 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimizing the Placement of Roadside LiDARs for Autonomous Driving
Oct 11, 2023



Multi-agent cooperative perception is an increasingly popular topic in the field of autonomous driving, where roadside LiDARs play an essential role. However, how to optimize the placement of roadside LiDARs is a crucial but often overlooked problem. This paper proposes an approach to optimize the placement of roadside LiDARs by selecting optimized positions within the scene for better perception performance. To efficiently obtain the best combination of locations, a greedy algorithm based on perceptual gain is proposed, which selects the location that can maximize the perceptual gain sequentially. We define perceptual gain as the increased perceptual capability when a new LiDAR is placed. To obtain the perception capability, we propose a perception predictor that learns to evaluate LiDAR placement using only a single point cloud frame. A dataset named Roadside-Opt is created using the CARLA simulator to facilitate research on the roadside LiDAR placement problem.
Towards Vehicle-to-everything Autonomous Driving: A Survey on Collaborative Perception
Aug 31, 2023



Vehicle-to-everything (V2X) autonomous driving opens up a promising direction for developing a new generation of intelligent transportation systems. Collaborative perception (CP) as an essential component to achieve V2X can overcome the inherent limitations of individual perception, including occlusion and long-range perception. In this survey, we provide a comprehensive review of CP methods for V2X scenarios, bringing a profound and in-depth understanding to the community. Specifically, we first introduce the architecture and workflow of typical V2X systems, which affords a broader perspective to understand the entire V2X system and the role of CP within it. Then, we thoroughly summarize and analyze existing V2X perception datasets and CP methods. Particularly, we introduce numerous CP methods from various crucial perspectives, including collaboration stages, roadside sensors placement, latency compensation, performance-bandwidth trade-off, attack/defense, pose alignment, etc. Moreover, we conduct extensive experimental analyses to compare and examine current CP methods, revealing some essential and unexplored insights. Specifically, we analyze the performance changes of different methods under different bandwidths, providing a deep insight into the performance-bandwidth trade-off issue. Also, we examine methods under different LiDAR ranges. To study the model robustness, we further investigate the effects of various simulated real-world noises on the performance of different CP methods, covering communication latency, lossy communication, localization errors, and mixed noises. In addition, we look into the sim-to-real generalization ability of existing CP methods. At last, we thoroughly discuss issues and challenges, highlighting promising directions for future efforts. Our codes for experimental analysis will be public at https://github.com/memberRE/Collaborative-Perception.
Domain Adaptation based Enhanced Detection for Autonomous Driving in Foggy and Rainy Weather
Jul 20, 2023Typically, object detection methods for autonomous driving that rely on supervised learning make the assumption of a consistent feature distribution between the training and testing data, however such assumption may fail in different weather conditions. Due to the domain gap, a detection model trained under clear weather may not perform well in foggy and rainy conditions. Overcoming detection bottlenecks in foggy and rainy weather is a real challenge for autonomous vehicles deployed in the wild. To bridge the domain gap and improve the performance of object detectionin foggy and rainy weather, this paper presents a novel framework for domain-adaptive object detection. The adaptations at both the image-level and object-level are intended to minimize the differences in image style and object appearance between domains. Furthermore, in order to improve the model's performance on challenging examples, we introduce a novel adversarial gradient reversal layer that conducts adversarial mining on difficult instances in addition to domain adaptation. Additionally, we suggest generating an auxiliary domain through data augmentation to enforce a new domain-level metric regularization. Experimental findings on public V2V benchmark exhibit a substantial enhancement in object detection specifically for foggy and rainy driving scenarios.
S2R-ViT for Multi-Agent Cooperative Perception: Bridging the Gap from Simulation to Reality
Jul 18, 2023



Due to the lack of real multi-agent data and time-consuming of labeling, existing multi-agent cooperative perception algorithms usually select the simulated sensor data for training and validating. However, the perception performance is degraded when these simulation-trained models are deployed to the real world, due to the significant domain gap between the simulated and real data. In this paper, we propose the first Simulation-to-Reality transfer learning framework for multi-agent cooperative perception using a novel Vision Transformer, named as S2R-ViT, which considers both the Implementation Gap and Feature Gap between simulated and real data. We investigate the effects of these two types of domain gaps and propose a novel uncertainty-aware vision transformer to effectively relief the Implementation Gap and an agent-based feature adaptation module with inter-agent and ego-agent discriminators to reduce the Feature Gap. Our intensive experiments on the public multi-agent cooperative perception datasets OPV2V and V2V4Real demonstrate that the proposed S2R-ViT can effectively bridge the gap from simulation to reality and outperform other methods significantly for point cloud-based 3D object detection.
HM-ViT: Hetero-modal Vehicle-to-Vehicle Cooperative perception with vision transformer
Apr 20, 2023Vehicle-to-Vehicle technologies have enabled autonomous vehicles to share information to see through occlusions, greatly enhancing perception performance. Nevertheless, existing works all focused on homogeneous traffic where vehicles are equipped with the same type of sensors, which significantly hampers the scale of collaboration and benefit of cross-modality interactions. In this paper, we investigate the multi-agent hetero-modal cooperative perception problem where agents may have distinct sensor modalities. We present HM-ViT, the first unified multi-agent hetero-modal cooperative perception framework that can collaboratively predict 3D objects for highly dynamic vehicle-to-vehicle (V2V) collaborations with varying numbers and types of agents. To effectively fuse features from multi-view images and LiDAR point clouds, we design a novel heterogeneous 3D graph transformer to jointly reason inter-agent and intra-agent interactions. The extensive experiments on the V2V perception dataset OPV2V demonstrate that the HM-ViT outperforms SOTA cooperative perception methods for V2V hetero-modal cooperative perception. We will release codes to facilitate future research.
FedBEVT: Federated Learning Bird's Eye View Perception Transformer in Road Traffic Systems
Apr 04, 2023



Bird's eye view (BEV) perception is becoming increasingly important in the field of autonomous driving. It uses multi-view camera data to learn a transformer model that directly projects the perception of the road environment onto the BEV perspective. However, training a transformer model often requires a large amount of data, and as camera data for road traffic is often private, it is typically not shared. Federated learning offers a solution that enables clients to collaborate and train models without exchanging data. In this paper, we propose FedBEVT, a federated transformer learning approach for BEV perception. We address two common data heterogeneity issues in FedBEVT: (i) diverse sensor poses and (ii) varying sensor numbers in perception systems. We present federated learning with camera-attentive personalization~(FedCaP) and adaptive multi-camera masking~(AMCM) to enhance the performance in real-world scenarios. To evaluate our method in real-world settings, we create a dataset consisting of four typical federated use cases. Our findings suggest that FedBEVT outperforms the baseline approaches in all four use cases, demonstrating the potential of our approach for improving BEV perception in autonomous driving. We will make all codes and data publicly available.
Collaboration Helps Camera Overtake LiDAR in 3D Detection
Mar 23, 2023



Camera-only 3D detection provides an economical solution with a simple configuration for localizing objects in 3D space compared to LiDAR-based detection systems. However, a major challenge lies in precise depth estimation due to the lack of direct 3D measurements in the input. Many previous methods attempt to improve depth estimation through network designs, e.g., deformable layers and larger receptive fields. This work proposes an orthogonal direction, improving the camera-only 3D detection by introducing multi-agent collaborations. Our proposed collaborative camera-only 3D detection (CoCa3D) enables agents to share complementary information with each other through communication. Meanwhile, we optimize communication efficiency by selecting the most informative cues. The shared messages from multiple viewpoints disambiguate the single-agent estimated depth and complement the occluded and long-range regions in the single-agent view. We evaluate CoCa3D in one real-world dataset and two new simulation datasets. Results show that CoCa3D improves previous SOTA performances by 44.21% on DAIR-V2X, 30.60% on OPV2V+, 12.59% on CoPerception-UAVs+ for AP@70. Our preliminary results show a potential that with sufficient collaboration, the camera might overtake LiDAR in some practical scenarios. We released the dataset and code at https://siheng-chen.github.io/dataset/CoPerception+ and https://github.com/MediaBrain-SJTU/CoCa3D.
V2V4Real: A Real-world Large-scale Dataset for Vehicle-to-Vehicle Cooperative Perception
Mar 19, 2023



Modern perception systems of autonomous vehicles are known to be sensitive to occlusions and lack the capability of long perceiving range. It has been one of the key bottlenecks that prevents Level 5 autonomy. Recent research has demonstrated that the Vehicle-to-Vehicle (V2V) cooperative perception system has great potential to revolutionize the autonomous driving industry. However, the lack of a real-world dataset hinders the progress of this field. To facilitate the development of cooperative perception, we present V2V4Real, the first large-scale real-world multi-modal dataset for V2V perception. The data is collected by two vehicles equipped with multi-modal sensors driving together through diverse scenarios. Our V2V4Real dataset covers a driving area of 410 km, comprising 20K LiDAR frames, 40K RGB frames, 240K annotated 3D bounding boxes for 5 classes, and HDMaps that cover all the driving routes. V2V4Real introduces three perception tasks, including cooperative 3D object detection, cooperative 3D object tracking, and Sim2Real domain adaptation for cooperative perception. We provide comprehensive benchmarks of recent cooperative perception algorithms on three tasks. The V2V4Real dataset can be found at https://research.seas.ucla.edu/mobility-lab/v2v4real/.
The OpenCDA Open-source Ecosystem for Cooperative Driving Automation Research
Jan 26, 2023



Advances in Single-vehicle intelligence of automated driving have encountered significant challenges because of limited capabilities in perception and interaction with complex traffic environments. Cooperative Driving Automation~(CDA) has been considered a pivotal solution to next-generation automated driving and intelligent transportation. Though CDA has attracted much attention from both academia and industry, exploration of its potential is still in its infancy. In industry, companies tend to build their in-house data collection pipeline and research tools to tailor their needs and protect intellectual properties. Reinventing the wheels, however, wastes resources and limits the generalizability of the developed approaches since no standardized benchmarks exist. On the other hand, in academia, due to the absence of real-world traffic data and computation resources, researchers often investigate CDA topics in simplified and mostly simulated environments, restricting the possibility of scaling the research outputs to real-world scenarios. Therefore, there is an urgent need to establish an open-source ecosystem~(OSE) to address the demands of different communities for CDA research, particularly in the early exploratory research stages, and provide the bridge to ensure an integrated development and testing pipeline that diverse communities can share. In this paper, we introduce the OpenCDA research ecosystem, a unified OSE integrated with a model zoo, a suite of driving simulators at various resolutions, large-scale real-world and simulated datasets, complete development toolkits for benchmark training/testing, and a scenario database/generator. We also demonstrate the effectiveness of OpenCDA OSE through example use cases, including cooperative 3D LiDAR detection, cooperative merge, cooperative camera-based map prediction, and adversarial scenario generation.
Street-View Image Generation from a Bird's-Eye View Layout
Jan 16, 2023

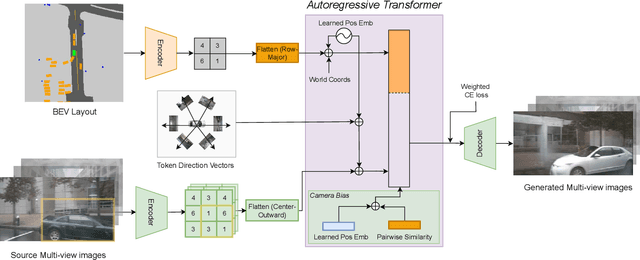

Bird's-Eye View (BEV) Perception has received increasing attention in recent years as it provides a concise and unified spatial representation across views and benefits a diverse set of downstream driving applications. While the focus has been placed on discriminative tasks such as BEV segmentation, the dual generative task of creating street-view images from a BEV layout has rarely been explored. The ability to generate realistic street-view images that align with a given HD map and traffic layout is critical for visualizing complex traffic scenarios and developing robust perception models for autonomous driving. In this paper, we propose BEVGen, a conditional generative model that synthesizes a set of realistic and spatially consistent surrounding images that match the BEV layout of a traffic scenario. BEVGen incorporates a novel cross-view transformation and spatial attention design which learn the relationship between cameras and map views to ensure their consistency. Our model can accurately render road and lane lines, as well as generate traffic scenes under different weather conditions and times of day. The code will be made publicly available.