 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContracting with a Learning Agent
Jan 29, 2024Many real-life contractual relations differ completely from the clean, static model at the heart of principal-agent theory. Typically, they involve repeated strategic interactions of the principal and agent, taking place under uncertainty and over time. While appealing in theory, players seldom use complex dynamic strategies in practice, often preferring to circumvent complexity and approach uncertainty through learning. We initiate the study of repeated contracts with a learning agent, focusing on agents who achieve no-regret outcomes. Optimizing against a no-regret agent is a known open problem in general games; we achieve an optimal solution to this problem for a canonical contract setting, in which the agent's choice among multiple actions leads to success/failure. The solution has a surprisingly simple structure: for some $\alpha > 0$, initially offer the agent a linear contract with scalar $\alpha$, then switch to offering a linear contract with scalar $0$. This switch causes the agent to ``free-fall'' through their action space and during this time provides the principal with non-zero reward at zero cost. Despite apparent exploitation of the agent, this dynamic contract can leave \emph{both} players better off compared to the best static contract. Our results generalize beyond success/failure, to arbitrary non-linear contracts which the principal rescales dynamically. Finally, we quantify the dependence of our results on knowledge of the time horizon, and are the first to address this consideration in the study of strategizing against learning agents.
Decentralized Reinforcement Learning: Global Decision-Making via Local Economic Transactions
Jul 05, 2020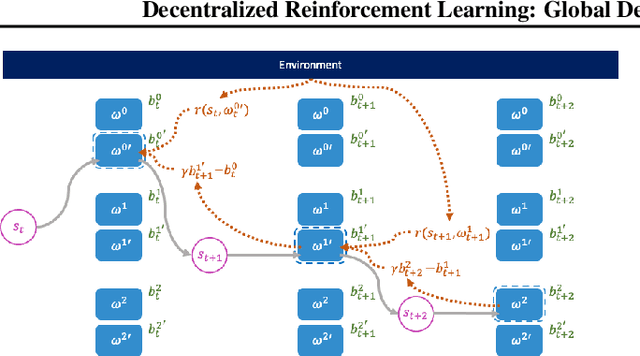
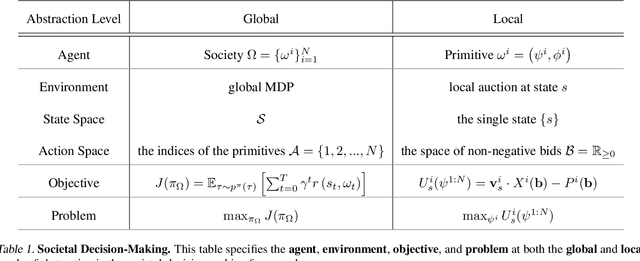
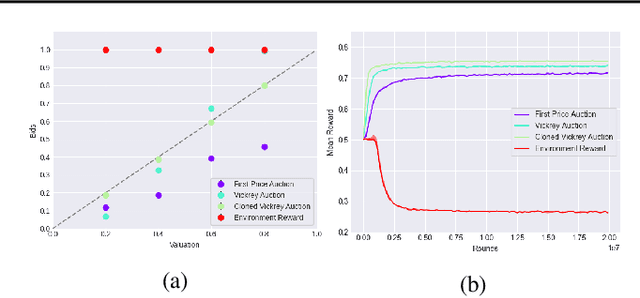
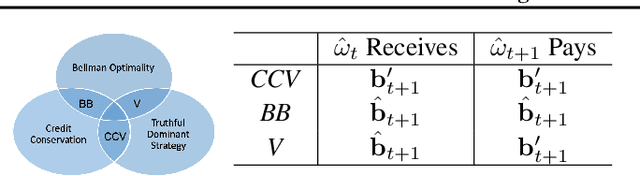
This paper seeks to establish a framework for directing a society of simple, specialized, self-interested agents to solve what traditionally are posed as monolithic single-agent sequential decision problems. What makes it challenging to use a decentralized approach to collectively optimize a central objective is the difficulty in characterizing the equilibrium strategy profile of non-cooperative games. To overcome this challenge, we design a mechanism for defining the learning environment of each agent for which we know that the optimal solution for the global objective coincides with a Nash equilibrium strategy profile of the agents optimizing their own local objectives. The society functions as an economy of agents that learn the credit assignment process itself by buying and selling to each other the right to operate on the environment state. We derive a class of decentralized reinforcement learning algorithms that are broadly applicable not only to standard reinforcement learning but also for selecting options in semi-MDPs and dynamically composing computation graphs. Lastly, we demonstrate the potential advantages of a society's inherent modular structure for more efficient transfer learning.
Auction learning as a two-player game
Jun 11, 2020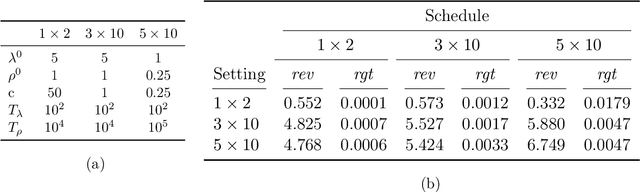
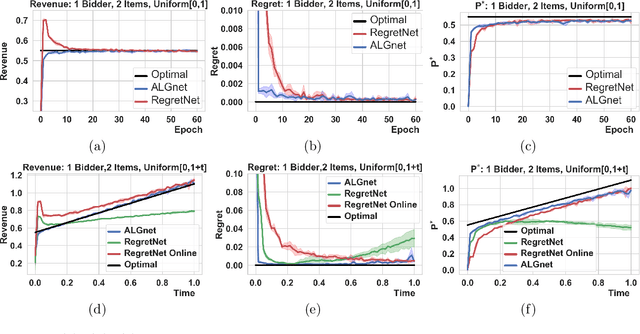
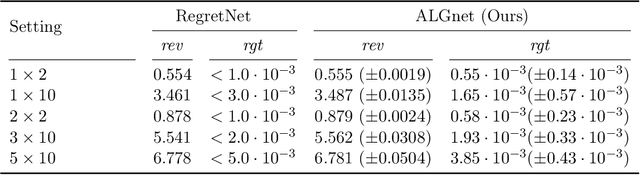
Designing an incentive compatible auction that maximizes expected revenue is a central problem in Auction Design. While theoretical approaches to the problem have hit some limits, a recent research direction initiated by Duetting et al. (2019) consists in building neural network architectures to find optimal auctions. We propose two conceptual deviations from their approach which result in enhanced performance. First, we use recent results in theoretical auction design (Rubinstein and Weinberg, 2018) to introduce a time-independent Lagrangian. This not only circumvents the need for an expensive hyper-parameter search (as in prior work), but also provides a principled metric to compare the performance of two auctions (absent from prior work). Second, the optimization procedure in previous work uses an inner maximization loop to compute optimal misreports. We amortize this process through the introduction of an additional neural network. We demonstrate the effectiveness of our approach by learning competitive or strictly improved auctions compared to prior work. Both results together further imply a novel formulation of Auction Design as a two-player game with stationary utility functions.
A Permutation-Equivariant Neural Network Architecture For Auction Design
Mar 02, 2020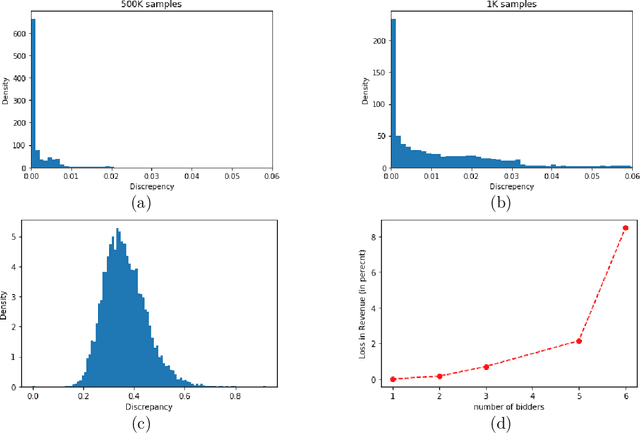
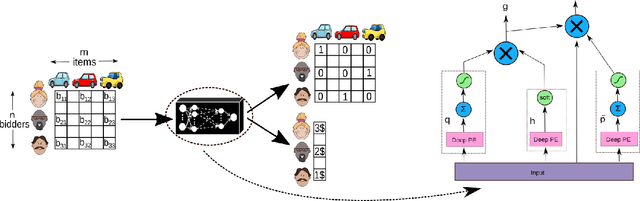
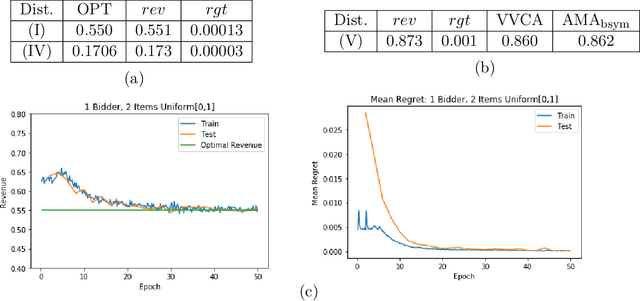
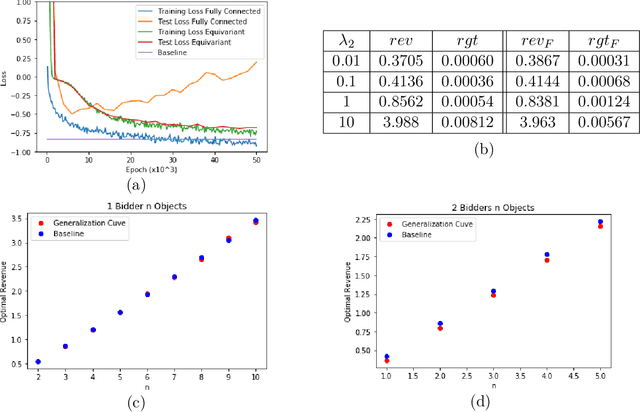
Designing an incentive compatible auction that maximizes expected revenue is a central problem in Auction Design. Theoretical approaches to the problem have hit some limits in the past decades and analytical solutions are known for only a few simple settings. Computational approaches to the problem through the use of LPs have their own set of limitations. Building on the success of deep learning, a new approach was recently proposed by D\"utting et al., 2017 in which the auction is modeled by a feed-forward neural network and the design problem is framed as a learning problem. The neural architectures used in that work are general purpose and do not take advantage of any of the symmetries the problem could present, such as permutation equivariance. In this work, we consider auction design problems that have permutation-equivariant symmetry and construct a neural architecture that is capable of perfectly recovering the permutation-equivariant optimal mechanism, which we show is not possible with the previous architecture. We demonstrate that permutation-equivariant architectures are not only capable of recovering previous results, they also have better generalization properties.
The Sample Complexity of Up-to-$\varepsilon$ Multi-Dimensional Revenue Maximization
Aug 07, 2018We consider the sample complexity of revenue maximization for multiple bidders in unrestricted multi-dimensional settings. Specifically, we study the standard model of $n$ additive bidders whose values for $m$ heterogeneous items are drawn independently. For any such instance and any $\varepsilon>0$, we show that it is possible to learn an $\varepsilon$-Bayesian Incentive Compatible auction whose expected revenue is within $\varepsilon$ of the optimal $\varepsilon$-BIC auction from only polynomially many samples. Our approach is based on ideas that hold quite generally, and completely sidestep the difficulty of characterizing optimal (or near-optimal) auctions for these settings. Therefore, our results easily extend to general multi-dimensional settings, including valuations that aren't necessarily even subadditive, and arbitrary allocation constraints. For the cases of a single bidder and many goods, or a single parameter (good) and many bidders, our analysis yields exact incentive compatibility (and for the latter also computational efficiency). Although the single-parameter case is already well-understood, our corollary for this case extends slightly the state-of-the-art.
Selling to a No-Regret Buyer
Nov 25, 2017We consider the problem of a single seller repeatedly selling a single item to a single buyer (specifically, the buyer has a value drawn fresh from known distribution $D$ in every round). Prior work assumes that the buyer is fully rational and will perfectly reason about how their bids today affect the seller's decisions tomorrow. In this work we initiate a different direction: the buyer simply runs a no-regret learning algorithm over possible bids. We provide a fairly complete characterization of optimal auctions for the seller in this domain. Specifically: - If the buyer bids according to EXP3 (or any "mean-based" learning algorithm), then the seller can extract expected revenue arbitrarily close to the expected welfare. This auction is independent of the buyer's valuation $D$, but somewhat unnatural as it is sometimes in the buyer's interest to overbid. - There exists a learning algorithm $\mathcal{A}$ such that if the buyer bids according to $\mathcal{A}$ then the optimal strategy for the seller is simply to post the Myerson reserve for $D$ every round. - If the buyer bids according to EXP3 (or any "mean-based" learning algorithm), but the seller is restricted to "natural" auction formats where overbidding is dominated (e.g. Generalized First-Price or Generalized Second-Price), then the optimal strategy for the seller is a pay-your-bid format with decreasing reserves over time. Moreover, the seller's optimal achievable revenue is characterized by a linear program, and can be unboundedly better than the best truthful auction yet simultaneously unboundedly worse than the expected welfare.
Multi-armed Bandit Problems with Strategic Arms
Jun 27, 2017We study a strategic version of the multi-armed bandit problem, where each arm is an individual strategic agent and we, the principal, pull one arm each round. When pulled, the arm receives some private reward $v_a$ and can choose an amount $x_a$ to pass on to the principal (keeping $v_a-x_a$ for itself). All non-pulled arms get reward $0$. Each strategic arm tries to maximize its own utility over the course of $T$ rounds. Our goal is to design an algorithm for the principal incentivizing these arms to pass on as much of their private rewards as possible. When private rewards are stochastically drawn each round ($v_a^t \leftarrow D_a$), we show that: - Algorithms that perform well in the classic adversarial multi-armed bandit setting necessarily perform poorly: For all algorithms that guarantee low regret in an adversarial setting, there exist distributions $D_1,\ldots,D_k$ and an approximate Nash equilibrium for the arms where the principal receives reward $o(T)$. - Still, there exists an algorithm for the principal that induces a game among the arms where each arm has a dominant strategy. When each arm plays its dominant strategy, the principal sees expected reward $\mu'T - o(T)$, where $\mu'$ is the second-largest of the means $\mathbb{E}[D_{a}]$. This algorithm maintains its guarantee if the arms are non-strategic ($x_a = v_a$), and also if there is a mix of strategic and non-strategic arms.