 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeParameter-Efficient Fine-Tuning in Large Models: A Survey of Methodologies
Oct 24, 2024



The large models, as predicted by scaling raw forecasts, have made groundbreaking progress in many fields, particularly in natural language generation tasks, where they have approached or even surpassed human levels. However, the unprecedented scale of their parameters brings significant computational and storage costs. These large models require substantial computational resources and GPU memory to operate. When adapting large models to specific downstream tasks, their massive parameter scale poses a significant challenge in fine-tuning on hardware platforms with limited computational power and GPU memory. To address this issue, Parameter-Efficient Fine-Tuning (PEFT) offers a practical solution by efficiently adjusting the parameters of large pre-trained models to suit various downstream tasks. Specifically, PEFT adjusts the parameters of pre-trained large models to adapt to specific tasks or domains, minimizing the introduction of additional parameters and the computational resources required. This review mainly introduces the preliminary knowledge of PEFT, the core ideas and principles of various PEFT algorithms, the applications of PEFT, and potential future research directions. By reading this review, we believe that interested parties can quickly grasp the PEFT methodology, thereby accelerating its development and innovation.
LoGU: Long-form Generation with Uncertainty Expressions
Oct 18, 2024



While Large Language Models (LLMs) demonstrate impressive capabilities, they still struggle with generating factually incorrect content (i.e., hallucinations). A promising approach to mitigate this issue is enabling models to express uncertainty when unsure. Previous research on uncertainty modeling has primarily focused on short-form QA, but realworld applications often require much longer responses. In this work, we introduce the task of Long-form Generation with Uncertainty(LoGU). We identify two key challenges: Uncertainty Suppression, where models hesitate to express uncertainty, and Uncertainty Misalignment, where models convey uncertainty inaccurately. To tackle these challenges, we propose a refinement-based data collection framework and a two-stage training pipeline. Our framework adopts a divide-and-conquer strategy, refining uncertainty based on atomic claims. The collected data are then used in training through supervised fine-tuning (SFT) and direct preference optimization (DPO) to enhance uncertainty expression. Extensive experiments on three long-form instruction following datasets show that our method significantly improves accuracy, reduces hallucinations, and maintains the comprehensiveness of responses.
Atomic Calibration of LLMs in Long-Form Generations
Oct 17, 2024



Large language models (LLMs) often suffer from hallucinations, posing significant challenges for real-world applications. Confidence calibration, which estimates the underlying uncertainty of model predictions, is essential to enhance the LLMs' trustworthiness. Existing research on LLM calibration has primarily focused on short-form tasks, providing a single confidence score at the response level (macro calibration). However, this approach is insufficient for long-form generations, where responses often contain more complex statements and may include both accurate and inaccurate information. Therefore, we introduce atomic calibration, a novel approach that evaluates factuality calibration at a fine-grained level by breaking down long responses into atomic claims. We classify confidence elicitation methods into discriminative and generative types and demonstrate that their combination can enhance calibration. Our extensive experiments on various LLMs and datasets show that atomic calibration is well-suited for long-form generation and can also improve macro calibration results. Additionally, atomic calibration reveals insightful patterns in LLM confidence throughout the generation process.
ChatHouseDiffusion: Prompt-Guided Generation and Editing of Floor Plans
Oct 15, 2024



The generation and editing of floor plans are critical in architectural planning, requiring a high degree of flexibility and efficiency. Existing methods demand extensive input information and lack the capability for interactive adaptation to user modifications. This paper introduces ChatHouseDiffusion, which leverages large language models (LLMs) to interpret natural language input, employs graphormer to encode topological relationships, and uses diffusion models to flexibly generate and edit floor plans. This approach allows iterative design adjustments based on user ideas, significantly enhancing design efficiency. Compared to existing models, ChatHouseDiffusion achieves higher Intersection over Union (IoU) scores, permitting precise, localized adjustments without the need for complete redesigns, thus offering greater practicality. Experiments demonstrate that our model not only strictly adheres to user specifications but also facilitates a more intuitive design process through its interactive capabilities.
MGMapNet: Multi-Granularity Representation Learning for End-to-End Vectorized HD Map Construction
Oct 10, 2024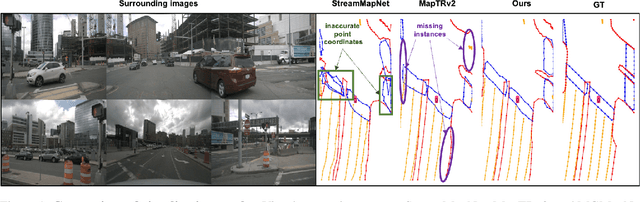
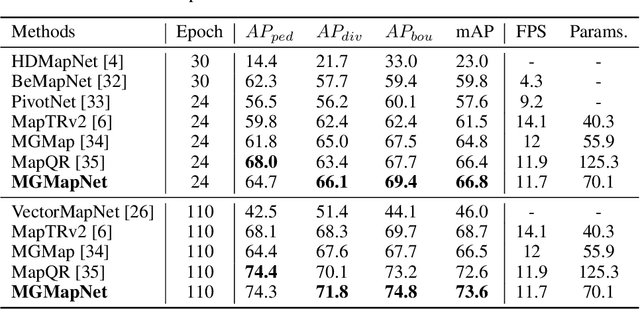
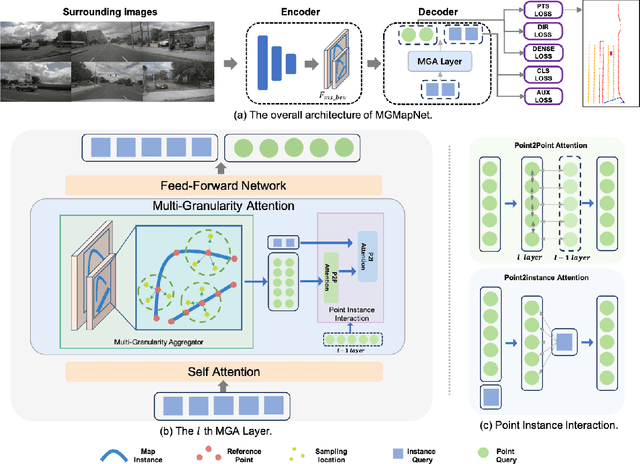

The construction of Vectorized High-Definition (HD) map typically requires capturing both category and geometry information of map elements. Current state-of-the-art methods often adopt solely either point-level or instance-level representation, overlooking the strong intrinsic relationships between points and instances. In this work, we propose a simple yet efficient framework named MGMapNet (Multi-Granularity Map Network) to model map element with a multi-granularity representation, integrating both coarse-grained instance-level and fine-grained point-level queries. Specifically, these two granularities of queries are generated from the multi-scale bird's eye view (BEV) features using a proposed Multi-Granularity Aggregator. In this module, instance-level query aggregates features over the entire scope covered by an instance, and the point-level query aggregates features locally. Furthermore, a Point Instance Interaction module is designed to encourage information exchange between instance-level and point-level queries. Experimental results demonstrate that the proposed MGMapNet achieves state-of-the-art performance, surpassing MapTRv2 by 5.3 mAP on nuScenes and 4.4 mAP on Argoverse2 respectively.
Not All Preference Pairs Are Created Equal: A Recipe for Annotation-Efficient Iterative Preference Learning
Jun 25, 2024



Iterative preference learning, though yielding superior performances, requires online annotated preference labels. In this work, we study strategies to select worth-annotating response pairs for cost-efficient annotation while achieving competitive or even better performances compared with the random selection baseline for iterative preference learning. Built on assumptions regarding uncertainty and distribution shifts, we propose a comparative view to rank the implicit reward margins as predicted by DPO to select the response pairs that yield more benefits. Through extensive experiments, we show that annotating those response pairs with small margins is generally better than large or random, under both single- and multi-iteration scenarios. Besides, our empirical results suggest allocating more annotation budgets in the earlier iterations rather than later across multiple iterations.
CMTNet: Convolutional Meets Transformer Network for Hyperspectral Images Classification
Jun 20, 2024Hyperspectral remote sensing (HIS) enables the detailed capture of spectral information from the Earth's surface, facilitating precise classification and identification of surface crops due to its superior spectral diagnostic capabilities. However, current convolutional neural networks (CNNs) focus on local features in hyperspectral data, leading to suboptimal performance when classifying intricate crop types and addressing imbalanced sample distributions. In contrast, the Transformer framework excels at extracting global features from hyperspectral imagery. To leverage the strengths of both approaches, this research introduces the Convolutional Meet Transformer Network (CMTNet). This innovative model includes a spectral-spatial feature extraction module for shallow feature capture, a dual-branch structure combining CNN and Transformer branches for local and global feature extraction, and a multi-output constraint module that enhances classification accuracy through multi-output loss calculations and cross constraints across local, international, and joint features. Extensive experiments conducted on three datasets (WHU-Hi-LongKou, WHU-Hi-HanChuan, and WHU-Hi-HongHu) demonstrate that CTDBNet significantly outperforms other state-of-the-art networks in classification performance, validating its effectiveness in hyperspectral crop classification.
MaskMatch: Boosting Semi-Supervised Learning Through Mask Autoencoder-Driven Feature Learning
May 10, 2024



Conventional methods in semi-supervised learning (SSL) often face challenges related to limited data utilization, mainly due to their reliance on threshold-based techniques for selecting high-confidence unlabeled data during training. Various efforts (e.g., FreeMatch) have been made to enhance data utilization by tweaking the thresholds, yet none have managed to use 100% of the available data. To overcome this limitation and improve SSL performance, we introduce \algo, a novel algorithm that fully utilizes unlabeled data to boost semi-supervised learning. \algo integrates a self-supervised learning strategy, i.e., Masked Autoencoder (MAE), that uses all available data to enforce the visual representation learning. This enables the SSL algorithm to leverage all available data, including samples typically filtered out by traditional methods. In addition, we propose a synthetic data training approach to further increase data utilization and improve generalization. These innovations lead \algo to achieve state-of-the-art results on challenging datasets. For instance, on CIFAR-100 with 2 labels per class, STL-10 with 4 labels per class, and Euro-SAT with 2 labels per class, \algo achieves low error rates of 18.71%, 9.47%, and 3.07%, respectively. The code will be made publicly available.
2L3: Lifting Imperfect Generated 2D Images into Accurate 3D
Jan 29, 2024Reconstructing 3D objects from a single image is an intriguing but challenging problem. One promising solution is to utilize multi-view (MV) 3D reconstruction to fuse generated MV images into consistent 3D objects. However, the generated images usually suffer from inconsistent lighting, misaligned geometry, and sparse views, leading to poor reconstruction quality. To cope with these problems, we present a novel 3D reconstruction framework that leverages intrinsic decomposition guidance, transient-mono prior guidance, and view augmentation to cope with the three issues, respectively. Specifically, we first leverage to decouple the shading information from the generated images to reduce the impact of inconsistent lighting; then, we introduce mono prior with view-dependent transient encoding to enhance the reconstructed normal; and finally, we design a view augmentation fusion strategy that minimizes pixel-level loss in generated sparse views and semantic loss in augmented random views, resulting in view-consistent geometry and detailed textures. Our approach, therefore, enables the integration of a pre-trained MV image generator and a neural network-based volumetric signed distance function (SDF) representation for a single image to 3D object reconstruction. We evaluate our framework on various datasets and demonstrate its superior performance in both quantitative and qualitative assessments, signifying a significant advancement in 3D object reconstruction. Compared with the latest state-of-the-art method Syncdreamer~\cite{liu2023syncdreamer}, we reduce the Chamfer Distance error by about 36\% and improve PSNR by about 30\% .
Multi-Candidate Speculative Decoding
Jan 12, 2024



Large language models have shown impressive capabilities across a variety of NLP tasks, yet their generating text autoregressively is time-consuming. One way to speed them up is speculative decoding, which generates candidate segments (a sequence of tokens) from a fast draft model that is then verified in parallel by the target model. However, the acceptance rate of candidate tokens receives limitations from several factors, such as the model, the dataset, and the decoding setup. This paper proposes sampling multiple candidates from a draft model and then organising them in batches for verification. We design algorithms for efficient multi-candidate verification while maintaining the distribution of the target model. Our approach shows significant improvements in acceptance rates on multiple datasets and models, consistently outperforming standard speculative decoding.