 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImitate and Repurpose: Learning Reusable Robot Movement Skills From Human and Animal Behaviors
Mar 31, 2022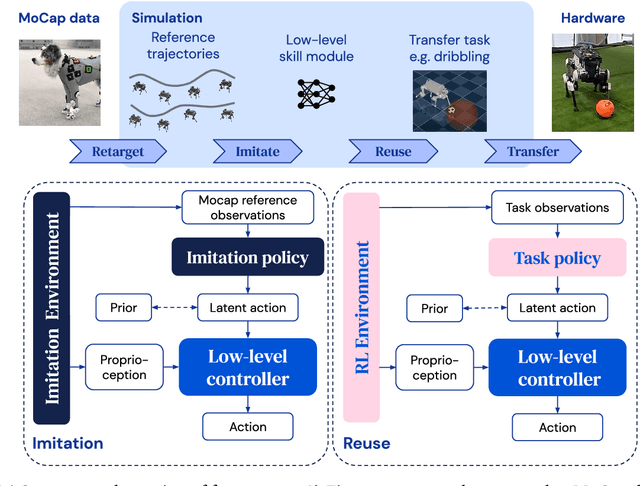

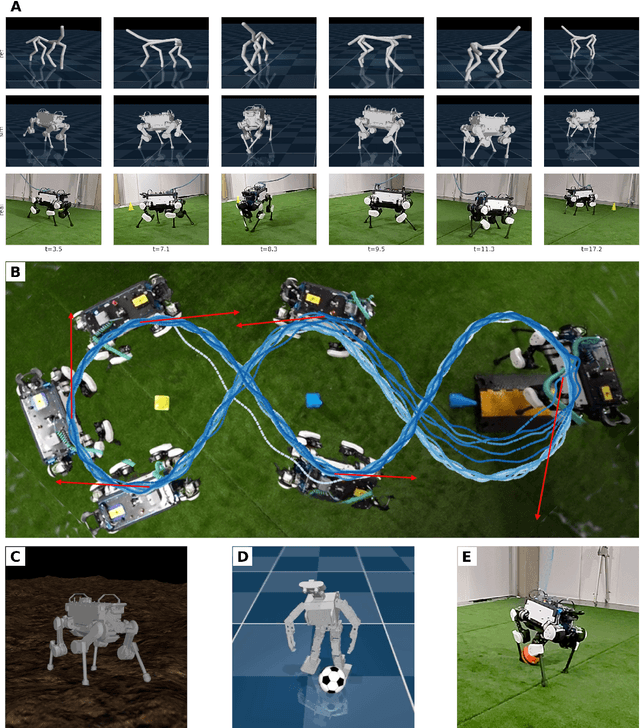
We investigate the use of prior knowledge of human and animal movement to learn reusable locomotion skills for real legged robots. Our approach builds upon previous work on imitating human or dog Motion Capture (MoCap) data to learn a movement skill module. Once learned, this skill module can be reused for complex downstream tasks. Importantly, due to the prior imposed by the MoCap data, our approach does not require extensive reward engineering to produce sensible and natural looking behavior at the time of reuse. This makes it easy to create well-regularized, task-oriented controllers that are suitable for deployment on real robots. We demonstrate how our skill module can be used for imitation, and train controllable walking and ball dribbling policies for both the ANYmal quadruped and OP3 humanoid. These policies are then deployed on hardware via zero-shot simulation-to-reality transfer. Accompanying videos are available at https://bit.ly/robot-npmp.
Is Curiosity All You Need? On the Utility of Emergent Behaviours from Curious Exploration
Sep 17, 2021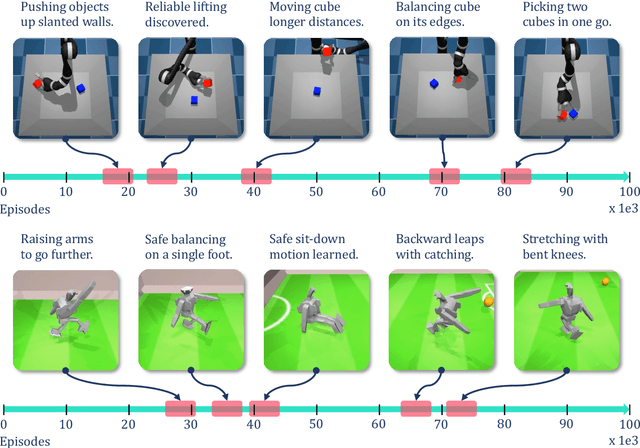

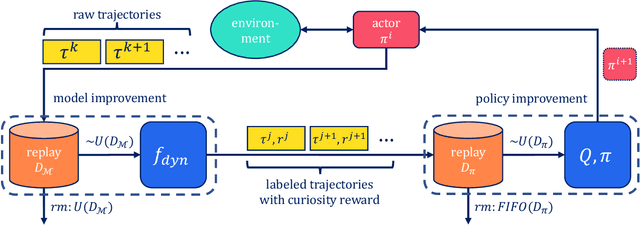

Curiosity-based reward schemes can present powerful exploration mechanisms which facilitate the discovery of solutions for complex, sparse or long-horizon tasks. However, as the agent learns to reach previously unexplored spaces and the objective adapts to reward new areas, many behaviours emerge only to disappear due to being overwritten by the constantly shifting objective. We argue that merely using curiosity for fast environment exploration or as a bonus reward for a specific task does not harness the full potential of this technique and misses useful skills. Instead, we propose to shift the focus towards retaining the behaviours which emerge during curiosity-based learning. We posit that these self-discovered behaviours serve as valuable skills in an agent's repertoire to solve related tasks. Our experiments demonstrate the continuous shift in behaviour throughout training and the benefits of a simple policy snapshot method to reuse discovered behaviour for transfer tasks.
Collect & Infer -- a fresh look at data-efficient Reinforcement Learning
Aug 23, 2021This position paper proposes a fresh look at Reinforcement Learning (RL) from the perspective of data-efficiency. Data-efficient RL has gone through three major stages: pure on-line RL where every data-point is considered only once, RL with a replay buffer where additional learning is done on a portion of the experience, and finally transition memory based RL, where, conceptually, all transitions are stored and re-used in every update step. While inferring knowledge from all explicitly stored experience has lead to a tremendous gain in data-efficiency, the question of how this data is collected has been vastly understudied. We argue that data-efficiency can only be achieved through careful consideration of both aspects. We propose to make this insight explicit via a paradigm that we call 'Collect and Infer', which explicitly models RL as two separate but interconnected processes, concerned with data collection and knowledge inference respectively. We discuss implications of the paradigm, how its ideas are reflected in the literature, and how it can guide future research into data efficient RL.
Representation Matters: Improving Perception and Exploration for Robotics
Nov 03, 2020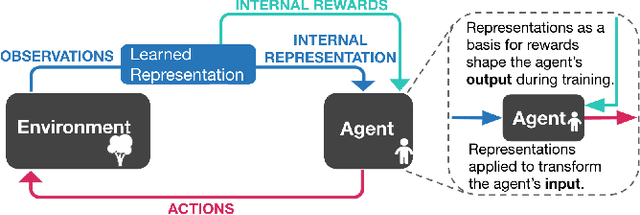
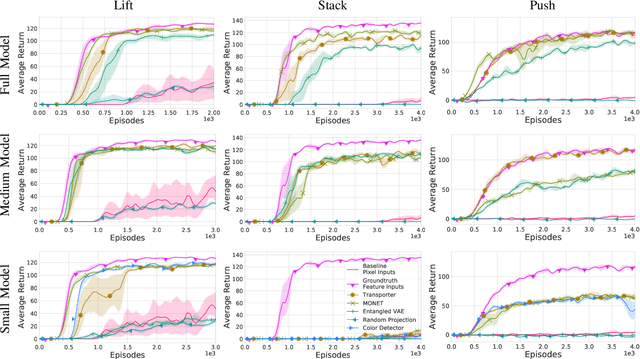

Projecting high-dimensional environment observations into lower-dimensional structured representations can considerably improve data-efficiency for reinforcement learning in domains with limited data such as robotics. Can a single generally useful representation be found? In order to answer this question, it is important to understand how the representation will be used by the agent and what properties such a 'good' representation should have. In this paper we systematically evaluate a number of common learnt and hand-engineered representations in the context of three robotics tasks: lifting, stacking and pushing of 3D blocks. The representations are evaluated in two use-cases: as input to the agent, or as a source of auxiliary tasks. Furthermore, the value of each representation is evaluated in terms of three properties: dimensionality, observability and disentanglement. We can significantly improve performance in both use-cases and demonstrate that some representations can perform commensurate to simulator states as agent inputs. Finally, our results challenge common intuitions by demonstrating that: 1) dimensionality strongly matters for task generation, but is negligible for inputs, 2) observability of task-relevant aspects mostly affects the input representation use-case, and 3) disentanglement leads to better auxiliary tasks, but has only limited benefits for input representations. This work serves as a step towards a more systematic understanding of what makes a 'good' representation for control in robotics, enabling practitioners to make more informed choices for developing new learned or hand-engineered representations.
"What, not how": Solving an under-actuated insertion task from scratch
Oct 30, 2020

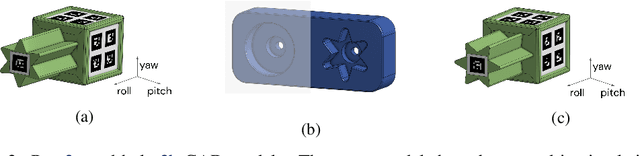
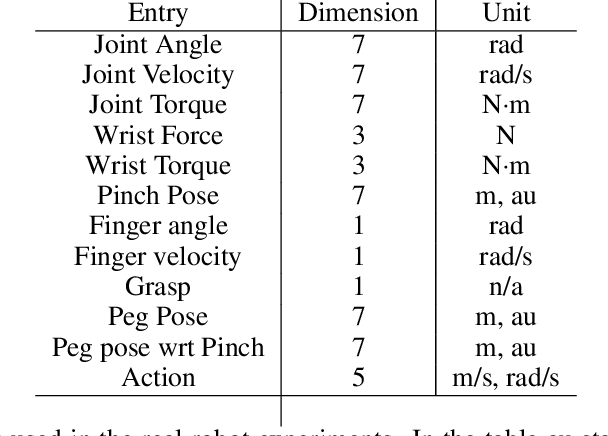
Robot manipulation requires a complex set of skills that need to be carefully combined and coordinated to solve a task. Yet, most ReinforcementLearning (RL) approaches in robotics study tasks which actually consist only of a single manipulation skill, such as grasping an object or inserting a pre-grasped object. As a result the skill ('how' to solve the task) but not the actual goal of a complete manipulation ('what' to solve) is specified. In contrast, we study a complex manipulation goal that requires an agent to learn and combine diverse manipulation skills. We propose a challenging, highly under-actuated peg-in-hole task with a free, rotational asymmetrical peg, requiring a broad range of manipulation skills. While correct peg (re-)orientation is a requirement for successful insertion, there is no reward associated with it. Hence an agent needs to understand this pre-condition and learn the skill to fulfil it. The final insertion reward is sparse, allowing freedom in the solution and leading to complex emerging behaviour not envisioned during the task design. We tackle the problem in a multi-task RL framework using Scheduled Auxiliary Control (SAC-X) combined with Regularized Hierarchical Policy Optimization (RHPO) which successfully solves the task in simulation and from scratch on a single robot where data is severely limited.
Towards General and Autonomous Learning of Core Skills: A Case Study in Locomotion
Aug 06, 2020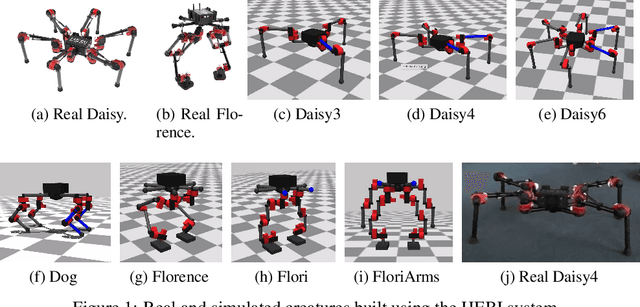
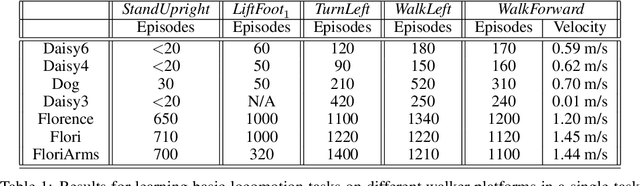
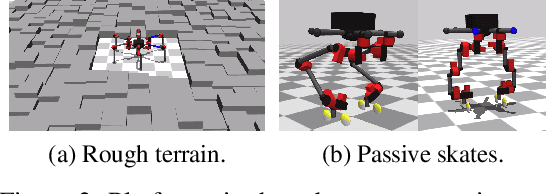

Modern Reinforcement Learning (RL) algorithms promise to solve difficult motor control problems directly from raw sensory inputs. Their attraction is due in part to the fact that they can represent a general class of methods that allow to learn a solution with a reasonably set reward and minimal prior knowledge, even in situations where it is difficult or expensive for a human expert. For RL to truly make good on this promise, however, we need algorithms and learning setups that can work across a broad range of problems with minimal problem specific adjustments or engineering. In this paper, we study this idea of generality in the locomotion domain. We develop a learning framework that can learn sophisticated locomotion behavior for a wide spectrum of legged robots, such as bipeds, tripeds, quadrupeds and hexapods, including wheeled variants. Our learning framework relies on a data-efficient, off-policy multi-task RL algorithm and a small set of reward functions that are semantically identical across robots. To underline the general applicability of the method, we keep the hyper-parameter settings and reward definitions constant across experiments and rely exclusively on on-board sensing. For nine different types of robots, including a real-world quadruped robot, we demonstrate that the same algorithm can rapidly learn diverse and reusable locomotion skills without any platform specific adjustments or additional instrumentation of the learning setup.
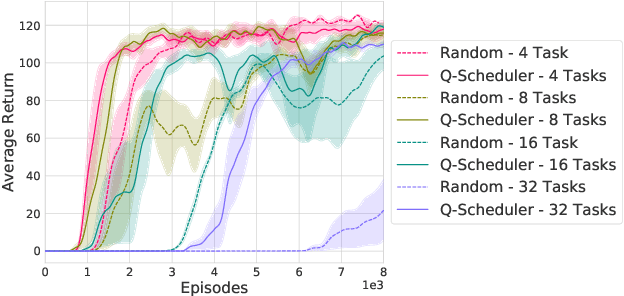
Data-efficient Hindsight Off-policy Option Learning
Jul 30, 2020
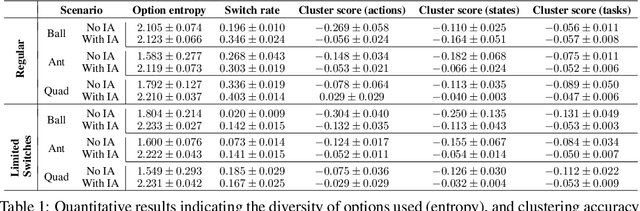


Solutions to most complex tasks can be decomposed into simpler, intermediate skills, reusable across wider ranges of problems. We follow this concept and introduce Hindsight Off-policy Options (HO2), a new algorithm for efficient and robust option learning. The algorithm relies on critic-weighted maximum likelihood estimation and an efficient dynamic programming inference procedure over off-policy trajectories. We can backpropagate through the inference procedure through time and the policy components for every time-step, making it possible to train all component's parameters off-policy, independently of the data-generating behavior policy. Experimentally, we demonstrate that HO2 outperforms competitive baselines and solves demanding robot stacking and ball-in-cup tasks from raw pixel inputs in simulation. We further compare autoregressive option policies with simple mixture policies, providing insights into the relative impact of two types of abstractions common in the options framework: action abstraction and temporal abstraction. Finally, we illustrate challenges caused by stale data in off-policy options learning and provide effective solutions.
Simple Sensor Intentions for Exploration
May 15, 2020
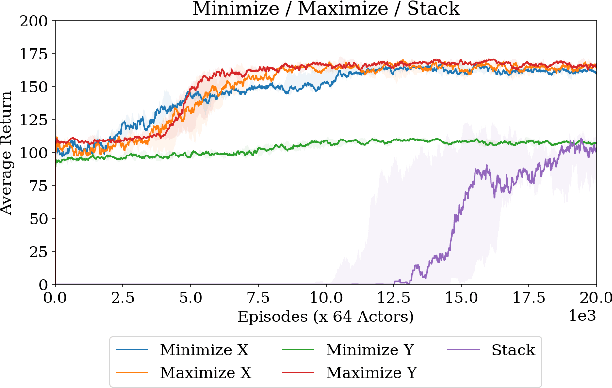
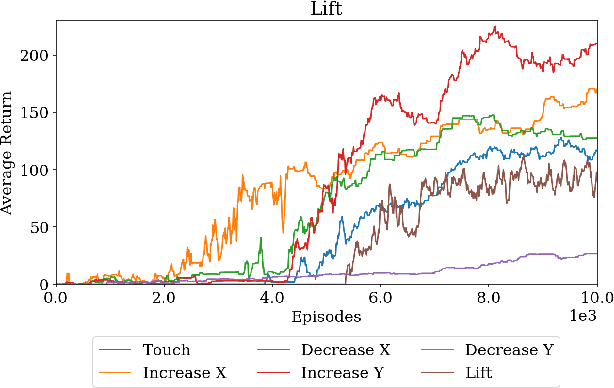
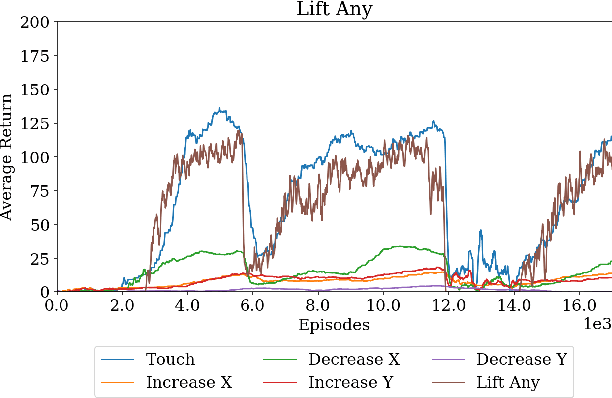
Modern reinforcement learning algorithms can learn solutions to increasingly difficult control problems while at the same time reduce the amount of prior knowledge needed for their application. One of the remaining challenges is the definition of reward schemes that appropriately facilitate exploration without biasing the solution in undesirable ways, and that can be implemented on real robotic systems without expensive instrumentation. In this paper we focus on a setting in which goal tasks are defined via simple sparse rewards, and exploration is facilitated via agent-internal auxiliary tasks. We introduce the idea of simple sensor intentions (SSIs) as a generic way to define auxiliary tasks. SSIs reduce the amount of prior knowledge that is required to define suitable rewards. They can further be computed directly from raw sensor streams and thus do not require expensive and possibly brittle state estimation on real systems. We demonstrate that a learning system based on these rewards can solve complex robotic tasks in simulation and in real world settings. In particular, we show that a real robotic arm can learn to grasp and lift and solve a Ball-in-a-Cup task from scratch, when only raw sensor streams are used for both controller input and in the auxiliary reward definition.
Keep Doing What Worked: Behavioral Modelling Priors for Offline Reinforcement Learning
Feb 23, 2020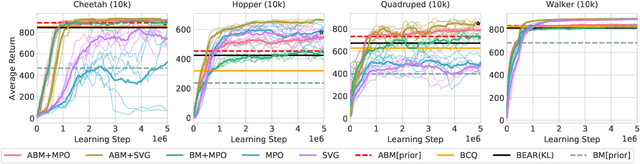

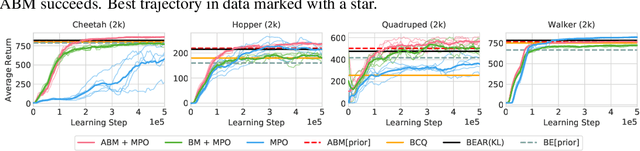
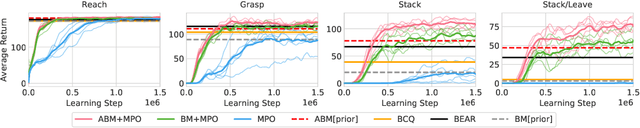
Off-policy reinforcement learning algorithms promise to be applicable in settings where only a fixed data-set (batch) of environment interactions is available and no new experience can be acquired. This property makes these algorithms appealing for real world problems such as robot control. In practice, however, standard off-policy algorithms fail in the batch setting for continuous control. In this paper, we propose a simple solution to this problem. It admits the use of data generated by arbitrary behavior policies and uses a learned prior -- the advantage-weighted behavior model (ABM) -- to bias the RL policy towards actions that have previously been executed and are likely to be successful on the new task. Our method can be seen as an extension of recent work on batch-RL that enables stable learning from conflicting data-sources. We find improvements on competitive baselines in a variety of RL tasks -- including standard continuous control benchmarks and multi-task learning for simulated and real-world robots.
Continuous-Discrete Reinforcement Learning for Hybrid Control in Robotics
Jan 02, 2020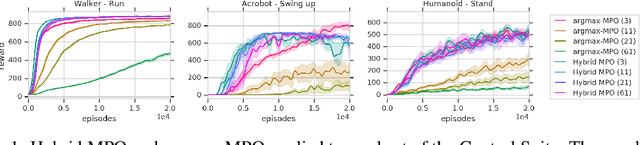



Many real-world control problems involve both discrete decision variables - such as the choice of control modes, gear switching or digital outputs - as well as continuous decision variables - such as velocity setpoints, control gains or analogue outputs. However, when defining the corresponding optimal control or reinforcement learning problem, it is commonly approximated with fully continuous or fully discrete action spaces. These simplifications aim at tailoring the problem to a particular algorithm or solver which may only support one type of action space. Alternatively, expert heuristics are used to remove discrete actions from an otherwise continuous space. In contrast, we propose to treat hybrid problems in their 'native' form by solving them with hybrid reinforcement learning, which optimizes for discrete and continuous actions simultaneously. In our experiments, we first demonstrate that the proposed approach efficiently solves such natively hybrid reinforcement learning problems. We then show, both in simulation and on robotic hardware, the benefits of removing possibly imperfect expert-designed heuristics. Lastly, hybrid reinforcement learning encourages us to rethink problem definitions. We propose reformulating control problems, e.g. by adding meta actions, to improve exploration or reduce mechanical wear and tear.