reinforcement Learning
May 26, 2024We present Causal Amortized Active Structure Learning (CAASL), an active intervention design policy that can select interventions that are adaptive, real-time and that does not require access to the likelihood. This policy, an amortized network based on the transformer, is trained with reinforcement learning on a simulator of the design environment, and a reward function that measures how close the true causal graph is to a causal graph posterior inferred from the gathered data. On synthetic data and a single-cell gene expression simulator, we demonstrate empirically that the data acquired through our policy results in a better estimate of the underlying causal graph than alternative strategies. Our design policy successfully achieves amortized intervention design on the distribution of the training environment while also generalizing well to distribution shifts in test-time design environments. Further, our policy also demonstrates excellent zero-shot generalization to design environments with dimensionality higher than that during training, and to intervention types that it has not been trained on.
Differentiable Multi-Target Causal Bayesian Experimental Design
Feb 21, 2023



We introduce a gradient-based approach for the problem of Bayesian optimal experimental design to learn causal models in a batch setting -- a critical component for causal discovery from finite data where interventions can be costly or risky. Existing methods rely on greedy approximations to construct a batch of experiments while using black-box methods to optimize over a single target-state pair to intervene with. In this work, we completely dispose of the black-box optimization techniques and greedy heuristics and instead propose a conceptually simple end-to-end gradient-based optimization procedure to acquire a set of optimal intervention target-state pairs. Such a procedure enables parameterization of the design space to efficiently optimize over a batch of multi-target-state interventions, a setting which has hitherto not been explored due to its complexity. We demonstrate that our proposed method outperforms baselines and existing acquisition strategies in both single-target and multi-target settings across a number of synthetic datasets.
Modelling non-reinforced preferences using selective attention
Jul 25, 2022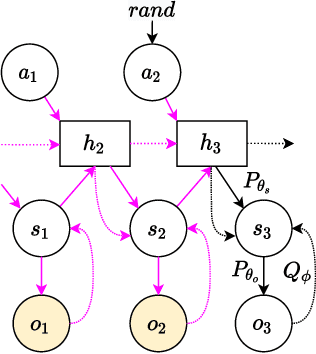
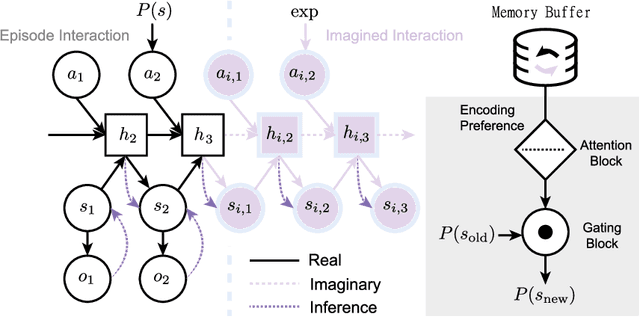
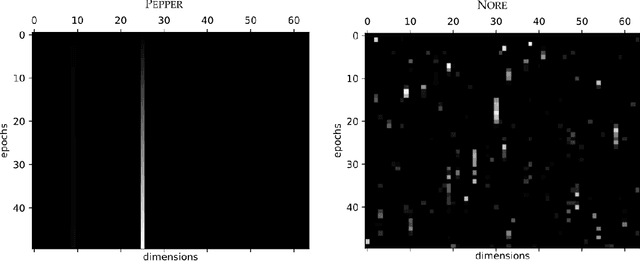
How can artificial agents learn non-reinforced preferences to continuously adapt their behaviour to a changing environment? We decompose this question into two challenges: ($i$) encoding diverse memories and ($ii$) selectively attending to these for preference formation. Our proposed \emph{no}n-\emph{re}inforced preference learning mechanism using selective attention, \textsc{Nore}, addresses both by leveraging the agent's world model to collect a diverse set of experiences which are interleaved with imagined roll-outs to encode memories. These memories are selectively attended to, using attention and gating blocks, to update agent's preferences. We validate \textsc{Nore} in a modified OpenAI Gym FrozenLake environment (without any external signal) with and without volatility under a fixed model of the environment -- and compare its behaviour to \textsc{Pepper}, a Hebbian preference learning mechanism. We demonstrate that \textsc{Nore} provides a straightforward framework to induce exploratory preferences in the absence of external signals.
Interventions, Where and How? Experimental Design for Causal Models at Scale
Mar 03, 2022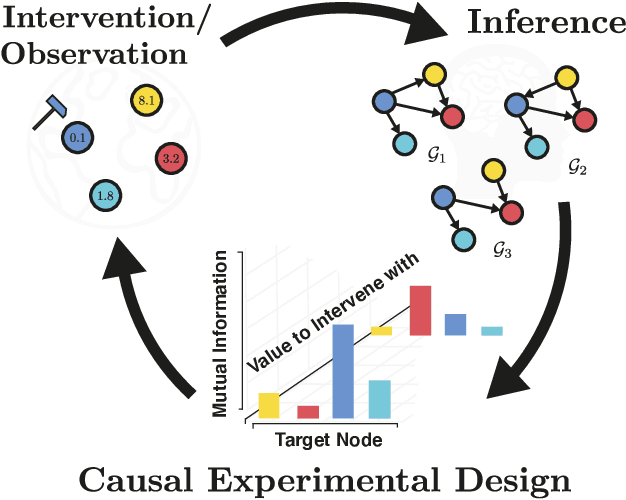
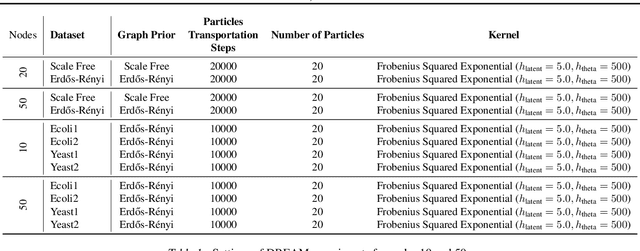
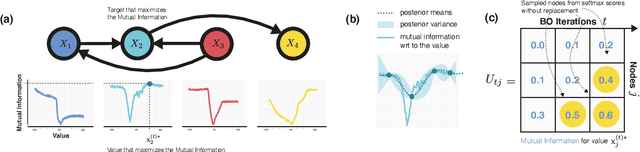
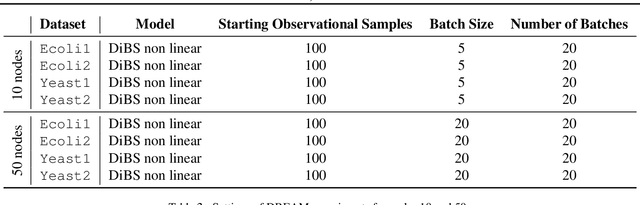
Causal discovery from observational and interventional data is challenging due to limited data and non-identifiability which introduces uncertainties in estimating the underlying structural causal model (SCM). Incorporating these uncertainties and selecting optimal experiments (interventions) to perform can help to identify the true SCM faster. Existing methods in experimental design for causal discovery from limited data either rely on linear assumptions for the SCM or select only the intervention target. In this paper, we incorporate recent advances in Bayesian causal discovery into the Bayesian optimal experimental design framework, which allows for active causal discovery of nonlinear, large SCMs, while selecting both the target and the value to intervene with. We demonstrate the performance of the proposed method on synthetic graphs (Erdos-R\`enyi, Scale Free) for both linear and nonlinear SCMs as well as on the in-silico single-cell gene regulatory network dataset, DREAM.
Causal-BALD: Deep Bayesian Active Learning of Outcomes to Infer Treatment-Effects from Observational Data
Nov 03, 2021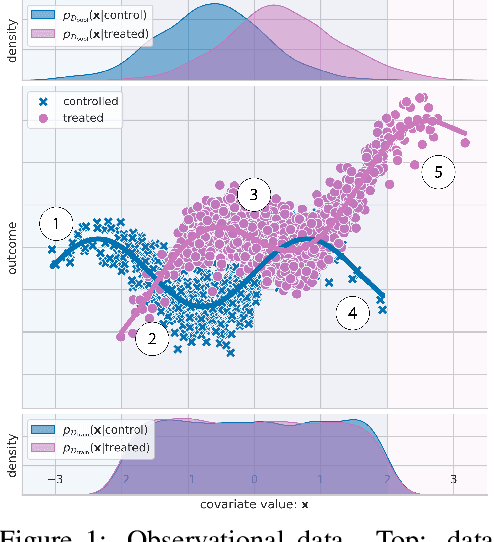
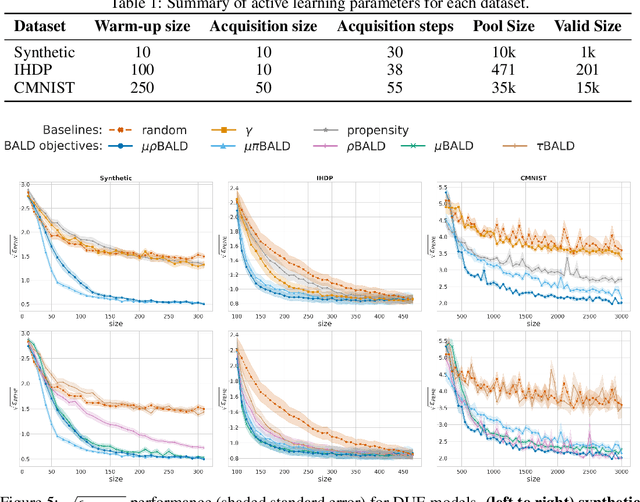
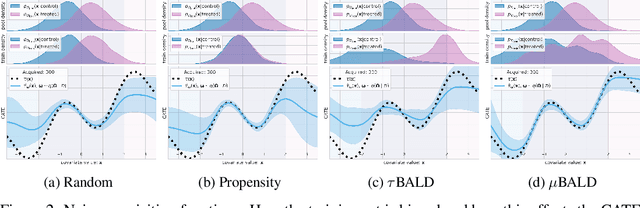

Estimating personalized treatment effects from high-dimensional observational data is essential in situations where experimental designs are infeasible, unethical, or expensive. Existing approaches rely on fitting deep models on outcomes observed for treated and control populations. However, when measuring individual outcomes is costly, as is the case of a tumor biopsy, a sample-efficient strategy for acquiring each result is required. Deep Bayesian active learning provides a framework for efficient data acquisition by selecting points with high uncertainty. However, existing methods bias training data acquisition towards regions of non-overlapping support between the treated and control populations. These are not sample-efficient because the treatment effect is not identifiable in such regions. We introduce causal, Bayesian acquisition functions grounded in information theory that bias data acquisition towards regions with overlapping support to maximize sample efficiency for learning personalized treatment effects. We demonstrate the performance of the proposed acquisition strategies on synthetic and semi-synthetic datasets IHDP and CMNIST and their extensions, which aim to simulate common dataset biases and pathologies.
Exploration and preference satisfaction trade-off in reward-free learning
Jun 08, 2021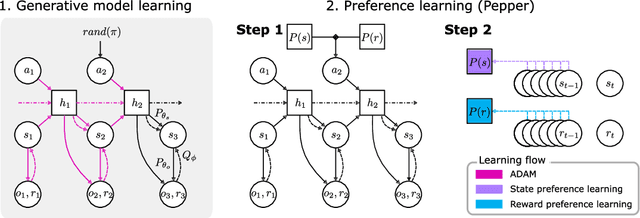

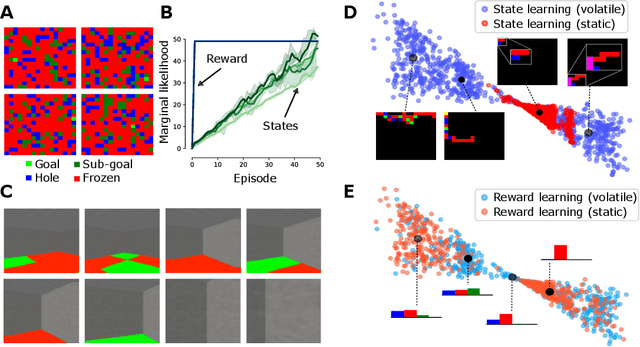

Biological agents have meaningful interactions with their environment despite the absence of a reward signal. In such instances, the agent can learn preferred modes of behaviour that lead to predictable states -- necessary for survival. In this paper, we pursue the notion that this learnt behaviour can be a consequence of reward-free preference learning that ensures an appropriate trade-off between exploration and preference satisfaction. For this, we introduce a model-based Bayesian agent equipped with a preference learning mechanism (pepper) using conjugate priors. These conjugate priors are used to augment the expected free energy planner for learning preferences over states (or outcomes) across time. Importantly, our approach enables the agent to learn preferences that encourage adaptive behaviour at test time. We illustrate this in the OpenAI Gym FrozenLake and the 3D mini-world environments -- with and without volatility. Given a constant environment, these agents learn confident (i.e., precise) preferences and act to satisfy them. Conversely, in a volatile setting, perpetual preference uncertainty maintains exploratory behaviour. Our experiments suggest that learnable (reward-free) preferences entail a trade-off between exploration and preference satisfaction. Pepper offers a straightforward framework suitable for designing adaptive agents when reward functions cannot be predefined as in real environments.
Global Earth Magnetic Field Modeling and Forecasting with Spherical Harmonics Decomposition
Feb 02, 2021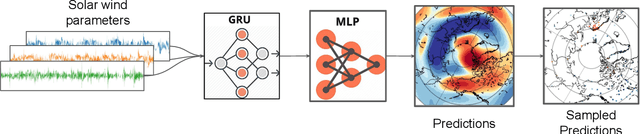


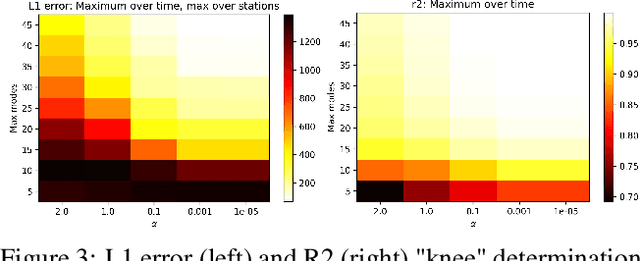
Modeling and forecasting the solar wind-driven global magnetic field perturbations is an open challenge. Current approaches depend on simulations of computationally demanding models like the Magnetohydrodynamics (MHD) model or sampling spatially and temporally through sparse ground-based stations (SuperMAG). In this paper, we develop a Deep Learning model that forecasts in Spherical Harmonics space 2, replacing reliance on MHD models and providing global coverage at one minute cadence, improving over the current state-of-the-art which relies on feature engineering. We evaluate the performance in SuperMAG dataset (improved by 14.53%) and MHD simulations (improved by 24.35%). Additionally, we evaluate the extrapolation performance of the spherical harmonics reconstruction based on sparse ground-based stations (SuperMAG), showing that spherical harmonics can reliably reconstruct the global magnetic field as evaluated on MHD simulation.