 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSongComposer: A Large Language Model for Lyric and Melody Composition in Song Generation
Feb 27, 2024



We present SongComposer, an innovative LLM designed for song composition. It could understand and generate melodies and lyrics in symbolic song representations, by leveraging the capability of LLM. Existing music-related LLM treated the music as quantized audio signals, while such implicit encoding leads to inefficient encoding and poor flexibility. In contrast, we resort to symbolic song representation, the mature and efficient way humans designed for music, and enable LLM to explicitly compose songs like humans. In practice, we design a novel tuple design to format lyric and three note attributes (pitch, duration, and rest duration) in the melody, which guarantees the correct LLM understanding of musical symbols and realizes precise alignment between lyrics and melody. To impart basic music understanding to LLM, we carefully collected SongCompose-PT, a large-scale song pretraining dataset that includes lyrics, melodies, and paired lyrics-melodies in either Chinese or English. After adequate pre-training, 10K carefully crafted QA pairs are used to empower the LLM with the instruction-following capability and solve diverse tasks. With extensive experiments, SongComposer demonstrates superior performance in lyric-to-melody generation, melody-to-lyric generation, song continuation, and text-to-song creation, outperforming advanced LLMs like GPT-4.
VideoPrism: A Foundational Visual Encoder for Video Understanding
Feb 20, 2024



We introduce VideoPrism, a general-purpose video encoder that tackles diverse video understanding tasks with a single frozen model. We pretrain VideoPrism on a heterogeneous corpus containing 36M high-quality video-caption pairs and 582M video clips with noisy parallel text (e.g., ASR transcripts). The pretraining approach improves upon masked autoencoding by global-local distillation of semantic video embeddings and a token shuffling scheme, enabling VideoPrism to focus primarily on the video modality while leveraging the invaluable text associated with videos. We extensively test VideoPrism on four broad groups of video understanding tasks, from web video question answering to CV for science, achieving state-of-the-art performance on 30 out of 33 video understanding benchmarks.
Betrayed by Attention: A Simple yet Effective Approach for Self-supervised Video Object Segmentation
Nov 29, 2023



In this paper, we propose a simple yet effective approach for self-supervised video object segmentation (VOS). Our key insight is that the inherent structural dependencies present in DINO-pretrained Transformers can be leveraged to establish robust spatio-temporal correspondences in videos. Furthermore, simple clustering on this correspondence cue is sufficient to yield competitive segmentation results. Previous self-supervised VOS techniques majorly resort to auxiliary modalities or utilize iterative slot attention to assist in object discovery, which restricts their general applicability and imposes higher computational requirements. To deal with these challenges, we develop a simplified architecture that capitalizes on the emerging objectness from DINO-pretrained Transformers, bypassing the need for additional modalities or slot attention. Specifically, we first introduce a single spatio-temporal Transformer block to process the frame-wise DINO features and establish spatio-temporal dependencies in the form of self-attention. Subsequently, utilizing these attention maps, we implement hierarchical clustering to generate object segmentation masks. To train the spatio-temporal block in a fully self-supervised manner, we employ semantic and dynamic motion consistency coupled with entropy normalization. Our method demonstrates state-of-the-art performance across multiple unsupervised VOS benchmarks and particularly excels in complex real-world multi-object video segmentation tasks such as DAVIS-17-Unsupervised and YouTube-VIS-19. The code and model checkpoints will be released at https://github.com/shvdiwnkozbw/SSL-UVOS.
Semantics Meets Temporal Correspondence: Self-supervised Object-centric Learning in Videos
Aug 19, 2023Self-supervised methods have shown remarkable progress in learning high-level semantics and low-level temporal correspondence. Building on these results, we take one step further and explore the possibility of integrating these two features to enhance object-centric representations. Our preliminary experiments indicate that query slot attention can extract different semantic components from the RGB feature map, while random sampling based slot attention can exploit temporal correspondence cues between frames to assist instance identification. Motivated by this, we propose a novel semantic-aware masked slot attention on top of the fused semantic features and correspondence maps. It comprises two slot attention stages with a set of shared learnable Gaussian distributions. In the first stage, we use the mean vectors as slot initialization to decompose potential semantics and generate semantic segmentation masks through iterative attention. In the second stage, for each semantics, we randomly sample slots from the corresponding Gaussian distribution and perform masked feature aggregation within the semantic area to exploit temporal correspondence patterns for instance identification. We adopt semantic- and instance-level temporal consistency as self-supervision to encourage temporally coherent object-centric representations. Our model effectively identifies multiple object instances with semantic structure, reaching promising results on unsupervised video object discovery. Furthermore, we achieve state-of-the-art performance on dense label propagation tasks, demonstrating the potential for object-centric analysis. The code is released at https://github.com/shvdiwnkozbw/SMTC.
Prune Spatio-temporal Tokens by Semantic-aware Temporal Accumulation
Aug 08, 2023Transformers have become the primary backbone of the computer vision community due to their impressive performance. However, the unfriendly computation cost impedes their potential in the video recognition domain. To optimize the speed-accuracy trade-off, we propose Semantic-aware Temporal Accumulation score (STA) to prune spatio-temporal tokens integrally. STA score considers two critical factors: temporal redundancy and semantic importance. The former depicts a specific region based on whether it is a new occurrence or a seen entity by aggregating token-to-token similarity in consecutive frames while the latter evaluates each token based on its contribution to the overall prediction. As a result, tokens with higher scores of STA carry more temporal redundancy as well as lower semantics thus being pruned. Based on the STA score, we are able to progressively prune the tokens without introducing any additional parameters or requiring further re-training. We directly apply the STA module to off-the-shelf ViT and VideoSwin backbones, and the empirical results on Kinetics-400 and Something-Something V2 achieve over 30% computation reduction with a negligible ~0.2% accuracy drop. The code is released at https://github.com/Mark12Ding/STA.
Taming Diffusion Models for Audio-Driven Co-Speech Gesture Generation
Mar 18, 2023Animating virtual avatars to make co-speech gestures facilitates various applications in human-machine interaction. The existing methods mainly rely on generative adversarial networks (GANs), which typically suffer from notorious mode collapse and unstable training, thus making it difficult to learn accurate audio-gesture joint distributions. In this work, we propose a novel diffusion-based framework, named Diffusion Co-Speech Gesture (DiffGesture), to effectively capture the cross-modal audio-to-gesture associations and preserve temporal coherence for high-fidelity audio-driven co-speech gesture generation. Specifically, we first establish the diffusion-conditional generation process on clips of skeleton sequences and audio to enable the whole framework. Then, a novel Diffusion Audio-Gesture Transformer is devised to better attend to the information from multiple modalities and model the long-term temporal dependency. Moreover, to eliminate temporal inconsistency, we propose an effective Diffusion Gesture Stabilizer with an annealed noise sampling strategy. Benefiting from the architectural advantages of diffusion models, we further incorporate implicit classifier-free guidance to trade off between diversity and gesture quality. Extensive experiments demonstrate that DiffGesture achieves state-of-theart performance, which renders coherent gestures with better mode coverage and stronger audio correlations. Code is available at https://github.com/Advocate99/DiffGesture.
Motion-inductive Self-supervised Object Discovery in Videos
Oct 01, 2022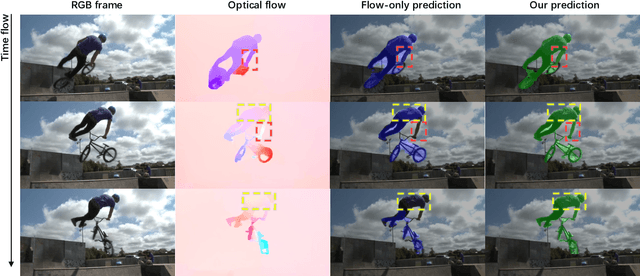
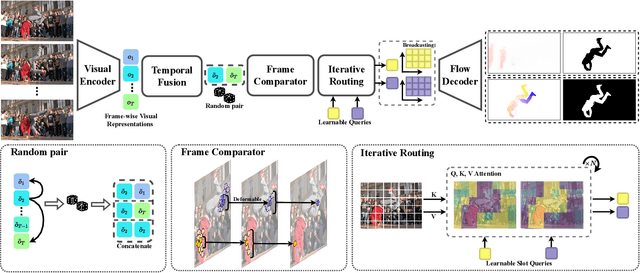
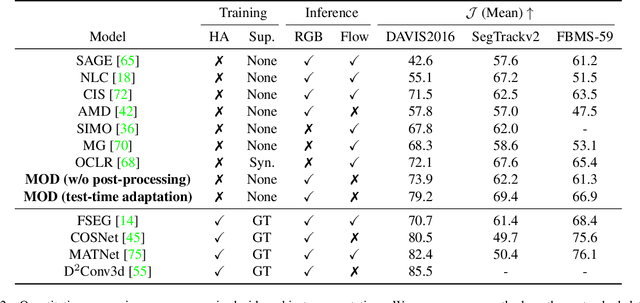
In this paper, we consider the task of unsupervised object discovery in videos. Previous works have shown promising results via processing optical flows to segment objects. However, taking flow as input brings about two drawbacks. First, flow cannot capture sufficient cues when objects remain static or partially occluded. Second, it is challenging to establish temporal coherency from flow-only input, due to the missing texture information. To tackle these limitations, we propose a model for directly processing consecutive RGB frames, and infer the optical flow between any pair of frames using a layered representation, with the opacity channels being treated as the segmentation. Additionally, to enforce object permanence, we apply temporal consistency loss on the inferred masks from randomly-paired frames, which refer to the motions at different paces, and encourage the model to segment the objects even if they may not move at the current time point. Experimentally, we demonstrate superior performance over previous state-of-the-art methods on three public video segmentation datasets (DAVIS2016, SegTrackv2, and FBMS-59), while being computationally efficient by avoiding the overhead of computing optical flow as input.
Static and Dynamic Concepts for Self-supervised Video Representation Learning
Jul 26, 2022
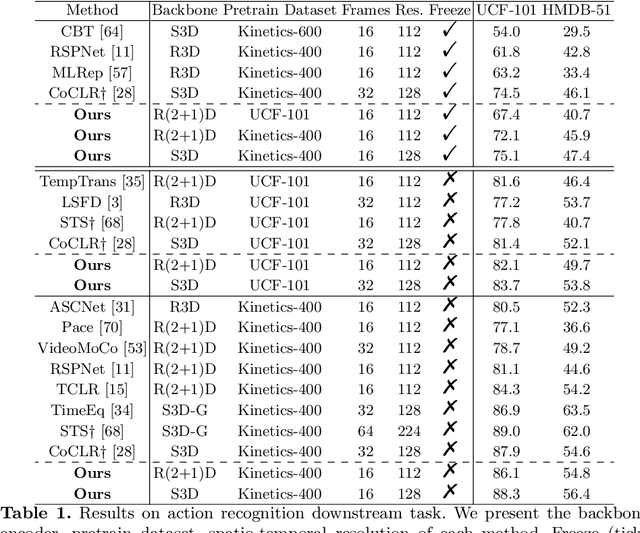
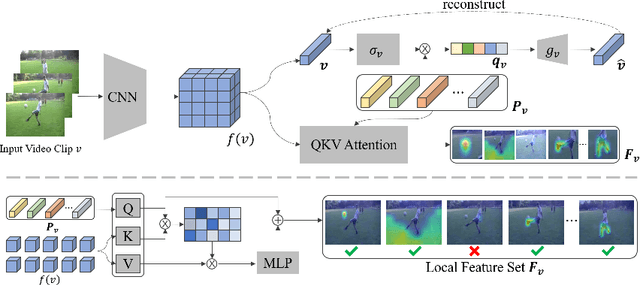
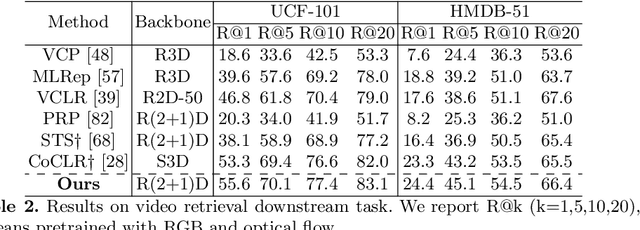
In this paper, we propose a novel learning scheme for self-supervised video representation learning. Motivated by how humans understand videos, we propose to first learn general visual concepts then attend to discriminative local areas for video understanding. Specifically, we utilize static frame and frame difference to help decouple static and dynamic concepts, and respectively align the concept distributions in latent space. We add diversity and fidelity regularizations to guarantee that we learn a compact set of meaningful concepts. Then we employ a cross-attention mechanism to aggregate detailed local features of different concepts, and filter out redundant concepts with low activations to perform local concept contrast. Extensive experiments demonstrate that our method distills meaningful static and dynamic concepts to guide video understanding, and obtains state-of-the-art results on UCF-101, HMDB-51, and Diving-48.
Exploring Fine-Grained Audiovisual Categorization with the SSW60 Dataset
Jul 21, 2022
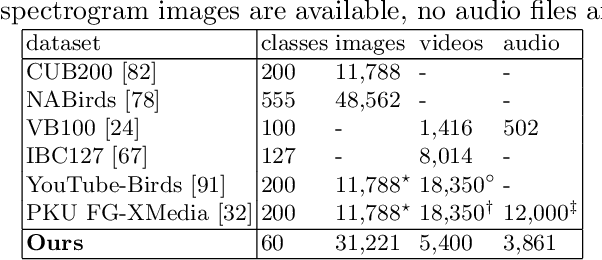
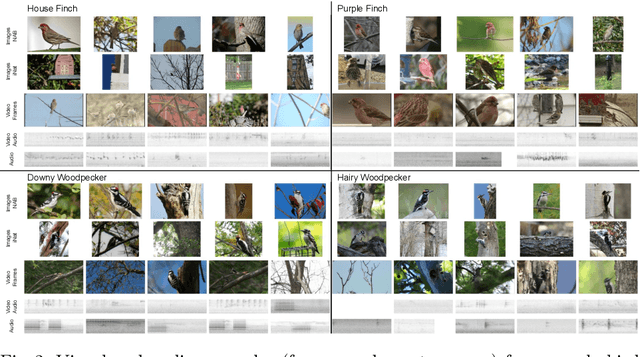
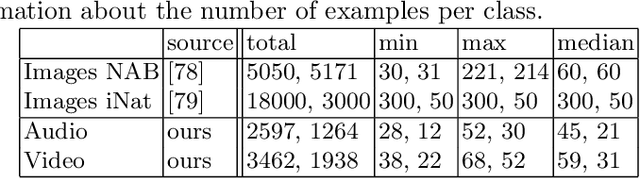
We present a new benchmark dataset, Sapsucker Woods 60 (SSW60), for advancing research on audiovisual fine-grained categorization. While our community has made great strides in fine-grained visual categorization on images, the counterparts in audio and video fine-grained categorization are relatively unexplored. To encourage advancements in this space, we have carefully constructed the SSW60 dataset to enable researchers to experiment with classifying the same set of categories in three different modalities: images, audio, and video. The dataset covers 60 species of birds and is comprised of images from existing datasets, and brand new, expert-curated audio and video datasets. We thoroughly benchmark audiovisual classification performance and modality fusion experiments through the use of state-of-the-art transformer methods. Our findings show that performance of audiovisual fusion methods is better than using exclusively image or audio based methods for the task of video classification. We also present interesting modality transfer experiments, enabled by the unique construction of SSW60 to encompass three different modalities. We hope the SSW60 dataset and accompanying baselines spur research in this fascinating area.
Multimodal Open-Vocabulary Video Classification via Pre-Trained Vision and Language Models
Jul 15, 2022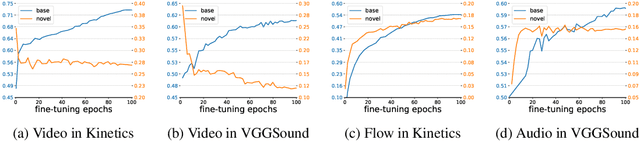
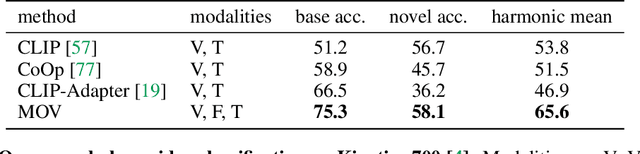
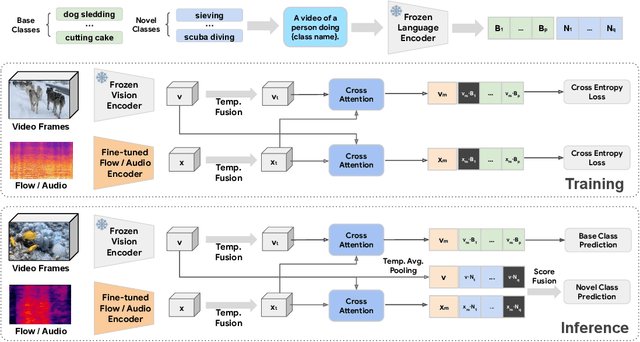
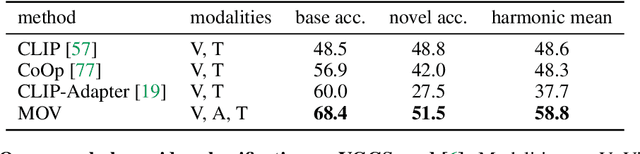
Utilizing vision and language models (VLMs) pre-trained on large-scale image-text pairs is becoming a promising paradigm for open-vocabulary visual recognition. In this work, we extend this paradigm by leveraging motion and audio that naturally exist in video. We present \textbf{MOV}, a simple yet effective method for \textbf{M}ultimodal \textbf{O}pen-\textbf{V}ocabulary video classification. In MOV, we directly use the vision encoder from pre-trained VLMs with minimal modifications to encode video, optical flow and audio spectrogram. We design a cross-modal fusion mechanism to aggregate complimentary multimodal information. Experiments on Kinetics-700 and VGGSound show that introducing flow or audio modality brings large performance gains over the pre-trained VLM and existing methods. Specifically, MOV greatly improves the accuracy on base classes, while generalizes better on novel classes. MOV achieves state-of-the-art results on UCF and HMDB zero-shot video classification benchmarks, significantly outperforming both traditional zero-shot methods and recent methods based on VLMs. Code and models will be released.