 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCapturing the motion of every joint: 3D human pose and shape estimation with independent tokens
Mar 01, 2023



In this paper we present a novel method to estimate 3D human pose and shape from monocular videos. This task requires directly recovering pixel-alignment 3D human pose and body shape from monocular images or videos, which is challenging due to its inherent ambiguity. To improve precision, existing methods highly rely on the initialized mean pose and shape as prior estimates and parameter regression with an iterative error feedback manner. In addition, video-based approaches model the overall change over the image-level features to temporally enhance the single-frame feature, but fail to capture the rotational motion at the joint level, and cannot guarantee local temporal consistency. To address these issues, we propose a novel Transformer-based model with a design of independent tokens. First, we introduce three types of tokens independent of the image feature: \textit{joint rotation tokens, shape token, and camera token}. By progressively interacting with image features through Transformer layers, these tokens learn to encode the prior knowledge of human 3D joint rotations, body shape, and position information from large-scale data, and are updated to estimate SMPL parameters conditioned on a given image. Second, benefiting from the proposed token-based representation, we further use a temporal model to focus on capturing the rotational temporal information of each joint, which is empirically conducive to preventing large jitters in local parts. Despite being conceptually simple, the proposed method attains superior performances on the 3DPW and Human3.6M datasets. Using ResNet-50 and Transformer architectures, it obtains 42.0 mm error on the PA-MPJPE metric of the challenging 3DPW, outperforming state-of-the-art counterparts by a large margin. Code will be publicly available at https://github.com/yangsenius/INT_HMR_Model
Federated contrastive learning models for prostate cancer diagnosis and Gleason grading
Feb 17, 2023



The application effect of artificial intelligence (AI) in the field of medical imaging is remarkable. Robust AI model training requires large datasets, but data collection faces communication, ethics, and privacy protection constraints. Fortunately, federated learning can solve the above problems by coordinating multiple clients to train the model without sharing the original data. In this study, we design a federated contrastive learning framework (FCL) for large-scale pathology images and the heterogeneity challenges. It enhances the model's generalization ability by maximizing the attention consistency between the local client and server models. To alleviate the privacy leakage problem when transferring parameters and verify the robustness of FCL, we use differential privacy to further protect the model by adding noise. We evaluate the effectiveness of FCL on the cancer diagnosis task and Gleason grading task on 19,635 prostate cancer WSIs from multiple clients. In the diagnosis task, the average AUC of 7 clients is 95% when the categories are relatively balanced, and our FCL achieves 97%. In the Gleason grading task, the average Kappa of 6 clients is 0.74, and the Kappa of FCL reaches 0.84. Furthermore, we also validate the robustness of the model on external datasets(one public dataset and two private datasets). In addition, to better explain the classification effect of the model, we show whether the model focuses on the lesion area by drawing a heatmap. Finally, FCL brings a robust, accurate, low-cost AI training model to biomedical research, effectively protecting medical data privacy.
Artificial intelligence for diagnosing and predicting survival of patients with renal cell carcinoma: Retrospective multi-center study
Jan 12, 2023



Background: Clear cell renal cell carcinoma (ccRCC) is the most common renal-related tumor with high heterogeneity. There is still an urgent need for novel diagnostic and prognostic biomarkers for ccRCC. Methods: We proposed a weakly-supervised deep learning strategy using conventional histology of 1752 whole slide images from multiple centers. Our study was demonstrated through internal cross-validation and external validations for the deep learning-based models. Results: Automatic diagnosis for ccRCC through intelligent subtyping of renal cell carcinoma was proved in this study. Our graderisk achieved aera the curve (AUC) of 0.840 (95% confidence interval: 0.805-0.871) in the TCGA cohort, 0.840 (0.805-0.871) in the General cohort, and 0.840 (0.805-0.871) in the CPTAC cohort for the recognition of high-grade tumor. The OSrisk for the prediction of 5-year survival status achieved AUC of 0.784 (0.746-0.819) in the TCGA cohort, which was further verified in the independent General cohort and the CPTAC cohort, with AUC of 0.774 (0.723-0.820) and 0.702 (0.632-0.765), respectively. Cox regression analysis indicated that graderisk, OSrisk, tumor grade, and tumor stage were found to be independent prognostic factors, which were further incorporated into the competing-risk nomogram (CRN). Kaplan-Meier survival analyses further illustrated that our CRN could significantly distinguish patients with high survival risk, with hazard ratio of 5.664 (3.893-8.239, p < 0.0001) in the TCGA cohort, 35.740 (5.889-216.900, p < 0.0001) in the General cohort and 6.107 (1.815 to 20.540, p < 0.0001) in the CPTAC cohort. Comparison analyses conformed that our CRN outperformed current prognosis indicators in the prediction of survival status, with higher concordance index for clinical prognosis.
Hyperbolic Cosine Transformer for LiDAR 3D Object Detection
Nov 10, 2022Recently, Transformer has achieved great success in computer vision. However, it is constrained because the spatial and temporal complexity grows quadratically with the number of large points in 3D object detection applications. Previous point-wise methods are suffering from time consumption and limited receptive fields to capture information among points. In this paper, we propose a two-stage hyperbolic cosine transformer (ChTR3D) for 3D object detection from LiDAR point clouds. The proposed ChTR3D refines proposals by applying cosh-attention in linear computation complexity to encode rich contextual relationships among points. The cosh-attention module reduces the space and time complexity of the attention operation. The traditional softmax operation is replaced by non-negative ReLU activation and hyperbolic-cosine-based operator with re-weighting mechanism. Extensive experiments on the widely used KITTI dataset demonstrate that, compared with vanilla attention, the cosh-attention significantly improves the inference speed with competitive performance. Experiment results show that, among two-stage state-of-the-art methods using point-level features, the proposed ChTR3D is the fastest one.
DeepNoise: Disentanglement of Experimental Noise from Real Biological Signals based on Fluorescent Microscopy Image Classification via Deep Learning
Sep 13, 2022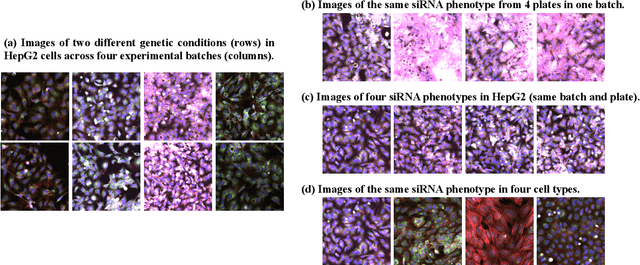
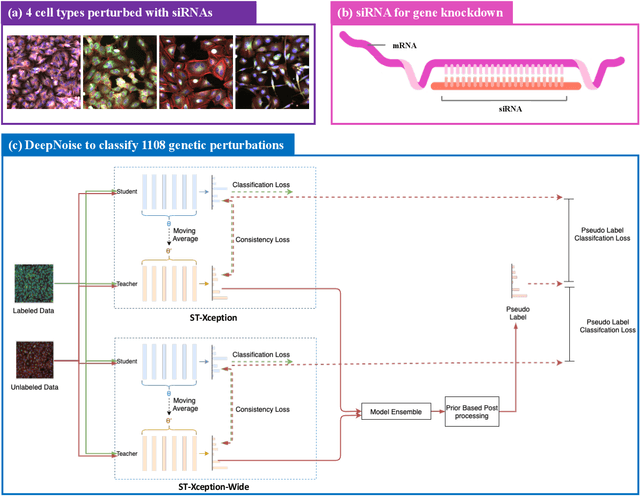
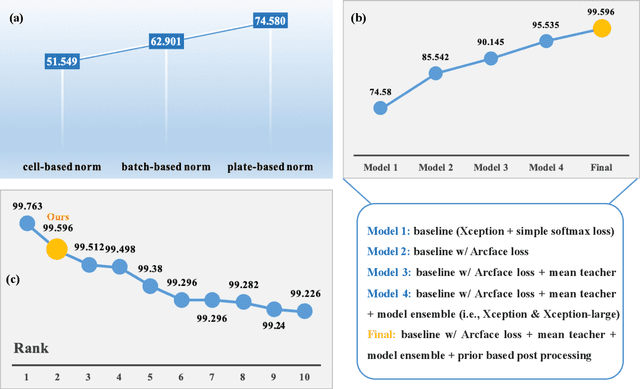
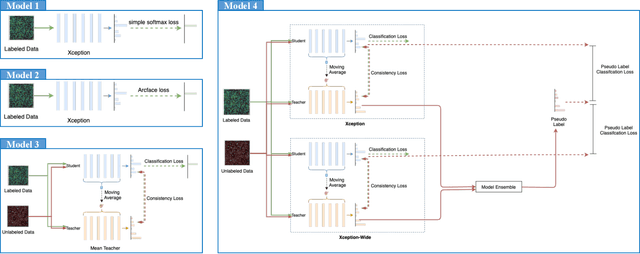
The high-content image-based assay is commonly leveraged for identifying the phenotypic impact of genetic perturbations in biology field. However, a persistent issue remains unsolved during experiments: the interferential technical noise caused by systematic errors (e.g., temperature, reagent concentration, and well location) is always mixed up with the real biological signals, leading to misinterpretation of any conclusion drawn. Here, we show a mean teacher based deep learning model (DeepNoise) that can disentangle biological signals from the experimental noise. Specifically, we aim to classify the phenotypic impact of 1,108 different genetic perturbations screened from 125,510 fluorescent microscopy images, which are totally unrecognizable by human eye. We validate our model by participating in the Recursion Cellular Image Classification Challenge, and our proposed method achieves an extremely high classification score (Acc: 99.596%), ranking the 2nd place among 866 participating groups. This promising result indicates the successful separation of biological and technical factors, which might help decrease the cost of treatment development and expedite the drug discovery process.
Exploring Runtime Decision Support for Trauma Resuscitation
Jul 06, 2022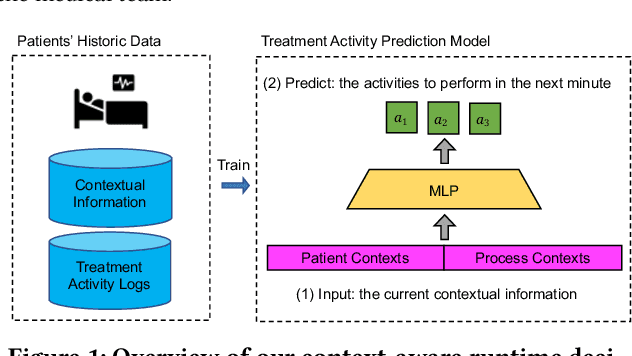
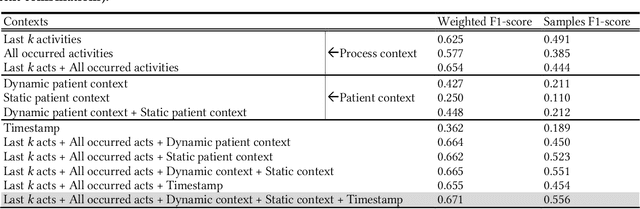
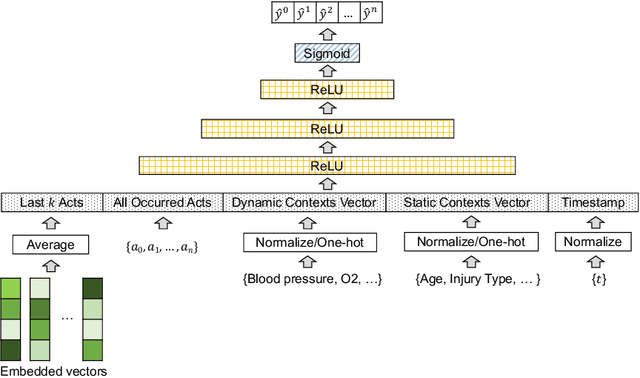
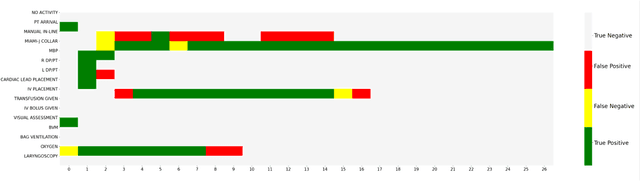
AI-based recommender systems have been successfully applied in many domains (e.g., e-commerce, feeds ranking). Medical experts believe that incorporating such methods into a clinical decision support system may help reduce medical team errors and improve patient outcomes during treatment processes (e.g., trauma resuscitation, surgical processes). Limited research, however, has been done to develop automatic data-driven treatment decision support. We explored the feasibility of building a treatment recommender system to provide runtime next-minute activity predictions. The system uses patient context (e.g., demographics and vital signs) and process context (e.g., activities) to continuously predict activities that will be performed in the next minute. We evaluated our system on a pre-recorded dataset of trauma resuscitation and conducted an ablation study on different model variants. The best model achieved an average F1-score of 0.67 for 61 activity types. We include medical team feedback and discuss the future work.
LPFS: Learnable Polarizing Feature Selection for Click-Through Rate Prediction
Jun 01, 2022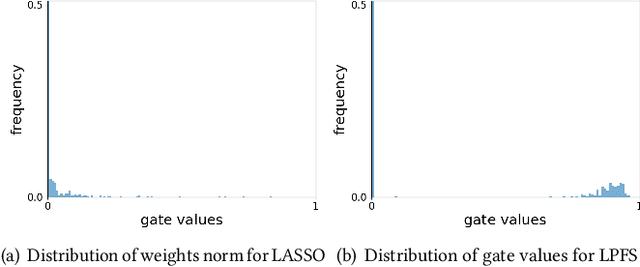
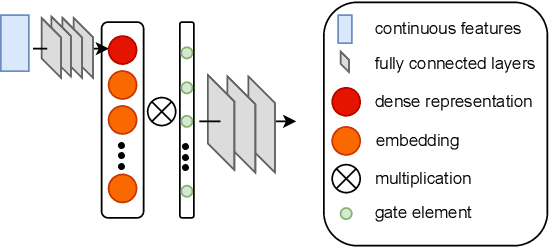

In industry, feature selection is a standard but necessary step to search for an optimal set of informative feature fields for efficient and effective training of deep Click-Through Rate (CTR) models. Most previous works measure the importance of feature fields by using their corresponding continuous weights from the model, then remove the feature fields with small weight values. However, removing many features that correspond to small but not exact zero weights will inevitably hurt model performance and not be friendly to hot-start model training. There is also no theoretical guarantee that the magnitude of weights can represent the importance, thus possibly leading to sub-optimal results if using these methods. To tackle this problem, we propose a novel Learnable Polarizing Feature Selection (LPFS) method using a smoothed-$\ell^0$ function in literature. Furthermore, we extend LPFS to LPFS++ by our newly designed smoothed-$\ell^0$-liked function to select a more informative subset of features. LPFS and LPFS++ can be used as gates inserted at the input of the deep network to control the active and inactive state of each feature. When training is finished, some gates are exact zero, while others are around one, which is particularly favored by the practical hot-start training in the industry, due to no damage to the model performance before and after removing the features corresponding to exact-zero gates. Experiments show that our methods outperform others by a clear margin, and have achieved great A/B test results in KuaiShou Technology.
Nuclear Norm Maximization Based Curiosity-Driven Learning
May 28, 2022
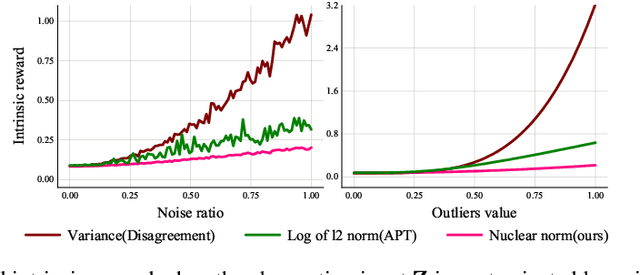
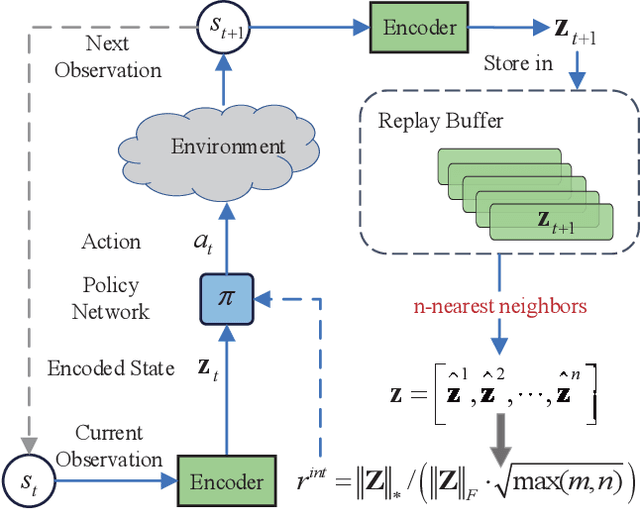
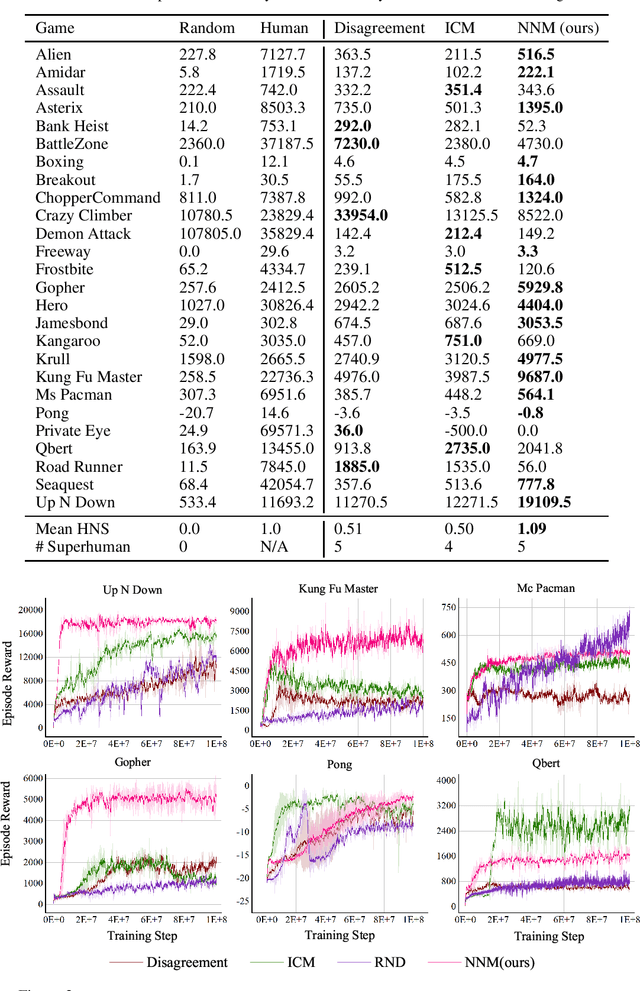
To handle the sparsity of the extrinsic rewards in reinforcement learning, researchers have proposed intrinsic reward which enables the agent to learn the skills that might come in handy for pursuing the rewards in the future, such as encouraging the agent to visit novel states. However, the intrinsic reward can be noisy due to the undesirable environment's stochasticity and directly applying the noisy value predictions to supervise the policy is detrimental to improve the learning performance and efficiency. Moreover, many previous studies employ $\ell^2$ norm or variance to measure the exploration novelty, which will amplify the noise due to the square operation. In this paper, we address aforementioned challenges by proposing a novel curiosity leveraging the nuclear norm maximization (NNM), which can quantify the novelty of exploring the environment more accurately while providing high-tolerance to the noise and outliers. We conduct extensive experiments across a variety of benchmark environments and the results suggest that NNM can provide state-of-the-art performance compared with previous curiosity methods. On 26 Atari games subset, when trained with only intrinsic reward, NNM achieves a human-normalized score of 1.09, which doubles that of competitive intrinsic rewards-based approaches. Our code will be released publicly to enhance the reproducibility.
Pan-cancer computational histopathology reveals tumor mutational burden status through weakly-supervised deep learning
Apr 07, 2022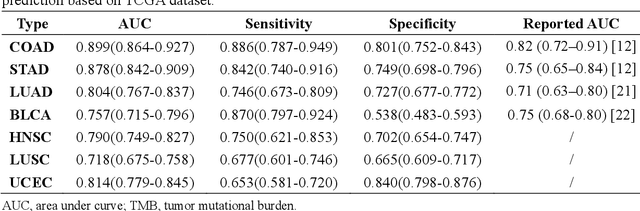
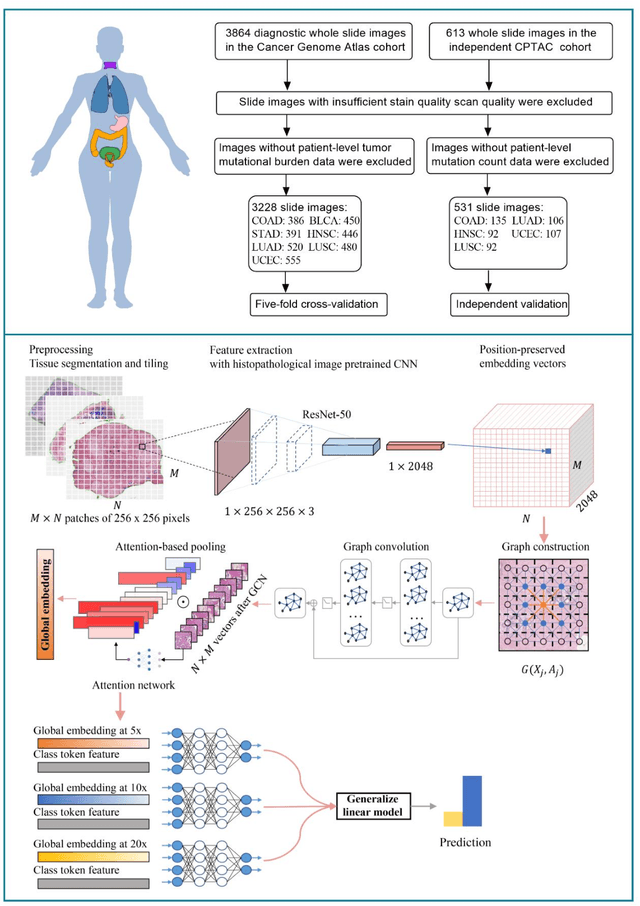
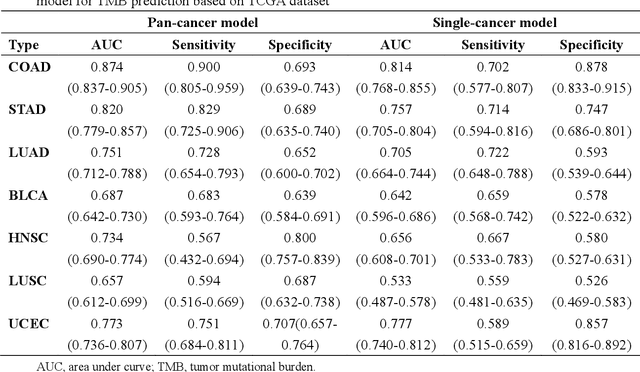
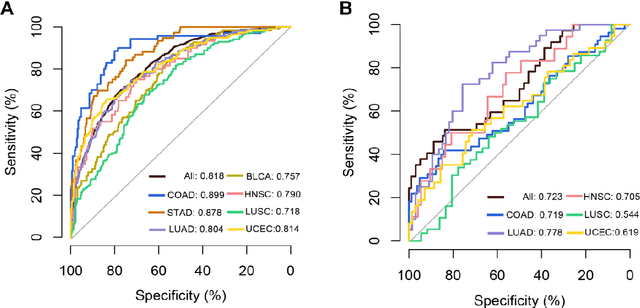
Tumor mutational burden (TMB) is a potential genomic biomarker that can help identify patients who will benefit from immunotherapy across a variety of cancers. We included whole slide images (WSIs) of 3228 diagnostic slides from the Cancer Genome Atlas and 531 WSIs from the Clinical Proteomic Tumor Analysis Consortium for the development and verification of a pan-cancer TMB prediction model (PC-TMB). We proposed a multiscale weakly-supervised deep learning framework for predicting TMB of seven types of tumors based only on routinely used hematoxylin-eosin (H&E)-stained WSIs. PC-TMB achieved a mean area under curve (AUC) of 0.818 (0.804-0.831) in the cross-validation cohort, which was superior to the best single-scale model. In comparison with the state-of-the-art TMB prediction model from previous publications, our multiscale model achieved better performance over previously reported models. In addition, the improvements of PC-TMB over the single-tumor models were also confirmed by the ablation tests on 10x magnification. The PC-TMB algorithm also exhibited good generalization on external validation cohort with AUC of 0.732 (0.683-0.761). PC-TMB possessed a comparable survival-risk stratification performance to the TMB measured by whole exome sequencing, but with low cost and being time-efficient for providing a prognostic biomarker of multiple solid tumors. Moreover, spatial heterogeneity of TMB within tumors was also identified through our PC-TMB, which might enable image-based screening for molecular biomarkers with spatial variation and potential exploring for genotype-spatial heterogeneity relationships.
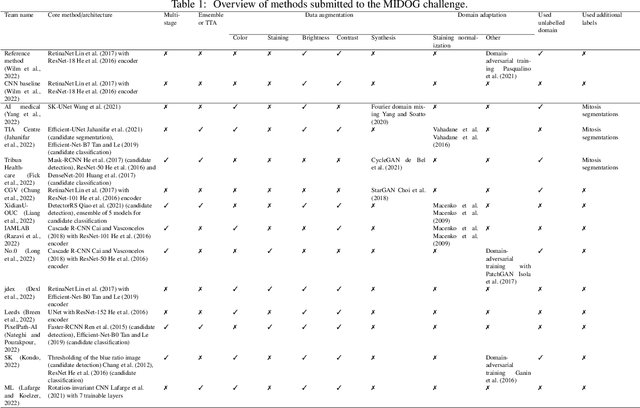
Mitosis domain generalization in histopathology images -- The MIDOG challenge
Apr 06, 2022

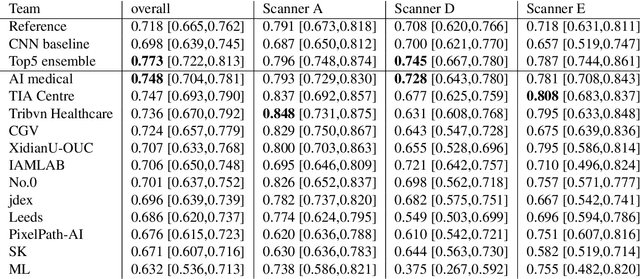
The density of mitotic figures within tumor tissue is known to be highly correlated with tumor proliferation and thus is an important marker in tumor grading. Recognition of mitotic figures by pathologists is known to be subject to a strong inter-rater bias, which limits the prognostic value. State-of-the-art deep learning methods can support the expert in this assessment but are known to strongly deteriorate when applied in a different clinical environment than was used for training. One decisive component in the underlying domain shift has been identified as the variability caused by using different whole slide scanners. The goal of the MICCAI MIDOG 2021 challenge has been to propose and evaluate methods that counter this domain shift and derive scanner-agnostic mitosis detection algorithms. The challenge used a training set of 200 cases, split across four scanning systems. As a test set, an additional 100 cases split across four scanning systems, including two previously unseen scanners, were given. The best approaches performed on an expert level, with the winning algorithm yielding an F_1 score of 0.748 (CI95: 0.704-0.781). In this paper, we evaluate and compare the approaches that were submitted to the challenge and identify methodological factors contributing to better performance.